本文旨在探讨基于Llama factory使用LoRA(Low-Rank Adaptation)技术对Llama3.1-70B-Chinese-Chat模型进行微调的过程,重点介绍在单机多卡和多机多卡两种分布式训练环境下的实现方法。
1.环境准备
1.1 平台环境
微调Llama3.1-70B模型,本地环境跑不了。只能选择租用云上GPU。关于算力租赁平台,我选择的是FunHPC,理由如下:
- 官网简单明了,进去就能租(无需排队),显卡类型多,总能找到适合我的卡型。
- 价格非常亲民,和其他平台相比,算是非常便宜了。
- 提供code-server开发界面,开发方便快捷。
- 最近官方出了一个活动,只要发文章,就能领取80元的算力金。趁着这个机会,写一份我微调Llama3.1-70B的历程。
磁盘空间扩容:
- 600G
显卡选择
- 单机多卡训练选择的是8×A100(40G),即1台A100服务器。
- 多机多卡训练选择的是2×8×100(40G),即2台A100服务器。
租用镜像选择:
- pytorch 2.2.0+cuda121
1.2 Llama factory 环境
1.2.1 下载Llama factory

1.2.2 安装 Llama factory环境

2.数据集准备
下面的python代码主要完成3个方面:
- 配置代理,方便访问huggingface,这里我画上了下,不方便透露了。
- 从huggingface上下载m-a-p/COIG-CQIA数据集,作为本次微调的数据集。
- 将下载后的数据集,转换成Alpaca格式。
Alpaca格式如下:
[
{
"instruction": "human instruction (required)",
"input": "human input (optional)",
"output": "model response (required)",
"system": "system prompt (optional)",
"history": [
["human instruction in the first round (optional)", "model response in the first round (optional)"],
["human instruction in the second round (optional)", "model response in the second round (optional)"]
]
}
]
import os
import json
from datasets import load_dataset, concatenate_datasets
# 设置代理
os.environ["http_proxy"] = "*****"
os.environ["https_proxy"] = "*****"
def prepare_data():
data_names = ["chinese_traditional", "human_value", "wiki", "ruozhiba", "logi_qa", "wikihow", "zhihu", "douban", "xhs"]
datasets = [load_dataset("m-a-p/COIG-CQIA", name=name, cache_dir="./data", split="train") for name in data_names]
concatenated_dataset = concatenate_datasets(datasets)
return concatenated_dataset
def convert_to_alpaca_format(dataset):
alpaca_data = []
for entry in dataset:
alpaca_entry = {
"instruction": entry['instruction'],
"input": entry['input'],
"output": entry['output']
}
alpaca_data.append(alpaca_entry)
return alpaca_data
# 准备数据并转换为 Alpaca 格式
datasets = prepare_data()
alpaca_data = convert_to_alpaca_format(datasets)
# 将结果保存为 JSON 文件,不转义非 ASCII 字符
with open('alpaca_format_data.json', 'w', encoding='utf-8') as f:
json.dump(alpaca_data, f, ensure_ascii=False, indent=4)
print("转换完成,数据已保存为 'alpaca_format_data.json'")
3.模型准备
3.1 模型下载
pip install modelscope
modelscope download --model XD_AI/Llama3.1-70B-Chinese-Chat --local_dir /data/coding/Llama3.1-70B-Chinese-Cha
3.2 模型校验
由于model比较大,会报显存错误。我将校验代码修改了一下,改成多卡调用。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "/data/coding/Llama3.1-70B-Chinese-Chat"
dtype = torch.bfloat16
# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 设置 pad_token_id
