🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题
🍊专栏推荐:深度学习网络原理与实战
🍊近期目标:写好专栏的每一篇文章
🍊支持小苏:点赞👍🏼、收藏⭐、留言📩
深度学习语义分割篇——LR-ASPP原理详解+源码实战
写在前面
Hello,大家好,我是小苏👦🏽👦🏽👦🏽
在之前我为大家介绍过DeepLab系列的三篇文章,大家还记得嘛,不记得的可以点击下面链接看一看喔。✨✨✨
- 深度学习语义分割篇——DeepLabV1原理详解篇🍁🍁🍁
- 深度学习语义分割篇——DeepLabV2原理详解篇🍁🍁🍁
- 深度学习语义分割篇——DeeplabV3原理详解+源码实战🍁🍁🍁
今天为大家带来的同样也是语义分割网络——LR-ASPP,本文会结合源码为大家介绍LR-ASPP的结构,让大家对其有一个更加清晰的认识。兄弟萌,准备好了嘛,我要开始发车了喔~~~🚖🚖🚖
论文下载地址🌱🌱🌱
LR-ASPP网络结构
在介绍LR-ASPP网络结构之前,我们先来说说这个网络相较于DeepLab系列网络有什么优势,其实啊它最大的优势就是轻量,计算成本小,这样更适合进行模型压缩和优化,以满足边缘设备和移动设备上的部署需求。我们可以来看看pytorch官网给的一张测评表,如下:

可以看到,LR-ASPP结构的推理时间比我们先前介绍的DeepLabV3网络小的多,但mIou只有一定程度的降低。【可以忍受,往往模型的精度和速度之前都要有所取舍。🌸🌸🌸】
不知道大家注意到没有,上图的LR-ASPP网络后面写着MobileNetV3-Large,没错,这个其实就是LR-ASPP网络采用的backbone——MobileNetV3。🌱🌱🌱
MobileNet,大家不知道了解不,不清楚的可以看一下我的这篇博客:详细且通俗讲解轻量级神经网络——MobileNets【V1、V2、V3】
我这里还是简单的和大家总结一下MobileNet,其实它提出了一种更加轻量的卷积——深度可分离卷积,让网络的参数量和计算量都大大减少,当然这个是MoblieNetV1提出来的,后面的MobileNetV2和MobileNetV3都添加了其它的trick,具体详见上文提到的博客。【注:我还写过其它的轻量级网络,如ShuffleNet系列、RepVGG等等,感兴趣的可以去我主页搜索。🍑🍑🍑】
注:LR-ASPP结构就是在MobileNetV3论文中提出来的喔🍀🍀🍀
接下来我们就来介绍LR-ASPP的结构了喔,如下图所示:

可以看到LR-ASPP网络由两部分构成,第一部分为以MobileNetV3为基础的Backbone,第二部分为一个分割头,下面分别来进行介绍:
-
Backbone(MobileNetV3)
MobileNetV3的网络结构是怎么样的呢?我们直接来看下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4BdFDCs4-1645335379593)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220219221747292.png)]](https://img-blog.csdnimg.cn/img_convert/96965fb571c1861c7e6b5436f1b6e9a4.webp?x-oss-process=image/format,png#pic_center)
从上图可以看出,有5处步长s为2,即表示进行了5次下采样的操作,也即一共进行了32倍的下采样。但是在语义分割任务中,我们采用32倍下采样会丢失太多的信息,所以往往不会下采样这么多倍。那么这里问一下大家还记得我们在前3节介绍DeepLab系列的时候下采样倍率是多少吗?
没错,是进行8被下采样,其实啊,对于一般的语义分割任务,通过都是进行8倍下采样,但是呢,LR-ASPP网络主打一个轻量,所以将下采样倍率设置成16以减小参数量。LR-ASPP网络的Backbone结构如下图所示:可以看到此时步长s为2的只有4处,即只下采样16 倍。并且采用了空洞卷积,图中的参数d表示膨胀率。

-
Segmentation Head(分割头)
说完了Backbone,我们接着来说分割头。
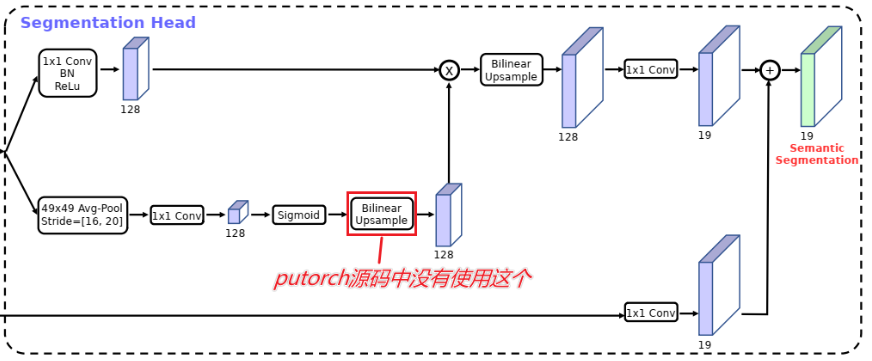
首先大家这里注意一下,MobileNetV3中的图中有画上图红框中的线性插值,但是pytorch源码中实际上是没有使用的。
整体来看分割头有两个分支,分别是从Backbone中提取到的特征,下面分别介绍一下:
-
分支1
分支1先分成上下两个部分,如下:

