夕小瑶科技说 原创
作者 | Richard
在大语言模型(LLM)问世之后,基于 LLM 的 Agent 引起了广泛的关注并且变得越来越流行。规划能力无论对人类还是 Agent 都是一个重要的决策步骤,规划的本质是通过预先设定的行动过程,以期望在未来达到特定的目标或者解决特定的问题。
规划是基于 LLM 的 Agent 一个关键的能力,涉及从初始状态达到预期目标的系统性过程。规划决定了 Agent 如何在复杂环境中自主操作,其中包括与环境交互、执行动作、考虑约束条件和可用资源等。
最近关于 Agent 训练的最新研究表明,通过使用轨迹数据(动作-观察对)序列对大模型进行微调可以增强其规划的能力。但是目前的工作主要集中于手动设计的规划任务和环境中的合成轨迹。
鉴于此,港大联合微软提出 AgentGen 框架,对自动合成多样化环境和从简单到困难的渐进规划任务进行探索。AgentGen 框架利用 LLM 生成多样化环境和规划任务,采用基于启发式规则构建的语料库和 BO-EVOL 方法提升任务难度多样性。
AgentGen 极大提高了 LLM 的规划能力,AgentGen指令微调的 Llama-3 8B 在整体性能上超过了 GPT-3.5,甚至在某些任务上,其还接近 GPT-4 的水平。

论文标题:
AGENTGEN: Enhancing Planning Abilities for Large Language Model based Agent via Environment and Task Generation
论文链接:
https://arxiv.org/pdf/2408.00764
什么是规划问题?
目标导向的确定性规划问题被定义为 ,其中 表示 Agent 交互的环境,表示 Agent 需要完成的任务。
环境包括动作空间、状态空间和转移函数。
任务由定义,表示目标条件,为初始状态。
规划问题可用Python或PDDL实现。在PDDL中,域文件定义环境,问题文件定义任务。在Python中(如OpenAI gym),规划问题通常实现为一个类,包含转移函数、奖励函数和初始状态定义。