pad_token_id = tokenizer.pad_token_id if tokenizer.pad_token_id is not None else tokenizer.eos_token_id
# 使用 device_map 自动将模型切分到多 GPU
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=dtype,
device_map="auto"
)
chat = [{"role": "user", "content": "写一首关于机器学习的诗。"}]
inputs = tokenizer.apply_chat_template(chat, tokenize=True, add_generation_prompt=True, return_tensors="pt")
# 设置 attention_mask
input_ids = inputs.input_ids.to("cuda:0")
attention_mask = inputs.attention_mask.to("cuda:0") if "attention_mask" in inputs else None
# 推理
outputs = model.generate(
input_ids,
attention_mask=attention_mask, # 添加 attention_mask
max_new_tokens=8192,
do_sample=True,
temperature=0.6,
top_p=0.9,
pad_token_id=pad_token_id # 设置 pad_token_id
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
输出结果:
机器学习的诗
在数据的海洋中漂流,
机器学习的帆船缓缓前行。
算法的帆吸收着知识的风,
在预测的天空下,探索未知的星辰。
神经网络的缆绳,层层交织,
像大脑的神经,智慧的图腾。
激活函数的灯塔,指引方向,
在复杂的迷宫中,寻找最短的路径。
训练的锤炼,重复不息,
优化的目标,精确无误。
误差的波澜,逐渐平息,
模型的力量,日益壮大。
测试的考验,验证的时刻,
真实世界的挑战,机遇与风险。
泛化的梦想,跨越边界,
机器学习的诗篇,永不止息。
在这个数字的时代,
机器学习的诗,讲述着未来。
智能的火种,点燃希望,
编织人类梦想的强大纽带。
4.模型训练
在训练之前需要做的两件事儿:
-
-
将alpaca_format_data.json文件放到Llama factory的data目录下。
-
在dataset_info.json中添加:
{
“alpaca_format_data”: {
“file_name”: “alpaca_format_data.json”
},
-
4.1 单机多卡训练
我的llama3_lora_sft_ds31.yaml如下:
### model
model_name_or_path: /data/coding/Llama3.1-70B-Chinese-Chat
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
deepspeed: /data/coding/LLaMA-Factory/examples/deepspeed/ds_z3_offload_config.json
### dataset
dataset: alpaca_format_data
template: llama3
cutoff_len: 1024
max_samples: 30000
overwrite_cache: true
preprocessing_num_workers: 64
### output
output_dir: /data/coding/LLaMA3-70B/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 8
gradient_accumulation_steps: 8
learning_rate: 5.0e-4
num_train_epochs: 5.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### ddp_backend
ddp_backend: nccl
ddp_find_unused_parameters: false
### eval
val_size: 0.1
per_device_eval_batch_size: 8
eval_strategy: steps
eval_steps: 500
load_best_model_at_end: true
终端执行命令如下:
FORCE_TORCHRUN=1 llamafactory-cli train /data/coding/LLaMA-Factory/examples/train_lora/llama3_lora_sft_ds31.yaml
训练过程如下:
[INFO|trainer.py:2134] 2024-08-16 09:14:59,763 >> ***** Running training *****
[INFO|trainer.py:2135] 2024-08-16 09:14:59,763 >> Num examples = 22,582
[INFO|trainer.py:2136] 2024-08-16 09:14:59,763 >> Num Epochs = 5
[INFO|trainer.py:2137] 2024-08-16 09:14:59,763 >> Instantaneous batch size per device = 8
