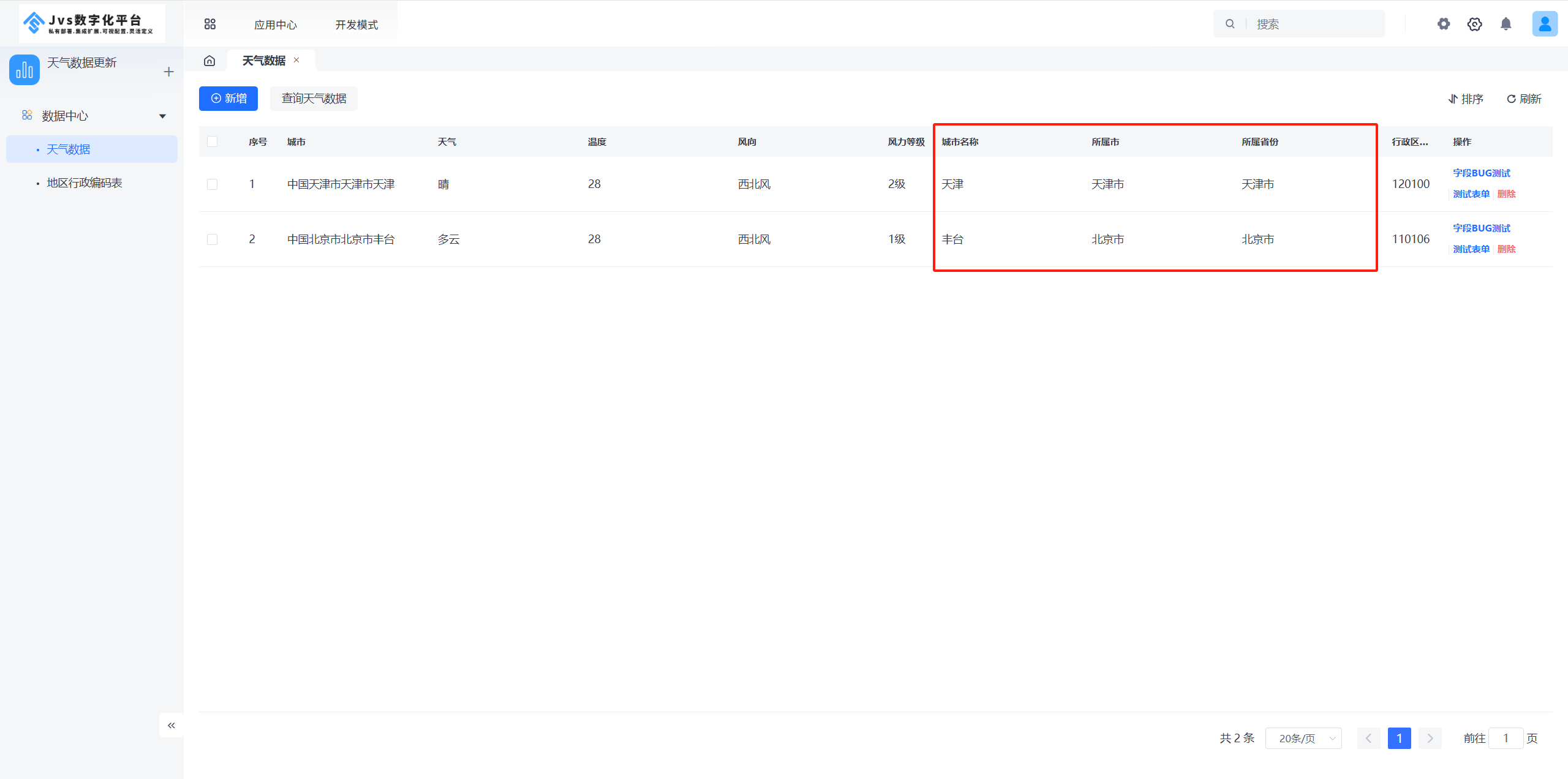
【STM32开发笔记】STM32H7S78-DK上的CoreMark移植和优化--兼记STM32上的printf重定向实现及常见问题解决
- 一、CoreMark简介
- 二、创建CubeMX项目
- 2.1 选择MCU
- 2.2 配置CPU时钟
- 2.3 配置串口功能
- 2.4 配置LED引脚
- 2.5 生成CMake项目
- 三、基础功能支持
- 3.1 支持记录耗时
- 3.2 支持printf输出到串口
- 3.3 支持printf输出浮点数
- 四、移植CoreMark源码
- 4.1 添加CoreMark源码
- 4.2 修改 core_portme.c 文件
- 4.3 修改 core_portme.h 文件
- 4.4 修改 core_main.c 文件
- 4.5 修改 main.c 文件
- 4.6 修改 CMakeLists.txt 文件
- 4.7 编译、下载、运行
- 五、优化CoreMark跑分
- 5.1 修改CMake构建类型
- 5.2 修改编译优化选项
- 5.3 打开ICache和DCache
- 5.4 解决换行不对齐问题
- 5.5 项目最终版源代码
- 六、参考链接
本文首介绍CoreMark是什么,然后使用CubeMX创建空的STM32H7S7L8HxH项目,并生成基于CMake的项目代码;接着一步步将CoreMark源码移植到项目中;最后一步步优化CoreMark跑分,将跑分从106.4最终优化到2410.2分,实现了近23倍的提升。本文实验过程中介绍了如何使用STM32 HAL库接口进行计时,以及如何将printf输出重定向到UART,并通过ST-Link调试器接收UART输出。另外,本文还介绍了如何解决使用gcc工具链时STM32上的printf无法输出浮点数问题,以及如何解决STM32上printf输出换行不对齐问题。因此,无论你对STM32H7S上的CoreMark跑分感兴趣,还是对STM32上的printf重定向方法及常见问题感兴趣,本文都值得一看。
一、CoreMark简介
什么是CoreMark?
来自CoreMark首页的解释是:
CoreMark is a simple, yet sophisticated benchmark that is designed specifically to test the functionality of a processor core. Running CoreMark produces a single-number score allowing users to make quick comparisons between processors.
