基于 Transformer 的扩散模型日益完善,已被证明能够彻底改变文本到图像的生成方式。Transformer 的功能不仅能增强模型的可扩展性和性能,还会增加模型的复杂性。
在这种情况下,模型的复杂性越高,功耗和内存消耗也就越大。
例如,使用像 Stable Diffusion 3 这样的模型进行推理时,需要巨大的 GPU 内存,因为涉及到文本编码器、扩散主干和图像解码器等组件。这样的高内存需求可能会给使用消费级 GPU 的用户带来困扰,从而影响模型的可访问性和实验性。
这时,模型量化的作用就凸显出来了。想象一下,能够将资源密集型模型缩小到更易管理的大小,而不牺牲其效果。量化就像将高分辨率图像压缩成更紧凑的格式,将模型的参数转换为低精度表示。这不仅可以减少内存使用量,还能加快计算速度,使复杂模型更易于访问和使用。
在这篇文章中,你将了解 Quanto 的量化工具如何显著提高基于 Transformer 的扩散管道的内存效率。
Quanto 介绍:多功能 PyTorch 量化后端
量化是减少深度学习模型计算和内存需求的关键技术,使其更适合部署在消费设备上。通过使用低精度数据类型(如 8 位整数 (int8))代替 32 位浮点数 (float32),量化不仅可以降低内存存储要求,还可以针对特定硬件进行优化,例如 CUDA 设备上的 int8 或 float8 矩阵乘法。
Quanto是Hugging Face团队开发的一个Python库,它利用Transformer和XLM-RoBERTa技术进行跨语言文本转换。Quanto通过量化和解量化处理实现高效、泛化和易用的多语言任务解决,适用于信息检索、社交媒体监控等多种场景。
Quanto 是 Optimum 的新量化后端,旨在提供多功能且直接的量化过程。Quanto 以其对各种功能的全面支持而脱颖而出,确保与各种模型配置和设备的兼容性:
- Eager Mode 兼容性:与不可跟踪的模型无缝协作。
- 设备灵活性:量化模型可以部署在任何设备上,包括 CUDA 和 MPS。
- 自动集成:自动插入量化/反量化存根、功能操作和量化模块。
- 简化的工作流程:提供从浮点模型到动态和静态量化模型的轻松过渡。
- 序列化支持:兼容 PyTorch weight_only 和 Safetensors 格式。
- 加速矩阵乘法:支持 CUDA 设备上的各种量化格式(int8-int8、fp16-int4、bf16-int8、bf16-int4)。
- 广泛的支持:处理 int2、int4、int8 和 float8 权重和激活。
虽然许多工具专注于缩小大型 AI 模型,但 Quanto 的设计简单且适用于各种模型。
Quanto 工作流程
要使用 pip 安装 Quanto,请使用以下代码:-
!pip install optimum-quanto- 量化模型
以下代码将有助于将标准模型转换为量化模型
from optimum.quanto import quantize, qint8
quantize(model, weights=qint8, activations=qint8)- 校准
Quanto 的校准模式可确保量化参数根据模型中的实际数据分布进行调整,从而提高量化模型的准确性和效率。
from optimum.quanto import Calibration
with Calibration(momentum=0.9):
model(samples)- 量化感知训练
如果模型性能受到影响,可以对模型进行几个时期的调整,以提高模型性能。
import torch
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data).dequantize()
loss = torch.nn.functional.nll_loss(output, target)
loss.backward()
optimizer.step()- 冻结整数权重
冻结模型时,浮点权重将转换为量化权重。
from optimum.quanto import freeze
freeze(model)H100 基准测试研究
H100 GPU 是一款高性能显卡,专为要求苛刻的 AI 任务而设计,包括对大型模型(如变压器和扩散模型)进行训练和推理。以下是它被选为基准测试的原因:
