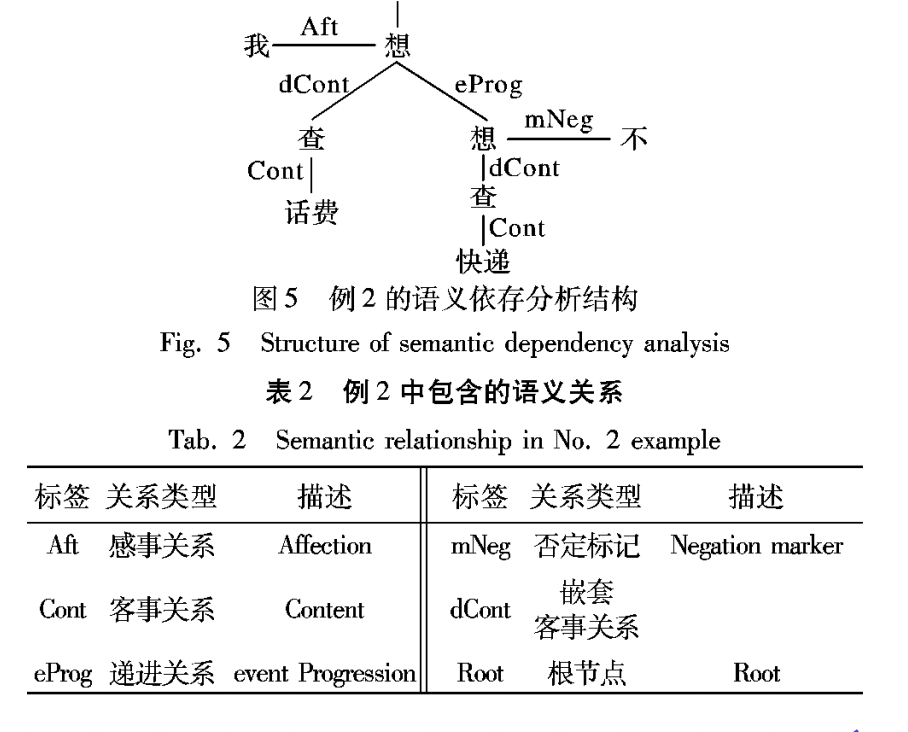
简介
学件由周志华教授在 2016 年提出 [1, 2]。在学件范式下,世界各地的开发者可分享模型至学件基座系统,系统通过有效查搜和复用学件帮助用户高效解决机器学习任务,而无需从零开始构建机器学习模型。
北冥坞是学件的第一个系统性开源实现,为学件相关研究提供了一个初步科研平台。有分享意愿的开发者可自由提交模型,学件坞协助产生规约形成学件存放在学件坞中,开发者在这个过程中无需向学件坞泄露自己的训练数据。未来的用户可以通过向学件坞提交需求,在学件坞协助下查搜复用学件来完成自己的机器学习任务,且用户可以不向学件坞泄露自有数据。预计在学件坞拥有数以百万计的学件后,将可能出现“涌现”行为:以往没有专门开发过模型的机器学习任务,可能通过复用若干个现有学件而解决。
学件由性能优良的机器学习模型和描述模型的规约组成。规约刻画了模型的能力,使得模型在未来能够根据用户需求被充分识别和复用。规约由两部分构成:语义规约通过文本描述模型的功能,而统计规约刻画模型所蕴含的统计信息。
[1] Zhi-Hua Zhou. Learnware: on the future of machine learning. Frontiers of Computer Science, 2016, 10(4): 589–590
[2] 周志华. 机器学习: 发展与未来. 中国计算机学会通讯, 2017, vol.13, no.1 (2016 中国计算机大会 keynote)

官网地址:https://bmwu.cloud/
北冥坞不但可以让科研人员和用户像使用HuggingFace一样上传自己的模型,还可以基于基座系统,根据用户的需求进行模型匹配、协作融合,高效处理用户的学习任务。
论文地址:https://arxiv.org/abs/2401.14427
北冥坞系统仓库:https://www.gitlink.org.cn/beimingwu/beimingwu
科研工具包仓库:https://www.gitlink.org.cn/beimingwu/learnware
原理
学件由机器学习模型和描述模型的规约构成,即「学件 = 模型 + 规约」。
学件的规约由「语义规约」和「统计规约」两部分组成:
1)语义规约通过文本对模型的类型及功能进行描述;
2)统计规约则通过各类机器学习技术,刻画模型所蕴含的统计信息。
学件的规约刻画了模型的能力,使得模型能够在未来用户事先对学件一无所知的情况下被充分识别并复用,以满足用户需求。

规约是学件基座系统的核心组件,串联了系统中关于学件的全部流程,包括学件上传、组织、查搜、部署与复用。
就像《天龙八部》中的燕子坞由很多小岛组成一样,北冥坞中的规约也像一个个的小岛一样。
来自不同特征/标记空间的学件,构成众多的规约岛屿,所有规约岛屿共同构成学件基座系统中的规约世界。在规约世界中,如果能够发现并建立不同岛屿之间的联系,那么相对应的规约岛屿将可以进行合并。
在学件范式下,世界各地的开发者可分享模型至学件基座系统,系统通过有效查搜和复用学件帮助用户高效解决机器学习任务,而无需从零开始构建机器学习模型。
北冥坞是学件的第一个系统性开源实现,为学件相关研究提供了一个初步科研平台。

有分享意愿的开发者可自由提交模型,学件坞协助产生规约形成学件存放在学件坞中,开发者在这个过程中无需向学件坞泄露自己的训练数据。
未来的用户可以通过向学件坞提交需求,在学件坞协助下查搜复用学件来完成自己的机器学习任务,且用户可以不向学件坞泄露自有数据。
而且以后,在学件坞拥有数以百万计的学件后,将可能出现「涌现」行为:以往没有专门开发过模型的机器学习任务,可能通过复用若干个现有学件而解决。