Agent 训练
得益于 LLMs 的进步,基于 LLM 的 Agent 引起了研究人员的广泛关注。
基于 LLM 的 Agent 是指利用 LLMs 感知环境、作出决策并执行行动,以代替或者帮助人们完成特定任务。
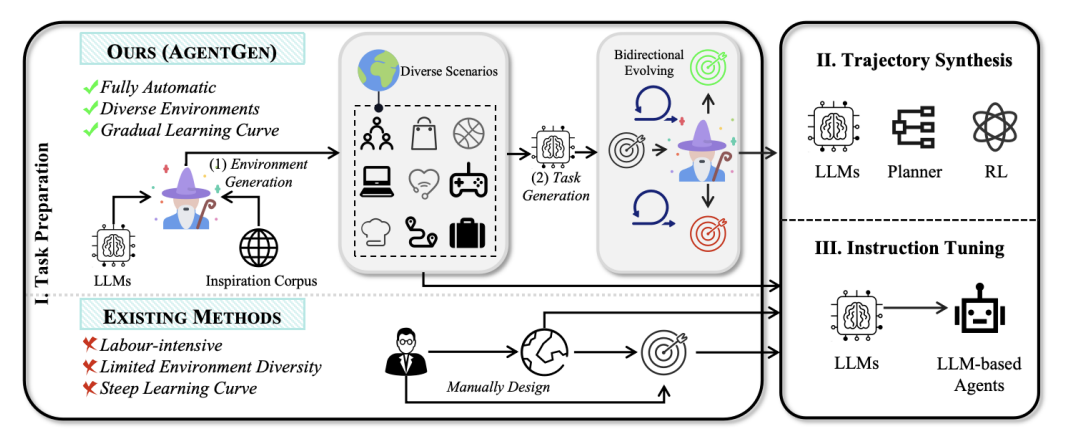
通过指令微调 LLMs 来提升规划能力是一个 Agent 的一个重要研究领域,被称为 Agent 训练。如下图所示,典型的 Agent 训练可以分为三个阶段:
-
环境准备和任务规划
-
在这些任务上合成轨迹数据(动作-观察对序列)
-
使用合成的数据对 LLMs 进行指令微调
目前而言,环境准备和任务规划主要依赖人工进行设计,这样的资源密集型任务就阻碍了大规模轨迹数据的生成。具体而言,设计多样化的环境需要定义一系列丰富和实用的场景,而实现这些环境往往通过需要具备编程技能的人类专家参与。除此之外,制定任务通常需要创建一个难度逐渐递进的任务集。
由于以上的种种限制,目前的 Agent 训练只能使用少量环境进行数据合成。
为解决上述不足,港大联合微软提出 AgentGen框架,利用 LLMs 构建多样化的环境和规划任务用于 Agent 训练,将可用环境从几个扩展到数百个。具体而言,AgentGen 围绕两个阶段构建:环境生成和任务生成。
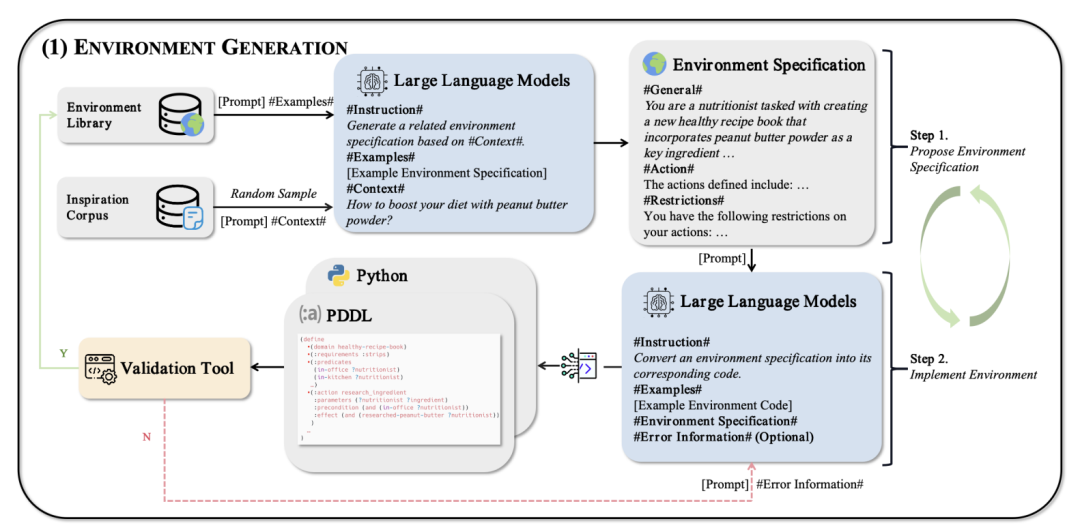
环境生成
环境生成是 AgentGen 框架的第一个核心组成部分,其生成过程包括三个主要组建:
-
环境规范生成模块:这个模块使用大语言模型(LLM)首先生成环境的规范。规范通常包括环境的总体概述、状态空间和动作空间的描述,以及转移函数的定义。
-
环境实现模块:基于生成的环境规范,这个模块生成相应的代码。这可以看作是一个典型的代码生成问题。
-
环境库:这是一个存储先前生成的高质量环境的库,作为综合环境数据集,并为生成新环境提供上下文示例。
为了增加环境的多样性,AgentGen 引入了一个启发语料库 ,包含足够多样化的文本段落。在生成环境时,首先从 中采样一个文本段落 ,然后提示LLM基于 生成相关环境。
