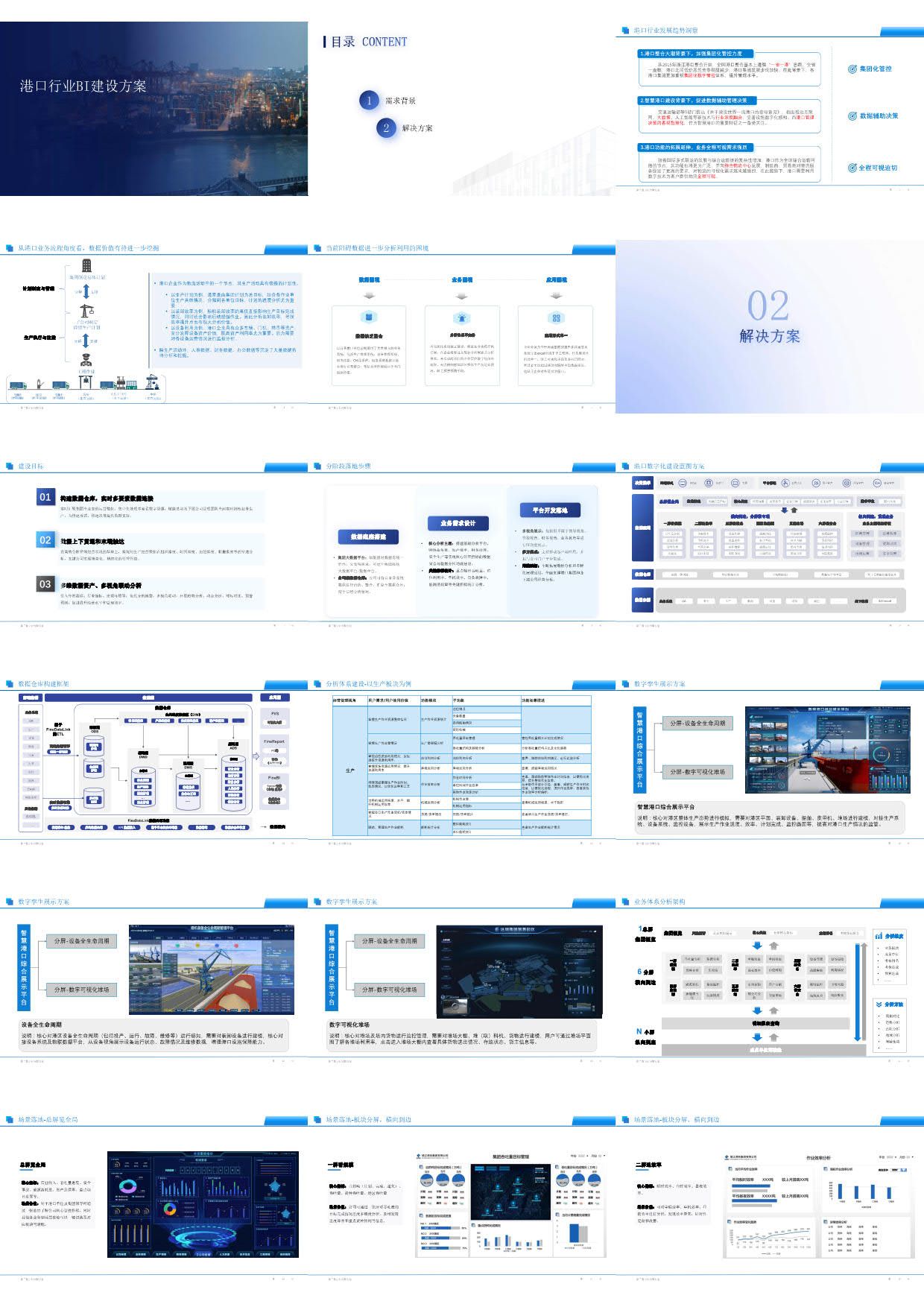
C++与OpenCV联袂打造:智能视觉识别技术的实践与探索
- 1. 环境设置与准备工作
- 1.1 安装OpenCV和配置开发环境
- 1.1.1 下载OpenCV
- 1.1.2 安装OpenCV
- Windows系统
- Linux系统
- 1.1.3 配置OpenCV库
- 1.2 C++编译器的选择与配置
- 1.2.1 Windows系统
- 1.2.2 Linux系统
- 1.2.3 编译器配置
- 1.3 选择合适的集成开发环境(IDE)或文本编辑器
- 1.3.1 集成开发环境(IDE)
- 1.3.2 文本编辑器
- 1.3.3 配置IDE或编辑器
- 2. 图像获取与预处理
- 2.1 使用OpenCV读取图像和视频流
- 2.1.1 图像的读取
- 2.1.2 视频流的读取
- 2.2 图像预处理技术
- 2.2.1 图像灰度化
- 2.2.2 图像滤波
- 2.2.3 边缘检测
- 3. 物体检测与识别
- 3.1 目标检测方法概述
- 3.1.1 Haar级联检测器
- 3.1.2 基于深度学习的检测器
- 3.2 实现物体检测的步骤和算法
- 3.2.1 使用预训练模型
- 3.2.2 自定义训练模型
- 4. 特征提取与描述
- 4.1 特征提取概述
- 4.1.1 关键点检测
- 4.1.2 特征描述符计算
- 4.2 使用SIFT进行特征提取与描述
- 4.2.1 初始化SIFT检测器
- 4.3 使用SURF进行特征提取与描述
- 4.3.1 初始化SURF检测器
- 4.4 使用ORB进行特征提取与描述
- 4.4.1 初始化ORB检测器
- 4.5 特征描述符的应用
- 4.5.1 描述符匹配示例
- 5. 图像匹配与识别
- 5.1 图像特征匹配算法
- 5.1.1 基于特征的匹配
- 5.1.1.1 特征点检测与描述
- 5.1.1.2 匹配优化
- 5.1.2 模板匹配
- 5.1.2.1 实现模板匹配
- 5.2 实现图像识别的方法和技术
- 5.2.1 静态图像识别
- 5.2.1.1 物体检测
- 5.2.1.2 图像分类
- 5.2.2 实时图像识别
- 5.2.2.1 实时物体检测
- 6. 应用与性能优化
- 6.1 实际场景中的应用考虑
- 6.1.1 应用场景的复杂性
- 6.1.2 硬件资源的限制
- 6.1.3 环境光照与背景变化
- 6.1.4 实时性要求
- 6.2 性能优化策略和技术
- 6.2.1 并行处理
- 6.2.1.1 OpenMP
- 6.2.1.2 C++11线程
- 6.2.2 GPU加速
- 6.2.2.1 使用OpenCV的CUDA模块
- 6.2.2.2 使用深度学习框架的GPU加速
- 6.2.3 算法优化
- 6.2.3.1 减少计算复杂度
- 6.2.3.2 数据预处理
- 6.2.3.3 硬件加速优化
1. 环境设置与准备工作
在使用C++结合OpenCV进行智能视觉识别技术的开发之前,正确设置和配置开发环境是至关重要的一步。这不仅保证了开发过程的顺利进行,还能有效提升代码的执行效率和程序的稳定性。本文将详细介绍环境设置的关键步骤,包括OpenCV的安装与配置、C++编译器的选择与配置,以及集成开发环境(IDE)或文本编辑器的选择。

1.1 安装OpenCV和配置开发环境
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,广泛用于图像处理、计算机视觉以及机器学习应用。为了在C++中使用OpenCV,我们需要完成以下几个步骤:
1.1.1 下载OpenCV
- 访问OpenCV官网:首先,前往OpenCV的官方网站 OpenCV官网。
- 选择版本:在下载页面上选择适合你操作系统的OpenCV版本。通常情况下,选择最新的稳定版本可以获得最新的功能和修复。
- 下载压缩包:下载适合你平台的压缩包(例如,Windows平台下的
.zip文件,或Linux平台下的.tar.gz文件)。
1.1.2 安装OpenCV
Windows系统
- 解压文件:将下载的OpenCV压缩包解压到你希望安装的位置。例如,你可以将其解压到
C:\opencv。 - 配置环境变量:
- 右键点击“计算机”或“此电脑”,选择“属性”。
- 选择“高级系统设置”,然后点击“环境变量”。
- 在“系统变量”中,找到“Path”变量,点击“编辑”。
- 添加OpenCV的
bin目录路径,例如C:\opencv\build\x64\vc15\bin。
- 配置CMake:如果你需要从源码编译OpenCV,可以使用CMake工具配置编译选项。下载并安装 CMake,然后使用CMake GUI配置OpenCV源代码的编译选项,生成适合你的编译器的项目文件。
Linux系统
- 安装依赖:使用包管理器安装OpenCV的依赖项。例如,在Ubuntu系统中可以运行以下命令:
sudo apt-get update sudo apt-get install build-essential cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev - 下载源码:克隆OpenCV源码库:
git clone https://github.com/opencv/opencv.git cd opencv - 编译和安装:
mkdir build cd build cmake .. make -j4 sudo make install
1.1.3 配置OpenCV库
配置OpenCV库路径以确保编译器能够找到OpenCV的头文件和库文件:
- Windows系统:在你的C++项目中,设置编译器的包含目录(Include Directories)和库目录(Library Directories)。这可以在项目的属性设置中完成,添加OpenCV的
include目录和lib目录。 - Linux系统:在你的Makefile或CMakeLists.txt中,设置OpenCV的包含目录和库目录。例如:
find_package(OpenCV REQUIRED) include_directories(${OpenCV_INCLUDE_DIRS}) target_link_libraries(your_target ${OpenCV_LIBS})
1.2 C++编译器的选择与配置
C++编译器的选择对程序的编译和运行有直接影响。不同操作系统和开发环境有不同的编译器选项。
1.2.1 Windows系统
在Windows上,常用的C++编译器包括Microsoft Visual Studio、MinGW和Clang:
- Microsoft Visual Studio:这是Windows上最常用的编译器之一。它提供了强大的集成开发环境(IDE)和调试工具。可以从 Visual Studio官网 下载并安装。
- MinGW:MinGW(Minimalist GNU for Windows)是一个将GNU工具链移植到Windows上的编译器。可以从 MinGW官网 下载并安装。
- Clang:Clang是一个开源的编译器前端,可以与LLVM一起使用。可以从 LLVM官网 下载。
1.2.2 Linux系统
在Linux上,GCC(GNU Compiler Collection)是最常用的C++编译器:
- GCC:可以通过系统的包管理器安装。例如,在Ubuntu上,可以使用以下命令:
sudo apt-get install g++
1.2.3 编译器配置
无论选择哪个编译器,都需要配置编译选项来适应OpenCV的使用:
- Windows系统:在编译选项中添加
-I选项来指定OpenCV的头文件路径,添加-L选项来指定OpenCV的库文件路径,并使用-l选项来链接OpenCV库。 - Linux系统:在编译命令中使用
pkg-config工具来自动配置OpenCV的编译选项。例如:g++ -o your_program your_program.cpp `pkg-config --cflags --libs opencv4`
1.3 选择合适的集成开发环境(IDE)或文本编辑器
IDE和文本编辑器的选择会影响你的开发效率和代码质量。以下是一些常用的IDE和文本编辑器推荐:
1.3.1 集成开发环境(IDE)
- Microsoft Visual Studio:功能强大的IDE,适合Windows开发。提供了完善的调试工具、代码提示和自动补全功能,非常适合大型项目的开发。
- CLion:由JetBrains开发的跨平台IDE,支持CMake和各种C++标准,适合Linux、Windows和macOS系统。具有智能代码分析和调试功能。
- Code::Blocks:轻量级的开源IDE,支持多种编译器,适合简单项目和跨平台开发。
1.3.2 文本编辑器
- Visual Studio Code:轻量级的代码编辑器,支持多种插件扩展,包括C++开发和OpenCV支持。适合快速开发和调试。
- Sublime Text:强大的文本编辑器,支持多种语言和插件。虽然不是专门的IDE,但可以通过插件实现C++开发功能。
- Atom:由GitHub开发的开源编辑器,支持丰富的插件系统和自定义功能。
1.3.3 配置IDE或编辑器
无论选择哪种IDE或编辑器,都需要进行一些配置以支持OpenCV和C++开发:
- 配置编译器路径:在IDE的设置中,配置编译器的路径和编译选项,以确保能够正确编译和链接OpenCV库。
- 设置项目路径:在IDE中配置项目路径,包括头文件路径、库文件路径等。
- 安装必要插件:如果使用文本编辑器,需要安装必要的插件来支持C++语法高亮、代码补全和调试功能。
通过以上步骤,你将能够顺利设置和配置你的C++与OpenCV开发环境,为智能视觉识别技术的开发奠定坚实的基础。合理选择和配置开发工具可以显著提升开发效率和代码质量,从而实现更高效的项目开发。
2. 图像获取与预处理
在计算机视觉和图像处理领域,图像获取与预处理是实现高效视觉识别系统的关键步骤。这一部分涉及如何使用OpenCV库来读取图像和视频流,以及对图像进行必要的预处理,以提高后续处理的准确性和效率。以下将详细讲解这一过程的各个方面。
2.1 使用OpenCV读取图像和视频流
OpenCV(Open Source Computer Vision Library)是一个广泛使用的计算机视觉库,支持多种图像和视频处理操作。在C++中使用OpenCV进行图像和视频流的读取非常直接。
2.1.1 图像的读取
要读取图像文件,可以使用OpenCV中的cv::imread函数。该函数支持多种图像格式,如JPG、PNG、BMP等。下面是一个简单的示例,演示如何使用cv::imread读取图像并显示它:
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 读取图像
cv::Mat image = cv::imread("example.jpg");
// 检查图像是否成功加载
if (image.empty()) {
std::cerr << "Error: Unable to load image!" << std::endl;
return -1;
}
// 显示图像
cv::imshow("Loaded Image", image);
cv::waitKey(0); // 等待用户按键
return 0;
}
在这个示例中,cv::imread从指定路径加载图像,并将其存储在cv::Mat对象中。如果图像加载失败,将打印错误信息。cv::imshow用于显示图像,cv::waitKey函数用于等待用户操作。
2.1.2 视频流的读取
读取视频流略微复杂一些。使用cv::VideoCapture类可以实现对视频文件或实时摄像头流的读取。以下是一个简单的示例,演示如何从摄像头读取视频流并显示每一帧:
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 打开默认摄像头(设备ID为0)
cv::VideoCapture cap(0);
// 检查摄像头是否成功打开
if (!cap.isOpened()) {
std::cerr << "Error: Unable to open camera!" << std::endl;
