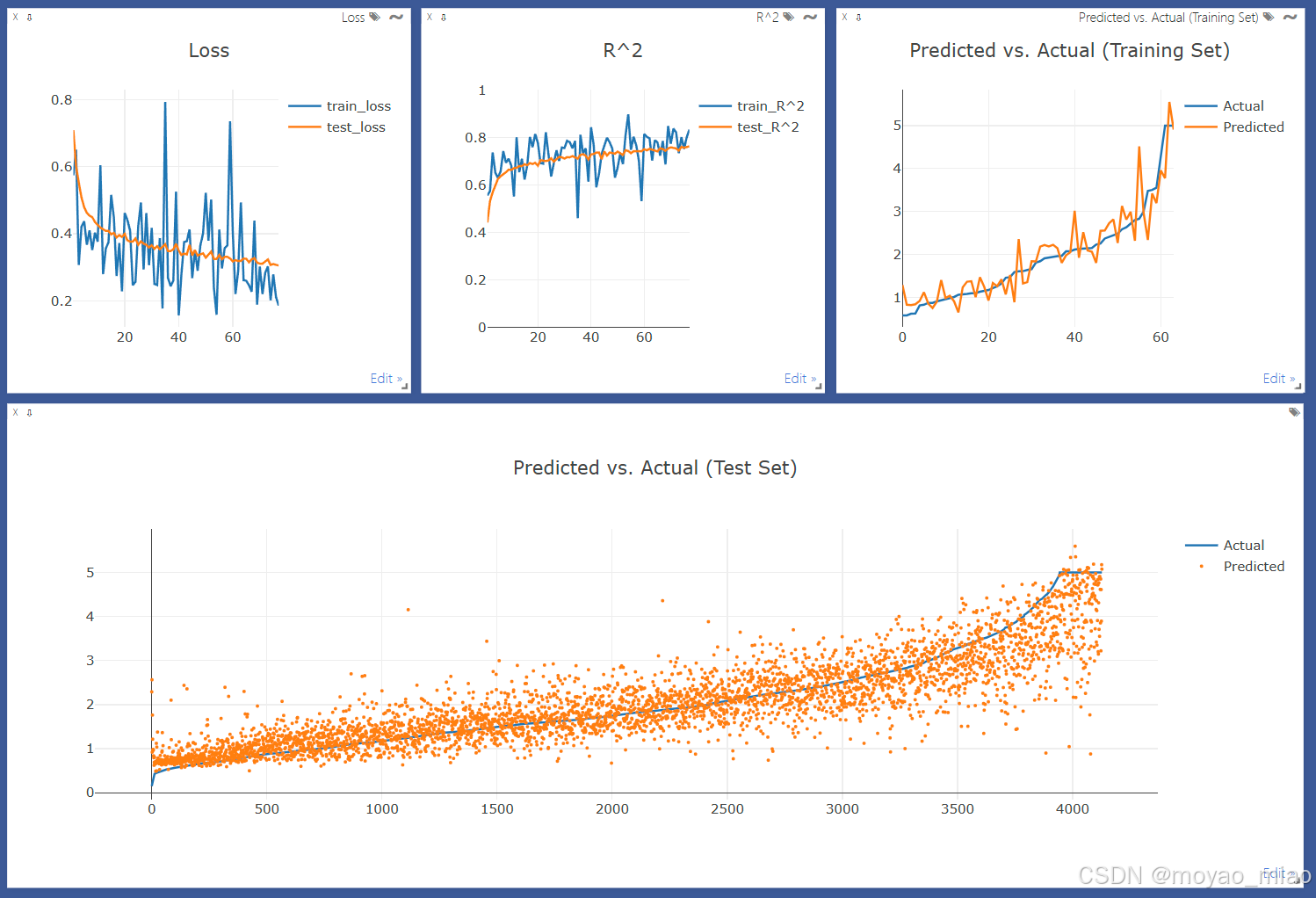
1.项目背景
近年来,印度社会关于女性权利的讨论日益频繁,然而,女性受侵害的违法事件仍层出不穷,这些事件不仅威胁到女性的生命安全,还深刻影响了社会的稳定与发展,尽管印度政府在法律和政策层面采取了一系列措施来保护女性的权利,减少性别暴力,但实际情况表明,这些措施的执行仍然存在许多挑战,女性的安全仍然面临严重威胁。在2024年8月9日,印度西孟加拉邦首府加尔各答发生了一起震惊全世界的案件,31岁的女实习医生在加尔各答一家医院的大厅睡觉时遭到侵害,最终不幸遇害,这起案件再一次引发了人们对女性安全的关注,也揭示了印度女性在公共场所和工作环境中面临的巨大风险。
本项目通过可视化分析、相关性分析和方差分析,深入探讨了印度不同年份侵害女性的事件,这些结论为进一步理解印度不同地区和不同年份的犯罪动态提供了有力的依据,并为未来的政策制定和执法提供了参考依据。
2.数据说明
| 字段 | 说明 |
|---|---|
| State | 地区 |
| Year | 年份 |
| Rape | 强奸案件数 |
| K&A | 绑架与袭击案件数 |
| DD | 聘礼致死案件数 |
| AoW | 针对女性的袭击案件数 |
| AoM | 侮辱女性贞操案件数 |
| DV | 家庭暴力案件数 |
| WT | 妇女贩卖案件数 |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import spearmanr,f_oneway
data = pd.read_csv('/home/mw/input/08236512/CrimesOnWomenData.csv')
4.数据预览及数据预处理
# 查看数据信息
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 736 entries, 0 to 735
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0 736 non-null int64
1 State 736 non-null object
2 Year 736 non-null int64
3 Rape 736 non-null int64
4 K&A 736 non-null int64
5 DD 736 non-null int64
6 AoW 736 non-null int64
7 AoM 736 non-null int64
8 DV 736 non-null int64
9 WT 736 non-null int64
dtypes: int64(9), object(1)
memory usage: 57.6+ KB
# 查看重复值
data.duplicated().sum()
0
# 删除无关的'Unnamed: 0'列
data.drop(columns=['Unnamed: 0'],inplace=True)
# 将年份转换为整数
data['Year'] = data['Year'].astype(int)
# 增加一个汇总列,计算每个地区每年发生的所有案件总数
data['Total_Crimes'] = data[['Rape', 'K&A', 'DD', 'AoW', 'AoM', 'DV', 'WT']].sum(axis=1)
print('查看各地区的名称是否存在重复的州名或者格式不一样的州名:')
print(data['State'].unique())
查看各地区的名称是否存在重复的州名或者格式不一样的州名:
['ANDHRA PRADESH' 'ARUNACHAL PRADESH' 'ASSAM' 'BIHAR' 'CHHATTISGARH' 'GOA'
'GUJARAT' 'HARYANA' 'HIMACHAL PRADESH' 'JAMMU & KASHMIR' 'JHARKHAND'