北冥坞特性
如下图所示,北冥坞学件基座系统作为学件的初步科研平台,首次实现了学件范式中的核心流程:
- 提交阶段:系统内置了多重检测机制,以确保上传学件的质量。另外,系统会根据已有的学件规约,训练一个异构引擎,用于合并不同的规约岛屿,以及为学件赋予新规约。随着更多学件的上传,系统的异构引擎将持续更新,目标是通过系统内学件规约的持续迭代,构建更加精准的规约世界。
- 部署阶段:用户上传任务需求后,系统会自动选择是推荐单学件还是多学件组合,并提供高效的部署方式。无论是单个学件还是多学件组合,系统均提供了便捷的学件复用接口。

此外,北冥坞系统还具备以下特性:
- 学件规约生成:北冥坞系统在 learnware Python 包中提供规约生成接口,支持多种数据类型(表格、图像和文本),可以在本地高效生成。
- 学件质量检测:北冥坞系统内置了多重检测机制,以确保系统中每个学件的质量。
- 学件多样查搜:北冥坞系统同时支持语义规约和统计规约的查搜,覆盖的数据类型包括表格、图像、文本。另外,对于表格型任务,系统额外支持初步的异构表格学件的查搜。
- 学件本地部署:北冥坞系统在 learnware Python 包中同时提供学件部署与学件复用的接口,帮助用户以统一的方式便携地部署与复用学件。
- 保护原始数据:北冥坞系统所涉及的学件上传、查搜、部署均无需用户泄露原始数据,生成统计规约的过程在用户本地进行且代码公开。
- 面向社区开源:北冥坞系统面向社区开源,包括 learnware Python 包与前后端代码。其中 leanrware 包高度可扩展,未来新的规约设计、学件系统设计、学件查搜和复用方法都能轻松集成进来。
北冥坞系统总体架构
如下图所示,北冥坞的系统架构包含四个层次,从学件存储层至用户交互层,首次自底向上系统性地实现了学件范式。四个层次的具体功能如下:

- 学件存储层:管理以zip包格式存储的学件,并通过学件数据库提供相关信息的获取方式;
- 系统引擎层:囊括了学件范式中的所有流程,包括学件上传、检测、组织、查搜、部署和复用,并以learnware Python包的形式独立于后端和前端运行,为学件相关任务和科研探索提供了丰富的算法接口;
- 系统后端层:实现了北冥坞的工业级部署,提供了稳定的系统在线服务,并通过提供丰富的后端API支撑了前端和客户端的用户交互;
- 用户交互层:实现了基于网页的前端和基于命令行的客户端,为用户交互提供了丰富且便捷的方式。
基于上述系统架构,北冥坞项目一共包含如下五个子项目:
- 系统引擎:实现了学件范式中的核心组件和算法,并提供了一个基于命令行的客户端以便于用户交互,同时将其作为 learnware 包发布。
- 系统前端:提供了用户与系统交互的界面和功能,包括主系统和管理员系统。
- 系统后端:负责处理系统的运行逻辑和数据操作,确保系统的稳定性和高性能。
- 系统文档:维护系统的文档,包括用户指南、开发指南等,确保系统的易用性。
- 系统部署:负责管理系统的部署配置,包括前后端的部署文件。
实验评估
在论文中,研究团队还构建了各种类型的基础实验场景,评估表格、图像和文本数据上进行规约生成、学件识别和复用的基准算法。
表格数据实验
在各种表格数据集上,团队首先评估了从学件系统中识别和复用与用户任务具有相同特征空间的学件的性能。
而且,由于表格任务通常来自不同的特征空间,研究团队还对来自不同特征空间的学件的识别和复用进行了评估。
同质案例
在同质案例中,PFS数据集中的53个商店充当53个独立用户。
每个商店利用自己的测试数据作为用户任务数据,并采用统一的特征工程方法。这些用户随后可以在基座系统上查搜与其任务具有相同特征空间的同质学件。
当用户没有标注数据或标注数据量有限时,团队对不同的基准算法进行了比较,所有用户的平均损失如下图所示。左表显示,无数据方法比从市场上随机选择和部署一个学件要好得多;右图表明,当用户的训练数据有限时,识别并复用单个或多个学件比用户自训练的模型性能更优。

左表显示,无数据方法比从市场上随机选择和部署一个学件要好得多;右图表明,当用户的训练数据有限时,识别并复用单个或多个学件比用户自训练的模型性能更优。
异构案例
根据市场上学件与用户任务的相似性,异构案例可进一步分为不同的特征工程和不同的任务场景。
- 不同的特征工程场景:
下图左显示的结果表明,即使用户缺乏标注数据,系统中的学件也能表现出很强的性能,尤其是复用多个学件的AverageEnsemble方法。

- 不同的任务场景:
上图右显示了用户自训练模型和几种学件复用方法的损失曲线。
很明显,异构学件在用户标注数据量有限的情况下实验验证是有益的,有助于更好地与用户的特征空间进行对齐。
图像和文本数据实验
此外,研究团队在图像数据集上对系统进行了基础的评估。
下图显示,当用户面临标注数据稀缺或仅拥有有限数量的数据(少于 2000 个实例)时,利用学件基座系统可以产生良好的性能。

团队还在基准的文本数据集上对系统进行了基础评估。通过统一的特征提取器进行特征空间对齐。
如下图所示,即使在没有提供标注数据的情况下,通过学件识别和复用所获得的性能也能与系统中最好的学件相媲美。
此外,与从头开始训练模型相比,利用学件基座系统可以减少约2000个样本。