欢迎关注 OpenMMLab 公众号获取一手技术干货
当我们向 ChatGPT 提问时,我们希望他能准确地回答我们的问题。当我们向他提出不合理的要求,比如询问如何制作炸弹或者如何考试作弊,我们希望他能拒绝回答并及时纠正我们的错误。AI 对齐,就是让 AI 的价值观符合我们人类的价值观,更好地为我们所用。
为什么要自对齐(Self-alignment)
之前的对齐方式一般需要大量高质量的微调数据或者人类反馈的偏好数据,但是随着 LLM 的能力的不断提高,我们已经在越来越多的任务上逊色于 LLM,以往这种依赖于人类标注数据的对齐方式目前面临着如下两个挑战:
-
进一步提升对齐水平需要更多的高质量标注数据,成本过高,且边际效益不断递减。
-
LLM 能力超过人类,我们可能无法继续提供有效的对齐信号。面对能力强大的 LLM,我们不能轻易地分辨出他们回答的好坏来得到偏好数据,或者难以判断 LLM 回答的缺点,此时的对齐信号将不可避免存在许多噪音。
既然从人类标注数据中获取对齐信号的方式遇到了困难,那么能不能依靠模型自己依靠自己来对齐呢?当然有,这就是 Self-alignment 所要解决的问题,依靠模型自己进行对齐,尽量减少人类的干预。 根据当前工作所采用的方法,我们将 Self-alignment 的实现路线大致分为两类:
-
对齐 Pipline 数据合成:对目前对齐 Pipline 中所需的数据用 LLM 合成。传统 Pipline 主要包括 Instructions 和 Response 数据的采集,之后采用 SFT 或 RLHF 训练方式来对齐。既然 LLM 已经足够强大,我们何不利用 LLM 自己来合成这些数据。
-
Multi-agent:基于 Multi-agent 的对齐。我们可以精心设计多个 LLM 之间的组织形式,比如“左右互搏”的对抗方式或者利用多智能体协作合成微调数据。
本系列文章将分享 LLM 自对齐技术的最新研究进展,基于下图的架构,对当前 Self-alignment 相关工作进行全面梳理,厘清技术路线并分析潜在问题。
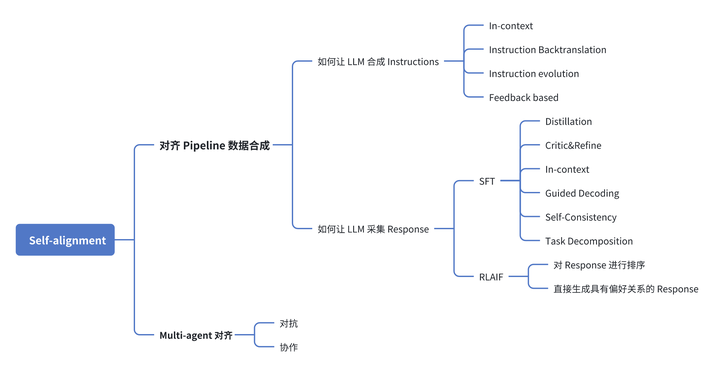
添加图片注释,不超过 140 字(可选)
对齐 Pipline 一般包括收集 Instructions、收集 Response、SFT 或 RLHF 训练三个步骤。这里收集的 Response 数据可能是人类撰写的 Response(SFT)或者是人类标注的偏好 Response(RLHF)。
该 Pipline 以数据作为驱动,依赖于高质量的标注数据。为了实现 Self-alignment,我们需要让 LLM 替代人类来采集这些数据。对于该路线的 Self-alignment,我们需要回答两个问题:
-
如何让 LLM 合成 Instructions
-
如何让 LLM 采集 Response 本篇文章将重点探讨“如何让 LLM 合成 Instructions”,深入分析现有的研究工作是如何解答这一问题的。
首先需要明确一下我们的目标——合成高质量的 Instructions,这里“高质量”涵盖了这几个方面:
-
任务多样性和复杂程度高
-
与 Response 的匹配性高
-
与当前对齐 LLM 的匹配程度高
其中前两点对多数任务都适用,可以用来构建通用的高质量数据集,第三点则更加灵活和“因材施教”,所带来的效益也最大。