return -1;
}
cv::Mat frame;
while (true) {
// 从摄像头捕获一帧
cap >> frame;
// 检查帧是否成功捕获
if (frame.empty()) {
std::cerr << "Error: Empty frame captured!" << std::endl;
break;
}
// 显示帧
cv::imshow("Video Stream", frame);
// 按 'q' 键退出
if (cv::waitKey(30) >= 0) {
break;
}
}
return 0;
}
在这个示例中,cv::VideoCapture用于打开摄像头。通过循环不断读取视频帧,并使用cv::imshow显示。cv::waitKey用于设定帧显示的延迟,并检查用户是否按下退出键(‘q’)。
2.2 图像预处理技术
图像预处理是计算机视觉系统中的重要步骤,目的是提高图像质量,为后续处理做准备。常见的预处理技术包括灰度化、滤波和边缘检测。
2.2.1 图像灰度化
图像灰度化是将彩色图像转换为灰度图像的过程。灰度图像具有单一的颜色通道,通常用于简化图像处理和分析任务。OpenCV提供了cv::cvtColor函数来实现这一操作:
#include <opencv2/opencv.hpp>
int main() {
// 读取彩色图像
cv::Mat colorImage = cv::imread("example.jpg");
// 转换为灰度图像
cv::Mat grayImage;
cv::cvtColor(colorImage, grayImage, cv::COLOR_BGR2GRAY);
// 显示灰度图像
cv::imshow("Gray Image", grayImage);
cv::waitKey(0);
return 0;
}
在这个示例中,cv::cvtColor将彩色图像转换为灰度图像,其中cv::COLOR_BGR2GRAY是转换代码,表示从BGR到灰度的转换。
2.2.2 图像滤波
滤波操作用于去除图像中的噪声或模糊图像。常见的滤波技术包括均值滤波、高斯滤波和中值滤波。OpenCV提供了多种滤波函数,如cv::GaussianBlur和cv::medianBlur。
高斯滤波:
#include <opencv2/opencv.hpp>
int main() {
// 读取图像
cv::Mat image = cv::imread("example.jpg");
// 高斯滤波
cv::Mat blurredImage;
cv::GaussianBlur(image, blurredImage, cv::Size(15, 15), 0);
// 显示滤波后的图像
cv::imshow("Gaussian Blurred Image", blurredImage);
cv::waitKey(0);
return 0;
}
在此示例中,cv::GaussianBlur用于对图像进行高斯模糊处理。参数cv::Size(15, 15)定义了高斯核的大小,0表示自动计算标准差。
中值滤波:
#include <opencv2/opencv.hpp>
int main() {
// 读取图像
cv::Mat image = cv::imread("example.jpg");
// 中值滤波
cv::Mat medianBlurredImage;
cv::medianBlur(image, medianBlurredImage, 15);
// 显示滤波后的图像
cv::imshow("Median Blurred Image", medianBlurredImage);
cv::waitKey(0);
return 0;
}
在此示例中,cv::medianBlur用于对图像进行中值滤波。参数15定义了滤波器的大小。
2.2.3 边缘检测
边缘检测是识别图像中物体边界的技术。常见的边缘检测算法包括Sobel算子、Canny边缘检测等。OpenCV提供了cv::Canny函数来实现Canny边缘检测:
#include <opencv2/opencv.hpp>
int main() {
// 读取图像并转换为灰度图像
cv::Mat image = cv::imread("example.jpg");
cv::Mat grayImage, edges;
cv::cvtColor(image, grayImage, cv::COLOR_BGR2GRAY);
// 使用Canny算法进行边缘检测
cv::Canny(grayImage, edges, 100, 200);
// 显示边缘检测结果
cv::imshow("Canny Edges", edges);
cv::waitKey(0);
return 0;
}
在这个示例中,cv::Canny用于检测图像中的边缘。参数100和200是Canny算法的低阈值和高阈值,用于确定边缘的检测灵敏度。
3. 物体检测与识别
3.1 目标检测方法概述
3.1.1 Haar级联检测器
Haar级联检测器是一种传统的物体检测方法,广泛应用于面部检测等任务。其核心思想是利用Haar特征进行特征提取,通过级联分类器实现高效的检测。
原理简介
Haar特征是基于图像区域内的灰度差异计算的特征,这些特征可以表示为矩形区域的加权和。级联分类器则是由一系列简单的分类器构成的,每个分类器负责在不同的特征空间进行判断。通过级联的方式,首先用较简单的分类器筛选掉大部分负样本,然后再用更复杂的分类器对剩余的样本进行更精细的判断,从而实现高效的检测。
OpenCV中的实现
在OpenCV中,Haar级联检测器的实现相对简单。以下是一个基于OpenCV的示例代码,用于检测图像中的人脸:
#include <opencv2/opencv.hpp>
int main() {
// 加载分类器
cv::CascadeClassifier face_cascade;
if (!face_cascade.load("haarcascade_frontalface_default.xml")) {
std::cerr << "Error loading cascade classifier" << std::endl;
