目录
一、SQL语句优化
1. 避免使用 SELECT * ,而是具体字段
2.避免使用 % 开头的 LIKE 的查询
3.避免使用子查询,使用JOIN
4.使用EXISTS代替IN
5.使用LIMIT 1优化查询
6.使用批量插入、优化INSERT操作
7.其他方式
二、SQL索引优化
1.在查询条件或者连接条件的列上建立索引
2.遵循最左前缀原则
3.避免在索引列上进行计算
4.使用覆盖索引
5.避免使用更新频繁的列作为索引
6.避免过多的列使用复合索引
7.定期维护索引
三、EXPLAIN分析查询
MYSQL优化一般从SQL语句开始优化,再分析索引,即使有了良好的索引,糟糕的查询语句也可能导致性能问题
优化查询语句可以帮助数据库更有效地利用现有的资源,减少不必要的开销。下面是几个关于如何从查询语句开始优化的步骤:
- 识别慢查询
- SQL优化
- 索引使用
- 使用 EXPLAIN 分析查询
一、SQL语句优化
不合理的SQL语句会导致:
- 索引失效,无法使用索引
- 全表扫描,因为数据库必须检查每一行数据以确定是否匹配
- 对于大型表,这会导致性能问题和资源消耗
下面的例子🌰以User表为例
CREATE TABLE User (
user_id INT PRIMARY KEY,
name VARCHAR(255),
phone VARCHAR(20),
email VARCHAR(255),
role VARCHAR(50),
address VARCHAR(255),
birthday DATETIME
);
1. 避免使用 SELECT * ,而是具体字段
❌:索引失效,全表扫描
SELECT * FROM user✅:节省资源、减少网络开销。可能用到覆盖索引,减少回表,提高查询效率
SELECT id,username,sex FROM user📌原因:
-
只取实际需要的字段,节省资源、减少网络开销。
-
可能用到覆盖索引,减少回表,提高查询效率
覆盖索引和回表下文会详解,此处不做过多赘述
⚠️注意:为节省时间,下面的样例字段都用 SELECT * 代替了
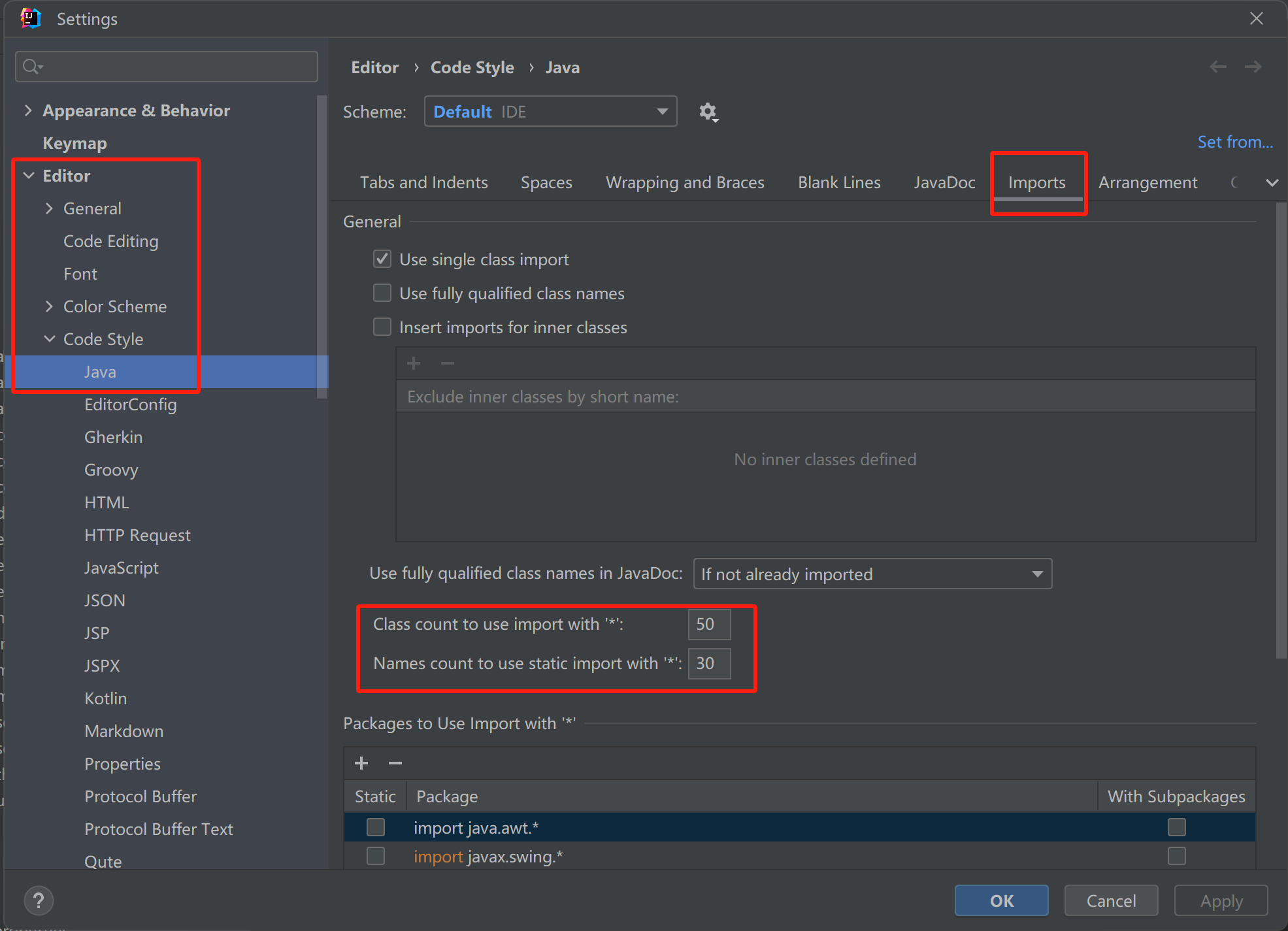
2.避免使用 % 开头的 LIKE 的查询
❌:
SELECT * FROM User WHERE name LIKE '%echola';✅:
SELECT * FROM User WHERE name LIKE 'echola%';3.避免使用子查询,使用JOIN
SELECT * FROM User
WHERE id IN (
SELECT user_id
FROM Orders
WHERE status = 'completed');
✅:
SELECT u.*
FROM User u JOIN Orders o ON u.id = o.user_id
WHERE o.status = 'completed';
inner join 、left join、right join,优先使用inner join
三种连接如果结果相同,优先使用inner join(返回行数少),如果使用left join左边表尽量小(小表在前,大表在后)
-
inner join 内连接,只保留两张表中完全匹配的结果集;
-
left join会返回左表所有的行,即使在右表中没有匹配的记录;
-
right join会返回右表所有的行,即使在左表中没有匹配的记录
⚠️:表连接不宜太多,一般5个以内
4.使用EXISTS代替IN
虽然需避免子查询,但是某些情况下还是需要使用子查询,使用EXISTS代替IN可以提高查询效率
❌:
SELECT * FROM User
WHERE id IN (
SELECT user_id
FROM Orders
WHERE status = 'completed');
✅:EXISTS 找到第一个匹配项后就会停止搜索,而 IN 会遍历整个子查询结果集
SELECT * FROM User
WHERE id EXISTS (
SELECT user_id
FROM Orders
WHERE status = 'completed');
5.使用LIMIT 1优化查询
在只需要一条结果的查询中使用 LIMIT 1 可以提高性能,
尤其是在使用Mybatis Plus中的selectOne(),若有多条数据符合,则会抛出异常,因此需要添加 LIMIT 1
SELECT * FROM users WHERE name = 'echola' LIMIT 1;6.使用批量插入、优化INSERT操作
