许多 NLP 应用程序(例如机器翻译、聊天机器人、文本摘要和语言模型)都会生成一些文本作为其输出。此外,图像字幕或自动语音识别(即语音转文本)等应用程序也会输出文本,即使它们可能不被视为纯 NLP 应用程序。
所有这些应用程序都使用几种常用算法作为其产生最终输出的最后一步:
- 贪婪搜索(Greedy Search)就是这样一种算法,它经常被使用,因为它简单快捷。
- 另一种方法是使用波束搜索(Beam Search),它非常受欢迎,因为尽管它需要更多的计算,但通常会产生更好的结果。
在本文中,我将探索 Beam Search 并解释使用它的原因及其工作原理。我们将简要介绍贪婪搜索作为比较,以便我们了解 Beam Search 如何改进它。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、NLP 模型如何生成输出
我们以序列到序列模型(Seq2Seq)为例。这些模型经常用于机器翻译等应用。

机器翻译的序列到序列模型
例如,如果使用此模型将英语翻译成西班牙语,它将以源语言中的句子(例如英语中的“You are welcome”)作为输入,并输出目标语言中的等效句子(例如西班牙语中的“De nada”)。
文本是单词(或字符)的序列,NLP 模型构建一个由源语言和目标语言中的整个单词集组成的词汇表。
该模型将源句子作为输入,并将其传递到嵌入层,然后传递到编码器。然后,编码器输出一个编码表示,该表示紧凑地捕获输入的基本特征。
然后,将此表示与“”标记一起输入到解码器以为其输出提供种子。解码器使用这些来生成自己的输出,即目标语言中句子的编码表示。
然后将其传递到输出层,该输出层可能由一些线性层和 Softmax 组成。线性层输出词汇表中每个单词在输出序列中每个位置出现的可能性的分数。然后,Softmax 将这些分数转换为概率:
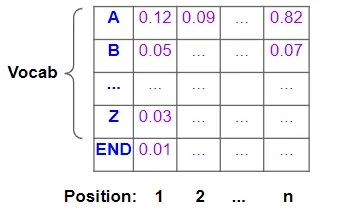
词汇表中每个字符的概率、输出序列中每个位置的概率
当然,我们的最终目标不是这些概率,而是最终的目标句子。为了得到这个,模型必须决定它应该为目标序列中的每个位置预测哪个单词。
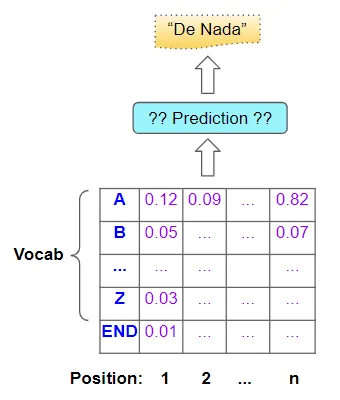
该模型根据概率预测输出句子
它是如何做到的?
2、贪婪搜索
一个相当明显的方法是简单地取每个位置上概率最高的单词并进行预测。它计算速度快,易于理解,而且通常能产生正确的结果:
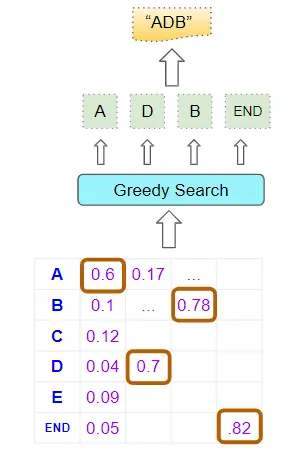
贪婪搜索
事实上,贪婪搜索非常容易理解,我们不需要花更多时间来解释它😃。但我们能做得更好吗?
啊哈,终于把我们带到了真正的话题!