return -1;
}
// 读取图像
cv::Mat img = cv::imread("input.jpg");
if (img.empty()) {
std::cerr << "Error loading image" << std::endl;
return -1;
}
// 转换为灰度图像
cv::Mat gray;
cv::cvtColor(img, gray, cv::COLOR_BGR2GRAY);
// 检测人脸
std::vector<cv::Rect> faces;
face_cascade.detectMultiScale(gray, faces);
// 绘制检测结果
for (const auto& face : faces) {
cv::rectangle(img, face, cv::Scalar(255, 0, 0), 2);
}
// 显示结果
cv::imshow("Detected Faces", img);
cv::waitKey(0);
return 0;
}
在上面的代码中,我们首先加载了预训练的Haar级联分类器,并使用它对图像中的人脸进行检测。
3.1.2 基于深度学习的检测器
与传统的Haar级联方法相比,基于深度学习的检测器(如YOLO、SSD、Faster R-CNN)提供了更高的检测精度和鲁棒性。这些方法通常基于卷积神经网络(CNN)来提取图像特征,并进行目标检测。
YOLO(You Only Look Once)
YOLO是一种单阶段目标检测方法,能够在一次前向传递中同时进行目标定位和分类。其主要优点是速度快,适用于实时检测任务。
Faster R-CNN
Faster R-CNN是区域卷积神经网络(R-CNN)的改进版本,引入了区域提议网络(RPN),使得目标检测速度和精度得到显著提升。Faster R-CNN先使用RPN生成目标区域提议,再通过分类器对这些区域进行进一步的识别。
SSD(Single Shot MultiBox Detector)
SSD也是一种单阶段检测器,它通过不同尺度的特征图进行目标检测,从而在不同大小的目标上获得较好的检测效果。
OpenCV中的实现
OpenCV提供了对这些深度学习检测器的支持。以下是一个基于YOLO的物体检测示例代码:
#include <opencv2/opencv.hpp>
int main() {
// 加载YOLO模型和配置文件
cv::dnn::Net net = cv::dnn::readNetFromDarknet("yolov3.cfg", "yolov3.weights");
// 读取图像
cv::Mat img = cv::imread("input.jpg");
if (img.empty()) {
std::cerr << "Error loading image" << std::endl;
return -1;
}
// 创建Blob并进行前向传播
cv::Mat blob;
cv::dnn::blobFromImage(img, blob, 1.0 / 255.0, cv::Size(416, 416), cv::Scalar(0, 0, 0), true, false);
net.setInput(blob);
std::vector<cv::Mat> outs;
net.forward(outs, net.getUnconnectedOutLayersNames());
// 解析输出结果
for (const auto& output : outs) {
for (int i = 0; i < output.rows; ++i) {
cv::Mat scores = output.row(i).colRange(5, output.cols);
cv::Point classId;
double confidence;
cv::minMaxLoc(scores, 0, &confidence, 0, &classId);
if (confidence > 0.5) {
// 计算边界框
int centerX = static_cast<int>(output.at<float>(i, 0) * img.cols);
int centerY = static_cast<int>(output.at<float>(i, 1) * img.rows);
int w = static_cast<int>(output.at<float>(i, 2) * img.cols);
int h = static_cast<int>(output.at<float>(i, 3) * img.rows);
cv::Rect box(centerX - w / 2, centerY - h / 2, w, h);
cv::rectangle(img, box, cv::Scalar(0, 255, 0), 2);
}
}
}
// 显示结果
cv::imshow("Detected Objects", img);
cv::waitKey(0);
return 0;
}
在上述代码中,我们使用YOLO模型进行物体检测。通过加载预训练的模型文件和权重文件,我们可以对输入图像进行检测并绘制边界框。
3.2 实现物体检测的步骤和算法
3.2.1 使用预训练模型
使用预训练模型是实现物体检测的便捷方式,特别是在数据集有限或者计算资源受限的情况下。预训练模型已经在大量数据上进行过训练,并且能够识别各种常见的目标。
步骤
- 选择合适的预训练模型:根据应用需求选择合适的模型,如YOLO、Faster R-CNN等。
- 加载模型和权重文件:使用OpenCV的
cv::dnn::readNetFromDarknet或类似函数加载模型文件和权重。 - 准备输入图像:将输入图像转换为模型所需的格式(如Blob)。
- 执行前向传播:通过模型进行前向传播以获得检测结果。
- 解析检测结果:从模型的输出中提取目标位置和类别信息。
- 后处理:对检测结果进行过滤和调整,如非极大值抑制(NMS)以去除冗余检测框。
示例代码
// 省略部分与前述相同的代码...