'KARNATAKA' 'KERALA' 'MADHYA PRADESH' 'MAHARASHTRA' 'MANIPUR' 'MEGHALAYA'
'MIZORAM' 'NAGALAND' 'ODISHA' 'PUNJAB' 'RAJASTHAN' 'SIKKIM' 'TAMIL NADU'
'TRIPURA' 'UTTAR PRADESH' 'UTTARAKHAND' 'WEST BENGAL' 'A & N ISLANDS'
'CHANDIGARH' 'D & N HAVELI' 'DAMAN & DIU' 'LAKSHADWEEP' 'PUDUCHERRY'
'Andhra Pradesh' 'Arunachal Pradesh' 'Assam' 'Bihar' 'Chhattisgarh' 'Goa'
'Gujarat' 'Haryana' 'Himachal Pradesh' 'Jammu & Kashmir' 'Jharkhand'
'Karnataka' 'Kerala' 'Madhya Pradesh' 'Maharashtra' 'Manipur' 'Meghalaya'
'Mizoram' 'Nagaland' 'Odisha' 'Punjab' 'Rajasthan' 'Sikkim' 'Tamil Nadu'
'Telangana' 'Tripura' 'Uttar Pradesh' 'Uttarakhand' 'West Bengal'
'A & N Islands' 'Chandigarh' 'D&N Haveli' 'Daman & Diu' 'Delhi UT'
'Lakshadweep' 'Puducherry']
有些州名存在多种拼写方式或格式,例如 “ANDHRA PRADESH” 和 “Andhra Pradesh”,以及 “BIHAR” 和 “Bihar”、‘D & N Haveli’和’D&N Haveli’
# 将所有州名标准化为首字母大写
data['State'] = data['State'].str.title()
# 将 'D&N Haveli' 改为 'D & N Haveli'
data['State'] = data['State'].replace('D&N Haveli', 'D & N Haveli')
# 检查数据中是否存在同一年同一个地区的数据重复
duplicates = data[data.duplicated(subset=['Year', 'State'], keep=False)]
# 显示可能存在重复的记录
duplicates.sort_values(by=['Year', 'State'])
Empty DataFrame
Columns: [State, Year, Rape, K&A, DD, AoW, AoM, DV, WT, Total_Crimes]
Index: []
发现不存在重复值,即一年内没有记录多次同一个地区的数据。
# 检查每年有多少个不同的地区
yearly_counts = data.groupby('Year')['State'].nunique()
# 显示每年的地区数量
yearly_counts
Year
2001 34
2002 34
2003 34
2004 34
2005 34
2006 34
2007 34
2008 34
2009 34
2010 34
2011 36
2012 36
2013 36
2014 36
2015 36
2016 36
2017 36
2018 36
2019 36
2020 36
2021 36
Name: State, dtype: int64
# 找出2001年至2010年少了的两个地区
full_set = set(data['State'].unique()) # 所有可能的地区
# 找出2001年到2010年每年缺少的地区
missing_regions = {}
for year in range(2001, 2011):
present_regions = set(data[data['Year'] == year]['State'].unique())