[INFO|trainer.py:2140] 2024-08-16 09:14:59,763 >> Total train batch size (w. parallel, distributed & accumulation) = 512
[INFO|trainer.py:2141] 2024-08-16 09:14:59,763 >> Gradient Accumulation steps = 8
[INFO|trainer.py:2142] 2024-08-16 09:14:59,763 >> Total optimization steps = 220
[INFO|trainer.py:2143] 2024-08-16 09:14:59,774 >> Number of trainable parameters = 103,546,880
{'loss': 2.021, 'grad_norm': 0.31445133686065674, 'learning_rate': 0.00022727272727272727, 'epoch': 0.23}
{'loss': 1.7366, 'grad_norm': 0.13742084801197052, 'learning_rate': 0.00045454545454545455, 'epoch': 0.45}
{'loss': 1.6267, 'grad_norm': 0.06480135023593903, 'learning_rate': 0.0004979887032076989, 'epoch': 0.68}
{'loss': 1.5846, 'grad_norm': 0.05686546117067337, 'learning_rate': 0.0004898732434036243, 'epoch': 0.91}
{'loss': 1.5642, 'grad_norm': 0.05606243386864662, 'learning_rate': 0.0004757316345716554, 'epoch': 1.13}
{'loss': 1.5164, 'grad_norm': 0.06566128134727478, 'learning_rate': 0.0004559191453574582, 'epoch': 1.36}
{'loss': 1.5104, 'grad_norm': 0.06976603716611862, 'learning_rate': 0.0004309335095262675, 'epoch': 1.59}
{'loss': 1.4946, 'grad_norm': 0.06345170736312866, 'learning_rate': 0.00040140242178441667, 'epoch': 1.81}
{'loss': 1.4851, 'grad_norm': 0.07551503926515579, 'learning_rate': 0.0003680677686931707, 'epoch': 2.04}
{'loss': 1.4064, 'grad_norm': 0.11773069202899933, 'learning_rate': 0.00033176699082935546, 'epoch': 2.27}
{'loss': 1.411, 'grad_norm': 0.09556800872087479, 'learning_rate': 0.00029341204441673266, 'epoch': 2.49}
{'loss': 1.4018, 'grad_norm': 0.09359253197908401, 'learning_rate': 0.000253966490958702, 'epoch': 2.72}
{'loss': 1.3875, 'grad_norm': 0.1037076786160469, 'learning_rate': 0.00021442129043167875, 'epoch': 2.95}
{'loss': 1.3314, 'grad_norm': 0.12813276052474976, 'learning_rate': 0.00017576990616793137, 'epoch': 3.17}
{'loss': 1.3125, 'grad_norm': 0.1260678470134735, 'learning_rate': 0.00013898334684855646, 'epoch': 3.4}
{'loss': 1.2788, 'grad_norm': 0.13497693836688995, 'learning_rate': 0.00010498577260720049, 'epoch': 3.63}
{'loss': 1.2677, 'grad_norm': 0.12839122116565704, 'learning_rate': 7.463127807341966e-05, 'epoch': 3.85}
{'loss': 1.2469, 'grad_norm': 0.175085186958313, 'learning_rate': 4.8682435617235344e-05, 'epoch': 4.08}
{'loss': 1.2235, 'grad_norm': 0.1542418748140335, 'learning_rate': 2.7791137836269158e-05, 'epoch': 4.31}
{'loss': 1.1948, 'grad_norm': 0.14159728586673737, 'learning_rate': 1.2482220564763668e-05, 'epoch': 4.53}
{'loss': 1.2039, 'grad_norm': 0.13814429938793182, 'learning_rate': 3.1402778309014278e-06, 'epoch': 4.76}