// 解析输出结果
for (const auto& output : outs) {
for (int i = 0; i < output.rows; ++i) {
cv::Mat scores = output.row(i).colRange(5, output.cols);
cv::Point classId;
double confidence;
cv::minMaxLoc(scores, 0, &confidence, 0, &classId);
if (confidence > 0.5) {
// 计算边界框
int centerX = static_cast<int>(output.at<float>(i, 0) * img.cols);
int centerY = static_cast<int>(output.at<float>(i, 1) * img.rows);
int w = static_cast<int>(output.at<float>(i, 2) * img.cols);
int h = static_cast<int>(output.at<float>(i, 3) * img.rows);
cv::Rect box(centerX - w / 2, centerY - h / 2, w, h);
cv::rectangle(img, box, cv::Scalar(0, 255, 0), 2);
}
}
}
3.2.2 自定义训练模型
对于一些特定的应用场景,使用预训练模型可能无法满足需求,这时可以考虑自定义训练模型。自定义训练模型可以提高对特定目标的检测精度,但需要大量的标注数据和计算资源。
步骤
- 准备数据集:收集并标注包含目标物体的图
像数据集。标注信息可以包括目标的边界框和类别。
2. 选择训练框架:选择适合的深度学习框架,如TensorFlow、PyTorch等,并设计合适的网络结构。
3. 训练模型:使用准备好的数据集训练模型。训练过程中需要调整超参数,监控训练进度,并进行模型验证。
4. 保存模型:训练完成后保存模型权重,以便后续使用。
5. 集成模型:将训练好的模型集成到C++项目中,使用OpenCV的cv::dnn模块进行加载和推理。
示例代码
以下代码展示了如何在C++中加载自定义训练的YOLO模型并进行推理:
#include <opencv2/opencv.hpp>
int main() {
// 加载自定义训练的YOLO模型和配置文件
cv::dnn::Net net = cv::dnn::readNetFromDarknet("custom_yolov3.cfg", "custom_yolov3.weights");
// 读取图像
cv::Mat img = cv::imread("input.jpg");
if (img.empty()) {
std::cerr << "Error loading image" << std::endl;
return -1;
}
// 创建Blob并进行前向传播
cv::Mat blob;
cv::dnn::blobFromImage(img, blob, 1.0 / 255.0, cv::Size(416, 416), cv::Scalar(0, 0, 0), true, false);
net.setInput(blob);
std::vector<cv::Mat> outs;
net.forward(outs, net.getUnconnectedOutLayersNames());
// 解析输出结果
for (const auto& output : outs) {
for (int i = 0; i < output.rows; ++i) {
cv::Mat scores = output.row(i).colRange(5, output.cols);
cv::Point classId;
double confidence;
cv::minMaxLoc(scores, 0, &confidence, 0, &classId);
if (confidence > 0.5) {
// 计算边界框
int centerX = static_cast<int>(output.at<float>(i, 0) * img.cols);
int centerY = static_cast<int>(output.at<float>(i, 1) * img.rows);
int w = static_cast<int>(output.at<float>(i, 2) * img.cols);
int h = static_cast<int>(output.at<float>(i, 3) * img.rows);
cv::Rect box(centerX - w / 2, centerY - h / 2, w, h);
cv::rectangle(img, box, cv::Scalar(0, 255, 0), 2);
}
}
}
// 显示结果
cv::imshow("Detected Objects", img);
cv::waitKey(0);
return 0;
}
通过以上步骤和示例代码,可以实现自定义训练模型的物体检测。这个过程虽然更加复杂,但可以为特定应用提供更高的精度和适应性。
4. 特征提取与描述
在计算机视觉中,特征提取与描述是实现物体识别、匹配以及跟踪等功能的基础。利用特征描述符可以将图像中的关键点转换为独特的向量表示,这些向量能够有效地描述物体的外观特征。本文将详细介绍如何在C++中结合OpenCV实现特征提取与描述,包括使用不同的特征描述符(如SIFT、SURF、ORB等)进行物体特征提取,并描述如何准备用于匹配或识别。
4.1 特征提取概述
特征提取是从图像中提取关键点及其描述符的过程。关键点是图像中具有显著变化的区域(如角点、边缘等),而描述符是用来描述这些关键点局部特征的向量。在OpenCV中,常用的特征提取算法包括SIFT(尺度不变特征变换)、SURF(加速稳健特征)和ORB(Oriented FAST and Rotated BRIEF)。
4.1.1 关键点检测
在特征提取过程中,首先需要检测关键点。OpenCV提供了多种方法来实现这一点:
- SIFT(尺度不变特征变换):SIFT算法通过在不同尺度下寻找局部极值来检测关键点,从而实现对尺度变化的鲁棒性。
- SURF(加速稳健特征):SURF是一种快速的特征提取算法,主要利用Hessian矩阵的行列式来检测关键点。
- ORB(Oriented FAST and Rotated BRIEF):ORB结合了FAST关键点检测和BRIEF描述符,且对旋转具有一定的不变性,计算速度较快。
4.1.2 特征描述符计算
一旦检测到关键点,接下来就是计算其描述符。描述符是一个向量,能够有效地表示关键点周围区域的特征。描述符的主要作用是用于特征匹配和识别。
4.2 使用SIFT进行特征提取与描述
SIFT(尺度不变特征变换)是一种非常经典的特征提取算法,其主要特点是对图像的尺度和旋转变化具有不变性。下面是如何使用OpenCV的SIFT算法进行特征提取与描述的步骤。
4.2.1 初始化SIFT检测器
在OpenCV中,SIFT算法被包含在cv::SIFT类中。我们可以通过以下代码创建SIFT检测器实例:
#include <opencv2/opencv.hpp>
#include <opencv2/xfeatures2d.hpp>
using namespace cv;
using namespace cv::xfeatures2d;
int main() {
// 读取图像
Mat img = imread("image.jpg", IMREAD_GRAYSCALE);
// 创建SIFT检测器
Ptr<SIFT> sift = SIFT::create();
// 检测关键点和计算描述符
std::vector<KeyPoint> keypoints;
Mat descriptors;
sift->detectAndCompute(img, noArray(), keypoints, descriptors);
// 可视化结果
Mat img_keypoints;
drawKeypoints(img, keypoints, img_keypoints);
imshow("SIFT Keypoints", img_keypoints);
waitKey(0);
return 0;
}
在上述代码中,我们首先读取图像并将其转换为灰度图。然后,创建SIFT检测器对象,并调用detectAndCompute方法来检测关键点并计算其描述符。最后,我们使用drawKeypoints函数将关键点绘制到图像上,并显示结果。
4.3 使用SURF进行特征提取与描述
SURF(加速稳健特征)是一种速度较快的特征提取算法,其主要通过Hessian矩阵来检测关键点。下面的示例演示了如何使用OpenCV的SURF算法进行特征提取与描述。
4.3.1 初始化SURF检测器
SURF算法在OpenCV中通过cv::xfeatures2d::SURF类实现。以下代码展示了如何创建SURF检测器并使用它进行特征提取:
#include <opencv2/opencv.hpp>
#include <opencv2/xfeatures2d.hpp>
using namespace cv;
using namespace cv::xfeatures2d;