missing = full_set - present_regions
missing_regions[year] = missing
missing_regions
{2001: {'Delhi Ut', 'Telangana'},
2002: {'Delhi Ut', 'Telangana'},
2003: {'Delhi Ut', 'Telangana'},
2004: {'Delhi Ut', 'Telangana'},
2005: {'Delhi Ut', 'Telangana'},
2006: {'Delhi Ut', 'Telangana'},
2007: {'Delhi Ut', 'Telangana'},
2008: {'Delhi Ut', 'Telangana'},
2009: {'Delhi Ut', 'Telangana'},
2010: {'Delhi Ut', 'Telangana'}}
发现2001-2010年少了2个地区的数据,进一步查看,发现少了的地区都是:
- Delhi Ut(德里)
- Telangana(特伦甘纳邦)
data.head()
State Year Rape K&A DD AoW AoM DV WT \
0 Andhra Pradesh 2001 871 765 420 3544 2271 5791 7
1 Arunachal Pradesh 2001 33 55 0 78 3 11 0
2 Assam 2001 817 1070 59 850 4 1248 0
3 Bihar 2001 888 518 859 562 21 1558 83
4 Chhattisgarh 2001 959 171 70 1763 161 840 0
Total_Crimes
0 13669
1 180
2 4048
3 4489
4 3964
5.描述性分析
5.1总述
data.describe(include='all')
State Year Rape K&A DD \
count 736 736.000000 736.000000 736.000000 736.000000
unique 36 NaN NaN NaN NaN
top Andhra Pradesh NaN NaN NaN NaN
freq 21 NaN NaN NaN NaN
mean NaN 2011.149457 727.855978 1134.542120 215.692935
std NaN 6.053453 977.024945 1993.536828 424.927334
min NaN 2001.000000 0.000000 0.000000 0.000000
25% NaN 2006.000000 35.000000 24.750000 1.000000
50% NaN 2011.000000 348.500000 290.000000 29.000000
75% NaN 2016.000000 1069.000000 1216.000000 259.000000
max NaN 2021.000000 6337.000000 15381.000000 2524.000000
AoW AoM DV WT Total_Crimes
count 736.000000 736.000000 736.000000 736.000000 736.000000
unique NaN NaN NaN NaN NaN
top NaN NaN NaN NaN NaN
freq NaN NaN NaN NaN NaN
mean 1579.115489 332.722826 2595.078804 28.744565 6613.752717
std 2463.962518 806.024551 4042.004953 79.999660 9056.583832
min 0.000000 0.000000 0.000000 0.000000 0.000000