{'loss': 1.2098, 'grad_norm': 0.13053908944129944, 'learning_rate': 0.0, 'epoch': 4.99}
{'train_runtime': 88370.9016, 'train_samples_per_second': 1.278, 'train_steps_per_second': 0.002, 'train_loss': 1.4279815023595637, 'epoch': 4.99}
[INFO|trainer.py:3821] 2024-08-17 09:50:24,508 >> Num examples = 2510
[INFO|trainer.py:3824] 2024-08-17 09:50:24,508 >> Batch size = 8
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 40/40 [14:59<00:00, 22.49s/it]
***** eval metrics *****
epoch = 4.9858
eval_loss = 1.5017
eval_runtime = 0:15:24.41
eval_samples_per_second = 2.715
eval_steps_per_second = 0.043
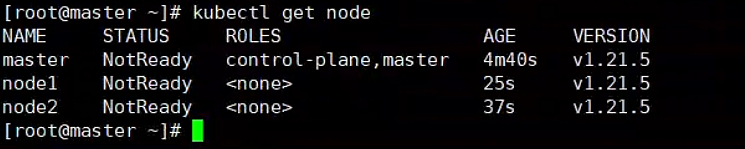
训练时间大致:15小时
显卡占用如下:
训练loss如下:
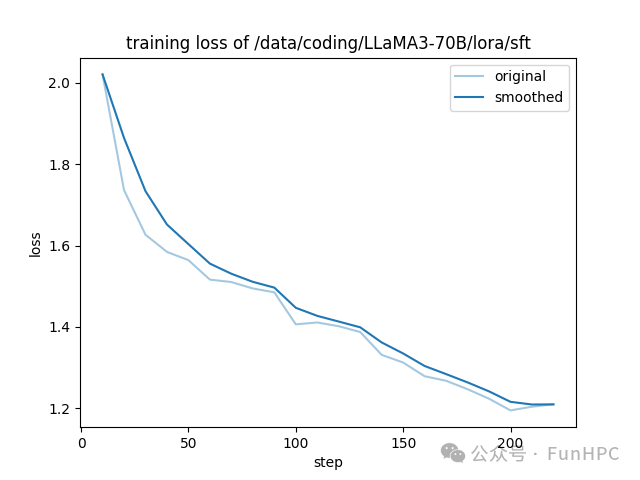
4.2 多机多卡训练
训练的yaml文件和单机多卡一致。
终端执行命令如下:
主节点:
FORCE_TORCHRUN=1 NNODES=2 RANK=0 MASTER_ADDR=10.222.51.150 MASTER_PORT=29500 llamafactory-cli train /data/coding/LLaMA-Factory/examples/train_lora/llama3_lora_sft_ds31.yaml
次节点:
FORCE_TORCHRUN=1 NNODES=2 RANK=1 MASTER_ADDR=10.222.51.150 MASTER_PORT=29500 llamafactory-cli train /data/coding/LLaMA-Factory/examples/train_lora/llama3_lora_sft_ds31.yaml
训练时间大致:63小时
{'loss': 1.9696, 'grad_norm': 0.10808725655078888, 'learning_rate': 0.00045454545454545455, 'epoch': 0.45}
13%|██████████████████▋ | 14/110 [22:44:00<155:12:34, 5820.36s/it
由于这里训练时间较长,就不展示训练过程及训练loss。
5.模型效果展示
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 llamafactory-cli chat --model_name_or_path /data/coding/Llama3.1-70B-Chinese-Chat --adapter_name_or_path /data/coding/LLaMA3-70B/lora/sft --template llama3 --finetuning_type lora
推理效果如下:
User: 为什么昙花开花时间非常短?
Assistant: 昙花原产于南美洲墨西哥、危地马拉、委内瑞拉等热带地区。昙花的花朵非常美丽,花朵颜色有红色、白色、紫色、粉红色、黄色等。它的花朵大多数在晚上开,第二天早晨就凋谢了,因此它又叫“一夜夫人”、“夜合花”等。昙花的花朵为什么时间这么短呢?原来昙花是喜暖的植物,白天温度高时,花瓣的伸展能力变弱,不能正常地舒展开来;而到了晚上温度低时,花瓣的伸展能力增强,花朵就开放了。到了第二天早晨,气温升高,花瓣的伸展能力又减弱,花朵便慢慢地合拢,最后就枯萎凋谢了。昙花的花朵时间短是由它的生理特性决定的。
User: 为什么英国曾被称为“日不落帝国”?
Assistant: 英国曾被称为“日不落帝国”,这是因为在18世纪和19世纪的殖民战争中,英国占领了世界各地的许多地方,从而建立了一个庞大的殖民帝国。当时英国在世界各地的殖民地非常多,无论什么时候,英国总有地方是白天。英国的这种特殊地位使它在当时被称为“日不落帝国”。但是,随着时间的推移,英国的殖民地逐渐独立,英国的殖民地数量也在不断减少,最终英国的殖民地几乎全部独立,英国的“日不落帝国”也随之消失了。
User: 给我介绍一下算力显卡
Assistant: 算力显卡是指那些专门用于计算的显卡。这些显卡通常具有非常高的性能和非常低的功耗,它们可以帮助用户进行各种复杂的计算任务,如数据挖掘、机器学习等。算力显卡的主要特点是它们具有非常高的浮点运算能力,这使得它们可以快速地处理大量的数据并产生高质量的结果。此外,算力显卡还具有非常低的功耗,这使得它们可以在长时间的运行中保持稳定的性能。
6.总结
本文通过单机多卡和多机多卡的情况下,完成基于Llama factory使用LoRA(Low-Rank Adaptation)技术对Llama3.1-70B-Chinese-Chat模型进行微调的过程。总体的推理效果不错。对于多机多卡下,训练速度慢的问题还有待改善。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