int main() {
// 读取图像
Mat img = imread("image.jpg", IMREAD_GRAYSCALE);
// 创建SURF检测器
Ptr<SURF> surf = SURF::create(400);
// 检测关键点和计算描述符
std::vector<KeyPoint> keypoints;
Mat descriptors;
surf->detectAndCompute(img, noArray(), keypoints, descriptors);
// 可视化结果
Mat img_keypoints;
drawKeypoints(img, keypoints, img_keypoints);
imshow("SURF Keypoints", img_keypoints);
waitKey(0);
return 0;
}
在这个示例中,我们创建了SURF检测器并设置了其阈值参数。通过调用detectAndCompute方法,我们可以得到关键点及其描述符。最终,我们将检测到的关键点绘制到图像上并显示。
4.4 使用ORB进行特征提取与描述
ORB(Oriented FAST and Rotated BRIEF)是一种快速且高效的特征提取算法,其结合了FAST关键点检测和BRIEF描述符。ORB具有良好的旋转不变性,并且计算速度较快。
4.4.1 初始化ORB检测器
ORB算法可以通过OpenCV的cv::ORB类实现。下面的代码示例展示了如何使用ORB算法进行特征提取:
#include <opencv2/opencv.hpp>
#include <opencv2/features2d.hpp>
using namespace cv;
int main() {
// 读取图像
Mat img = imread("image.jpg", IMREAD_GRAYSCALE);
// 创建ORB检测器
Ptr<ORB> orb = ORB::create();
// 检测关键点和计算描述符
std::vector<KeyPoint> keypoints;
Mat descriptors;
orb->detectAndCompute(img, noArray(), keypoints, descriptors);
// 可视化结果
Mat img_keypoints;
drawKeypoints(img, keypoints, img_keypoints);
imshow("ORB Keypoints", img_keypoints);
waitKey(0);
return 0;
}
在ORB算法中,我们创建了ORB检测器对象,并通过detectAndCompute方法来检测关键点并计算其描述符。最后,我们将关键点绘制到图像上并显示。
4.5 特征描述符的应用
提取出的特征描述符可以用于图像匹配和物体识别。常见的应用包括:
- 图像匹配:通过计算描述符之间的距离,可以找到两幅图像之间的对应关系。
- 物体识别:通过匹配不同图像中的关键点,可以识别出物体的存在。
OpenCV中提供了多种方法来进行描述符匹配,例如暴力匹配(Brute Force Matcher)和FLANN(Fast Library for Approximate Nearest Neighbors)匹配器。
4.5.1 描述符匹配示例
以下代码展示了如何使用暴力匹配器(Brute Force Matcher)来匹配SIFT描述符:
#include <opencv2/opencv.hpp>
#include <opencv2/xfeatures2d.hpp>
#include <opencv2/features2d.hpp>
using namespace cv;
using namespace cv::xfeatures2d;
int main() {
// 读取两幅图像
Mat img1 = imread("image1.jpg", IMREAD_GRAYSCALE);
Mat img2 = imread("image2.jpg", IMREAD_GRAYSCALE);
// 创建SIFT检测器
Ptr<SIFT> sift = SIFT::create();
std::vector<KeyPoint> keypoints1, keypoints2;
Mat descriptors1, descriptors2;
sift->detectAndCompute(img1, noArray(), keypoints1, descriptors1);
sift->detectAndCompute(img2, noArray(), keypoints2, descriptors2);
// 创建暴力匹配器
BFMatcher matcher(NORM_L2);
std::vector<DMatch> matches;
matcher.match(descriptors1, descriptors2, matches);
// 可视化匹配结果
Mat img_matches;
drawMatches(img1, keypoints1, img2, keypoints2, matches, img_matches);
imshow("Matches", img_matches);
waitKey(0);
return 0;
}
在上述代码中,我们读取了两幅图像,并分别使用SIFT算法提取了它们的关键点和描述符。然后,我们使用暴力匹配器来匹配描述符,并将匹配结果绘制到图像上。
5. 图像匹配与识别
图像匹配与识别是计算机视觉中的核心任务,它涉及从图像中提取特征并将这些特征用于图像之间的比对、物体识别以及场景分析。图像匹配主要包括基于特征的匹配和模板匹配,而图像识别则包括静态图像识别和实时识别。本文将详细介绍如何使用C++结合OpenCV实现这些技术。
5.1 图像特征匹配算法
图像特征匹配是通过比较图像特征来找到图像之间的对应关系。常见的图像特征匹配算法包括基于特征的匹配和模板匹配。以下将详细介绍这两种方法的实现。
5.1.1 基于特征的匹配
基于特征的匹配是通过提取图像中的特征点及其描述符来进行匹配的。这种方法适用于图像内容的变化(如视角变化、光照变化等),因为它依赖于描述符而非整个图像的像素值。以下是实现基于特征的匹配的步骤。
5.1.1.1 特征点检测与描述
首先,我们需要从两幅图像中检测特征点并计算其描述符。可以使用SIFT、SURF或ORB等特征检测器。这里我们以ORB为例进行说明:
#include <opencv2/opencv.hpp>
#include <opencv2/features2d.hpp>
using namespace cv;
int main() {
// 读取两幅图像
Mat img1 = imread("image1.jpg", IMREAD_GRAYSCALE);
Mat img2 = imread("image2.jpg", IMREAD_GRAYSCALE);
// 创建ORB检测器
Ptr<ORB> orb = ORB::create();
// 检测关键点和计算描述符
std::vector<KeyPoint> keypoints1, keypoints2;
Mat descriptors1, descriptors2;
orb->detectAndCompute(img1, noArray(), keypoints1, descriptors1);
orb->detectAndCompute(img2, noArray(), keypoints2, descriptors2);
// 创建暴力匹配器
BFMatcher matcher(NORM_HAMMING);
std::vector<DMatch> matches;
matcher.match(descriptors1, descriptors2, matches);
// 绘制匹配结果
Mat img_matches;
drawMatches(img1, keypoints1, img2, keypoints2, matches, img_matches);
imshow("ORB Matches", img_matches);
waitKey(0);
return 0;
}
在上述代码中,我们读取了两幅图像,并使用ORB算法提取了它们的特征点和描述符。然后,使用暴力匹配器(BFMatcher)来匹配描述符,并绘制匹配结果。
5.1.1.2 匹配优化
通常情况下,我们会使用最近邻匹配器(如暴力匹配器)来获得初步的匹配结果,并进一步使用比率测试或其他策略来优化匹配结果。例如,Lowe的比率测试可以用来筛选较为可靠的匹配对:
#include <opencv2/opencv.hpp>
#include <opencv2/features2d.hpp>
using namespace cv;
int main() {
// 读取两幅图像
Mat img1 = imread("image1.jpg", IMREAD_GRAYSCALE);
Mat img2 = imread("image2.jpg", IMREAD_GRAYSCALE);
// 创建ORB检测器
Ptr<ORB> orb = ORB::create();
// 检测关键点和计算描述符
std::vector<KeyPoint> keypoints1, keypoints2;
Mat descriptors1, descriptors2;