环境库在迭代 t 时刻定义为:
其中 是初始种子库,联合表示直到迭代 t 生成的所有验证过的环境。
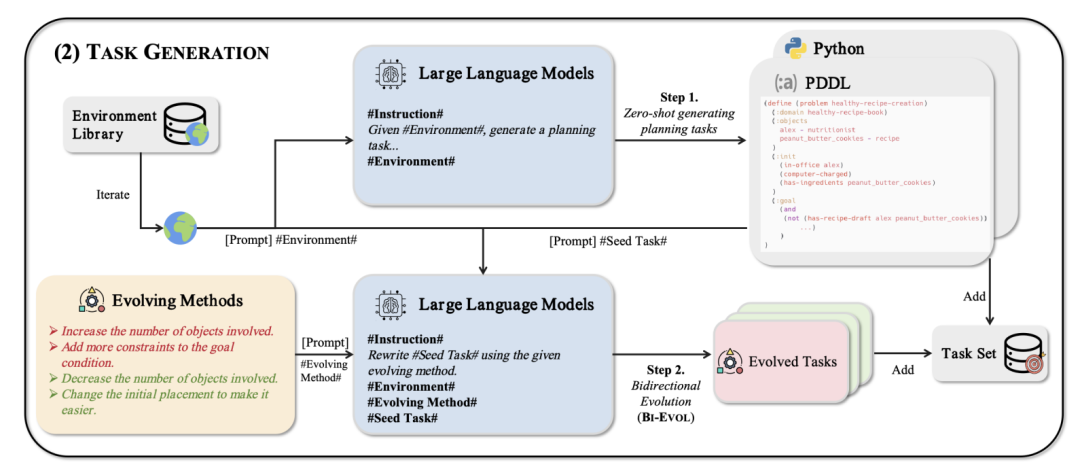
任务生成
任务生成是 AgentGen 框架的第二个核心组成部分,基于生成的环境,AgentGen 使用 LLM 生成相应的规划任务。为了创建难度多样的规划任务,AgentGen 采用了 BI-EVOL 两阶段生成方法:
-
初始任务生成:首先,AgentGen 以零样本方式提示LLM生成一组初始规划任务。
-
双向演化:随后,AgentGen 调整这些任务,使它们变得更简单或更具挑战性,形成一个全面的规划任务集。
BI-EVOL 方法引入了两个方向的演化:easy-evol 和 hard-evol。
-
easy-evol:通常涉及简化目标条件。这种方法的动机是,当智能体表现不佳且无法直接从典型的困难目标中学习时,更简单的任务可以促进学习。
-
hard-evol:通常涉及使目标条件更复杂,增加智能体完成任务所需的步骤数。这可以进一步增强智能体执行规划任务的能力。
通过这种双向演化方法,AgentGen 能够生成一个难度曲线更平滑的任务集,有利于 LLM 更有效地学习规划能力。
实验验证
为评估AGENTGEN框架的有效性,作者进行了一系列实验。这些实验主要分为两个部分:领域内任务评估和领域外任务评估。
-
领域内任务:使用PDDL实现的四个广泛应用的规划任务:Blocksworld:要求智能体通过移动块达到目标配置。Gripper:涉及在不同房间之间移动物体。Tyreworld:模拟更换汽车轮胎的过程。Barman:模拟调酒师混合鸡尾酒的任务。
-
领域外任务:选择了两个具有挑战性的部分可观察规划任务:Alfworld:测试智能体执行日常家务任务的能力。BabyAI:智能体在网格世界中解释和执行自然语言指令。
研究人员使用两个指标评估规划能力:成功率和进度率。进度率 衡量向目标状态 的进展。成功率只有在进度率达到1时才为1,其他情况为0。