翻译一下就是:
CoreMark是一个简单而又精密的基准测试程序,是专门为测试处理器核功能而设计的。运行CoreMark会产生一个“单个数字”的分数,(从而)允许用户在(不同)CPU之间进行快速比较。
简单来说,就是一个测试CPU性能的程序,类似PC上的Cinebench、CPU-Z之类的CPU性能测试工具。
了解了CoreMark是什么之后,接下来我们尝试在STM32H7S78-DK开发板上跑一下CoreMark,看看分数是多少。
接下来就可以开始进行CoreMark移植了,为了让移植步骤清晰明确,这里我把移植分为两大部分:
- 基础功能支持,即创建一个支持printf打印和计时的项目
- CoreMark移植,即将CoreMark源码添加到项目中,并修改CoreMark源码,使其能够正常运行
二、创建CubeMX项目
2.1 选择MCU
首先,启动CubeMX,Commercial Part Number 收入H7S7,回车搜索:
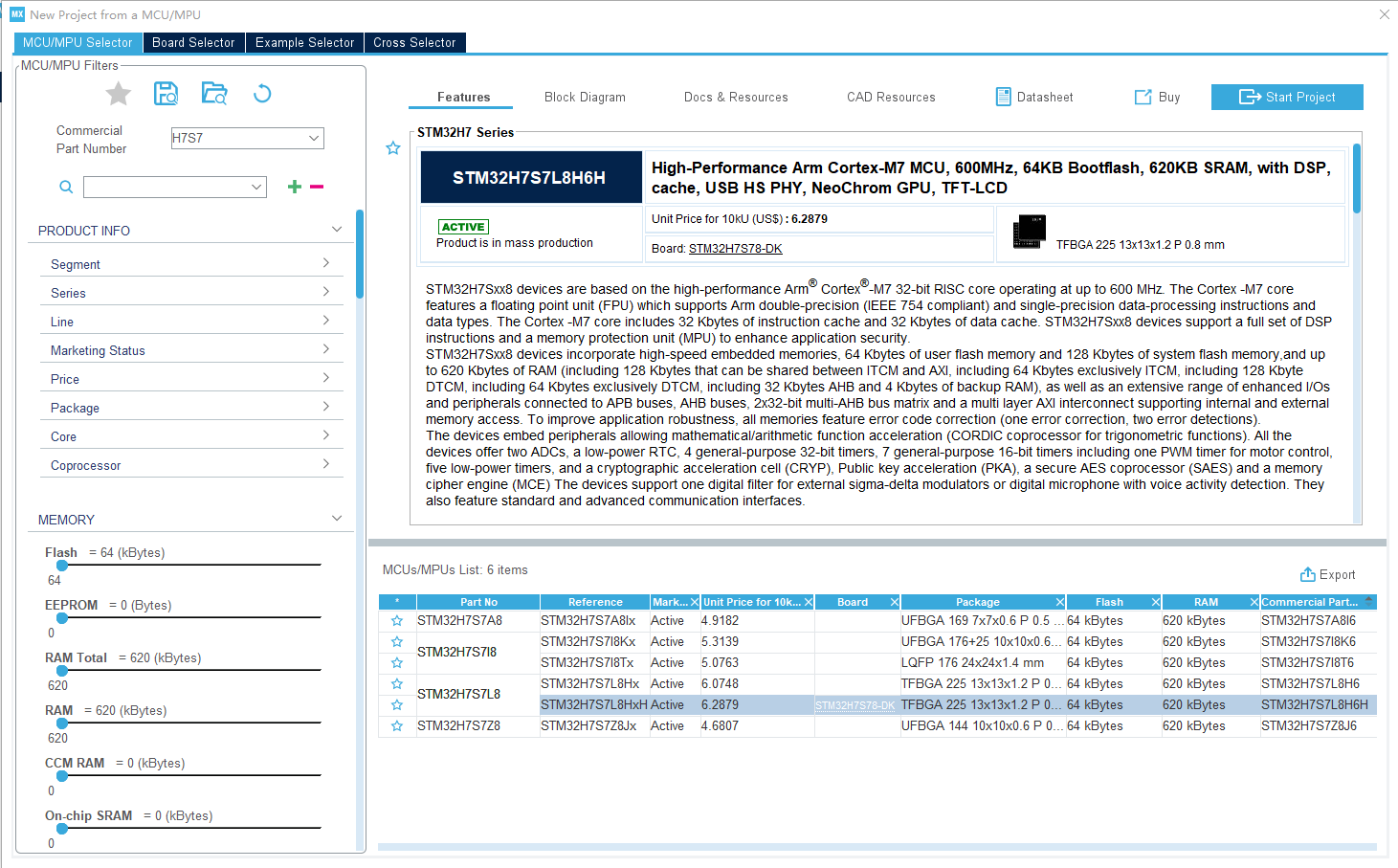
选中Board一行有STM32H7S78-DK的,然后点击右上角的Sart Project,开始创建项目。
2.2 配置CPU时钟
然后,STM32CubeMX进入配置界面,切换到Clock Configuration标签页,将To CPU Clocks修改为600并回车,CubeMX软件将会自动计算其他参数:
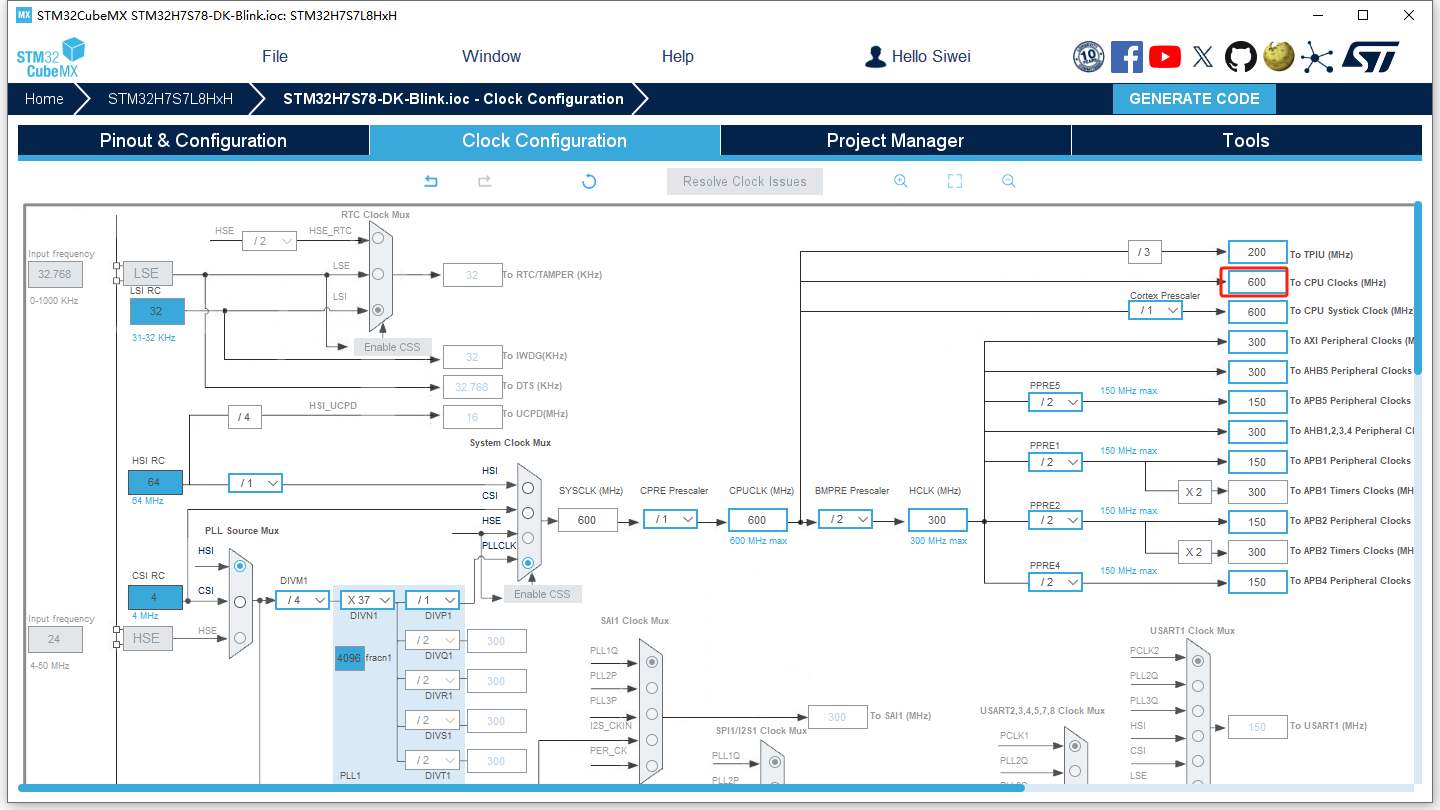
按Ctrol+S保存,选择适当的位置保存ioc文件。
2.3 配置串口功能
开发板上自带了ST-Link V3调试器,该调试器带有虚拟串口功能。通过查阅原理图,我们知道主控MCU和ST-Link之间的连接关系如下图:
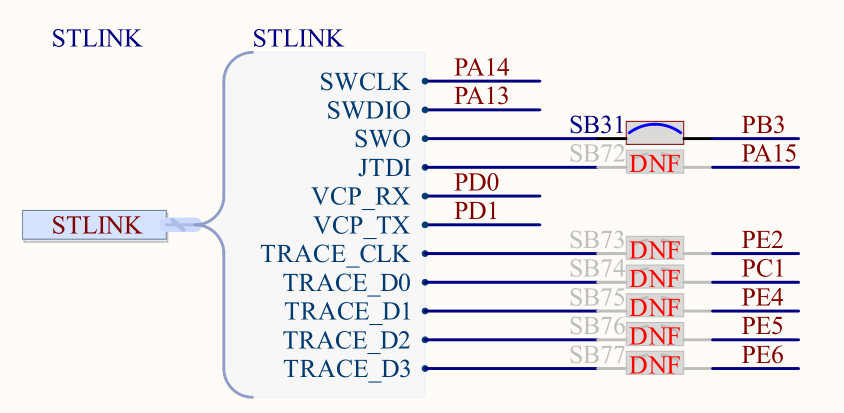
可以看到,ST-Link的虚拟串口和主控芯片的连接关系为:
- VCP_RX连接到主控芯片的 PD0上;
- VCP_TX连接到主控芯片的 PD1上;
接下来,需要修改这两个引脚的功能。
修改PD0为UART4_RX功能:

修改PD1为UART4_TX功能:

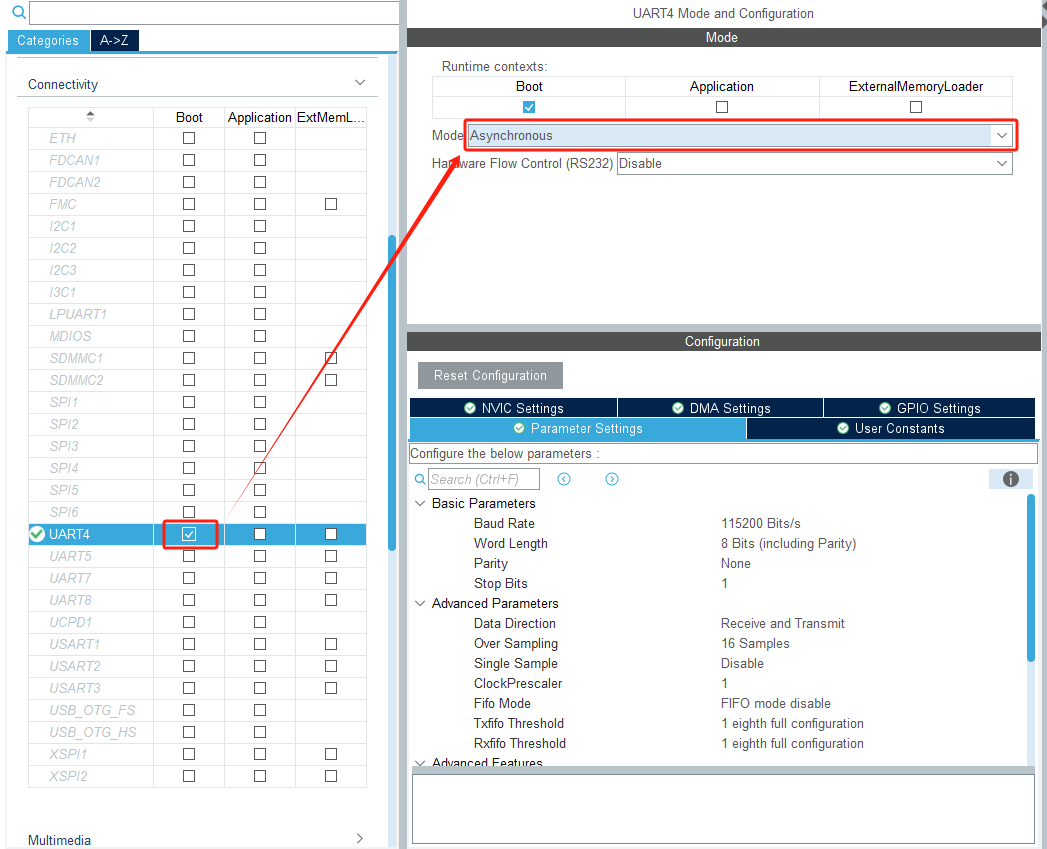
启用UART4功能,设置为异步,并分配到Boot子项目:
2.4 配置LED引脚
为了方便观察CoreMark执行完成了,我们把红色LED的控制引脚也配置一下。查阅原理图,找到USER LED对应部分:
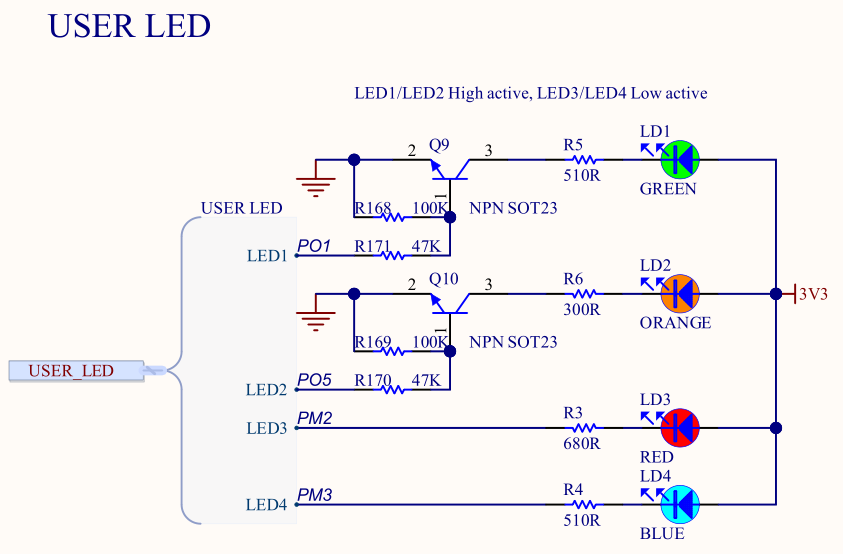
