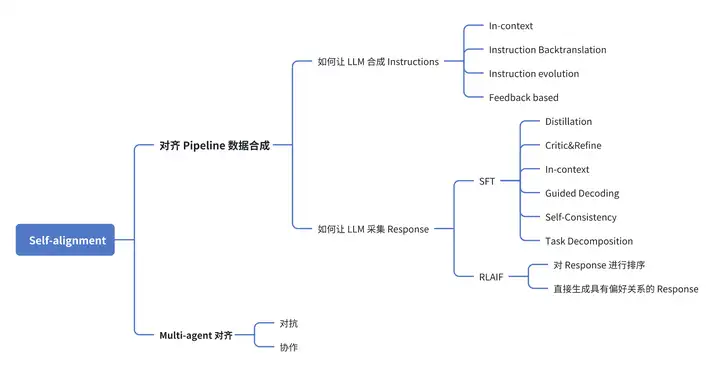
LLM 自对齐技术最新研究进展分享 系列文章继续更新啦!本系列文章将基于下图的架构,对当前 Self-alignment 相关工作进行全面梳理,厘清技术路线并分析潜在问题。
添加图片注释,不超过 140 字(可选)
在上一篇文章中,我们主要探讨了 “如何让 LLM 合成 Instructions”,解决了 Instructions 从哪里来的问题,接下来要解决的问题就是如何让 LLM 采集 Response,那么此时我们需要面临抉择,到底是要进行 SFT 还是 RLAIF 方式进行对齐,不同的选择需要用到不同的方式。
SFT
SFT 路线的目标是让 LLM 合成符合 3H 原则的回答:Helpful、Honest、Harmless。 目前工作采用如下几种常见方法采集高质量回答,包括 Distillation、Critic&Refine、In-context、Guided Decoding、Self-Consistency、Task Decomposition 这些方法。
Distillation
Distillation 的思路在于得到其他 Strong model 的回答,之后可以直接在该回答上进行微调,比如 Baize 和 UltraChat 都是收集其他 LLM 的对话数据,再进行蒸馏。 虽然蒸馏省事简单,但是可能会遇到如下几个问题:
-
受 Strong model 的能力瓶颈限制。
-
受 Strong model 的 Bias 影响,可以借鉴 Co-Supervised Learning 的思想不限制 Response 的来源,从多个 Strong model 进行蒸馏缓解该问题。
-
Strong model 的回答可能跟当前模型并不适配,需要进一步筛选。Selective Reflection-Tuning 不再将 Teacher model 的 Response 直接拿来蒸馏,而是对这些 Response 筛选出合适的,他们利用 Student model 的困惑度计算了一个 r-IFD 分数,该分数筛选得到的 Response 对于 Student model 来说与 Instructions 更加适配,这些 Response 更适合 Student model 进行学习。
Critic&Refine
该方法主要利用 LLM 的 Critic 和 Refine 能力。LLM 可以根据评论建议对自己的 Response 进行修改完善,利用该能力可以提高 Response 的质量。
SELF-REFINE 是较早挖掘 LLM Refine 能力的工作,对于生成的 Response,SELF-REFINE 让 LLM 自己对其进行评论,之后根据评论再对 Response 进行 Refine。
这里 Critic 可以由其他 Strong model 生成,之后 LLM 根据该 Critic 进行 Refine。IterAlign 让 LLM 通过self-reflection 对自己的 Response 进行 Refine,这里进行 self-reflection 时 LLM 参考了 GPT-3.5 的建议,之后 LLM 在 Refine 后的数据上进行 SFT。
我们也可以将 Critic、Refine 都交给 Strong model 来进行,LEMA 利用 GPT-4 对 LLM 不正确的 Response 进行错误定位、错误解释、错误修改,这些 GPT-4 的回答与分析将用来对当前 LLM 微调。 利用 Critic、Refine 来得到高质量 Response 可能有如下几个问题,这些问题的回答可以更好地利用这些能力:
-
如何对 LLM 的 Critic、Refine 的能力进行测评。The critique of critique 构建了一个评测 Critic 的量化指标——MetaCritique ,该指标越高,模型的 Critic 可以引出更好的 Refine 结果。
-
如何提高 LLM 的Critic、Refine 的能力。CriticBench 对 LLM 推理任务下的 Critic、Refine 能力进行了测评,发现 LLM 的 Generation 能力和批评、纠错的能力存在线性关系。
In-context
In-context 主要利用 LLM 的上下文学习能力,通过在 Prompt 中加入一些示例等上下文信息,引导产生相似回答,这里的信息可以是直接固定在上下文中,或者动态加入到上下文中。
-
固定上下文信息:该方式一般会预定义好一些 Rules,并加入一些跟对齐目标相关 Examples,如 SELF-ALIGN 在 In-context 中加入 5 个示例和 16 个 Principles,让 LLM 生成符合这些 Principle 的回答。