目前 LLM 合成 Instructions 的工作所采用方法可以分为如下四种:In-context、Instruction Backtranslation、Instruction evolution、Feedback based。
In-context
In-context 主要利用了 LLM 的上下文学习能力,通过在上下文中加入示例,可以引导 LLM 参照示例进行“举一反三”。
较早进行该工作的是 Self-Instruct,从一个不断增加的 Task pool 中随机挑选示例加入 Prompt 中,让 LLM 仿照这些示例进行生成,该 Task pool 初始化时包含了手工撰写的种子示例,同期的 Unnatural Instructions 也采用了类似的思路,利用 3 个种子合成构建了一个数据集。
早期工作的 Prompt 上下文未加入太多的其他信息,生成数据多样性和复杂度较差,因此后续工作从已有高质量数据中引入更多先验信息。 LaMini-LM 观察到可以利用维基百科中丰富的 Topic 来引导合成 Instructions,让生成的 Instructions 符合提供的主题,进一步提高了合成数据的多样性。DYNOSAUR 则充分利用之前 NLP 多种任务已有的数据集(如文本摘要),提示 LLM 将其转换为 Instructions 和对应 Response,只要现有数据集数量不断增加,就可以持续地合成涵盖更多任务的 Instructions 数据。
当我们面临任务数据量较少或容易得到其他不相关任务的高质量数据,可以考虑通过 In-context 的方式合成数据或者对其他任务的数据转化为本任务下的 Instructions。对已有数据的挖掘方式也可以进一步探索,可以利用数据集的不同角度下的信息,比如主题、人物、实体等。
Instruction Backtranslation
Instruction Backtranslation 核心出发点是现有无标注数据集存在大量的可以被视为 Response 的内容,如果能够构造对应的Instructions,就可以得到大量的问答数据对。这种数据集的问题和回答适配度会较高。
Instruction backtranslation 较早利用该技术,他们注意到无标注的 Web 语料中存在大量适合当做 Response 的数据,因此他们首先利用现有的 SFT 数据训练一个能够根据 Response 合成 Instruction 的模型,之后对提取出的 Response 进行反向标注,该方式合成的数据可以提高 LLM 的 instruction following 能力。LongForm 和 Instruction backtranslation 方法基本一致,除了选用的无标注数据集稍有不同,由于 LongForm 更加关注长问答任务,因此从长文档中提取 Gold Response。
虽然无标注数据中存在这些看起来似乎完美的 Response,但以往工作都是依靠定义的启发式规则从无标注数据中提取,这种方式得到的 Response 不可避免含有一些噪音。比如跟问答对话形式的 Response 存在分布差异。 DoG-Instruct 训练了一个模型对无标注数据集中的 Response 进行了润色修改(Wrap),使其符合对话风格。UDIT 从无标注文本中利用各种已经完善的工具提取出不同任务下(如文本摘要、多选题)的伪标签,之后加上提前写好的 Instructions 即可构造 SFT 数据,提高了 LLM 在不同任务间的泛化性。