25% 34.000000 3.000000 13.000000 0.000000 146.750000
50% 387.500000 31.000000 678.500000 0.000000 2632.000000
75% 2122.250000 277.500000 3545.000000 15.000000 10299.000000
max 14853.000000 9422.000000 23278.000000 549.000000 52246.000000
- 数据包含 36 个不同的地区,涵盖 2001 到 2021 年的时间范围。
- 强奸案件:平均 727.86 起,波动较大(标准差 977.02),最高达到 6337 起。
- 绑架与袭击:平均 1134.54 起,最高达 15381 起。
- 聘礼致死:平均 215.69 起,多数地区案件较少(中位数 29 起)。
- 针对女性的袭击:平均 1579.12 起,部分地区特别高(最高 14853 起)。
- 家庭暴力:平均 2595.08 起,最高达 23278 起。
- 妇女贩卖:大部分地区案件数较少(中位数 0 起),但某些地区案件数较高(最高 549 起)。
- 总犯罪数:平均 6613.75 起,波动大(标准差 9056.58),部分地区犯罪总量显著较高(最高 52246 起)。
5.2可视化分析
# 计算每个地区的犯罪总数
total_crimes_by_state = data.groupby('State')['Total_Crimes'].sum().sort_values(ascending=False)
# 绘制总犯罪数柱状图
plt.figure(figsize=(14, 8))
total_crimes_by_state.plot(kind='bar')
plt.title('2001-2021年各地区累计犯罪总数分布')
plt.xlabel('地区')
plt.ylabel('总犯罪数')
plt.xticks(rotation=90)
plt.show()
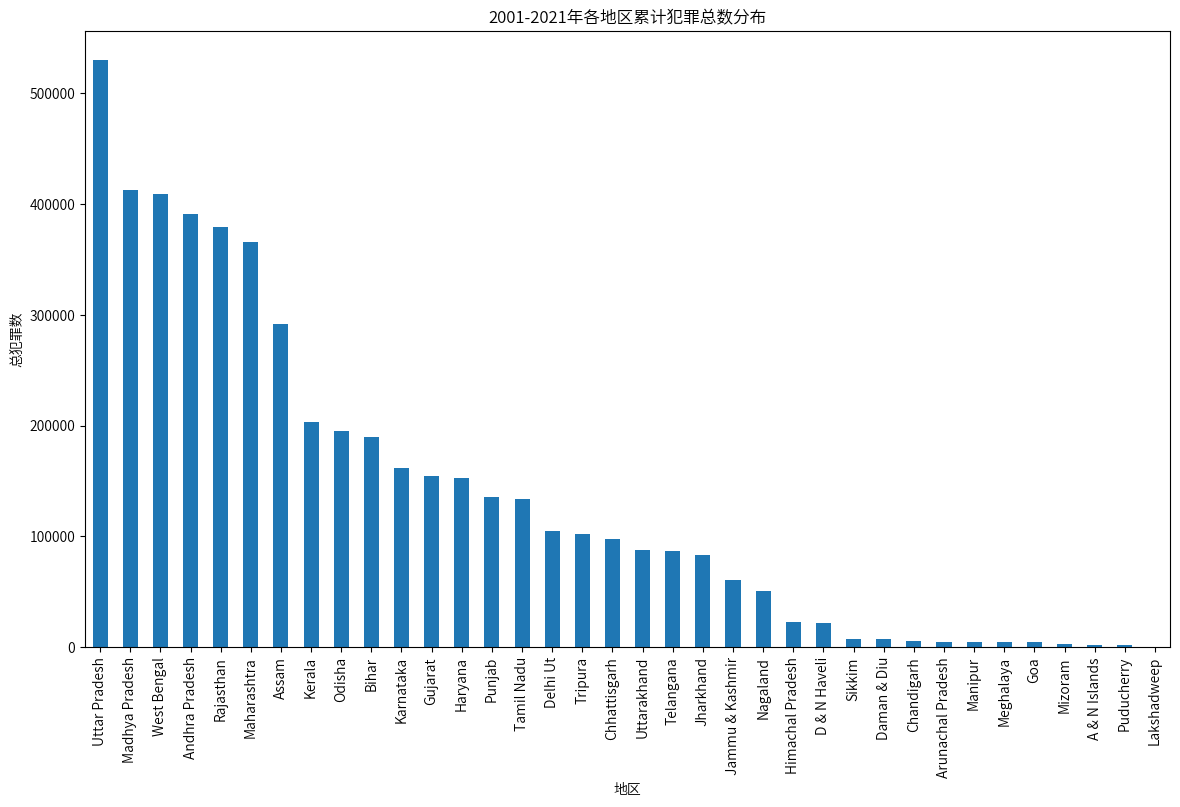
- 北方邦(Uttar Pradesh) 在2001-2021年间的累计犯罪总数是最高的,远高于其他地区,这表明北方邦在这段时间内的整体犯罪率显著高于其他邦。
- 拉克沙群岛(Lakshadweep) 和 本地治里(Puducherry) 以及 安达曼和尼科巴群岛(A & N Islands) 等地的累计犯罪总数明显较低,可能由于这些地区的较小人口规模和较低的社会活动密度。
总之,印度的一些人口大邦,如 Uttar Pradesh 和 Madhya Pradesh,犯罪总数显著高于其他邦,而一些较小的联邦属地和人口较少的地区的犯罪总数明显较低。
# 计算2001-2021年所有犯罪事件的总数
total_crimes_per_year = data.groupby('Year')['Total_Crimes'].sum()
# 绘制总犯罪事件数的趋势图(折线图)
plt.figure(figsize=(14, 8))
plt.plot(total_crimes_per_year.index, total_crimes_per_year.values, marker='o')
plt.title('2001-2021年所有犯罪事件总数的趋势图')
plt.xlabel('年份')
plt.ylabel('犯罪事件总数')
plt.xticks(total_crimes_per_year.index)
plt.grid(True)
plt.show()
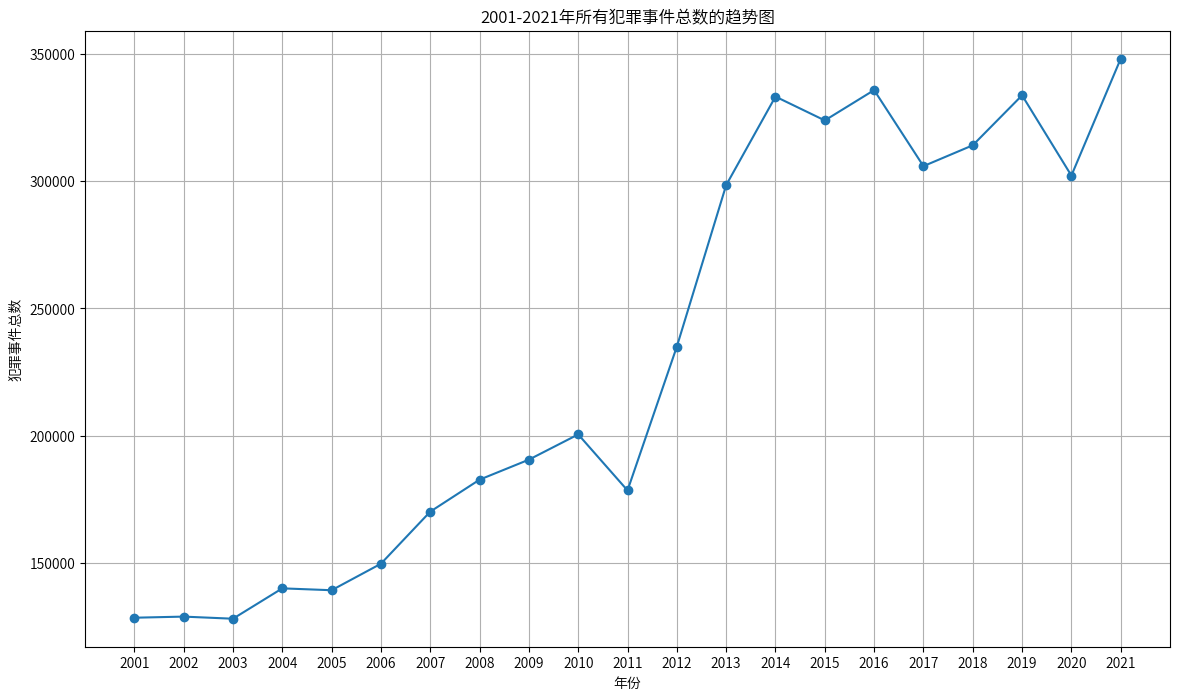
- 从2001年到2014年,犯罪事件总数显示出逐步上升的趋势。
- 从2014年到2021年,尽管总体保持在较高水平,但也存在一定的波动。
- 这也表明随着印度人口不断增加,犯罪事件也是不断增加,印度政府需要实施不同的保护女性的措施,并且加强执法力度!