orb->detectAndCompute(img1, noArray(), keypoints1, descriptors1);
orb->detectAndCompute(img2, noArray(), keypoints2, descriptors2);
// 创建暴力匹配器
BFMatcher matcher(NORM_HAMMING);
std::vector<std::vector<DMatch>> knn_matches;
matcher.knnMatch(descriptors1, descriptors2, knn_matches, 2);
// 使用比率测试筛选匹配结果
std::vector<DMatch> good_matches;
float ratio_thresh = 0.75f;
for (const auto& match : knn_matches) {
if (match[0].distance < ratio_thresh * match[1].distance) {
good_matches.push_back(match[0]);
}
}
// 绘制匹配结果
Mat img_matches;
drawMatches(img1, keypoints1, img2, keypoints2, good_matches, img_matches);
imshow("Good Matches", img_matches);
waitKey(0);
return 0;
}
在这段代码中,我们使用KNN(k-Nearest Neighbor)匹配来找到每个描述符的两个最佳匹配,并通过比率测试筛选出可靠的匹配对。
5.1.2 模板匹配
模板匹配是一种简单的图像匹配方法,通过将一个小模板图像在目标图像中滑动,并计算匹配度来找到目标图像中的模板位置。这种方法适用于模板和目标图像之间的几何变换较小的情况。
5.1.2.1 实现模板匹配
OpenCV提供了matchTemplate函数来实现模板匹配。以下是一个简单的示例:
#include <opencv2/opencv.hpp>
using namespace cv;
int main() {
// 读取目标图像和模板图像
Mat img = imread("scene.jpg", IMREAD_COLOR);
Mat templ = imread("template.jpg", IMREAD_COLOR);
// 创建匹配结果矩阵
Mat result;
matchTemplate(img, templ, result, TM_CCOEFF_NORMED);
// 找到最佳匹配位置
double minVal, maxVal;
Point minLoc, maxLoc;
minMaxLoc(result, &minVal, &maxVal, &minLoc, &maxLoc);
// 绘制矩形框
Rect matchRect(maxLoc.x, maxLoc.y, templ.cols, templ.rows);
rectangle(img, matchRect, Scalar(0, 255, 0), 2);
// 显示结果
imshow("Template Matching", img);
waitKey(0);
return 0;
}
在这段代码中,我们使用matchTemplate函数计算模板图像与目标图像的匹配度,并通过minMaxLoc函数找到最佳匹配位置。最终,我们在目标图像上绘制矩形框来标记匹配区域。
5.2 实现图像识别的方法和技术
图像识别是通过特征提取与匹配来识别图像内容的过程。根据应用场景的不同,图像识别可以分为实时识别和静态图像识别。
5.2.1 静态图像识别
静态图像识别是针对单张图像进行的识别任务,通常包括物体检测、分类和标注等。以下是静态图像识别的一些常用方法:
5.2.1.1 物体检测
物体检测是识别图像中物体的位置和类别的过程。常见的物体检测算法包括Haar特征分类器、YOLO(You Only Look Once)、SSD(Single Shot MultiBox Detector)等。OpenCV中提供了Haar特征分类器的实现:
#include <opencv2/opencv.hpp>
using namespace cv;
int main() {
// 读取图像
Mat img = imread("image.jpg");
// 加载Haar级联分类器
CascadeClassifier classifier;
classifier.load("haarcascade_frontalface_default.xml");
// 检测物体
std::vector<Rect> objects;
classifier.detectMultiScale(img, objects);
// 绘制检测结果
for (const auto& obj : objects) {
rectangle(img, obj, Scalar(0, 255, 0), 2);
}
// 显示结果
imshow("Object Detection", img);
waitKey(0);
return 0;
}
在上述代码中,我们使用Haar级联分类器来检测图像中的人脸,并绘制矩形框来标记检测到的区域。
5.2.1.2 图像分类
图像分类是将图像归类为预定义类别的过程。深度学习模型(如卷积神经网络CNN)在图像分类中表现优异。OpenCV与深度学习框架(如TensorFlow、PyTorch)结合可以实现图像分类。以下是一个使用预训练模型进行图像分类的示例:
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
using namespace cv;
using namespace cv::dnn;
int main() {
// 读取图像
Mat img = imread("image.jpg");
// 加载预训练模型
Net net = readNet
FromCaffe("deploy.prototxt", "bvlc_googlenet.caffemodel");
// 进行前向传播
Mat blob = blobFromImage(img, 1.0, Size(224, 224), Scalar(), true, false);
net.setInput(blob);
Mat prob = net.forward();
// 解析结果
Point classId;
double confidence;
minMaxLoc(prob, 0, &confidence, 0, &classId);
// 输出识别结果
std::cout << "Class ID: " << classId.x << " Confidence: " << confidence << std::endl;
return 0;
}
在这段代码中,我们加载了一个预训练的Caffe模型,并对输入图像进行前向传播,最终输出分类结果。
5.2.2 实时图像识别
实时图像识别是对视频流或摄像头捕获的连续图像进行识别。它需要高效的算法和优化的实现,以保证在处理视频流时的实时性。常见的实时识别方法包括基于深度学习的物体检测和跟踪。
5.2.2.1 实时物体检测
使用YOLO(You Only Look Once)进行实时物体检测是一种流行的方法。YOLO将整个图像分为网格,并在每个网格中预测物体类别和位置。以下是YOLO实时物体检测的基本实现:
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
using namespace cv;
using namespace cv::dnn;
int main() {
// 打开摄像头
VideoCapture cap(0);
// 加载YOLO模型
Net net = readNetFromDarknet("yolov3.cfg", "yolov3.weights");
while (true) {
Mat frame;
cap >> frame;
if (frame.empty()) break;
// 进行前向传播
Mat blob = blobFromImage(frame, 1.0 / 255.0, Size(416, 416), Scalar(), true, false);
net.setInput(blob);
std::vector<Mat> outputs;
net.forward(outputs, net.getUnconnectedOutLayersNames());
// 处理检测结果
for (const auto& output : outputs) {
for (int i = 0; i < output.rows; ++i) {
float confidence = output.at<float>(i, 4);
if (confidence > 0.5) {
int centerX = static_cast<int>(output.at<float>(i, 0) * frame.cols);
int centerY = static_cast<int>(output.at<float>(i, 1) * frame.rows);
int width = static_cast<int>(output.at<float>(i, 2) * frame.cols);
