1、LLaMA Factory 介绍
LLaMA Factory是一个在GitHub上开源的项目,该项目给自身的定位是:提供一个易于使用的大语言模型(LLM)微调框架,支持LLaMA、Baichuan、Qwen、ChatGLM等架构的大模型。更细致的看,该项目提供了从预训练、指令微调到RLHF阶段的开源微调解决方案。截止目前(2024年3月1日)支持约120+种不同的模型和内置了60+的数据集,同时封装出了非常高效和易用的开发者使用方法。而其中最让人喜欢的是其开发的LLaMA Board,这是一个零代码、可视化的一站式网页微调界面,它允许我们通过Web UI轻松设置各种微调过程中的超参数,且整个训练过程的实时进度都会在Web UI中进行同步更新。
简单理解,通过该项目我们只需下载相应的模型,并根据项目要求准备符合标准的微调数据集,即可快速开始微调过程,而这样的操作可以有效地将特定领域的知识注入到通用模型中,增强模型对特定知识领域的理解和认知能力,以达到“通用模型到垂直模型的快速转变”。
LLaMA Factory的GitHub地址如下:https://github.com/hiyouga/LLaMA-Factory/tree/main
LLaMA-Factory目前支持微调的模型及对应的参数量:
| 模型名 | 模型大小 | Template |
|---|---|---|
| Baichuan 2 | 7B/13B | baichuan2 |
| BLOOM/BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | - |
| ChatGLM3 | 6B | chatglm3 |
| Command R | 35B/104B | cohere |
| DeepSeek (Code/MoE) | 7B/16B/67B/236B | deepseek |
| Falcon | 7B/11B/40B/180B | falcon |
| Gemma/Gemma 2/CodeGemma | 2B/7B/9B/27B | gemma |
| GLM-4 | 9B | glm4 |
| InternLM2/InternLM2.5 | 7B/20B | intern2 |
| Llama | 7B/13B/33B/65B | - |
| Llama 2 | 7B/13B/70B | llama2 |
| Llama 3/Llama 3.1 | 8B/70B | llama3 |
| LLaVA-1.5 | 7B/13B | vicuna |
| MiniCPM | 1B/2B | cpm |
| Mistral/Mixtral | 7B/8x7B/8x22B | mistral |
| OLMo | 1B/7B | - |
| PaliGemma | 3B | gemma |
| Phi-1.5/Phi-2 | 1.3B/2.7B | - |
| Phi-3 | 4B/7B/14B | phi |
| Qwen/Qwen1.5/Qwen2 (Code/Math/MoE) | 0.5B/1.5B/4B/7B/14B/32B/72B/110B | qwen |
| StarCoder 2 | 3B/7B/15B | - |
| XVERSE | 7B/13B/65B | xverse |
| Yi/Yi-1.5 | 6B/9B/34B | yi |
| Yi-VL | 6B/34B | yi_vl |
| Yuan 2 | 2B/51B/102B | yuan |
可以看到,当前主流的开源大模型,包括ChatGLM3、Qwen的第一代以及最新的2版本,还有Biachuan2等,已经完全支持不同规模的参数量。针对LLaMA架构的系列模型,该项目已经基本实现了全面的适配。而其支持的训练方法,也主要围绕(增量)预训练、指令监督微调、奖励模型训练、PPO 训练和 DPO 训练展开,具体情况如下:
| 方法 | 全参数训练 | 部分参数训练 | LoRA | QLoRA |
|---|---|---|---|---|
| 预训练(Pre-Training) | ✅ | ✅ | ✅ | ✅ |
| 指令监督微调(Supervised Fine-Tuning) | ✅ | ✅ | ✅ | ✅ |
| 奖励模型训练(Reward Modeling) | ✅ | ✅ | ✅ | ✅ |
| PPO 训练(PPO Training) | ✅ | ✅ | ✅ | ✅ |
| DPO 训练(DPO Training) | ✅ | ✅ | ✅ | ✅ |
最后且最关键的一点需特别指出:虽然LLaMA-Factory项目允许我们在120余种大模型中灵活选择并快速开启微调工作,但运行特定参数量的模型是否可行,仍然取决于本地硬件资源是否充足。因此,在选择模型进行实践前,大家必须仔细参照下表,结合自己的服务器配置来决定,以避免因硬件资源不足导致的内存溢出等问题。不同模型参数在不同训练方法下的显存占用情况如下:
| 训练方法 | 精度 | 7B | 13B | 30B | 65B |
|---|---|---|---|---|---|
| 全参数 | 16 | 160GB | 320GB | 600GB | 1200GB |
| 部分参数 | 16 | 20GB | 40GB | 120GB | 240GB |
| LoRA | 16 | 16GB | 32GB | 80GB | 160GB |
| QLoRA | 8 | 10GB | 16GB | 40GB | 80GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB |
关于微调理论我们会在后面专门写文章解释
2、LLaMA-Factory私有化部署
作为GitHub上的开源项目,LLaMA-Factory的本地私有化部署过程与我们之前介绍的大模型部署大体相同,主要包括创建Python虚拟环境、下载项目文件及安装所需的依赖包。这一过程相对直观。但在开始部署之前,我们需要先了解LLaMA-Factory私有化部署对本地软硬件环境的具体要求:
- Python >= 3.8版本,建议Python3.10版本以上
- PyTorch >= 1.13.1版本,建议 Pytorch 版本为 2.2.1
- transformers >= 4.37.2,建议 transformers 版本为 4.38.1
- CUDA >= 11.6,建议CUDA版本为12.2
2.1 创建虚拟环境
创建LLaMA-Factory的Python虚拟环境
conda create --name llama_factory python==3.11