# 计算每种犯罪类型在各年份的总数
crime_types = ['Rape', 'K&A', 'DD', 'AoW', 'AoM', 'DV', 'WT']
crime_trends = data.groupby('Year')[crime_types].sum()
# 绘制各类犯罪类型随时间变化的趋势图
plt.figure(figsize=(14, 8))
for crime_type in crime_types:
plt.plot(crime_trends.index, crime_trends[crime_type], marker='o', label=crime_type)
plt.title('2001-2021年各类犯罪类型随时间的变化趋势')
plt.xlabel('年份')
plt.ylabel('犯罪案件总数')
plt.legend(title='犯罪类型')
plt.grid(True)
plt.xticks(crime_trends.index)
plt.show()
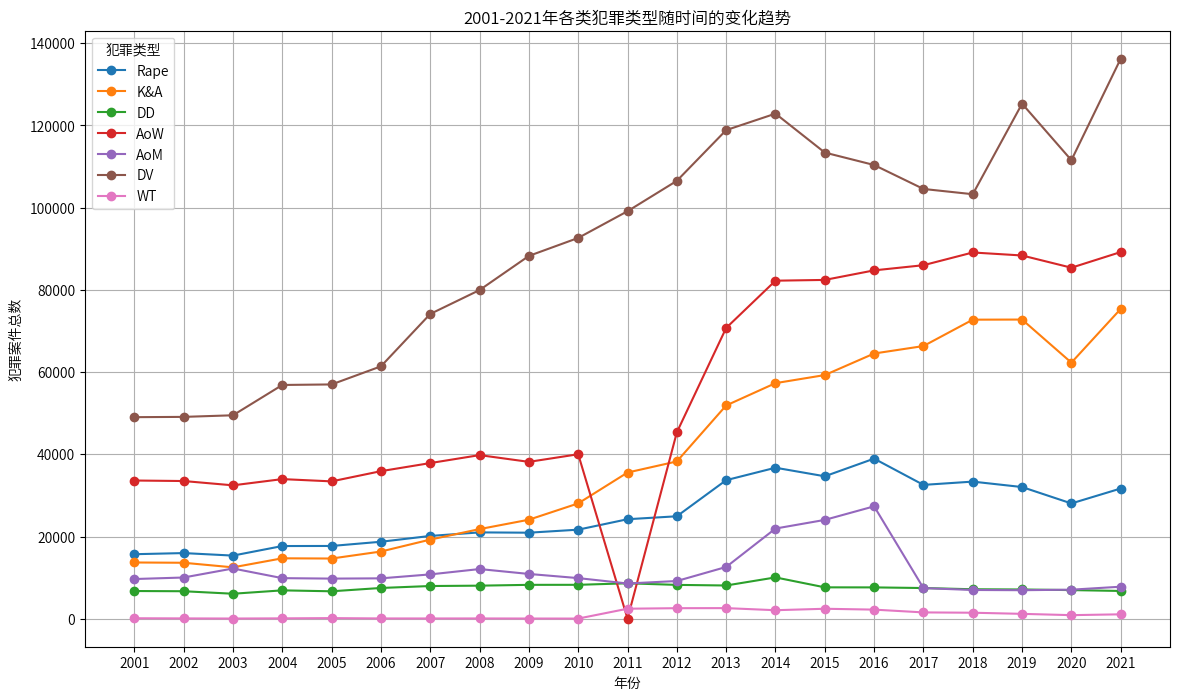
- 家庭暴力(DV) 一直是印度犯罪中的主要类型,而且从2001年到2021年持续上升,期间虽有波动,但是整体是显著上升的。
- 针对女性的袭击(AoW) 案件在2001年到2010年比较平稳,甚至在2011年下降到0(可能是数据丢失),从2012年到2014年上升明显,直到2015年后,上升又比较平稳。
- 绑架与袭击(K&A) 案件在2001年到2021年间总体呈现上升趋势,尤其是在2012年之后,有明显的增长。
- 侮辱女性贞操(AoM) 在整个时间段内波动较大,特别是在2013年和2017年,出现了急剧变化。
- 强奸案件(Rape) 案件在这段时间内波动较小,虽然在2012年后有所上升,但总体上变化不大。
- 聘礼致死(DD) 案件在整个时间段内保持相对稳定,没有显著的变化趋势。
- 妇女贩卖(WT) 案件数量相对较低,并且在这段时间内几乎没有显著变化。
家庭暴力、针对女性的袭击、绑架与袭击案件在这段时间内增幅较大,显示出这些类型的犯罪在社会中日益严重;2011年和2012年可能是关键年份,犯罪趋势出现了显著变化,可能受到社会事件、法律调整或执法力度变化的影响。
# 找出每年犯罪总数最多的城市
top_city_per_year = data.loc[data.groupby('Year')['Total_Crimes'].idxmax()]
# 初始化图表
plt.figure(figsize=(14, 8))
colors = ['blue', 'orange'] # 使用两种不同的颜色
# 绘制折线和点,并交替使用不同的颜色
for i in range(len(top_city_per_year) - 1):
plt.plot(top_city_per_year['Year'].iloc[i:i+2],
top_city_per_year['Total_Crimes'].iloc[i:i+2],
marker='o', color=colors[i % 2])
# 绘制标签
for i in range(len(top_city_per_year)):
if i % 2 == 0:
plt.text(top_city_per_year['Year'].iloc[i], top_city_per_year['Total_Crimes'].iloc[i] + 2000,
top_city_per_year['State'].iloc[i], fontsize=9, ha='center', color=colors[i % 2])
else:
plt.text(top_city_per_year['Year'].iloc[i], top_city_per_year['Total_Crimes'].iloc[i] - 2000,
top_city_per_year['State'].iloc[i], fontsize=9, ha='center', color=colors[i % 2])
plt.title('2001-2021年每年犯罪总数最多的城市及其犯罪总数')
plt.xlabel('年份')
plt.ylabel('犯罪总数')
plt.xticks(top_city_per_year['Year'])
plt.grid(True)
plt.show()
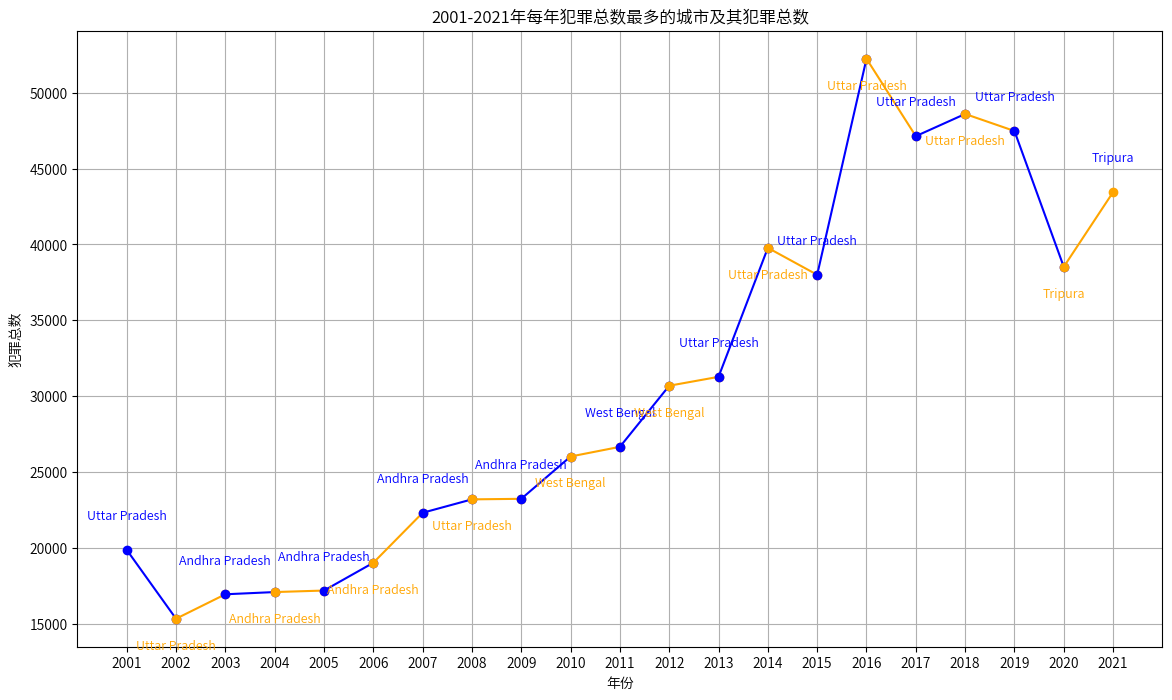