-
动态引入:该方式中的上下文信息不再固定,而是根据当前 Instructions 从数据库中检索出相关的示例,或者是直接从 LLM 中提取。比如 Human-Instruction-Free 希望提高 Specific Domain 下合成 Response 的质量,他们通过检索的方式从该 Domain 下的数据库中选择问题相似的 Examples 来作为上下文。OPO 也是采用了检索的方式,根据问题从数据库中检索相关的法律规定等信息加入到上下文中。
In-context 方法面临的问题主要在于对上下文中的信息较为敏感,需要根据对齐表现不断改进上下文的设计,如果需要更换任务则需要重新设计引入的信息。另外 In-context 方式生成 Response 也部分利用了现有数据的先验信息,未来也可以继续探索新的挖掘方式来为上下文引入更多信息。
Guided Decoding
对 LLM 的解码过程进行引导,可以提高回答的质量,此时一般需要对 LLM 的采样过程构建树或者图结构,选择高奖励值的路径。这种技术一般被用在解决复杂推理问题或者是提前中断可能会包含 Harmfule 内容的路径。
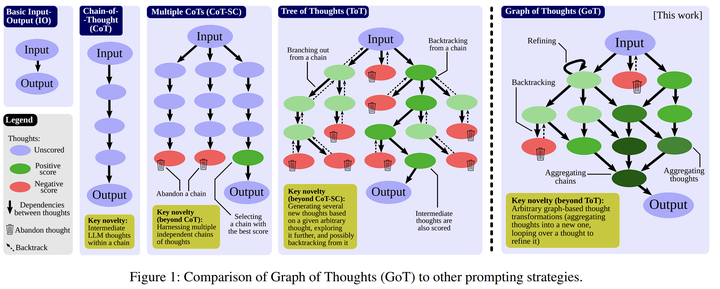
Guided Decoding 早期的相关工作为 CoT 技术,提示让 LLM 输出推理的中间步骤,只不过 CoT 的推理过程是一个简单的直线顺序结构,后续工作提出可以用树结构或图结构来表示推理过程,在构建树或者图的过程中对解码过程进行引导。
ToT 用树结构来表示LLM的思考过程,其中每个节点表示下一步采取的步骤、计划,LLM 会对每一个节点进行评价,选择最好的节点继续向下展开。GoT 在 ToT 的基础上对树结构进行了改进,将解码过程用一个图来表示,不同节点可以汇聚生成新的节点。
添加图片注释,不超过 140 字(可选)
除了聚焦于推理问题,Guided Decoding 也可以生成无害的回答。RAIN 就采用该技术提前裁剪掉可能包含有害内容的节点。
Guided Decoding 面临的主要问题在于采样效率,需要由其他模型进行状态估计,不过可以对该过程得到的答案进行蒸馏,推理时正常解码。比如 ALPHALLM 将该技术与 Self-training 进行结合。他们拿这种方式搜索得到的 Response 当做模型微调的数据,迭代进行 Self-training。
Self-Consistency
Self-Consistency 指的是当对 Response 进行多次采样时,正确答案可能会占据大多数,我们可以利用多数投票等方法得到正确的 Response,该技术可以帮助合成正确答案数据。Large Language Models Can Self-Improve 利用 CoT 和 Self-Consistency 来让模型进行自提升,产生正确的回答后作为微调数据将其蒸馏到参数中。
Task Decomposition
Task Decomposition 思路是采用分而治之的想法,对复杂任务进行拆解,分个解决后再汇总得到最终答案。 Decomposed Prompting 将复杂任务拆解后交给其他 LLM(当前 LLM 的 Copy)一起做,其他 LLM 接到任务后可以进一步拆解。LEAST-TO-MOST 则将复杂任务拆解为一个个接连的子任务,每一个任务的完成都能帮助后面的任务。Plan-and-Solve Prompting 则让 LLM 首先制定当前任务的计划,之后再根据该计划一步一步完成。
Task Decomposition 方法面临的主要问题在于:
-
将复杂任务拆分成这一步可能本来就是最困难的。
-
协作过程中错误可能累积。
-
部分任务并行化困难。某些任务只能顺序解决,无法多个 LLM 之间并行解决,会影响效率问题。
RLAIF
除了选择 SFT 这种方式进行参数更新,另一种就是 RLAIF。RLAIF 的主要目标在于自动采集偏好数据,来替代人类反馈。可以分为两个主要方法:
-
对产生的 Response 进行排序
-
直接生成具有偏好关系的 Response
对 Response 进行排序
我们可以用 LLM 来代替人类从多个回答中选择出较好的,这些选择结果将作为偏好数据来对模型进一步对齐。 CAI 是最早提出 RLAIF 的概念,尝试用 AI 来替代人类选择偏好数据,他们让 AI 来选择符合宪法要求的 Response,这种方法后面也用到了许多工作中,但是早期 RLAIF 的工作存在如下几个问题:
-
