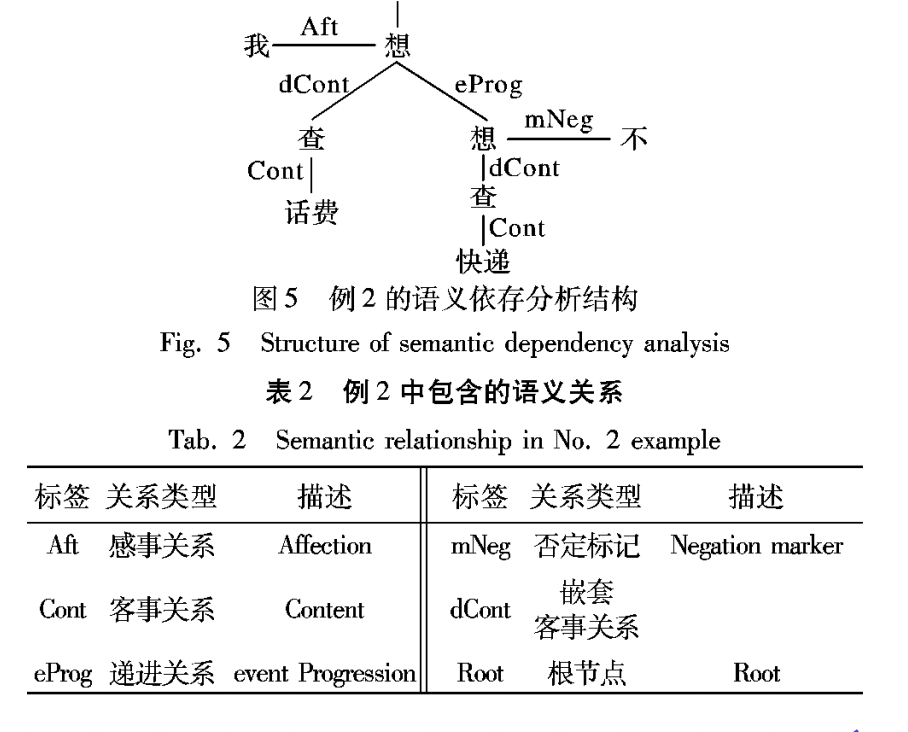
定时任务
需要在项目启动类添加注解开启支持定时任务:

以下示例是定时任务插入数据的操作:
package com.yupi.yupao.once.importuser;
import com.yupi.yupao.mapper.UserMapper;
import com.yupi.yupao.model.domain.User;
import org.springframework.stereotype.Component;
import org.springframework.util.StopWatch;
import javax.annotation.Resource;
/**
* 导入用户任务
*
*/
@Component
public class InsertUsers {
@Resource
private UserMapper userMapper;
/**
* 批量插入用户
*/
// initialDelay 每隔多少毫秒执行一次 fixedRate 执行的时间间隔 所以两个结合起来可以控制定时任务只执行一次
// @Scheduled(initialDelay = 5000, fixedRate = Long.MAX_VALUE)
public void doInsertUsers() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
final int INSERT_NUM = 1000;
for (int i = 0; i < INSERT_NUM; i++) {
User user = new User();
user.setUsername("假鱼皮");
user.setUserAccount("fakeyupi");
user.setAvatarUrl("https://636f-codenav-8grj8px727565176-1256524210.tcb.qcloud.la/img/logo.png");
user.setGender(0);
user.setUserPassword("12345678");
user.setPhone("123");
user.setEmail("123@qq.com");
user.setTags("[]");
user.setUserStatus(0);
user.setUserRole(0);
user.setPlanetCode("11111111");
userMapper.insert(user);
}
stopWatch.stop();
System.out.println(stopWatch.getTotalTimeMillis());
}
}
这种插入方法过程:建立数据库连接会话,插入一条数据,关闭数据库连接会话。如果需要插入非常多条数据,可能等待非常久(1000条90s)。
上述 for 循环插入数据的问题:
- 建立和释放数据库连接(批量查询解决)
- for 循环是绝对线性的(并发)
并发注意执行的先后顺序无影响,不要使用非并发类的集合。
package com.yupi.yupao.service;
import com.yupi.yupao.model.domain.User;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.util.StopWatch;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.*;
/**
* 导入用户测试
*
*/
@SpringBootTest
public class InsertUsersTest {
@Resource
private UserService userService;
// 核心线程数(默认运行的线程数): 40, 最大线程数:1000,存活时间;10000, 单位,任务队列长度:10000
private ExecutorService executorService = new ThreadPoolExecutor(40, 1000, 10000, TimeUnit.MINUTES, new ArrayBlockingQueue<>(10000));
/**
* 批量插入用户
*/
@Test
public void doInsertUsers() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 一共插入 10w 条数据
final int INSERT_NUM = 100000;
List<User> userList = new ArrayList<>();
for (int i = 0; i < INSERT_NUM; i++) {
User user = new User();
user.setUsername("原_创 【鱼_皮】https://t.zsxq.com/0emozsIJh");
user.setUserAccount("fakeyupi");
user.setAvatarUrl("https://636f-codenav-8grj8px727565176-1256524210.tcb.qcloud.la/img/logo.png");
user.setGender(0);
user.setUserPassword("12345678");
user.setPhone("123");
user.setEmail("123@qq.com");
user.setTags("[]");
user.setUserStatus(0);
user.setUserRole(0);
user.setPlanetCode("11111111");
userList.add(user);
}
// 18 秒 10 万条
// 1w 条为一组
userService.saveBatch(userList, 10000);
stopWatch.stop();
System.out.println(stopWatch.getTotalTimeMillis());
}
/**
* 并发批量插入用户
*/
@Test
public void doConcurrencyInsertUsers() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 分 20 组 一组 5000 条
int batchSize = 5000;
int j = 0;
List<CompletableFuture<Void>> futureList = new ArrayList<>();
for (int i = 0; i < 20; i++) {
List<User> userList = new ArrayList<>();
while (true) {
j++;
User user = new User();
user.setUsername("假鱼皮");
user.setUserAccount("fakeyupi");
user.setAvatarUrl("https://636f-codenav-8grj8px727565176-1256524210.tcb.qcloud.la/img/logo.png");
user.setGender(0);
user.setUserPassword("12345678");
user.setPhone("123");
user.setEmail("123@qq.com");
user.setTags("[]");
user.setUserStatus(0);
user.setUserRole(0);
user.setPlanetCode("11111111");
userList.add(user);
if (j % batchSize == 0) {
break;
}
}
// 异步执行
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
System.out.println("threadName: " + Thread.currentThread().getName());
userService.saveBatch(userList, batchSize);
}, executorService);
futureList.add(future);
}
CompletableFuture.allOf(futureList.toArray(new CompletableFuture[]{})).join();
// 6 秒 10 万条
stopWatch.stop();
System.out.println(stopWatch.getTotalTimeMillis());
}
}
用户插入单元测试,注意打包时要删掉或忽略,不然打一次包就插入一次
// CPU 密集型:分配的核心线程数 = CPU - 1
// IO 密集型:分配的核心线程数可以大于 CPU 核数
默认情况下,上述不同的分组组合结果也会不同,而且并不是一组数越大越好,因为线程数如果不自定义的话是默认的,根据不同的电脑,默认分配的线程数是不一样的。
也就是说,一部分线程干了一次活,可能也有一部分线程干了两次活。所以干了两次活的这部分线程就是时间消耗的主要原因。
所以后面我们自定义的线程池可能会提高性能。