- 北方邦(Uttar Pradesh) 在多数年份是犯罪总数最多的地区。
- 在2003年到2007年间,安得拉邦(Andhra Pradesh) 多次成为犯罪总数最多的地区,然而,随着时间推移,安得拉邦的主导地位逐渐被北方邦取代。
- 西孟加拉邦(West Bengal) 在2010年到2012年成为犯罪总数最多的地区,但这种情况没有持续太久,随后被北方邦超越,这一短暂的高峰可能与特定的社会或政治事件有关,导致该地区在这三年内犯罪总数增加。
- 特里普拉邦(Tripura) 在2020年和2021年成为犯罪总数最多的地区,这可能反映了该地区在这些年内面临的特殊治安挑战。
def plot_crime_trends(region, start_year, end_year, crime_types):
"""
绘制某个地区在特定年份范围内的犯罪事件趋势图或总犯罪次数。
参数:
region (str): 地区名称
start_year (int): 起始年份
end_year (int): 结束年份
crime_types (list): 要研究的犯罪类型列表,可以包含 'Total_Crimes' 或者特定犯罪类型
返回:
None
"""
# 筛选数据
region_data = data[(data['State'] == region) & (data['Year'] >= start_year) & (data['Year'] <= end_year)]
# 绘制图表
plt.figure(figsize=(14, 8))
for crime_type in crime_types:
plt.plot(region_data['Year'], region_data[crime_type], marker='o', label=crime_type)
plt.title(f'{region} {start_year}-{end_year}年间的犯罪事件趋势')
plt.xlabel('年份')
plt.ylabel('犯罪次数')
plt.legend(title='犯罪类型')
plt.xticks(region_data['Year'])
plt.grid(True)
plt.show()
# 以犯罪事件总数最多的城市Uttar Pradesh为例
plot_crime_trends('Uttar Pradesh', 2001, 2021, ['Rape', 'K&A', 'DD','AoW','AoM'])
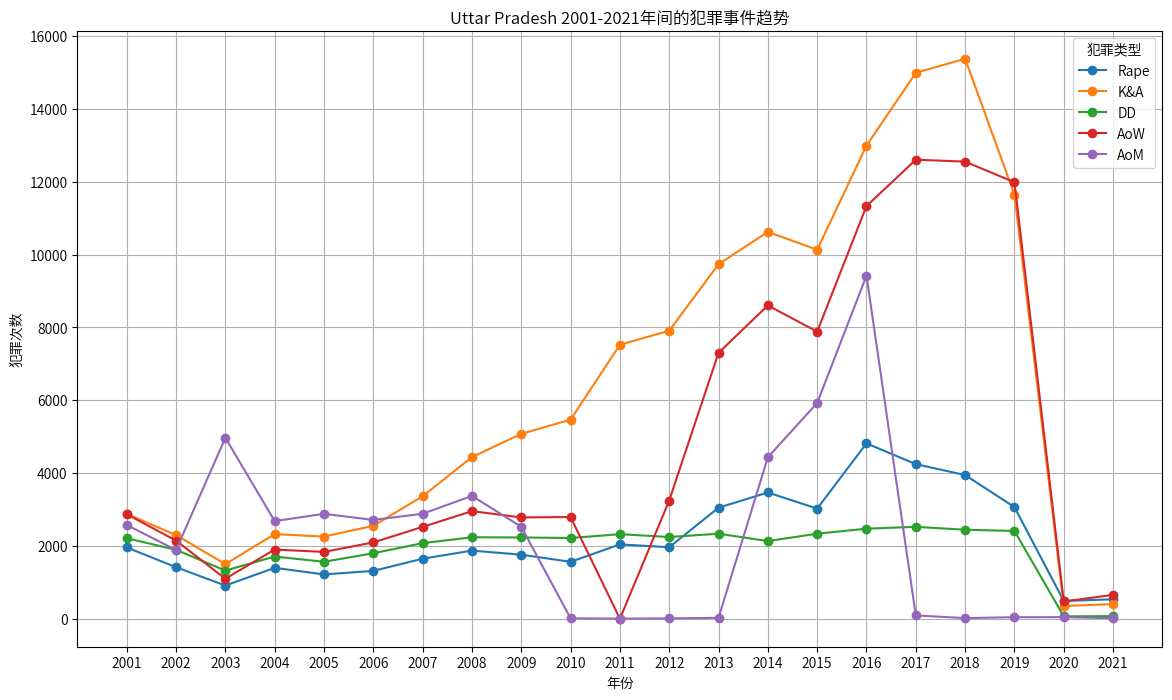
这里以犯罪事件总数最多的城市 北方邦(Uttar Pradesh) 为例,得出如下结论:
- 绑架与袭击(K&A) 案件几乎是北方邦(Uttar Pradesh)占比最大的案件,直到2018年达到顶峰,但是2019年开始明显下降,可能由于COVID-19大流行期间的封锁措施和其他社会因素导致的。
- 针对女性的袭击(AoW) 案件发展趋势与绑架与袭击(K&A)案件比较接近,也是一个主要的犯罪类型。
- 侮辱女性贞操(AoM) 案件波动较大,在2010年到2013年几乎为0,在2017年后也降低约为接近为0。
- 其余案件相对稳定,但是均在2019年明显下降,可能都是由于COVID-19大流行期间的封锁措施和其他社会因素导致的。
6.影响犯罪事件的因素
6.1斯皮尔曼相关性分析
def plot_spearmanr(data,features,title,wide,height):
# 计算斯皮尔曼相关性矩阵和p值矩阵
spearman_corr_matrix = data[features].corr(method='spearman')
pvals = data[features].corr(method=lambda x, y: spearmanr(x, y)[1]) - np.eye(len(data[features].columns))
# 转换 p 值为星号
def convert_pvalue_to_asterisks(pvalue):
if pvalue <= 0.001:
return "***"
elif pvalue <= 0.01:
return "**"
elif pvalue <= 0.05:
return "*"
return ""
# 应用转换函数
pval_star = pvals.map(lambda x: convert_pvalue_to_asterisks(x))
