1. git仓库
https://github.com/abbothzhang/fastcache
2. 整体原理
- initCache时不会申请内存,只有第一次set时候才会申请,且会一次性申请64MB,后面不够了又一次性申请1024*64MB大小内存
2.1. 时序图

3. 高性能原因
- 将cache分为512个bucket,每个bucket一个锁,将锁竞争维度降低, 增加并发度
- map定义为map[uint64]uint64, value里只存索引,真正的值放在二维数组里,这样GC时无需遍历,减少stw
- 堆外内存申请二维数组,无需GC
- 使用很多位运算,快速且节省空间
4. 注意点
- 一次会申请1024个chunk大小的内存,即1024*64KB=64MB大小的内存,如果初始化cache时候设置的缓存大小小于64MB,也会申请这么大
- 没有过期时间设置,FIFO的过期方式, 只靠缓存环覆盖
- 内存申请到初始化时设置的最大内存后,就会一直保持,不会释放
- 缓存数据大小超过
64K, 需要调用SetBig方法存储
5. 数据结构
- chunk为byte数组,作为环形缓冲区使用
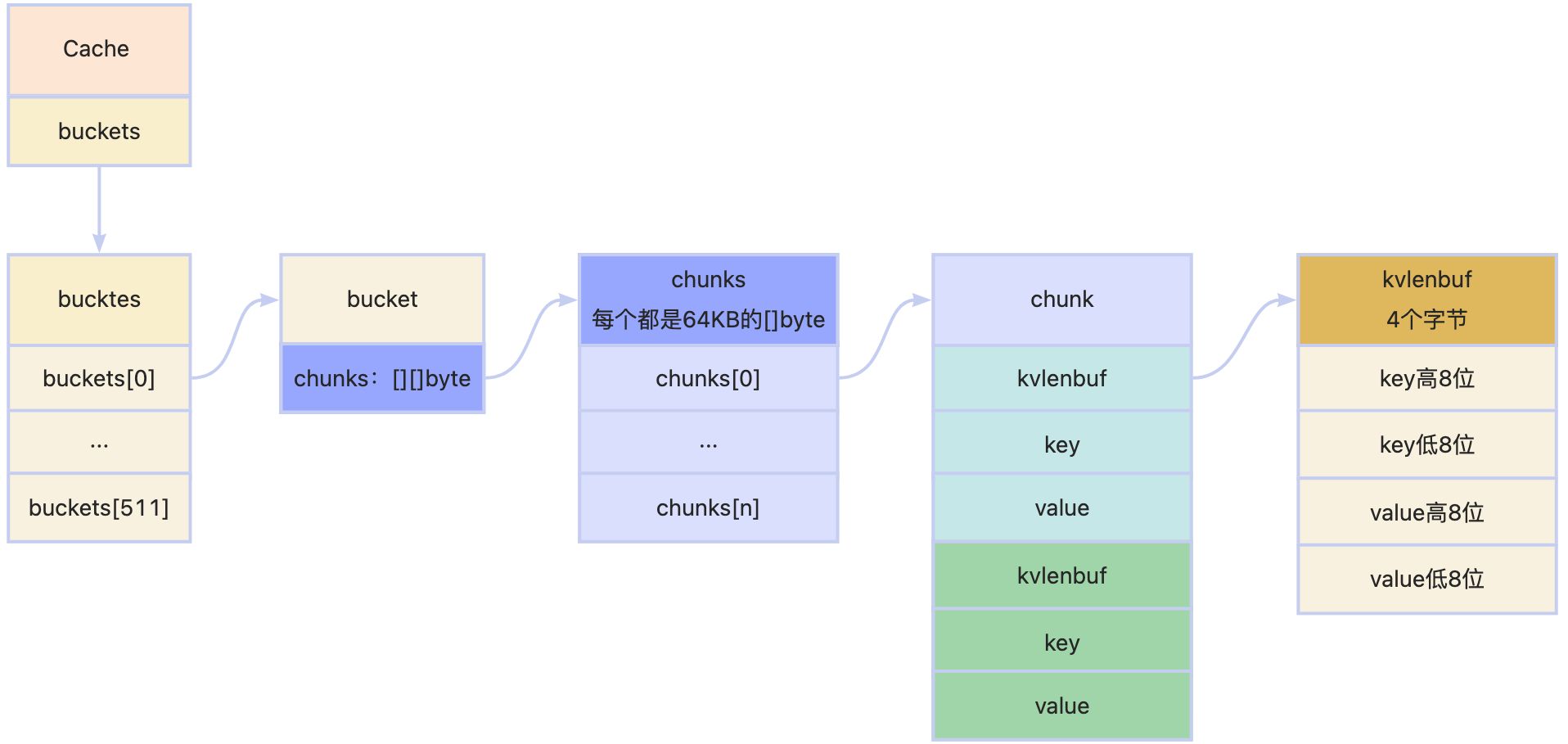
6. 初始化
6.1. 初始化入口
func New(maxBytes int) *Cache {
if maxBytes <= 0 {
panic(fmt.Errorf("maxBytes must be greater than 0; got %d", maxBytes))
}
var c Cache
maxBucketBytes := uint64((maxBytes + bucketsCount - 1) / bucketsCount)
for i := range c.buckets[:] {
c.buckets[i].Init(maxBucketBytes)
}
return &c
}
6.2. bucket初始化
下面是bucket的初始化方法,需要注意的是其仅仅初始化了b.chunks的大小,并没有初始化单个chunk的内存空间(即chunkSize字节)。chunk的初始化是在实际使用时从freeChunks申请的,这样可以避免预先分配冗余内存。这种方式有点类似底层的虚拟内存的概念,只有在真正使用的时候才会分配内存。后面会看到freeChunks是如何申请内存的
func (b *bucket) Init(maxBytes uint64) {
if maxBytes == 0 {
panic(fmt.Errorf("maxBytes cannot be zero"))
}
if maxBytes >= maxBucketSize {
panic(fmt.Errorf("too big maxBytes=%d; should be smaller than %d", maxBytes, maxBucketSize))
}
maxChunks := (maxBytes + chunkSize - 1) / chunkSize