可以看到,红色LED对应的是PM2引脚。
修改PM2引脚为GPIO_Output功能:

将其分配到Boot子项目,并为其设置用户标签(User Label):

2.5 生成CMake项目
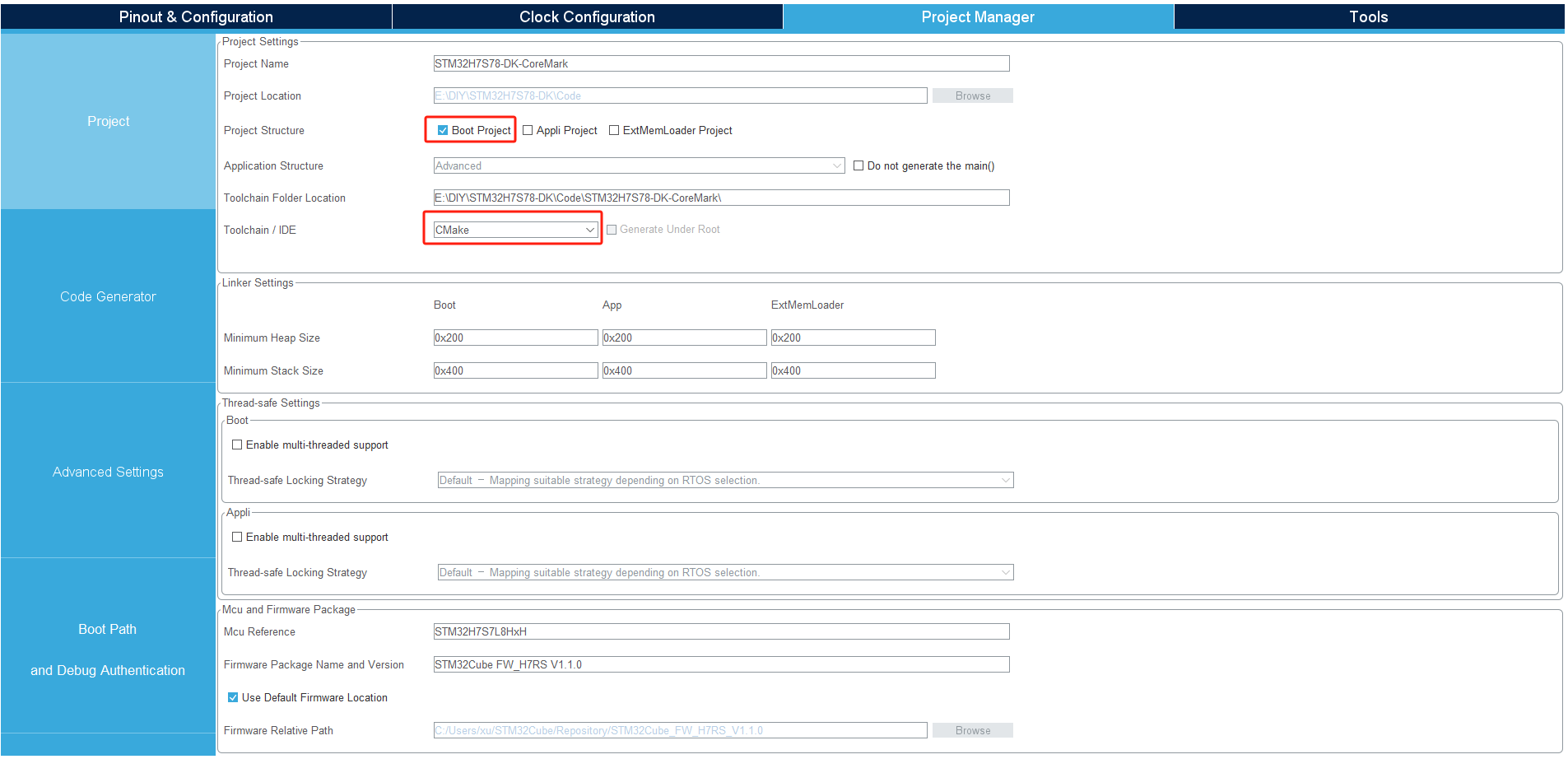
接下来,CubeMX软件切换到Project Manager标签页,Project Structure勾选 Boot Project,Toolchain/IDE下拉到 CMake:
Code Generator部分,勾选Generate peripheral initialization as a pair of ‘.c/.h’ files per peripherals:
最后,点击右上角的Generate Code,生成代码:
VSCode导入项目等等操作,本文不再赘述,具体可参考我上一篇帖子:
【STM32H7S78-DK评测】搭建基于ST官方VSCode扩展的STM32开发环境 - STM32团队 ST意法半导体中文论坛 (stmicroelectronics.cn)
三、基础功能支持
基础功能支持主要包括两个功能:
- 支持记录耗时
- 支持printf打印(包括浮点数打印)
下面分别介绍如何实现这两个功能。
3.1 支持记录耗时
STM32上,使用HAL库记录耗时非常简单,只需要用:
HAL_GetTick()获取Tick数即可,默认的Tick频率是1000Hz;- 需要注意的是:
HAL_GetTickFreq()返回的枚举值,并不是实际的频率(例如默认的HAL_TICK_FREQ_1KHZ,其值为1,而不是1000)。
因此,记录使用HAL_GetTick记录耗时,代码类似:
uint32_t start = HAL_GetTick();
// 需要记录耗时的代码
uint32_t end = HAL_GetTick();
float cost_s = (end - start) / 1000.0f; // 实际耗时(单位:秒)
3.2 支持printf输出到串口
CubeMX选择CMake项目后,默认已经生成了 syscalls.c文件,已经实现了支持gcc工具链的printf输出的一半功能。另外一半功能需要手动添加到usart.c文件的末尾的USER CODE区域:
/* USER CODE BEGIN 1 */
#ifdef __GNUC__
// GCC
int __io_putchar(int ch)
{
if (HAL_UART_Transmit(&huart4, (uint8_t*) &ch, 1, HAL_MAX_DELAY) != HAL_OK)