# 转换成 numpy 类型
corr_star_annot = pval_star.to_numpy()
# 定制 labels
corr_labels = spearman_corr_matrix.to_numpy()
p_labels = corr_star_annot
shape = corr_labels.shape
# 合并 labels
labels = (np.asarray(["{0:.2f}\n{1}".format(data, p) for data, p in zip(corr_labels.flatten(), p_labels.flatten())])).reshape(shape)
# 绘制热力图
fig, ax = plt.subplots(figsize=(height, wide), dpi=100, facecolor="w")
sns.heatmap(spearman_corr_matrix, annot=labels, fmt='', cmap='coolwarm',
vmin=-1, vmax=1, annot_kws={"size":10, "fontweight":"bold"},
linecolor="k", linewidths=.2, cbar_kws={"aspect":13}, ax=ax)
ax.tick_params(bottom=False, labelbottom=True, labeltop=False,
left=False, pad=1, labelsize=12)
ax.yaxis.set_tick_params(labelrotation=0)
# 自定义 colorbar 标签格式
cbar = ax.collections[0].colorbar
cbar.ax.tick_params(direction="in", width=.5, labelsize=10)
cbar.set_ticks([-1, -0.5, 0, 0.5, 1])
cbar.set_ticklabels(["-1.00", "-0.50", "0.00", "0.50", "1.00"])
cbar.outline.set_visible(True)
cbar.outline.set_linewidth(.5)
plt.title(title)
plt.show()
plot_spearmanr(data,crime_types,'各犯罪类型之间的相关性热力图',10,13)
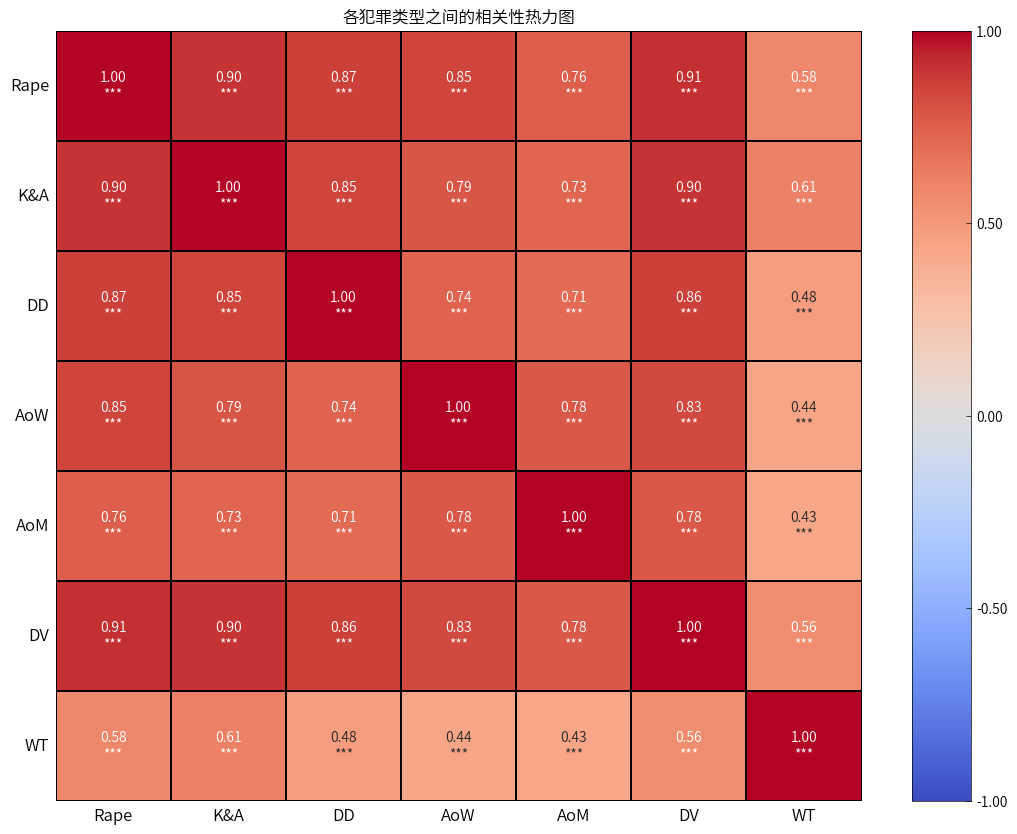
- 各个案件之间有明显的正相关,表明可能是受政策、经济等多方面因素的影响,导致这些犯罪行为在同一社会环境中频繁共同发生。
6.2方差分析
# 创建函数来进行ANOVA分析
def anova_test(var, target):
groups = [data[target][data[var] == level] for level in data[var].unique()]
F_stat, p_value = f_oneway(*groups)
return F_stat, p_value
crime_features = ['Rape', 'K&A', 'DD', 'AoW', 'AoM', 'DV', 'WT','Total_Crimes']
# 使用ANOVA来检验年份与各个犯罪事件之间的关系
anova_state_crime_results = {feature: anova_test('State', feature) for feature in crime_features}
# 将结果存入DataFrame
anova_state_crime_df = pd.DataFrame.from_dict(anova_state_crime_results, orient='index', columns=['F-Statistic', 'P-Value'])
anova_state_crime_df
F-Statistic P-Value
Rape 37.012734 8.063884e-135
K&A 17.460974 2.413443e-73
DD 70.091794 4.451585e-203
AoW 21.707619 7.008354e-89
AoM 24.552582 1.670675e-98
DV 32.490343 1.345413e-122
WT 9.073483 1.148222e-37