3、波束搜索简介
波束搜索比贪婪搜索有两点改进:
- 使用贪婪搜索,我们只取每个位置上最好的一个词。相比之下,波束搜索扩展了这一点,并取了最好的“N”个词。
- 使用贪婪搜索,我们单独考虑每个位置。一旦我们确定了该位置的最佳词,我们就不会检查它之前(即在前一个位置)或之后的内容。相比之下,波束搜索选择迄今为止最好的“N”个序列,并考虑所有前面的单词与当前位置的单词的组合概率。
换句话说,它比贪婪搜索投射的“搜索光束”更广泛一些,这就是它的名字的由来。超参数“N”称为波束宽度。
直观地看,这比贪婪搜索能给我们带来更好的结果。因为我们真正感兴趣的是最佳的完整句子,如果我们只在每个位置挑选最佳的单个单词,我们可能会错过它。
让我们举一个简单的例子,波束宽度为 2,并使用字符来保持简单:
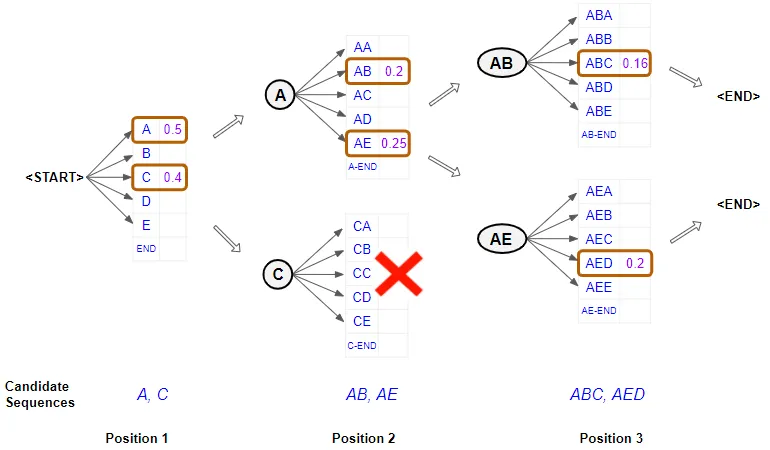
波束搜索示例,宽度 = 2
第一个位置:
- 考虑模型在第一个位置的输出。它从“”标记开始并获取每个单词的概率。现在它选择该位置的两个最佳字符。例如“A”和“C”。
第二个位置:
- 当涉及到第二个位置时,它会重新运行模型两次,通过修复第一个位置中的可能字符来生成概率。换句话说,它将第一个位置的字符限制为“A”或“C”,并生成具有两组概率的两个分支。具有第一组概率的分支对应于位置 1 中的“A”,具有第二组概率的分支对应于位置 1 中的“C”。
- 现在它根据前两个字符的组合概率从两组概率中挑选出总体上最好的两个字符对。因此,它不会从第一组中挑选出一个最佳字符对,也不会从第二组中挑选出一个最佳字符对。例如“AB” 和 “AE”
第三个位置:
- 当到达第三个位置时,它会重复该过程。它会通过将前两个位置限制为“AB”或“AE”来重新运行模型两次,并再次生成两组概率。
- 再次,它会根据两组概率中前三个字符的组合概率选择总体上最好的两个字符三元组。因此,我们现在有了前三个位置的两个最佳字符组合。例如“ABC” 和 “AED”。
重复直到结束标记:
- 它会继续执行此操作,直到它选择一个“”标记作为某个位置的最佳字符,然后结束该序列的分支。
它最终得到两个最佳序列并预测总体概率较高的序列。
4、波束搜索的工作原理
现在,我们从概念层面理解了波束搜索。让我们更深入地了解其工作原理的细节。我们将继续使用相同的示例,并使用 2 的束宽度。
继续使用我们的序列到序列模型,编码器和解码器可能是一个由一些 LSTM 层组成的循环网络。或者,它也可以使用 Transformers 而不是循环网络来构建。