b.chunks = make([][]byte, maxChunks)
b.m = make(map[uint64]uint64)
b.Reset()
}
6.3. 内存申请
func getChunk() []byte {
freeChunksLock.Lock()
// 检查是否有可用的内存块,如果没有,则开辟
if len(freeChunks) == 0 {
// Allocate offheap memory, so GOGC won't take into account cache size.
// This should reduce free memory waste.
//使用 unix.Mmap 分配一块较大的匿名内存区域 (chunkSize*chunksPerAlloc 字节),这块内存不会被 Go 的垃圾回收器(GOGC)计入,从而减少内存浪费。
data, err := unix.Mmap(-1, 0, chunkSize*chunksPerAlloc, unix.PROT_READ|unix.PROT_WRITE, unix.MAP_ANON|unix.MAP_PRIVATE)
if err != nil {
panic(fmt.Errorf("cannot allocate %d bytes via mmap: %s", chunkSize*chunksPerAlloc, err))
}
//将这块大内存分割成多个 chunkSize 大小的小块,每个小块被添加到 freeChunks 切片中。data 切片被逐步分割并转换成 *chunkSize 类型的指针
for len(data) > 0 {
p := (*[chunkSize]byte)(unsafe.Pointer(&data[0]))
freeChunks = append(freeChunks, p)
data = data[chunkSize:]
}
}
//从 freeChunks 切片中取出最后一个块,将其从切片中移除,并将其内容清空以防止泄露
n := len(freeChunks) - 1
p := freeChunks[n]
freeChunks[n] = nil
freeChunks = freeChunks[:n]
freeChunksLock.Unlock()
return p[:]
}
7. set
func (b *bucket) Set(key, value []byte, h uint64) {
// 原子地增加存储调用次数计数器
atomic.AddUint64(&b.setCalls, 1)
// 先行判断key、value大小,如果键 k 或值 v 的长度大于等于 65536(1<<16),方法会返回,因为下面的代码限制了只用16位存key和value
if len(key) >= (1<<16) || len(value) >= (1<<16) {
// Too big key or value - its length cannot be encoded
// with 2 bytes (see below). Skip the entry.