- 顶级性能:H100 提供卓越的速度和功能,使其成为处理大型模型(如文本到图像和文本到视频生成管道)所需的复杂操作的理想选择。
- 支持 FP16:此 GPU 可高效处理 FP16(半精度浮点)中的计算,从而减少内存使用量并加快计算速度,而不会显著牺牲准确性。
- 高级硬件功能:H100 支持针对混合精度训练和推理的优化操作,使其成为旨在减小模型大小同时保持性能的量化技术的绝佳选择。
在这里,我们使用的是 DigitalOcean 旗下 Paperspace 平台的 H100 云服务器。该平台GPU 服务器按秒计费,并提供在线 notebook 环境,一键部署人工智能相关工具、框架与库,并支持模型部署服务,可直接将训练后的模型部署为 API 供其他应用调用。同时,该平台除了提供 H100 以外,还提供 H100x8、A6000、A5000等多种型号的 GPU。
如果需要咨询更多其它型号的 GPU 价格,可访问 DigitalOcean 文档或 Paperspace 官网。如果注册遇到问题,或需要更多存储资源和 GPU 资源,中国地区用户可以联系 DigitalOcean 中国区独家战略合作伙伴卓普云的销售团队和技术支持团队。
言归正传,在基准测试研究中,主要关注的是将新的量化工具 Quanto 应用于扩散模型。虽然量化在大型语言模型 (LLM) 的从业者中广为人知,但它在扩散模型中的使用并不多。Quanto 用于探索它是否可以在这些模型中节省内存,同时几乎不损失质量。
以下是研究内容:
环境设置:
- CUDA 12.2:使用的 CUDA 版本,对于在 H100 GPU 上运行计算至关重要。
- PyTorch 2.4.0:用于模型训练和推理的深度学习框架。
- 扩散器:用于构建和运行扩散模型的库,从特定提交安装以确保一致性。
- Quanto:量化工具,也从特定提交安装。
- FP16 中的计算:默认情况下,所有计算均在 FP16 中执行,以减少内存使用量并提高速度。但是,VAE(变分自动编码器)未量化,以避免潜在的数值不稳定性。
- 关注关键管道:在本研究中,从扩散器中选择了三个基于变压器的扩散管道。之所以选择这些管道,是因为它们代表了一些最先进的文本到图像生成模型,因此非常适合测试 Quanto 在保持模型质量的同时减少内存使用量的有效性。
- PixArt-Sigma
- 稳定扩散 3
- Aura Flow
通过使用 H100 GPU 并专注于这些关键模型,该研究旨在展示 Quanto 在量化方面弥合 LLM 和扩散模型之间差距的潜力,从而显著节省内存,同时将对性能的影响降至最低。
| 模型 | 检查点 | # 参数(十亿) |
| PixArt | https://huggingface.co/PixArt-alpha/PixArt-Sigma-XL-2-1024-MS | 0.611 |
| Stable Diffusion 3 | https://huggingface.co/stabilityai/stable-diffusion-3-medium-diffusers | 2.028 |
| Aura Flow | https://huggingface.co/fal/AuraFlow/ | 6.843 |
应用 Quanto 量化扩散管道
使用 Quanto 量化模型遵循一个简单的过程:
首先安装所需的软件包,这里我们安装 transformers、quanto、torch、sentencepiece。但请注意,您可能需要根据需要安装更多软件包。
!pip install transformers==4.35.0
!pip install quanto==0.0.11
!pip install torch==2.1.1
!pip install sentencepiece==0.2.0
!pip install optimum-quanto在要量化的模块上调用 quantize() 函数,指定要量化的组件。在这种情况下,只有参数被量化,而激活保持不变。参数被量化为 FP8 数据类型。最后,调用 freeze() 函数用新量化的参数替换原始参数。
from optimum.quanto import freeze, qfloat8, quantize