基于 LSTM 的序列到序列模型
让我们关注解码器组件和输出层。
第一个位置:
在第一个时间步中,它使用编码器的输出和 <START> 标记的输入来生成第一个位置的字符概率:

第一个位置的字符概率
现在它选择两个概率最高的字符,例如“A”和“C”。
第二个位置:
对于第二个时间步,它像以前一样使用编码器的输出运行解码器两次。除了第一个位置中的“”标记外,它还强制在第一个解码器运行中将第二个位置的输入设置为“A”。在第二个解码器运行中,它强制将第二个位置的输入设置为“C”:
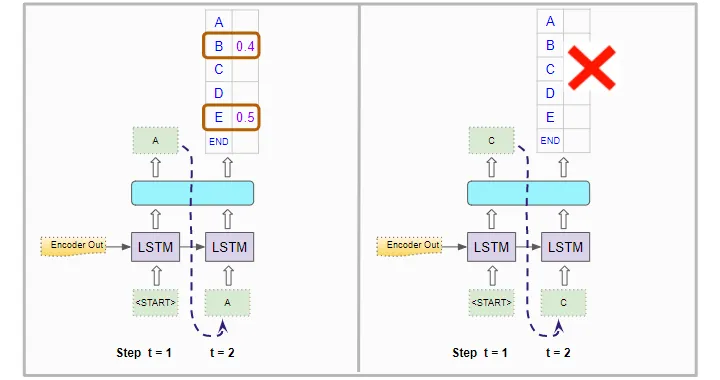
第二个位置的字符概率
它为第二个位置生成字符概率。但这些是单个字符概率。它需要计算前两个位置中字符对的组合概率。假设“A”已固定在第一个位置,则“AB”对的概率是“A”出现在第一个位置的概率乘以“B”出现在第二个位置的概率。下面的示例显示了计算过程:
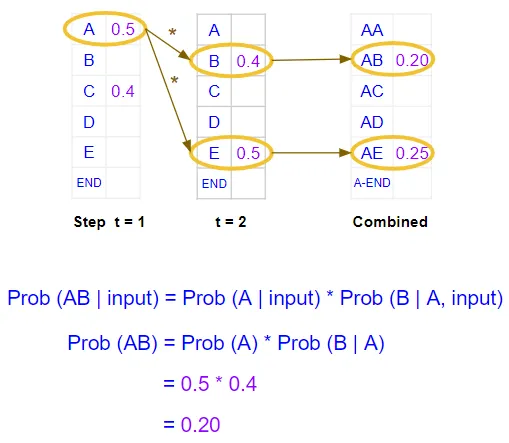
计算前两个位置中字符对的概率
它对两次解码器运行都执行此操作,并在两次运行中选择组合概率最高的字符对。因此,它选择了“AB”和“AE”:
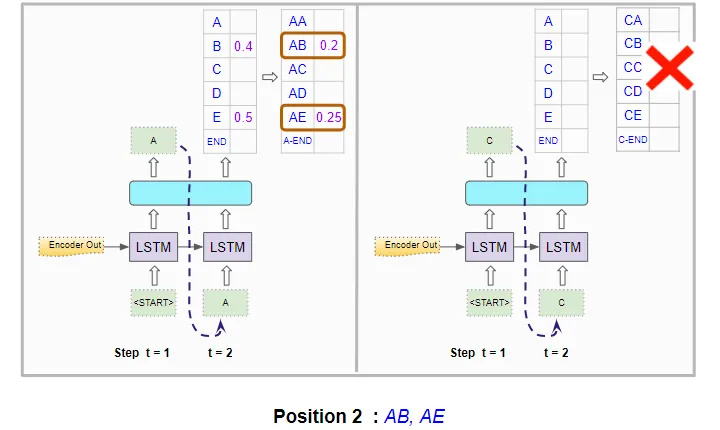
该模型根据组合概率选择两个最佳字符对
第三个位置:
对于第三个时间步骤,它再次像以前一样运行解码器两次。除了第一个位置中的 <START> 标记外,它还强制在第一个解码器运行中将第二个位置和第三个位置的输入分别设置为“A”和“B”。在第二个解码器运行中,它强制将第二个位置和第三个位置的输入分别设置为“A”和“E”:
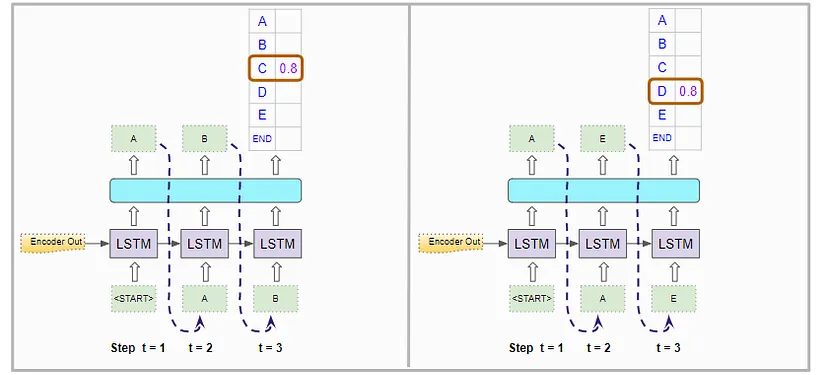
第三个位置的字符概率
它计算前三个位置中字符三元组的组合概率:

计算前三个位置中字符三元组的概率
它在两次运行中挑选出两个最佳的,因此挑选出“ABC”和“AED”:
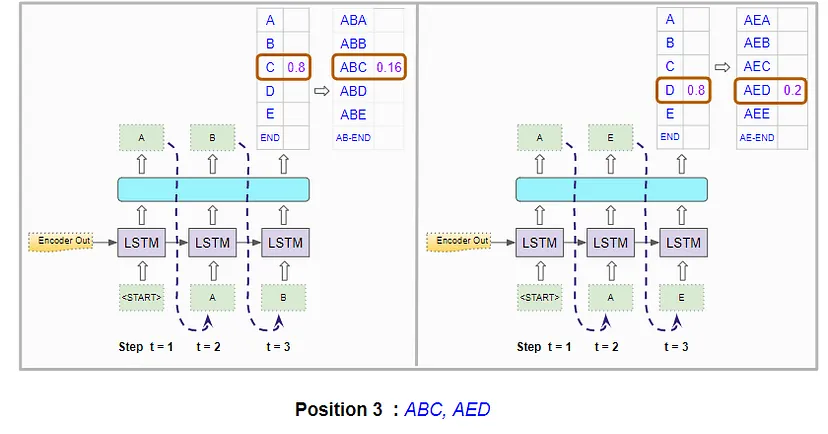
该模型根据组合概率选择两个最佳字符三元组
重复至结束标记:
它重复此过程,直到生成两个以 <END> 标记结尾的最佳序列。
然后它选择具有最高组合概率的序列来进行最终预测。
5、结束语
本文介绍了 Beam Search 的作用、工作原理以及它为何能给我们带来更好的结果。这需要增加计算量并延长执行时间。因此,我们应该评估这种权衡是否适合我们的应用程序用例。
原文链接:NLP波束搜索图解 - BimAnt