使用批量插入可以减少事务提交次数:在批量插入过程中,尽量减少事务提交的次数。可以在一个事务中插入多条记录,然后一次性提交。在开发中一般使用MybatisPlus的saveBatch()
START TRANSACTION;
INSERT INTO User (user_id, name, phone, email, role, address, birthday)
VALUES
(1, 'Alice', '1234567890', 'alice@example.com', 'user', 'New York', '2000-01-01 00:00:00'),
(2, 'Bob', '0987654321', 'bob@example.com', 'admin', 'Los Angeles', '1999-01-01 00:00:00'),
(3, 'Charlie', '5555555555', 'charlie@example.com', 'user', 'Chicago', '2001-01-01 00:00:00');
COMMIT;
7.其他方式
避免在 WHERE 子句中使用 OR 来连接条件
❌:
SELECT * FROM User WHERE age = 25 OR name = 'echola';✅:
SELECT * FROM User WHERE age = 25
UNION ALL
SELECT * FROM User WHERE name = 'echola';
避免使用 NOT IN、!=、<> 等负条件,因为这些条件不能有效使用索引
避免在索引列上使用IS NULL或IS NOT NULL
避免使用HAVING代替WHERE,在可能的情况下,使用 WHERE 代替 HAVING 进行过滤,因为 HAVING 是在聚合之后进行过滤,性能较差
二、SQL索引优化
合理地使用索引是SQL最重要的
如果数据量小的表,可以不建立索引,但数据量大的表肯定是需要建立索引的
如果一张表上kw的数据量,果索引使用不当,也可能会导致索引失效,反而成为负担
以下关键词条解释:
复合索引:多个列组合成的索引
覆盖索引:索引中包含了查询所需的全部字段
最左前缀原则:在复合索引中,查询条件应尽可能地按照索引的顺序进行匹配回表:当数据库使用索引来加速查询时,如果索引是非聚集索引(也称为辅助索引或者二级索引),那么索引项中存储的并不是完整的行数据,而是指向实际数据行的指针。当数据库通过索引查找到匹配的索引项后,还需要根据这个指针回到实际的数据页去获取完整的行数据
1.在查询条件或者连接条件的列上建立索引
⚠️:只要发现接口查询缓慢,优先检查 WHERE 后面的条件,有没有创建索引,如果已经建立索引,需要创建复合索引,调整现有索引
⚠️:索引不宜太多,一般5个以内
CREATE INDEX idx_userid ON User(user_id);SELECT * FROM User WHERE user_id = 123 AND name = 'echola';2.遵循最左前缀原则
对于复合索引(name, age, phone),可以用于(name),(name, age),(name, age, phone)顺序匹配查询
CREATE INDEX idx_name_age_phone ON User(name, age, phone);
❌:此处是(age,phone),没有按照索引的顺序进行匹配 ,导致索引无法完全利用,可能需要额外的回表操作
SELECT * FROM User WHERE age = 25 AND phone = '1234567890';✅:按顺序匹配(name, age)
SELECT * FROM User WHERE phone = '1234567890' AND age = 25 ;3.避免在索引列上进行计算
❌:使用 YEAR(date) 会导致索引失效
CREATE INDEX idx_birthday ON User(birthday);
SELECT * FROM User WHERE YEAR(birthday) = 2024;✅:
SELECT * FROM User WHERE birthday BETWEEN '2024-01-01' AND '2024-12-31';4.使用覆盖索引
如果查询的所有列都在索引中,那么数据库引擎可以不访问表中的数据而直接从索引中获取所需信息,这样可以减少回表操作,从而提高查询效率
❌:不使用覆盖索引
CREATE INDEX idx_userid ON User(user_id);