return
}
// zhmark kvLenBuf 表示 {key + value} 的指纹
//vLenBuf:用 4 字节存储键和值的长度(各用 2 字节编码),分别存储键的高 8 位和低 8 位长度,以及值的高 8 位和低 8 位长度,作为指纹
var kvLenBuf [4]byte
kvLenBuf[0] = byte(uint16(len(key)) >> 8)
// byte(len(k)) 只保留了 len(k) 的低 8 位
kvLenBuf[1] = byte(len(key))
kvLenBuf[2] = byte(uint16(len(value)) >> 8)
kvLenBuf[3] = byte(len(value))
//kvLen:计算键值对的总长度,包括 kvLenBuf、键 k 和值 v 的长度
kvLen := uint64(len(kvLenBuf) + len(key) + len(value))
// 如果 kvLen 大于或等于 chunkSize(块大小),方法返回,因为键值对太大,不能存储在一个块中
if kvLen >= chunkSize {
// Do not store too big keys and values, since they do not
// fit a chunk.
return
}
chunks := b.chunks
needClean := false
b.mu.Lock()
idx := b.idx
//计算新的写入位置:idxNew 是在当前索引 idx 的基础上加上 kvLen(键值对的总长度),计算出插入操作后的新位置。
idxNew := idx + kvLen
//计算 chunkIdx(当前块索引)和 chunkIdxNew(新块索引)
chunkIdx := idx / chunkSize
chunkIdxNew := idxNew / chunkSize
//如果新块索引超出了现有块的范围,需要新创建块
//如果超出块数组长度,重置索引和长度,增加生成代数 b.gen,并可能清理旧块。
//否则,调整当前块的起始索引
if chunkIdxNew > chunkIdx {
// 如果新的块索引 chunkIdxNew 超过了当前已分配的块的数量(即 chunks 切片的长度),说明需要重新初始化块
//如果下一个数据块的索引 大于 数据块的数量
if chunkIdxNew >= uint64(len(chunks)) {
// 此时采用环形缓冲区的方式: 从头开始存储数据
//将 idx 和 chunkIdx 重置为 0,并将 idxNew 设为 kvLen,这表示从新的块开始写入数据
idx = 0
idxNew = kvLen
chunkIdx = 0
//b.gen 是用于生成新的块标识符的代数。增加生成代数,并在生成代数满足一定条件时(如位掩码操作),进行额外的增加操作。
//这通常用于生成唯一的块版本标识符,帮助区分不同版本的块
b.gen++
// 如果重写次数达到上限,那么重新开始计算
// (1<<genSizeBits)-1 1先移位genSizeBits,再-1,生成genSizeBits个1
// b.gen&(1<<genSizeBits)-1,表示取b.gen的低genSizeBits位,如果低genSizeBits位都是0,
if b.gen&((1<<genSizeBits)-1) == 0 {
b.gen++
}
//设定 needClean 为 true,表示需要清理旧的块(或做其他必要的管理操作),这通常是在块已满或达到一定的容量时进行的维护操作
needClean = true
} else {
//如果 chunkIdxNew 没有超过现有块的数量,则更新当前索引 idx 和新的索引 idxNew,并设置 chunkIdx 为 chunkIdxNew。
//这表示继续在当前块内写入数据,更新索引以反映新的写入位置
idx = chunkIdxNew * chunkSize
idxNew = idx + kvLen
chunkIdx = chunkIdxNew
}
//清空当前块 chunks[chunkIdx] 的内容。
//虽然 chunks[chunkIdx] 被重新分配内存,
//但这一步骤确保当前块的内容被清空,以便新的数据可以被正确地追加到块中
// todo:2024/8/26 为什么要清理当前块数据
chunks[chunkIdx] = chunks[chunkIdx][:0]
}
//获取或创建块 chunk。
chunk := chunks[chunkIdx]
if chunk == nil {
chunk = getChunk()
chunk = chunk[:0]
}
// 指纹写入数据块
chunk = append(chunk, kvLenBuf[:]...)
// key 写入数据块
chunk = append(chunk, key...)
// value 写入数据块
chunk = append(chunk, value...)