int height = static_cast<int>(output.at<float>(i, 3) * frame.rows);
Rect bbox(centerX - width / 2, centerY - height / 2, width, height);
rectangle(frame, bbox, Scalar(0, 255, 0), 2);
}
}
}
// 显示结果
imshow("Real-time Detection", frame);
if (waitKey(1) >= 0) break;
}
return 0;
}
在这段代码中,我们通过摄像头捕获视频流,并使用YOLO模型进行实时物体检测,最后将检测结果绘制到视频帧上。
6. 应用与性能优化
6.1 实际场景中的应用考虑
在实际场景中应用智能视觉技术时,需要综合考虑以下几个方面:
6.1.1 应用场景的复杂性
不同的应用场景对智能视觉技术的要求不同。例如,安防监控、自动驾驶、医疗影像分析等场景都有其特定的挑战:
- 安防监控:需要处理高分辨率视频流,实时检测和识别异常行为或物体。要求高准确率和低误报率。
- 自动驾驶:需要实时处理来自摄像头和传感器的大量数据,进行物体检测、道路标识识别和障碍物避让等。
- 医疗影像分析:需要高精度的图像分割和特征提取,以辅助诊断和治疗。
6.1.2 硬件资源的限制
实际应用中,硬件资源的限制会影响智能视觉系统的性能。考虑以下因素:
- 处理器性能:CPU和GPU的计算能力直接影响处理速度。对于实时应用,处理器性能尤为重要。
- 内存带宽和容量:图像数据和中间结果需要占用大量内存。内存带宽和容量的限制会影响数据处理速度。
- 存储设备:图像和视频数据的存储要求可能会影响读写速度和系统性能。
6.1.3 环境光照与背景变化
环境光照变化和背景干扰可能会影响视觉系统的检测和识别效果。例如,在低光照或强光照条件下,图像质量可能会下降,从而影响特征提取和匹配的准确性。
6.1.4 实时性要求
许多应用场景要求视觉系统能够实时响应。例如,自动驾驶系统需要实时处理摄像头数据以进行驾驶决策。为此,需要设计高效的算法和优化系统性能,以满足实时性的要求。
6.2 性能优化策略和技术
为了提高智能视觉系统的性能,需要采用各种优化策略和技术。以下将介绍一些关键的优化方法,包括并行处理、GPU加速、算法优化等。
6.2.1 并行处理
并行处理可以有效提高计算效率,特别是在处理大规模图像数据时。C++和OpenCV提供了多种并行处理技术,包括线程和任务并行。
6.2.1.1 OpenMP
OpenMP是一个支持多平台共享内存多处理编程的API,可以用来实现多线程并行处理。以下是一个使用OpenMP优化图像处理的示例:
#include <opencv2/opencv.hpp>
#include <omp.h>
using namespace cv;
int main() {
Mat img = imread("image.jpg", IMREAD_GRAYSCALE);
Mat result = img.clone();
// 并行处理图像的每一行
#pragma omp parallel for
for (int i = 0; i < img.rows; ++i) {
for (int j = 0; j < img.cols; ++j) {
result.at<uchar>(i, j) = img.at<uchar>(i, j) * 2; // 示例操作
}
}
imshow("Processed Image", result);
waitKey(0);
return 0;
}
在上述代码中,我们使用OpenMP对图像的每一行进行并行处理,从而加速了图像处理过程。
6.2.1.2 C++11线程
C++11标准引入了对多线程的支持,可以用来实现任务并行处理。以下是一个使用C++11线程的示例:
#include <opencv2/opencv.hpp>
#include <thread>
#include <vector>
using namespace cv;
void processRow(Mat& img, Mat& result, int row) {
for (int j = 0; j < img.cols; ++j) {
result.at<uchar>(row, j) = img.at<uchar>(row, j) * 2; // 示例操作
}
}
int main() {
Mat img = imread("image.jpg", IMREAD_GRAYSCALE);
Mat result = img.clone();
std::vector<std::thread> threads;
// 启动线程处理每一行
for (int i = 0; i < img.rows; ++i) {
threads.emplace_back(processRow, std::ref(img), std::ref(result), i);
}
// 等待所有线程完成
for (auto& t : threads) {
t.join();
}
imshow("Processed Image", result);
waitKey(0);
return 0;
}
在这个示例中,我们使用C++11线程对图像的每一行进行处理,并在所有线程完成后显示处理结果。
6.2.2 GPU加速
GPU加速可以显著提高图像处理的速度,尤其是在处理大规模数据时。OpenCV提供了对CUDA的支持,可以利用NVIDIA GPU加速计算。
6.2.2.1 使用OpenCV的CUDA模块
OpenCV的CUDA模块提供了许多加速图像处理操作的功能。以下是一个使用CUDA加速图像处理的示例:
#include <opencv2/opencv.hpp>
#include <opencv2/cudaarithm.hpp>
#include <opencv2/cudaimgproc.hpp>
using namespace cv;
using namespace cv::cuda;
int main() {
// 读取图像
Mat img = imread("image.jpg", IMREAD_GRAYSCALE);
GpuMat d_img, d_result;
d_img.upload(img);
// 使用CUDA加速图像处理
Ptr<cuda::Filter> filter = cuda::createGaussianFilter(CV_8UC1, CV_8UC1, Size(5, 5), 0);
filter->apply(d_img, d_result);
// 下载结果并显示
Mat result;
d_result.download(result);
imshow("Processed Image", result);
waitKey(0);
return 0;
}
在这个示例中,我们使用CUDA模块中的高斯滤波器对图像进行处理,并将结果下载到主内存中显示。
6.2.2.2 使用深度学习框架的GPU加速
许多深度学习框架(如TensorFlow、PyTorch)提供了GPU加速功能。OpenCV可以与这些框架结合使用,进一步提高图像处理的性能。以下是一个使用TensorFlow的GPU加速示例:
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
using namespace cv;
using namespace cv::dnn;
int main() {
// 读取图像
Mat img = imread("image.jpg");
// 加载TensorFlow模型
Net net = readNetFromTensorflow("model.pb");
// 进行前向传播
Mat blob = blobFromImage(img, 1.0, Size(224, 224), Scalar(), true, false);
net.setInput(blob);
Mat prob = net.forward();
// 处理结果
// ...
return 0;
}
在这段代码中,我们使用TensorFlow的GPU加速功能进行前向传播,显著提高了计算速度。
6.2.3 算法优化
优化算法可以提高计算效率,减少处理时间。以下是一些常见的算法优化策略:
6.2.3.1 减少计算复杂度
通过简化算法或采用更高效的数据结构,可以减少计算复杂度。例如,在特征匹配中,使用近似最近邻搜索(如FLANN)可以比暴力搜索更快。
6.2.3.2 数据预处理
数据预处理可以减少计算量,提高算法效率。例如,对图像进行降噪、均衡化处理可以提高特征提取的准确性和效率。
6.2.3.3 硬件加速优化
针对特定硬件(如GPU、TPU)优化算法实现,可以充分发挥硬件性能。例如,利用TensorFlow的XLA(Accelerated Linear Algebra)编译器优化深度学习模型的计算图。
如果这篇文章给您带来了哪怕一丁点儿的乐趣或启发,不妨考虑赞赏杯茶水吧!谢谢您的慷慨支持!










![[原理理解] Swin Transformer相对位置编码理解](https://i-blog.csdnimg.cn/direct/1a9772e2861f4b79b3e8fa2a182c3646.png#pic_center)