下表展示了 AgentGen 与基准模型在领域内任务上的性能比较。从结果可以看出,AgentGen 在总体成功率上优于 GPT-3.5(11.67 vs 5.0);在 barman 任务中,AgentGen 甚至超过了 GPT-4的表现(15 vs 10);与参数规模相似的其他模型相比,Agentgen 在四个不同任务中始终表现更好;相比 Llama3,AgentGen 的总体成功率和进度率分别提高了10和9.95。
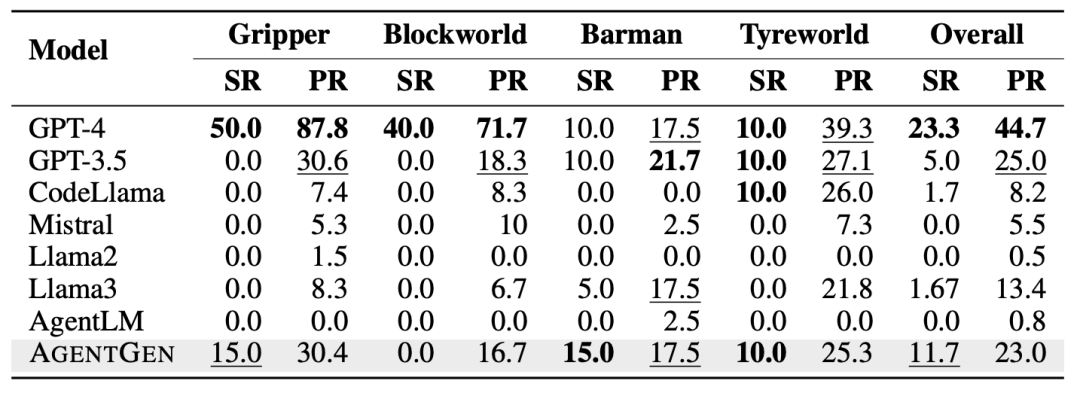
研究人员同样在鲁棒性上进行实验,下表展示了 AgentGen 在不同基础模型上的表现。实验选择了三个广泛使用的7-8B基础模型:Llama3-8B、CodeLLama-7B和Mistral-7B。结果显示所有三个模型在训练后的效果都显著提升。

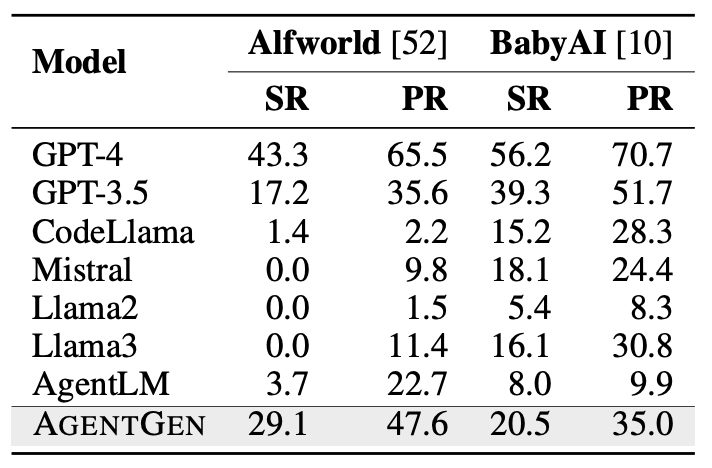
除了在领域内进行评估之外,研究人员还对 AgentGen 进行领域外任务评估。实验结果显示 AgentGen 相比 Llama3 有显著提升,在Alfworld上成功率增加到29.1,进度率增加36.2;在BabyAI上成功率增加4.4,进度率增加4.2;并且在 Alfworld 上,AgentGen 的表现超过了 GPT-3.5。更进一步,与参数规模相似的通用模型和智能体微调模型相比,AgentGen 在两个任务上都表现更优。
总结与展望
港大和微软联合推出的 AgentGen 框架通过自动生成多样化的环境和任务,显著提升了模型的规划能力。经 AgentGen 训练的8B参数模型在某些任务中接近甚至超越了 GPT-4 的表现。无论是在领域内还是领域外任务中,AgentGen 都展现出令人眼前一亮的效果和良好的泛化能力。特别是在 Alfworld 任务中远超 GPT-3.5 的表现。
未来,这一框架可能被应用到更复杂的规划任务中,如机器人控制或智能家居系统。随着进一步研究,我们或许能看到 AgentGen 在日常生活中的实际应用,比如协助个人日程安排或优化交通路线规划。