SELECT user_id, phone, role FROM User WHERE user_id = 123;索引 idx_userid 只包含 user_id 列,但 user_id, phone, 和 role 列不在索引里,导致需要回表访问主键索引或其他索引
✅:索引中覆盖了所有查询的列,数据库可以直接从索引中获取数据
CREATE INDEX idx_userid_phone_role ON User(user_id, phone, role);
SELECT user_id, phone, role FROM User WHERE user_id = 123;5.避免使用更新频繁的列作为索引
更新频繁的列作为索引会导致较高的维护成本,降低查询性能
❌:phone 列更新频繁,每次更新都会导致索引的重建,更新成本高,影响性能
CREATE INDEX idx_phone ON User(phone);6.避免过多的列使用复合索引
复合索引的列数不要太多,列数过多会增加索引的维护开销,并且可能导致索引文件过大。对此可以拆分为较少复合索引和单个索引
CREATE INDEX idx_userid_phone_role_address ON User(user_id, phone, role, address);7.定期维护索引
使用 ANALYZE TABLE 更新统计信息,并使用 OPTIMIZE TABLE 来整理碎片化的索引 ,特别是在大量插入、更新和删除操作后,表可能会出现碎片化,导致性能下降
ANALYZE TABLE User;
OPTIMIZE TABLE User;⚠️:这两个命令可能会导致锁定表,因此在高并发环境中使用时要谨慎,最好在低峰时段执行
对于非常大的表,执行这些命令可能需要较长时间,建议提前进行测试
三、EXPLAIN分析查询
使用 EXPLAIN 分析 SQL 执行计划可以帮助我们理解数据库如何执行查询,并找出潜在的性能瓶颈
SELECT user_id, phone, role FROM User WHERE user_id = 123 AND birthday > '2000-01-01 先看下没有建立索引的情况
EXPLAIN SELECT user_id, phone, role FROM User WHERE user_id = 123 AND birthday > '2000-01-01 00:00:00'; 执行结果:
具体解释:
EXPLAIN 输出表格包含多个列,每列提供不同的查询计划信息。常见列包括:
1、id:查询的标识符,表示查询的执行顺序
2、select_type:查询类型,如 SIMPLE(简单查询),PRIMARY(主查询),UNION(联合查询的一部分),SUBQUERY(子查询)
3、table:查询涉及的表
4、type:连接类型,表示MySQL如何查找行。常见类型按效率从高到低排列为:
- system:表只有一行(常见于系统表)
- const:表最多有一个匹配行(索引为主键或唯一索引)
- eq_ref:对于每个来自前一个表的行,表中最多有一个匹配行。
- ref:对于每个来自前一个表的行,表中可能有多个匹配行。
- range:使用索引查找给定范围的行。
- index:全表扫描索引。
- ALL:全表扫描。
5、possible_keys:查询中可能使用的索引(user_id主键索引PRIMARY KEY)
6、key:实际使用的索引。
7、key_len:使用的索引键长度。
8、ref:使用的列或常量,与索引比较,此处表示常量引用,即 user_id = 123
9、rows:MySQL 估计的要读取的行数。
10、filtered:经过表条件过滤后的行百分比。
11、Extra:额外的信息,如 Using index(覆盖索引),Using where(使用 WHERE 子句过滤),Using filesort(文件排序),Using temporary(使用临时表)
建立复合索引
CREATE INDEX idx_userid_birthday ON User(user_id, birthday);执行结果 :

主键索引使用:
默认的主键索引 user_id 被利用,使得查询可以快速定位到 user_id = 123 的记录。
复合索引优化:
创建复合索引 idx_userid_birthday 可以进一步优化查询性能,减少不必要的扫描操作。
通过这些步骤,我们可以确保查询性能得到显著提升,并且索引能够充分利用
欢迎对SQL优化的方式,进行补充……