
IP-Adapter 更新了全新的模型—FaceID plus V2 版本,同时还支持 SDXL 模型。
FaceID plus V2 版本的优点:
-
解决任务一致性
-
一张图生成相似角色
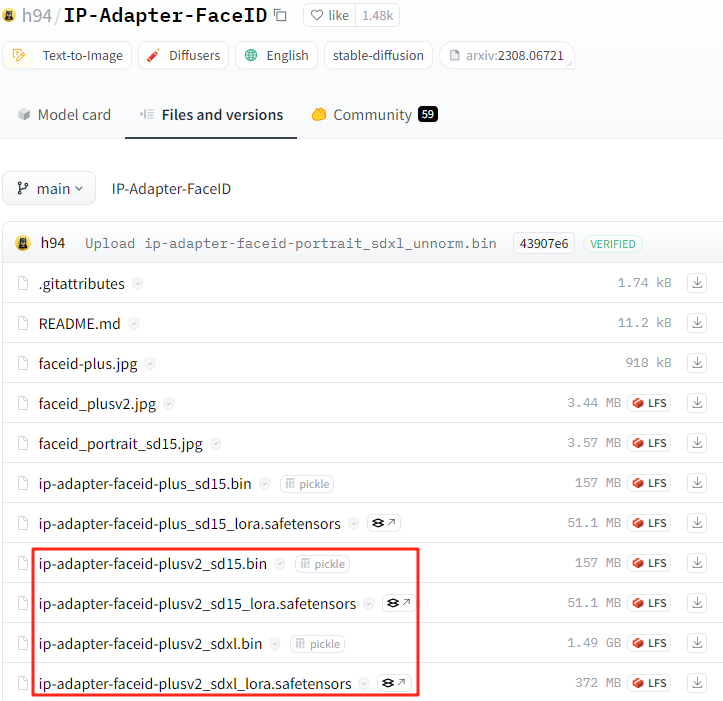
其中,两个 Lora文件 放置在:SD安装目录\models\Lora
两个 bin文件 放置在:SD安装目录\extensions\sd-webui-controlnet\models
实操
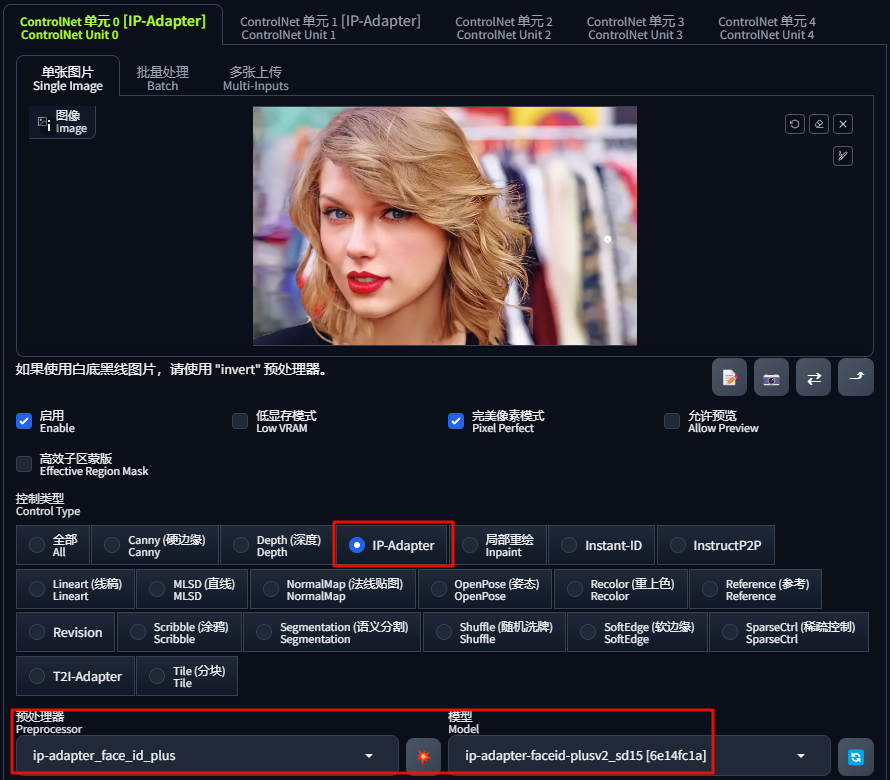
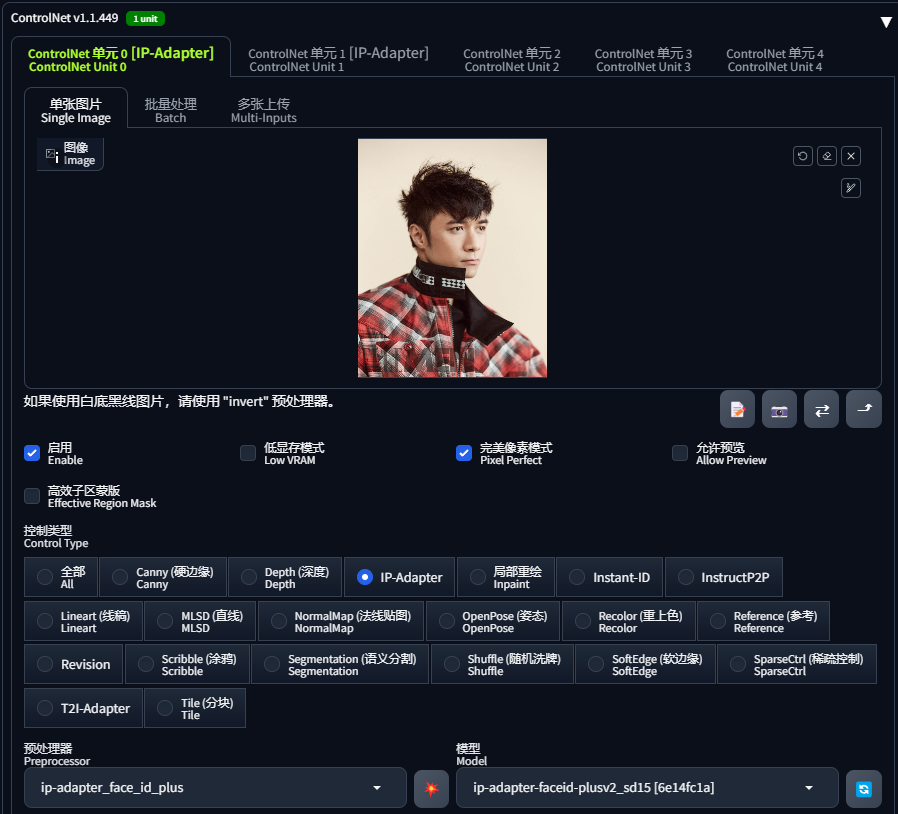
开启一个 ControlNet,上传一张霉霉的图片(尽量选择脸部近景图片),控制类型选择「IP-Adapter」,预处理器选择「ip-adapter_face_id_plus」,模型选择「ip-adapter-faceid-plusv2_sd15」:
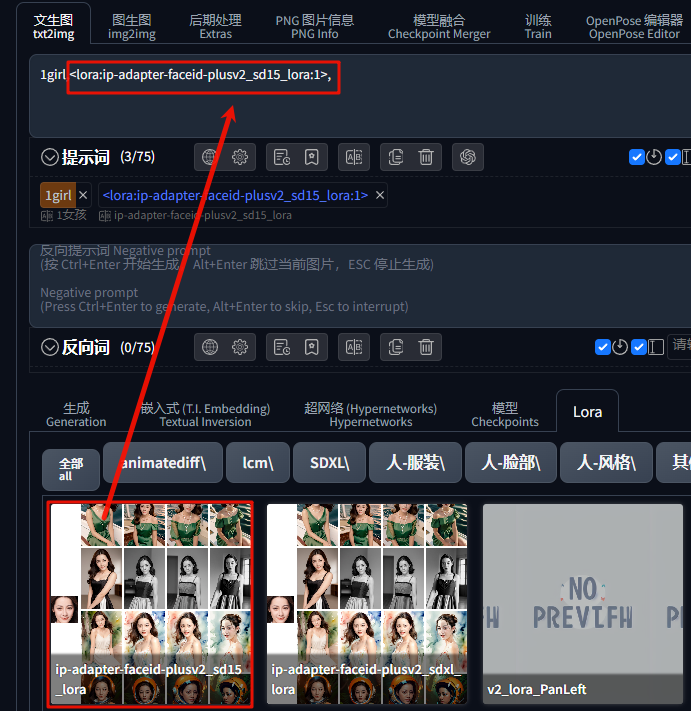
提示词输入:1girl,同时将 faceid-plusv2_sd15 的 lora 添加到正向提示词中:
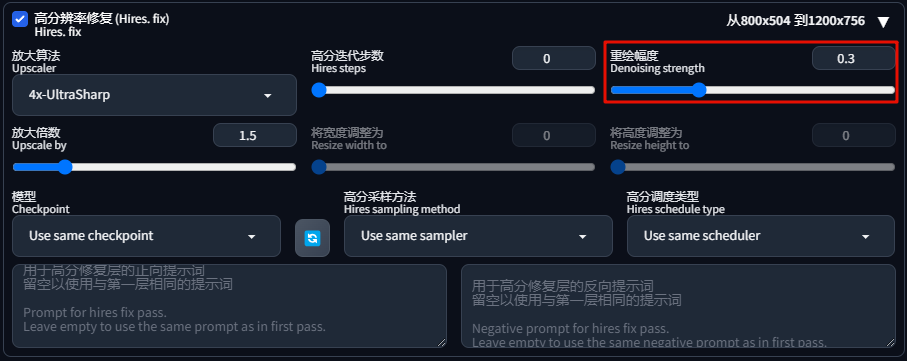
因为是生成人物图片,适当开启 高分辨率修复(想保持与原图相似,降低重绘幅度至0.3):
生成的图片如下:

再来试试我钟意的歌手—古巨基的图片,
这次上传一张侧脸图片,使用真人模型:

生成图片如下:

这里直接将该软件分享出来给大家吧~

1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!














![NSSCTF练习记录:[AFCTF 2018]BASE](https://i-blog.csdnimg.cn/direct/6a3d4a9e0d5d418f883b46319e839f0f.png)