如上所示,新创建了一个名为LLaMA-Factory的Python虚拟环境,其Python版本为3.11。创建完成后,通过如下命令进入该虚拟环境,执行后续的操作:
conda activate llama_factory

2.2 安装Pytorch
建议先自己根据CUDA版本要求安装Pytorch,如果按照llama_factory官网安装默认是支持CPU的版本,地址:https://pytorch.org/get-started/previous-versions/**
这里根据自己电脑显卡驱动的CUDA版本要求,在Pytorch官网中找到适合自己的Pytorch安装命令。
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
待安装完成后,如果想要检查是否成功安装了GPU版本的PyTorch,可以通过几个简单的步骤在Python环境中进行验证:
import torch
print(torch.cuda.is_available())

如果输出是 True,则表示GPU版本的PyTorch已经安装成功并且可以使用CUDA,如果输出是False,则表明没有安装GPU版本的PyTorch,或者CUDA环境没有正确配置,此时根据教程,重新检查自己的执行过程。
2.3 下载LLaMA-Factory项目文件
进入LLaMA-Factory的官方Github,地址:https://github.com/hiyouga/LLaMA-Factory , 在 GitHub 上将项目文件下载到有两种方式:克隆 (Clone) 和 下载 ZIP 压缩包。推荐使用克隆 (Clone)的方式。我们首先在GitHub上找到其仓库的URL。
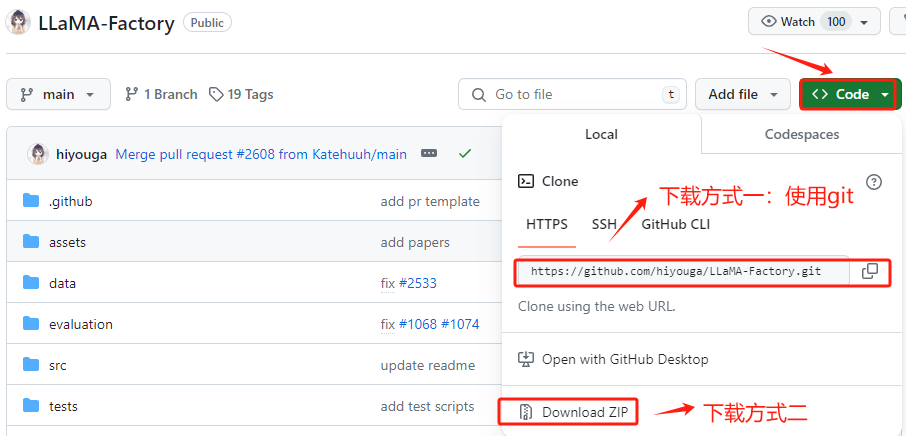
执行克隆命令,将LLaMA-Factory Github上的项目文件下载至本地的当前路径下,如下:
git clone https://github.com/hiyouga/LLaMA-Factory.git

如果网络不通或者其他原因无法下载,就下载zip文件解压到本地目录,或者上传到服务器。
建议在执行项目的依赖安装之前升级 pip 的版本,如果使用的是旧版本的 pip,可能无法安装一些最新的包,或者可能无法正确解析依赖关系。升级 pip 很简单,只需要运行命令如下命令:
python -m pip install --upgrade pip
2.4 安装LLaMA-Factory项目代码运行的项目依赖
在LLaMA-Factory中提供的 requirements.txt文件包含了项目运行所必需的所有 Python 包及其精确版本号。使用pip一次性安装所有必需的依赖,执行命令如下:
cd LLaMA-Factory
pip install -e ".[torch,metrics]"

如果不具备科学上网环境,还想通过在线的方式下载大模型,可以将模型下载源指向国内的ModelScope社区。这需要先中断当前的LLaMA-Board的后台服务,具体操作如下:
# Linux操作系统, 如果是 Windows 使用 `set USE_MODELSCOPE_HUB=1`
export USE_MODELSCOPE_HUB=1
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webui
通过上述步骤就已经完成了LLaMA-Factory模型的完整私有化部署过程。接下来,我们将详细介绍如何借助LLaMA-Factory项目执行ChaGLM3、Qwen和Baichuan2系列模型的微调和使用。
2.5 chat
先选择一个简单的模型进行测试,我们选择Qwen2-0.5B-Chat

可以在界面进行简单的对话

2.6 微调
选择数据集,注意我们启动命令时一定要在LLaMA-Factory目录下,不然数据会加载失败。选择预置的数据,支持预览查看,需要特定的数据格式,如果是自定义数据也需要按照这种格式来进行配置。

界面展示

训练过程

显存占用

显存全部占满
经过LoRA微调生成的Adapter权重和其相对应的配置文件,其存放在服务器下
/root/LLaMA-Factory-main/saves/Qwen2-0.5B-Chat/lora/train_2024-08-28-15-12-01

2.7 使用微调模型
对于LoRA微调,训练结束后如果想使用其微调后的模型,在LLaMA Board上也可以非常方便的加载,具体使用的过程如下:


通过上述步骤,我们可以完整地实现微调流程,且整个过程均可通过页面端完成,整体用户体验非常良好。大家也可以根据上述的流程,尝试对ChatGLM3-6B和Biachuan2系列模型进行LoRA或QLoRA微调,或者其他支持的系列模型。
2.8 合并导出
当然,除了分步加载微调后得到的Adapter 和 原始模型,在LLaMA Board上还可以一键进行模型权重的合并,具体操作如下:

导出后可以在主目录中查看


















![[Tomcat源码解析]——热部署和热加载原理](https://i-blog.csdnimg.cn/direct/99ae3f9b5ea746de86e653b4f150187f.png)