{
return -1;
}
return ch;
}
#endif
/* USER CODE END 1 */
完成以上修改之后,就可以适用printf打印了,可以修改main.c,找到其中的循环进行测试:
/* Infinite loop */
/* USER CODE BEGIN WHILE */
int count = 0;
printf("Hello, from STM32H7S78-DK!\r\n");
while (1)
{
printf("Hello, from STM32H7S78-DK %d!\r\n", ++count);
HAL_Delay(1000);
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
}
/* USER CODE END 3 */
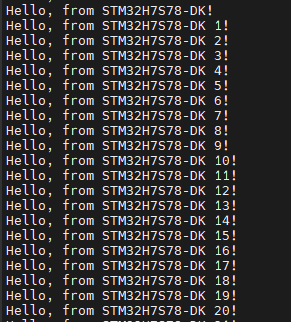
如无意外,编译、下载、运行可以通过ST-Link的虚拟串口看到如下输出:
3.3 支持printf输出浮点数
默认生成的CMake项目不支持浮点数打印,需要修改链接选项,修改文件Boot\CMakeLists.txt:
在末尾添加如下代码片段:
target_link_options(${CMAKE_PROJECT_NAME} PRIVATE
-u _printf_float
)
之后,再次编译,就可以输出浮点数了。
类似的,为了验证可以正常输出浮点数,修改main.c中的循环:
/* Infinite loop */
/* USER CODE BEGIN WHILE */
int count = 0;
printf("\r\n");
printf("Hello, from STM32H7S78-DK!\r\n");
while (1)
{
++count;
printf("Hello, from STM32H7S78-DK %d %f!\r\n", count, 1.0 / count);
HAL_Delay(1000);
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
}
/* USER CODE END 3 */
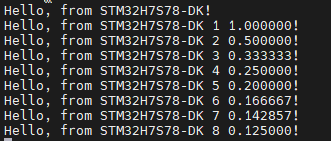
如无意外,编译、下载、运行,可以在串口看到如下输出:
四、移植CoreMark源码
4.1 添加CoreMark源码
CoreMark代码仓:https://github.com/eembc/coremark.git