// 更新数据块信息
chunks[chunkIdx] = chunk
// 更新哈希表 b.m 以映射哈希值 h 到当前的存储位置和版本号
// b.gen只用后24位,左移40位后,b.gen的值完全位于最右边
// 再和idx或一下,即把gen的高位放到idx里,两个值能存一起
b.m[h] = idx | (b.gen << bucketSizeBits)
//更新桶的索引 b.idx 为新的位置
b.idx = idxNew
if needClean {
// 如果缓冲区重写了,重新解析和构建数据哈希索引
b.cleanLocked()
}
b.mu.Unlock()
}
8. get
func (b *bucket) Get(dst, key []byte, hash uint64, returnDst bool) ([]byte, bool) {
atomic.AddUint64(&b.getCalls, 1)
// 初始化 found 变量为 false,表示默认没有找到匹配的数据
found := false
chunks := b.chunks
b.mu.RLock()
mapValueGenIdx := b.m[hash]
// bGen 获取当前bucket的版本号,防止因为覆盖写被误读取
// 通过位掩码 (1 << genSizeBits) - 1,bGen 提取了 b.gen 的低 genSizeBits 位。这个掩码确保只保留生成代数的有效部分,忽略其他位
currentGen := b.gen & ((1 << genSizeBits) - 1)
if mapValueGenIdx > 0 { // 如果 value 大于 0,说明存在可能的有效数据
// 检查 v 是否有效且符合当前代数 bGen
// 从 value 中提取生成代数 gen 和索引 idx。bucketSizeBits 表示索引部分的位数
gen := mapValueGenIdx >> bucketSizeBits
idx := mapValueGenIdx & ((1 << bucketSizeBits) - 1)
// 检查提取的生成代数和索引是否有效。确保数据没有被回收或被其他操作覆盖
// gen == bGen && idx < b.idx: 如果当前的桶版本号一致,并且索引小于当前的,那么是OK的
// gen+1 == bGen && idx >= b.idx:如果桶版本号比当前版本号低,但是idx比当前idx高,说明还没被覆盖,还是可以读取的
// gen == maxGen && currentGen == 1 && idx >= b.idx:如果达到最大版本,但是当前又是重写到1了,idx比当前idx高,说明还没被覆盖,还是可以读取的
if (gen == currentGen && idx < b.idx) || (gen+1 == currentGen && idx >= b.idx) || (gen == maxGen && currentGen == 1 && idx >= b.idx) {
// 计算数据块的索引
chunkIdx := idx / chunkSize
if chunkIdx >= uint64(len(chunks)) {
// 如果计算出的 chunkIdx 超出了 chunks 的范围,说明数据可能在文件加载过程中被损坏。
// 增加腐败计数器,然后跳转到 end 标签以解锁资源并返回。
atomic.AddUint64(&b.corruptions, 1)
goto end
}
chunk := chunks[chunkIdx]
idx %= chunkSize
if idx+4 >= chunkSize {
// 如果计算出的索引加上 4个字节 超出了 chunk 的范围,说明数据可能在文件加载过程中被损坏。
// 增加腐败计数器,然后跳转到 end 标签以解锁资源并返回。
atomic.AddUint64(&b.corruptions, 1)
goto end
}
kvLenBuf := chunk[idx : idx+4] // 提取包含键值长度的 4 字节数据
keyLen := (uint64(kvLenBuf[0]) << 8) | uint64(kvLenBuf[1]) // 解析键的长度
valLen := (uint64(kvLenBuf[2]) << 8) | uint64(kvLenBuf[3]) // 解析值的长度
idx += 4
if idx+keyLen+valLen >= chunkSize {
// 如果计算出的索引加上 keyLen 和 valLen 超出了 chunk 的范围,说明数据可能在文件加载过程中被损坏。
// 增加腐败计数器,然后跳转到 end 标签以解锁资源并返回。
atomic.AddUint64(&b.corruptions, 1)
goto end
}
if string(key) == string(chunk[idx:idx+keyLen]) { // 如果键匹配,防止hash碰撞
idx += keyLen
if returnDst { // 如果 returnDst 为 true,将值追加到 dst
dst = append(dst, chunk[idx:idx+valLen]...)
}
found = true
} else {
// 如果键不匹配,增加冲突计数器
atomic.AddUint64(&b.collisions, 1)
}
}
}
end:
b.mu.RUnlock() // 释放只读锁
if !found {
// 如果没有找到匹配项,增加未命中计数器
atomic.AddUint64(&b.misses, 1)
}
return dst, found // 返回结果
}