这些 AI 偏好选择产生的数据都是离线的,与当前正在训练的 LLM 的分布有偏差,可能会面临 Distribution shift 的问题,因此部分后续工作在 On-policy 这一点上继续改进。OAIF 采用另外的 Annotating model 来进行 Online 的偏好数据选择,SELF-JUDGE 提前训练好一个 Judge model,然后用该 Judge model 对当前产生的 Response 进行偏好选择。
-
另外一个问题则是奖励模型在训练中一般是冻结参数的,可能会随着训练进行无法继续提供有效的奖励信号,或者遇到 Rewad hack 问题。Self-Rewarding 提出让 LLM 自己当做奖励模型,每轮迭代时拿自己选择的偏好数据进行 DPO 训练,这样奖励模型会随着模型进化也会不断提高。
-
奖励模型一旦训练完成,我们无法再重新修改偏好。为了实现更精细化、动态的偏好选择,SALMON 引入了一个 Instructable Reward Model,可以在对齐时根据任意 principle 来对 Response 进行动态打分。
-
当模型对齐程度已经比较好的时候,用其他模型对 Response 排序会比较困难,不同 Response 之间可能没有明显差别。此时我们可以引入其他信号来帮助排序,CycleAlign 认为可以利用 LLM 自己产生 Response 的概率来辅助排序,首先分别用 Response 概率和其他模型排序得到两个结果,之后选择这两个结果的最长公共序列作为最终排序结果。
由于对 Response 进行排序本质是基于 LLM 的 Judge 能力,我们也可以对这种能力进一步拓展。
-
利用工具或代码:AUTOIF 让 LLM 自己针对 Instructions 的要求生成验证的代码,这些代码可以判断 Response 是否符合指令的要求。
-
LLM 集成:PoLL 选择用多个模型来进行 Judge,缓解单一模型带来的 Bias。
直接生成具有偏好关系的 Response
除了对 Response 排序得到偏好数据,还可以用某些方法引导模型直接产生偏好数据。这种方式产生的偏好数据一般有清晰的偏好关系,包含的噪音更少,可以通过以下几种方式进行生成:
-
通过 Prompt 直接生成:这种方式需要给出相反的指令,进而让模型产生相反的 Response。
GRATH 对于同一个 Questions,直接在 Prompt 中指明让 LLM 生成正确的答案和错误的答案,之后拿这些数据进行 DPO 训练,迭代进行该过程可以提高 LLM 的 truthfulness。RLCD 对 LLM 输入成对相反的 Prompt(如 Harmless 和 Harmfull),不同 Prompt 下得到的 Response 就可以直接作为偏好数据。
-
通过模型探索轨迹生成:多次采样,收集 LLM 的每一步探索和对应结果,对应的正确和错误的结果可以当做偏好数据。
UltraInteract 利用 LLM 的 Response 构造了一棵 Preference Tree,这棵 Preference Tree 是二叉树,根节点为 Instruction,每个节点的子节点分别是正确和错误的 Response,对于错误的 Response,LLM 会根据环境反馈和 GPT-4 的建议进行 Refine,之后继续向下对树进行拓展。当一颗 Preference Tree 构建完毕,每对子节点就是一个偏好数据。
-
通过对不同数据来源做出假设:对不同数据来源提前设定好一个偏好顺序,例如假定专家模型的回答优于当前较弱模型的回答,采集这些回答也可以构造偏好数据。
RLAIF 将人类反馈用 AI 反馈来进行替代,随之而来的一个问题在于我们无法确保 AI 提供的反馈是否本来就和人类对齐,另外为什么 AI 提供的反馈可以作为有效的对齐信号。例如 CriticBench 认为可能是有一部分知识模型难以通过生成的方式利用,只能通过评价反馈的方式利用。Self-Rewarding 则认为模型的反馈能力是指令跟随能力的副产品,随着模型不断对齐,其提供反馈的能力也在不断提高。
总结
本文我们重点探讨了“如何让 LLM 采集 Response”,解决了如何拿到 Response 的问题。至此,对于“对齐 Pipeline 数据合成”路线的 Self-alignment,我们需要关注的两大问题已全部有了答案。
在下一篇文章,我们将继续探讨 Self-alignment 的另一实现路线——Multi-agent 对齐,敬请期待哦!
系列传送门
LLM自对齐技术最新研究分享(一):对齐 Pipeline 数据合成(上)-CSDN博客
LLM自对齐技术最新研究分享(二):对齐 Pipeline 数据合成(下)-CSDN博客