Total_Crimes 30.091820 1.059024e-115
- 所有的 p 值都非常小,远小于 0.05,这意味着对于每种犯罪类型以及犯罪事件的总数,地区与犯罪事件的发生之间都存在显著的统计关联。
# 使用ANOVA来检验年份与各个犯罪事件之间的关系
anova_year_crime_results = {feature: anova_test('Year', feature) for feature in crime_features}
# 将结果存入DataFrame
anova_year_crime_df = pd.DataFrame.from_dict(anova_year_crime_results, orient='index', columns=['F-Statistic', 'P-Value'])
anova_year_crime_df
F-Statistic P-Value
Rape 1.525899 6.577121e-02
K&A 3.952864 1.914412e-08
DD 0.110429 9.999997e-01
AoW 3.364957 1.117186e-06
AoM 1.357885 1.355946e-01
DV 1.177280 2.669488e-01
WT 4.837442 3.489876e-11
Total_Crimes 2.214237 1.752640e-03
- 显著关系:绑架与袭击(K&A)、针对女性的袭击(AoW)、妇女贩卖(WT)、以及总犯罪数量(Total_Crimes)与年份之间存在非常显著的关系。
- 非显著关系:聘礼致死(DD)、家庭暴力(DV)、侮辱女性贞操(AoM)与年份之间没有显著关系。
7.总结
本项目通过可视化分析、相关性分析和方差分析,深入探讨了印度不同年份侵害女性的事件。以下是本项目的主要结论:
1. 数据结构:
- 数据范围:涵盖了 2001 年至 2021 年,涉及 36 个不同地区。
- 强奸案件:平均每年 727.86 起,波动较大(标准差 977.02),最高达 6337 起。
- 绑架与袭击:平均每年 1134.54 起,最高达 15381 起。
- 聘礼致死:平均每年 215.69 起,案件数量在大多数地区较少(中位数 29 起)。
- 针对女性的袭击:平均每年 1579.12 起,部分地区案件特别高(最高 14853 起)。
- 家庭暴力:平均每年 2595.08 起,最高达 23278 起。
- 妇女贩卖:大部分地区案件数较少(中位数 0 起),但在某些地区案件数较高(最高 549 起)。
- 总犯罪数:平均每年 6613.75 起,波动大(标准差 9056.58),部分地区犯罪总量显著较高(最高 52246 起)。
2. 可视化分析:
- 地区差异:如北方邦(Uttar Pradesh)和中央邦(Madhya Pradesh)等人口大邦,犯罪总数显著高于其他地区,而一些较小的联邦属地和人口较少的地区犯罪总数较低。
- 犯罪趋势:随着印度人口的不断增加,犯罪事件也在持续增加。印度政府需要实施更多保护女性的措施,并加强执法力度。
- 犯罪类型变化:家庭暴力、针对女性的袭击、绑架与袭击案件在研究期间增幅较大,显示出这些类型的犯罪在社会中的严重性日益加剧。2011 年和 2012 年可能是关键年份,犯罪趋势出现了显著变化,可能受到社会事件、法律调整或执法力度变化的影响。
- 犯罪总数最多的地区:
- 北方邦(Uttar Pradesh) 在大多数年份中,犯罪总数最多。
- 安得拉邦(Andhra Pradesh) 在 2003 年至 2007 年间多次成为犯罪总数最多的地区,但其主导地位随着时间推移被北方邦取代。
- 西孟加拉邦(West Bengal) 在 2010 年至 2012 年成为犯罪总数最多的地区,这一短暂高峰可能与特定社会或政治事件有关。
- 特里普拉邦(Tripura) 在 2020 年和 2021 年成为犯罪总数最多的地区,这可能反映了该地区在这些年内面临的特殊治安挑战。
3. 方差分析:
- 地区与犯罪事件的关系:分析结果显示,地区与各类犯罪事件的发生之间存在显著的统计关联。
- 年份与犯罪类型的关系:
- 绑架与袭击(K&A)、针对女性的袭击(AoW)、妇女贩卖(WT)以及总犯罪数量(Total_Crimes)与年份之间存在非常显著的关系。
- 聘礼致死(DD)、家庭暴力(DV)、侮辱女性贞操(AoM)与年份之间没有显著关系。
这些结论为进一步理解印度不同地区和不同年份的犯罪动态提供了有力的依据,并为未来的政策制定和执法提供了参考依据。