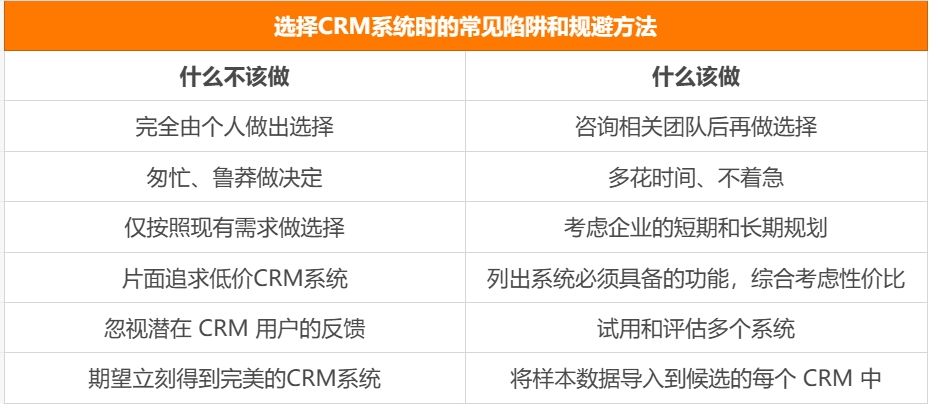
k-均值与PCA
- k-均值
- 图片颜色聚类
- PCA(主成分分析)
- 对x去均值化
- 图像降维
k-均值
K-均值是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。
K-均值是一个迭代算法,假设我们想要将数据聚类成n个组,其方法为:
首先选择K个随机的点,称为聚类中心(cluster centroids);
对于数据集中的每一个数据,按照距离K个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类。
计算每一个组的平均值,将该组所关联的中心点移动到平均值的位置。
重复步骤2-4直至中心点不再变化。

样本数据



import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio
from scipy.optimize import minimize
import pandas as pd
from sklearn.svm import SVC
"""
1获取每个样本所属类别
"""
def fnd_centroids(x,centros):
idx=[]
for i in range(len(x)):
#x[i] 1x2数组 centros是 kx2的数组
dist =np.linalg.norm((x[i]- centros),axis=1)#dis 1xk
id_i=np.argmin(dist)
idx.append(id_i)
return np.array(idx)
"""
2.计算聚类中心点
"""
def compute_centros(X,idx,k):
centros =[]
for i in range(k):
centros_i = np.mean(x[idx == i],axis=0)
centros.append(centros_i)
return np.array(centros)
"""
3.运行kmeans,重复执行1和2
"""
def run_kmeans(x,centros,iters):
k = len(centros)
centros_all =[]
centros_all.append(centros)
centros_i = centros
for i in range(iters):
idx = fnd_centroids(x,centros_i)
centros_i = compute_centros(x,idx,k)
centros_all.append(centros_i)
return idx,np.array(centros_all)
"""
绘制数据集和聚类中心的移动轨迹
"""
def plot_data(X,centros_all,idx):
plt.figure()
plt.scatter(X[:,0],X[:,1],c=idx,cmap='rainbow')
plt.plot(centros_all[:,:,0],centros_all[:,:,1],'kx--')
"""
观察初始聚类点的位置对聚类效果的影响
"""
def init_centros(x,k):
index = np.random.choice(len(x),k)
return x[index]
data1=sio.loadmat("E:/学习/研究生阶段/python-learning/吴恩达机器学习课后作业/code/ex7-kmeans and PCA/data/ex7data2.mat")
x=data1["X"]
# plt.scatter(x[:,0],x[:,1])
centros=np.array([[3,3],[6,2],[8,5]])
idx=fnd_centroids(x,centros)
compute_centros(x,idx,k=3)
idx, centros_all = run_kmeans(x, centros, iters=10)
# plot_data(x,centros_all, idx)
# plt.show()
init_centros(x,k=3)
for i in range(4):
idx,centros_all = run_kmeans(x,init_centros(x,k=3),iters=10)
plot_data(x,centros_all,idx)
plt.show()




图片颜色聚类

PCA(主成分分析)



数据集

对x去均值化



import numpy as np
import scipy.io as sio
import matplotlib.pyplot as plt
mat = sio.loadmat("E:/学习/研究生阶段/python-learning/吴恩达机器学习课后作业/code/ex7-kmeans and PCA/data/ex7data1.mat")
x= mat['X']
# plt.scatter(x[:,0],x[:,1])
# plt.show()
"""对x去均值化"""
x_demean= x - np.mean(x,axis=0)
# plt.scatter(x_demean[:,0],x_demean[:,1])
# plt.show()
"""计算协方差矩阵"""
C=x_demean.T@x_demean/ len(x)
"""计算特征值,特征向量"""
U,S,V = np.linalg.svd(C)
U1=U[:,0]
"""实现降维"""
x_reduction= x_demean@U1
plt.figure(figsize=(7,7))
plt.scatter(x_demean[:,0],x_demean[:,1])
plt.plot([0,U1[0]],[0,U1[1]],c='r')
plt.plot([0,U[:,1][0]],[0,U[:,1][1]],c='k')
plt.show()

import numpy as np
import scipy.io as sio
import matplotlib.pyplot as plt
mat = sio.loadmat("E:/学习/研究生阶段/python-learning/吴恩达机器学习课后作业/code/ex7-kmeans and PCA/data/ex7data1.mat")
x= mat['X']
# plt.scatter(x[:,0],x[:,1])
# plt.show()
"""对x去均值化"""
x_demean= x - np.mean(x,axis=0)
# plt.scatter(x_demean[:,0],x_demean[:,1])
# plt.show()
"""计算协方差矩阵"""
C=x_demean.T@x_demean/ len(x)
"""计算特征值,特征向量"""
U,S,V = np.linalg.svd(C)
U1=U[:,0]
"""实现降维"""
x_reduction= x_demean@U1
plt.figure(figsize=(7,7))
plt.scatter(x_demean[:,0],x_demean[:,1])
plt.plot([0,U1[0]],[0,U1[1]],c='r')
plt.plot([0,U[:,1][0]],[0,U[:,1][1]],c='k')
plt.show()
"""还原数据"""
x_restore = x_reduction.reshape(50,1)@U1.reshape(1,2) + np.mean(x,axis=0)
x_reduction.shape,U1.shape
plt.scatter(x[:,0],x[:,1])
plt.scatter(x_restore[:,0],x_restore[:,1])
plt.show()
图像降维


降维后图片

import numpy as np
import scipy.io as sio
import matplotlib.pyplot as plt
def plot_100_images(X):
fig, axs = plt.subplots(ncols=10, nrows=10, figsize=(10,10))
for c in range(10):
for r in range(10):
axs[c,r].imshow(X[10*c + r].reshape(32,32).T,cmap = 'Greys_r')#显示单通道的灰度图
axs[c,r].set_xticks([])
axs[c,r].set_yticks([])
mat = sio.loadmat("E:/学习/研究生阶段/python-learning/吴恩达机器学习课后作业/code/ex7-kmeans and PCA/data/ex7faces.mat")
x= mat['X']
plot_100_images(x)
means = np.mean(x,axis=0)
x_demean =x -means
C= x_demean.T@x_demean
u,s,V = np.linalg.svd(C)
U1= u[:,:36]
x_reduction = x_demean@U1
x_recover = x_reduction@U1.T+means
plot_100_images(x_recover)
plt.show()