from diffusers import PixArtSigmaPipeline
import torch
pipeline = PixArtSigmaPipeline.from_pretrained("PixArt-alpha/PixArt-Sigma-XL-2-1024-MS", torch_dtype=torch.float16
).to("cuda")
quantize(pipeline.transformer, weights=qfloat8)
freeze(pipeline.transformer)一旦完成,就使用管道。
image = pipeline("ghibli style, a fantasy landscape with castles").images[0]
图:使用 FP8 中的扩散变压器生成的图像
以下代码可用于量化文本编码器。
quantize(pipeline.text_encoder, weights=qfloat8)
freeze(pipeline.text_encoder)文本编码器同样是一个变换器模型,因此也可以进行量化。通过量化文本编码器和扩散主干,可以显著节省内存。
LLM 管道
💡optimum-quanto 提供帮助类来量化、保存和重新加载 Hugging Face 量化模型。
以下代码将使用 Transformers 库加载预训练语言模型 (Meta-Llama-3-8B)。然后,它使用 Optimum Quanto 的 QuantizedModelForCausalLM 类对模型进行量化,具体来说就是将模型的权重转换为 qint4 数据类型。lm_head(输出层)被排除在量化之外,以保持其精度,从而确保最终输出质量保持较高水平。
from transformers import AutoModelForCausalLM
from optimum.quanto import QuantizedModelForCausalLM, qint4
model = AutoModelForCausalLM.from_pretrained('meta-llama/Meta-Llama-3-8B')
qmodel = QuantizedModelForCausalLM.quantize(model, weights=qint4, exclude='lm_head')# quantized model can be saved using save_pretrained
qmodel.save_pretrained('./Llama-3-8B-quantized')# reload the model using from_pretrained
from optimum.quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM.from_pretrained('Llama-3-8B-quantized')与 Transformers 的集成
Quanto 与 Hugging Face Transformers 库无缝集成。任何模型都可以通过 QuantoConfig 进行量化。
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = QuantoConfig(weights="int8")
quantized_model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config= quantization_config
)💡使用 Quanto,无论使用 CPU/GPU/MPS(Apple Silicon),你都可以量化和运行你的模型。
from transformers import AutoModelForSpeechSeq2Seq
model_id = "openai/whisper-large-v3"
quanto_config = QuantoConfig(weights="int8")
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="cuda",
quantization_config=quanto_config
)Quanto 中的张量:
- Quanto 的作用:Quanto 使用特殊的张量(数据结构),对其进行修改以适应较小的数据类型,如 int8 或 float8。这使模型更节省内存,运行速度更快。
- 转换过程:
- 对于浮点数,它只使用 PyTorch 的内置转换。
- 对于整数,它会对数字进行四舍五入以使其适合较小的数据类型。
- 准确性:Quanto 试图通过避免过多的极端值(太大或太小)来保持转换的准确性,因为这些极端值可能会扭曲模型的性能。
- 优化操作:使用这些较小的数据类型(较低位宽)可以使模型运行得更快,因为这些类型的操作更快。
Quanto 中的模块:
- 替换 Torch 模块:Quanto 可以将常规 PyTorch 组件替换为适用于这些较小张量的特殊 Quanto 版本。
- 权重转换:当模型仍在微调时,权重(模型的可调参数)会动态转换,这可能会使速度稍微变慢。但是一旦模型最终确定(冻结),此转换就会停止。
- 偏差:偏差(另一组模型参数)不会被转换,因为转换它们会降低准确性或需要非常高的精度,从而导致效率低下。
- 激活:模型的激活(中间输出)也会转换为较小的数据类型,但只有在校准模型以找到最佳转换设置后才会转换。
可量化的模块:
- 线性层:这些是模型中的全连接层,其中权重始终量化,但偏差保持原样。
- Conv2D 层:这些是图像处理中经常使用的卷积层。在这里,权重也始终量化,而偏差则不量化。
- LayerNorm:这会对模型中的数据进行规范化。在 Quanto 中,输出可以量化,但权重和偏差保持原样。
这种设置允许模型变得更小、更快,同时仍保持良好的准确性。
研究的最终观察结果
量化扩散模型中的文本编码器(例如稳定扩散中使用的模型)会显著影响性能和内存效率。对于使用三个不同文本编码器的稳定扩散 3,与量化这些编码器相关的观察结果如下:
- 量化第二个文本编码器:这种方法效果不佳,可能是由于第二个编码器的特定特性。
- 量化第一个文本编码器 (CLIPTextModelWithProjection):建议使用此选项,并且通常有效,因为第一个编码器的量化在内存节省和性能之间提供了良好的平衡。
- 量化第三个文本编码器 (T5EncoderModel):也建议使用此方法。量化第三个编码器可以节省大量内存,而不会显著影响模型的性能。
- 量化第一个和第三个文本编码器:结合第一个和第三个文本编码器的量化可以成为最大化内存效率同时保持可接受性能水平的良好策略。
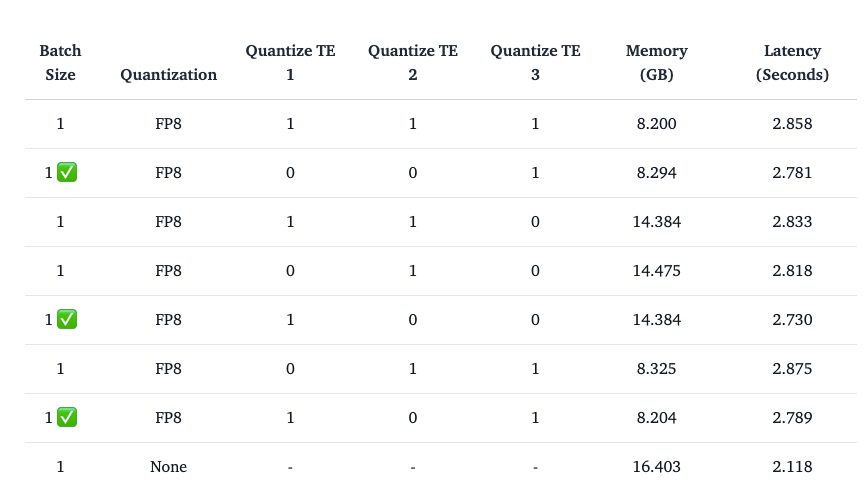
在内存节省方面,该表详细说明了通过应用每种量化策略可以节省多少内存,特别关注量化不同文本编码器组合之间的相对利益和权衡(图片来源)
- 在所有情况下量化扩散变换器可确保观察到的内存节省主要归因于文本编码器量化。
- 当考虑强大的 GPU(例如 H100 或 4090)时,使用 bfloat16 会更快。
- 由于高效的整数运算和硬件优化,qint8 通常推理速度更快。
- 融合 QKV 投影会加厚 int8 内核,从而通过减少运算次数和利用高效的数据处理进一步优化计算。
- 在 H100 GPU 上使用带有 bfloat16 的 qint4 时,内存使用率会有所提高,因为 qint4 每个值仅使用 4 位,从而减少了存储权重所需的内存量。但是,这是以增加推理延迟为代价的。这是因为 H100 GPU 仍然不支持使用 4 位整数(int4)的计算。尽管权重以压缩的 4 位格式存储,但实际计算仍以 bfloat16(16 位浮点格式)执行,这意味着硬件必须处理更复杂的操作,从而导致处理时间变慢。
结论
Quanto 为 PyTorch 提供了强大的量化后端,通过将权重转换为较低精度格式来优化模型性能。通过支持 qint8 和 qint4 等技术,Quanto 减少了内存消耗并加快了推理速度。此外,Quanto 可在不同设备(CPU、GPU、MPS)上工作,并与各种设置兼容。但是,在 MPS 设备上,使用 float8 会导致错误。
总体而言,Quanto 可以更有效地部署深度学习模型,在内存节省和性能权衡之间取得平衡。
参考文献
- 使用 Quanto 和扩散器的内存高效扩散变换器
- Quanto:Optimum 的 PyTorch 量化后端
- quanto 0.2.0
- Optimum Quanto Github