上半部分经过一个CBA结构(卷积-归一化-激活函数)得到特征图,下半部分先通过一个全局平均池化层,然后经过一个1×1的卷积核Sigmoid函数得到特征图。接着将上下两个部分相乘得到新的特征图,这一部分特别像SENet,不熟悉的去看看MobileNetV3中对SENet的解释。最后再进行一个双线性插值和1×1卷积。更详细的结构如下图所示:

-
分支2

分支2就一个1×1的卷积结构,就没什么好说的啦。🍭🍭🍭
得到分支1和分支2的特征图后会进行一个Add相加操作,最后使用一个双线性插值就得到最终的输出特征图啦。🥗🥗🥗
-
到这里,LR-ASPP的网络结构就为大家介绍完啦,如图所示:(图片来自B站霹雳吧啦Wz)

LR-ASPP源码解析
LR-ASPP源码地址🍁🍁🍁
本节LR-ASPP模型属于语义分割,对语义分割不清楚的务必要看一下我之前的博客喔~~~🍚🍚🍚
- ①深度学习语义分割篇——FCN原理详解篇
- ②深度学习语义分割篇——FCN原理详解篇
介绍了这么多,好像还没为大家介绍LR-ASPP的全称腻,我滴锅。😀😀😀LR-ASPP全称为Lite Reduced Atrous Spatial Pyramid Pooling,翻译过来的话为精简轻量版的ASPP,是的,这里的ASPP我没有翻译了,因为我觉得大家应该会很熟悉这个词了叭,在DeepLab系列中我多次提到了这个结构,不熟悉的可以去看一下。当然了,本文的ASPP结构和之前的是有所区别的,大家可以对照一下下图比较一下:(图片来自Le0v1n)


下面正式进入源码解析环节,其实这个代码感觉DeepLabV3的代码也是非常像的,首先先来搭建MobileNetV3的backbone,如下:
backbone = mobilenet_v3_large(dilated=True)
dilated=True参数和DeepLabV3中构建的resnet的backbone是一样的,都是在相应的层设置空调卷积,大家这里自己跳进去看看叭,我们还是重点来介绍分割头部分的代码。
我们来看看输入一张3×480×480的图片,经过backbone后的输出,如图:

可以看到有两个输出,一个是low,表示浅层特征,其维度为40×60×60,另一个是high,表示深层特征,其维度为960×30×30,如下图所示:【4表示batch_size】

得到backbone的输出后,就可以输入到LRASPPHead,即分割头中了,代码如下:
self.classifier = LRASPPHead(low_channels, high_channels, num_classes, inter_channels) out = self.classifier(features)
class LRASPPHead(nn.Module):
def __init__(self,
low_channels: int,
high_channels: int,
num_classes: int,
inter_channels: int) -> None:
super(LRASPPHead, self).__init__()
self.cbr = nn.Sequential(
nn.Conv2d(high_channels, inter_channels, 1, bias=False),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True)
)
self.scale = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(high_channels, inter_channels, 1, bias=False),
nn.Sigmoid()
)
self.low_classifier = nn.Conv2d(low_channels, num_classes, 1)
self.high_classifier = nn.Conv2d(inter_channels, num_classes, 1)
def forward(self, inputs: Dict[str, Tensor]) -> Tensor:
low = inputs["low"]
high = inputs["high"]
x = self.cbr(high)
s = self.scale(high)
x = x * s
x = F.interpolate(x, size=low.shape[-2:], mode="bilinear", align_corners=False)
return self.low_classifier(low) + self.high_classifier(x)
这个代码也很好理解啦,和之前给出的网络结构是完全一致的,我们给出此步只后的输出特征图的尺寸:

最后,我们会再使用一个线性插值还原到原图尺寸,代码如下:
out = F.interpolate(out, size=input_shape, mode="bilinear", align_corners=False)
输出结果的shape如下:

到这里,整个LR-ASPP网络就介绍完了,后面就是设置优化器、损失函数等操作,这些都和FCN、DeepLabV3是一样的了,大家自己看看就行了。这里再给大家提个醒,这里的损失函数的创建过程如下:和FCN一样,都会忽略值为255的像素,这里其实还是比较难理解的,在我FCN源码详解篇中对此做了详细的解释,还不清楚的可以去看看喔。🍄🍄🍄
def criterion(inputs, target):
losses = {}
for name, x in inputs.items():
# 忽略target中值为255的像素,255的像素是目标边缘或者padding填充
losses[name] = nn.functional.cross_entropy(x, target, ignore_index=255)
if len(losses) == 1:
return losses['out']
return losses['out'] + 0.5 * losses['aux']
小结
本节LR-ASPP原理详解+源码实战的内容就为大家介绍到这里了喔~~~是不是也是非常简单呢。🍚🍚🍚语义分割篇我也打算先就介绍到这里了,后面预计更新一些有意思的小项目,或者自己也学学NLP的相关知识,然后再分享给大家。好啦,我们下期间!!!🌼🌼🌼
参考文献
LR-ASPP模型简介(语义分割)🍁🍁🍁
LR-ASPP原理🍁🍁🍁
LR-ASPP源码讲解(Pytorch)🍁🍁🍁
如若文章对你有所帮助,那就🛴🛴🛴