将代码下载下来之后,将其中的如下文件到项目的Boot\Core\Src子目录下:
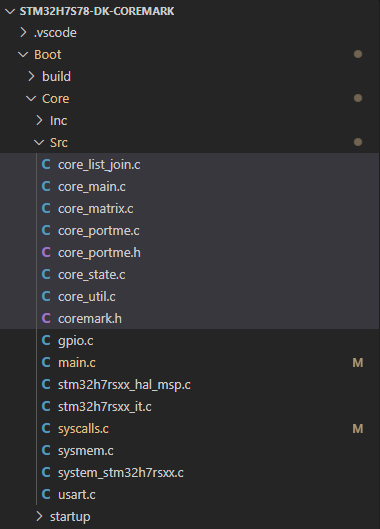
拷贝后,Boot项目文件结构如下:
4.2 修改 core_portme.c 文件
core_portme.c文件中,需要修改的是计时的几个宏定义,具体如下:
// 注释(或者删除)原来的这三个宏定义
//#define CORETIMETYPE clock_t
//#define GETMYTIME(_t) (*_t = clock())
//#define EE_TICKS_PER_SEC (NSECS_PER_SEC / TIMER_RES_DIVIDER)
// 添加以下代码:
#include "stm32h7rsxx_hal.h"
#define CORETIMETYPE uint32_t
#define GETMYTIME(_t) (*_t = HAL_GetTick())
#define EE_TICKS_PER_SEC (1000)
4.3 修改 core_portme.h 文件
core_portme.h文件,开头部分需要新增如下代码:
#define ITERATIONS 1600 // 这个值需要保证能够运行至少10秒,可以先写一个值,运行不足10秒会报错,再回来修改
#define FLAGS_STR "" // 这个值根据实际的编译优化选项进行填写,在最终输出种原样输出,根据实际用的编译选项修改
#define MAIN_HAS_NOARGC 1 // coremark main不使用参数
#define MAIN_HAS_NORETURN 1 // coremark main不使用返回值
void core_main(void); // coremark main 函数原型
4.4 修改 core_main.c 文件
coremark源码的core_main.c中定义了main函数,CubeMX生成的main.c中也有main函数,直接编译会产生冲突,因此需要修改core_main.c文件,重命名其中的main函数,并在main.c中调用它。
在core_main.c中,找到main函数,并将其修改为core_main:
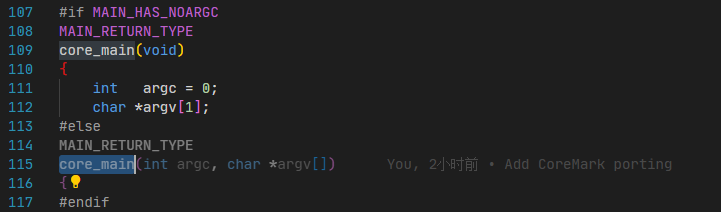
4.5 修改 main.c 文件
接下来,修改 main.c 文件,开头出添加:

找到while循环,并将其修改为:
/* Infinite loop */
/* USER CODE BEGIN WHILE */
