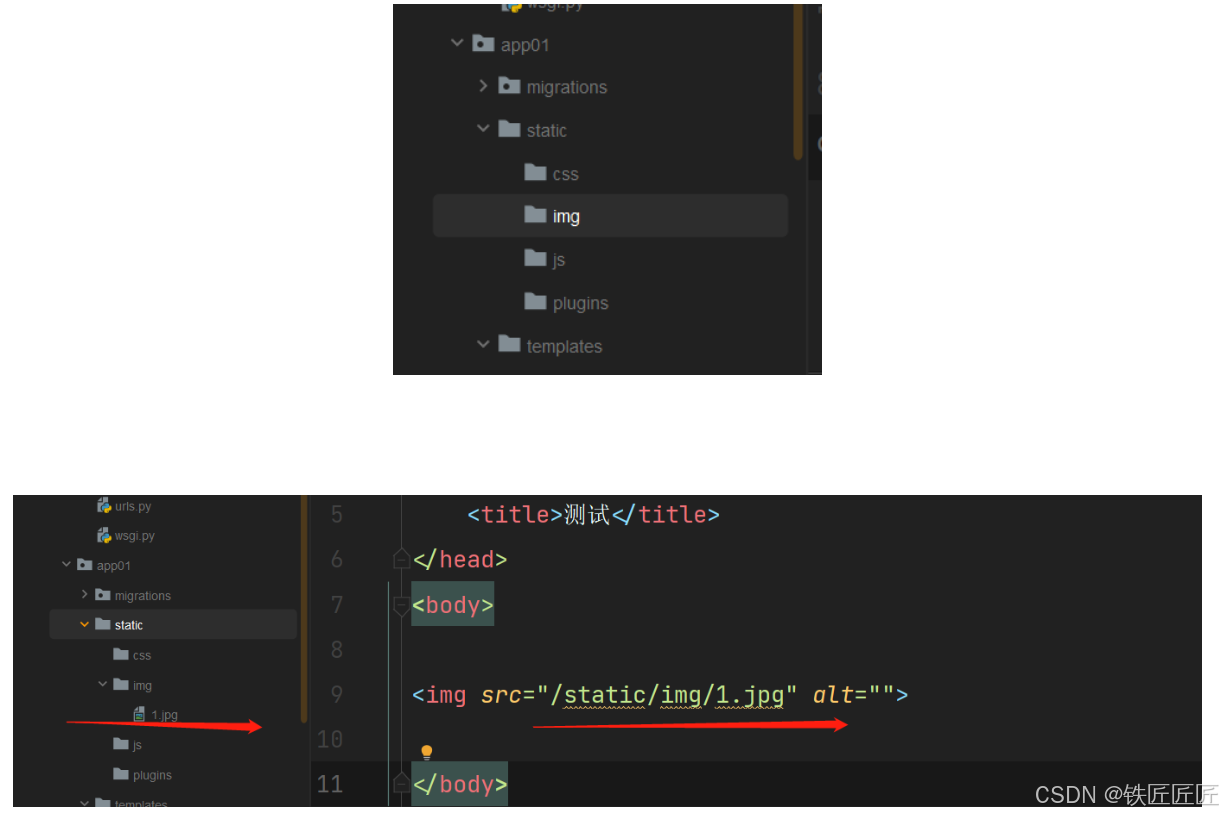
关系型数据库和 NoSQL 数据库



Redis的源码安装

编译

vim /etc/redis/6379.conf
bind改成* -::*
关闭protected模式


Redis 主从复制
主从同步过程

环境配置
redis-node1 master
redis-node2 slave1
redis-node3 slave2
slave中配置
vim /etc/redis/6379.conf

master中操作

slave中查看master的操作

Redis的哨兵(高可用)



三台开启哨兵模式,这里可知10为master

将10手动shutdown

20 30开始投票,认为10已经挂掉,并且选举30为新的master


远程连接30主机,看到只有一台slave

在10开启redis
![]()
此时看到30的slave数量为2

恢复10为master

在整个架构中可能会出现的问题

Redis Cluster(无中心化设计)
Redis Cluster 工作原理
在哨兵sentinel机制中,可以解决redis高可用问题,即当master故障后可以自动将slave提升为master, 从而可以保证redis服务的正常使用,但是无法解决redis单机写入的瓶颈问题,即单机redis写入性能受 限于单机的内存大小、并发数量、网卡速率等因素。
redis 3.0版本之后推出了无中心架构的redis cluster机制,在无中心的redis集群当中,其每个节点保存 当前节点数据和整个集群状态,每个节点都和其他所有节点连接

这里我们采用三主(10 20 30)三从(110 120 130)
首先我们需要保证一个纯净的实验环境,下载redis


用123456进行验证 这里还不能创建用户

将已经node1已经编辑好的文件拷贝到其他主机

多台主机一起操作,查看6379端口已经开启

创建redis-cluster
设定主备,并分配哈希槽
这里看id可知
10(master)对应120(slave)
20(master)对应130(slave)
30(master)对应110(slave)
这个是随机分配的

检测redis集群状态

此时我们想创建用户,系统告诉我们哈希槽落在20主机上

那么我们来20主机上创建用户

集群扩容
这里我们做4主4从,添加40和140主机
将node2编辑好的文件复制到40和140主机

redis-cli -a 123456 --cluster add-node 172.25.254.40:6379 172.25.254.20:6379
将40主机加入到20所在的哈希槽中

check时看到40已经已经加入组,虽然是master但是(0 slots),说明不能存储数据,所以我们需要划分哈希槽位

这里我们将所有主机划分4096个槽位

此时我们看到40已经拥有自己的槽位

我们再将140作为备加入组

check看到140已经加入,且与40互为主备

clsuter集群维护(集群删除)
这里140我们直接用 redis-cli -a 123456 --cluster del-node 172.25.254.140:6379 加id即可删除

但是40有槽位,所以我们需要先划分槽位再删除
node1为40的id,这里我们直接将40的槽位都给20

看到40没有槽位,20槽位翻倍,我们再删除40

记录一下我们八台虚拟机同时开