printf("\r\nHello, from STM32H7S78-DK!\r\n");
core_main();
while (1)
{
HAL_GPIO_TogglePin(RED_GPIO_Port, RED_Pin);
HAL_Delay(1000);
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
}
/* USER CODE END 3 */
4.6 修改 CMakeLists.txt 文件
完成以上修改后,还差最后一步,就是让新增的coremark的几个源码文件参与到编译、链接过程中。因此,需要修改Boot\CMakeLists.txt文件,
找到其中的target_sources代码片段,将其修改为:
# Add sources to executable
target_sources(${CMAKE_PROJECT_NAME} PRIVATE
# Add user sources here
./Core/Src/core_list_join.c
./Core/Src/core_main.c
./Core/Src/core_matrix.c
./Core/Src/core_state.c
./Core/Src/core_util.c
./Core/Src/core_portme.c
)
4.7 编译、下载、运行
完成上述所有修改后,编译构建,可以看到如下输出:
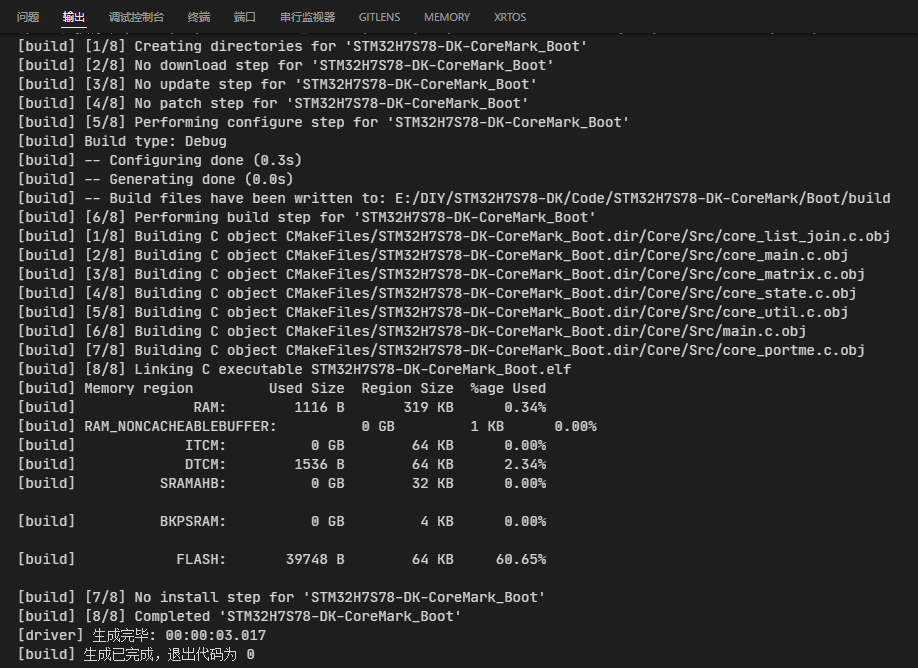
下载、运行,可以看到串口输出如下:

跑分结果为 106.425 分,这个分数太低了。另外,输出结果中的换行没有从头对齐,但这个问题不大,可以最后再处理,具体处理方法见本文的5.4节。
五、优化CoreMark跑分
前面CoreMark跑分较低,接下来尝试通过不同方法提升跑分。
5.1 修改CMake构建类型
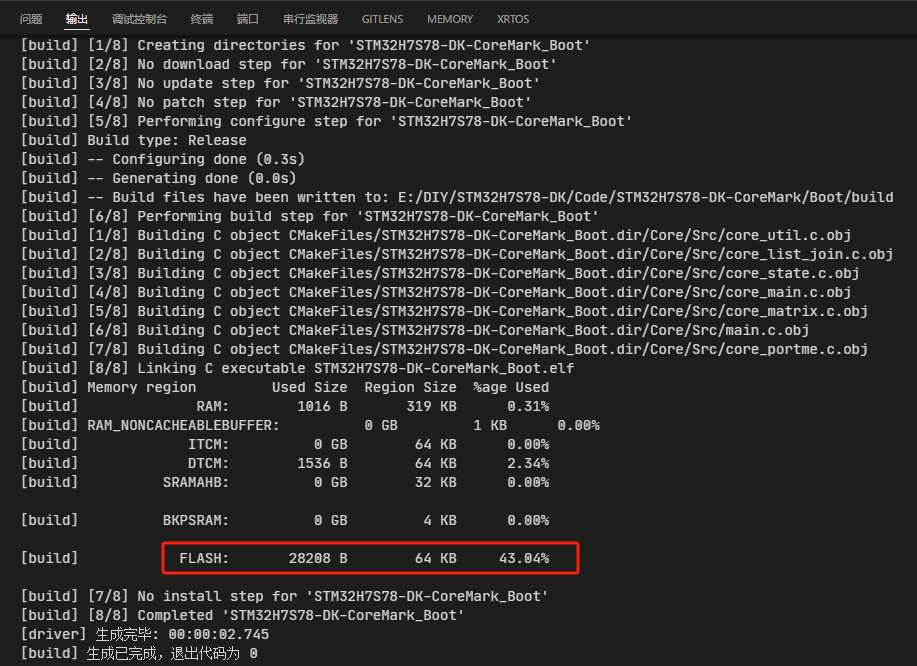
仔细观察4.7节的构建输出,可以看到Build type为Debug。接下来,将其修改为Release,尝试再次运行CoreMark。
修改Boot\CMakeLists.txt文件,将其中的CMAKE_BUILD_TYPE修改为Release:

再次编译,可看到FLASH占用少了很多:
下载、运行,可以看到串口输出如下:

这次的分数为230.81,但出现了报错,提示执行时间不足10秒。
修改前面提到的 core_portme.h 中的 ITERATIONS ,将其修改为 3200, 再次编译、下载、运行,串口输出如下:
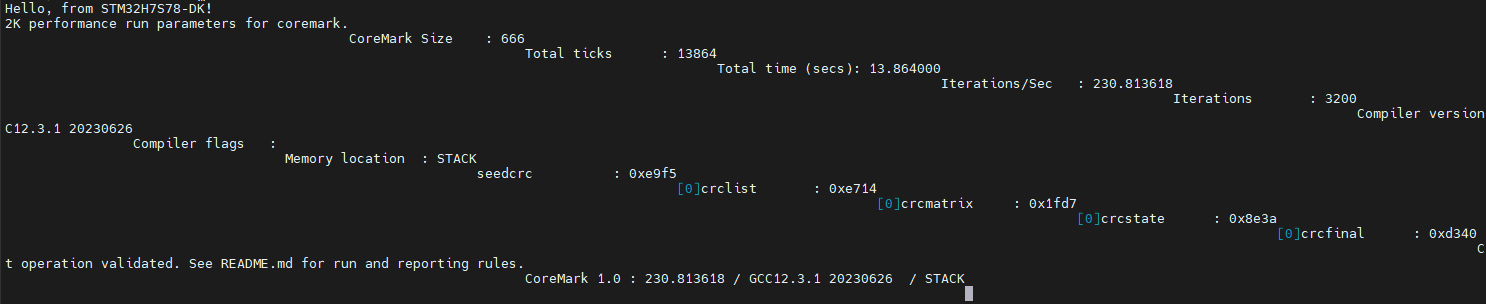
跑分还是230.81,执行时间变成了13秒多了。
5.2 修改编译优化选项
CMAKE_BUILD_TYPE修改为Release后,实际的编译优化选项是-Os,可以在生成的compile_commands.json中找到具体编译命令:

接下来,修改 Boot\CMakeLists.txt 文件,在其中添加如下代码段:
target_compile_options(${CMAKE_PROJECT_NAME} PRIVATE
-Ofast
)
顺便修改core_portme.h中的FLAGS_STR为"-Ofast"。
再次编译,可以看到FLASH占用如下:
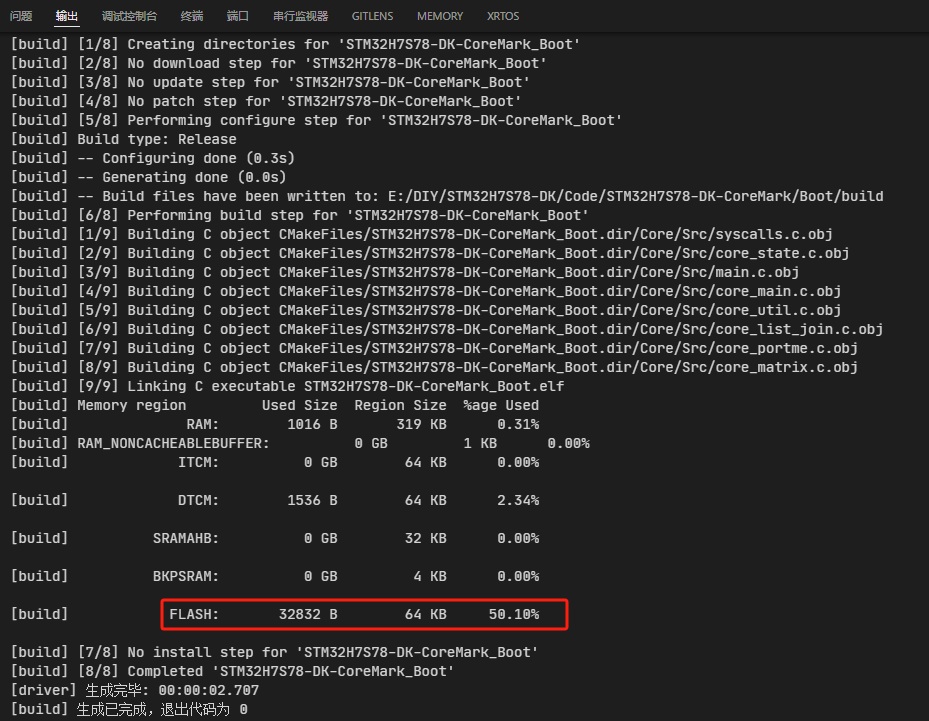
再次下载、运行,可以看到串口输出如下:

这次分数来到了447.43,可喜可贺!
然而,按照过往经验,600MHz Cortex-M7 CPU的CoreMark跑分不应该只有400多!
5.3 打开ICache和DCache
接下来,修改main.c,在main函数的开头添加如下代码:
/* USER CODE BEGIN 1 */
/* Enable the CPU Cache */
/* Enable I-Cache---------------------------------------------------------*/
SCB_EnableICache();
/* Enable D-Cache---------------------------------------------------------*/
SCB_EnableDCache();
/* USER CODE END 1 */
再次编译下载运行,可以看到串口输出如下:
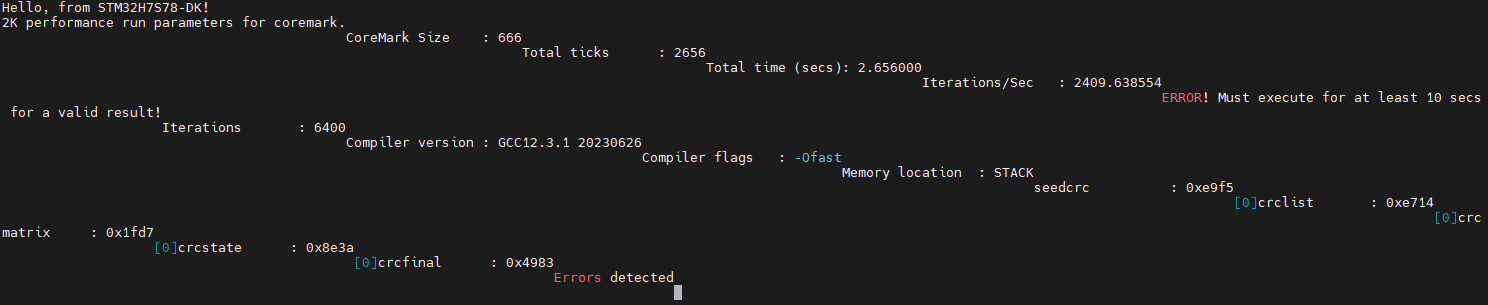
执行时间变成了2秒多,有报错。
重新修改 ITERATIONS 为 32000,再次编译下载运行,可以看到串口输出如下:
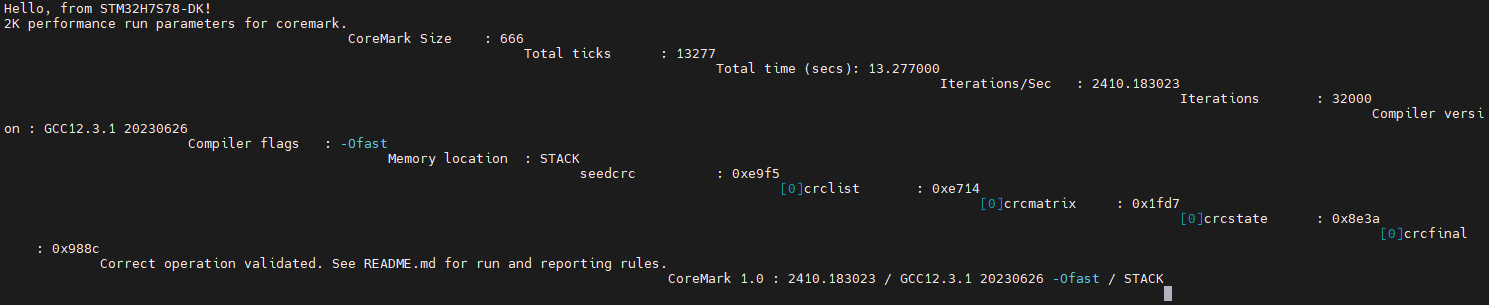
分数跑到了2410.18,好了,这次的分数差不多可以了。
5.4 解决换行不对齐问题
由于CoreMark结果输出使用的换行仅为\n,而在串口终端中,需要使用\r\n才能保证换行对齐。
为了让没有\r的一行文本输出也可以正常对齐,我们可以修改 syscalls.c 中的 _write 函数。
修改前为:
__attribute__((weak)) int _write(int file, char *ptr, int len)
{
(void)file;
int DataIdx;
for (DataIdx = 0; DataIdx < len; DataIdx++)
{
__io_putchar(*ptr++);
}
return len;
}
修改后为:
__attribute__((weak)) int _write(int file, char *ptr, int len)
{
(void)file;
int DataIdx;
static int cr = 0; // 是否遇到 \r 状态
for (DataIdx = 0; DataIdx < len; DataIdx++)
{
if (*ptr == '\r') {
cr = 1;
}
if (*ptr == '\n') {
if (!cr) {
__io_putchar('\r');
}
cr = 0;
}
__io_putchar(*ptr++);
}
return len;
}
完成上述修改后,再次编译下载运行,可以看到串口输出如下:
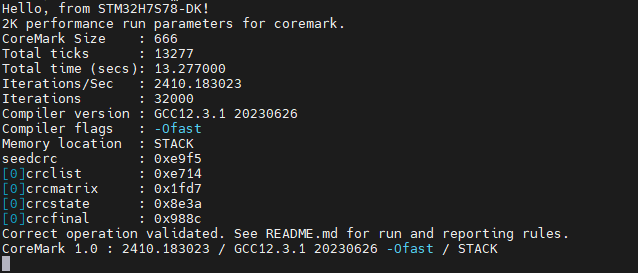
好了,这下看起舒服多了。
最终成绩:2410.183023 分,和CoreMark官网上查到的STM32H72x/73x系列使用IAR编译器的成绩差不多了:
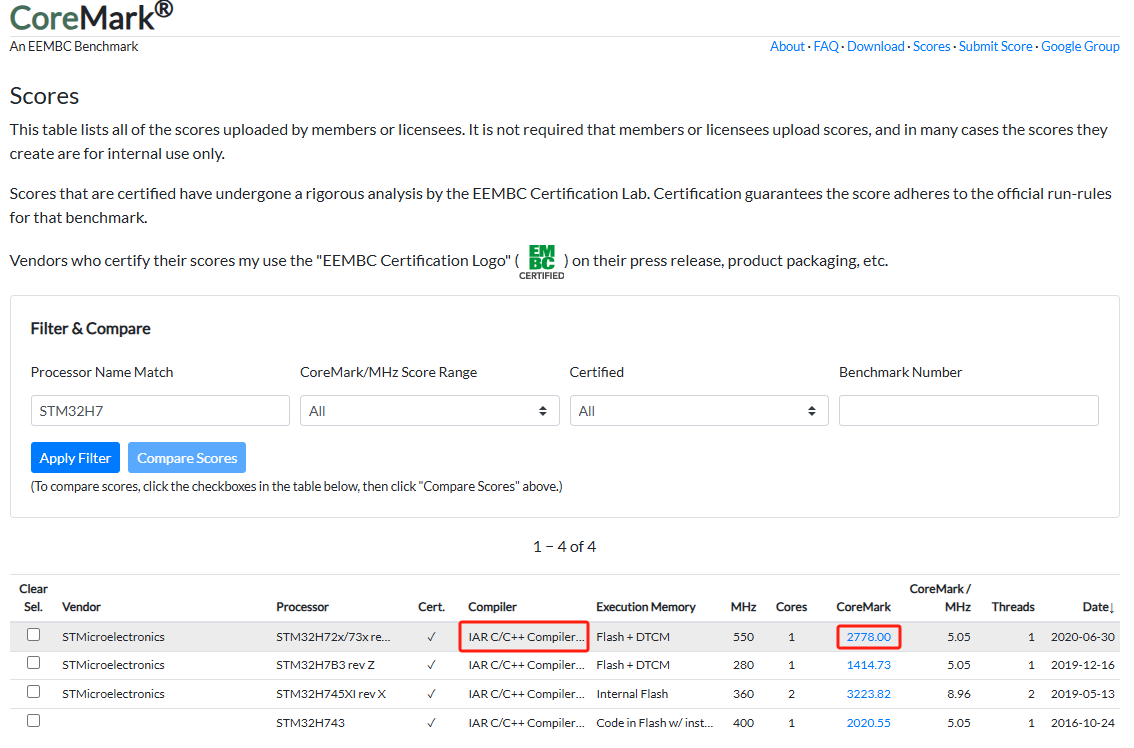
毕竟IAR是收费的,使用免费的GCC编译,能够跑到这个分数,已经可以了。
5.5 项目最终版源代码
整个项目代码,已分享至GitHub: https://github.com/xusiwei/STM32H7S78-DK-CoreMark.git
六、参考链接
- CoreMark官方页面: https://www.eembc.org/coremark/
- CoreMark源代码仓: https://github.com/eembc/coremark.git
- CoreMark分数查询网页: https://www.eembc.org/coremark/scores.php
- STM32H7S78-DK原理图: https://www.st.com.cn/resource/en/schematic_pack/mb1736-h7s7l8-d01-schematic.pdf
- STM32CubeMX下载页面: https://www.st.com.cn/zh/development-tools/stm32cubemx.html