Instruction Backtranslation 和 In-context 都属于将 LLM 的生成能力与现有数据结合,充分挖掘现有的数据潜力。In-context 更侧重于 LLM 的生成能力,Instruction Backtranslation 则更侧重于现有数据(存在 Gold Response)。未来可以探索其他范式来结合 LLM 生成能力和现有真实数据,并取得两者间的平衡。
Instruction evolution
Instruction evolution 核心思路是根据定义好的规则对现有的 Instructions 进行改写,定义的规则和我们想要 Instructions 具有的性质有关。
较早进行该工作的是 WizardLM,主要目的在于提高 Instructions 的多样性和复杂性,因此设计从深度和广度两个方向上进行 Evolve,其中深度指的是提升 Instructions 的复杂度,可以定义增加限制、使输入更加复杂、增加推理步骤等演化规则,广度指的是生成完全不同的 Instruction,增加 Instructions 的多样性。后续该方法也用到了其他下游任务中,比如代码生成(WizardCoder)、数学推理等(WizardMath)。
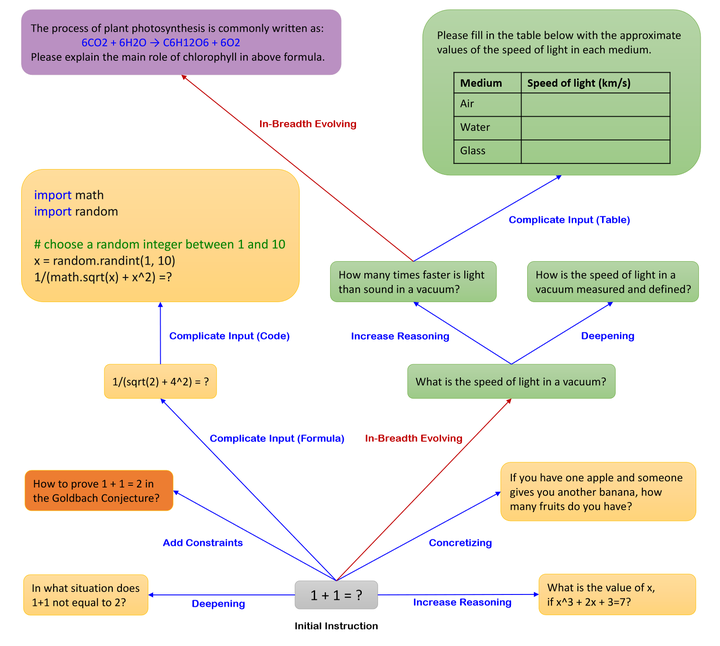
但是人为设计 evolution 的规则可能带来成本问题,这些规则缺乏泛化性,针对一种任务设计的 evolution 规则可能无法迁移到新的任务中。 Auto Evol-Instruct 尝试对这些规则的自动优化,以增加 Instructions 的复杂性为目标,设计了一个自动寻找 evolution 规则的框架。该工作让一个 Optimizer LLM 对当前 Evolution 规则下得到的 Instructions 进行分析,之后根据分析出的问题对 Evolution 规则进行优化,整个过程可以迭代多次。当需要迁移到新的任务时,只需要更换输入数据即可。
Instruction evolution 和 In-context 都是举一反三,不同的是 Instruction evolution 合成 Instructions 具有明显的方向,目前多面向复杂性和多样性两个角度,这两个数据性质也在许多工作中被证明对模型性能有增益。除了复杂性和多样性,是否有其他数据集属性也可以提高模型表现,这些未被探索的属性也可以进一步作为 Instruction evolution 的演化方向。
Feedback based
Feedback based 核心思路是根据模型的反馈来动态地调整合成 Instructions 的方向,这种方式可以针对性的提高模型某一方面的能力,所合成的 Instructions 相比较前几种方法与 LLM 更加匹配。 根据对齐场景不同,这种反馈的利用方式也随之变化,常见的有如下几个对齐场景:
提升对困难问题的回答质量
该场景下模型的 Feedback 就是回答的正确性,错误的回答可以给 Instructions 合成模型提供反馈。 LLM2LLM 让一个教师模型根据当前 LLM 的错误回答合成相似的问答对,该过程可以迭代进行,从而不断修正当前 LLM 对类似问题的回答正确性。LLMs-as-Instructors 和 LLM2LLM 采用类似的思路,也是从 LLM 错误的 Response 中获得反馈,Teacher model 之后根据当前 LLM 存在的问题和分析结果合成相似问答数据。

提升对 Harmful Instructions 的安全性
该场景下的反馈就是模型的 Response 是否符合 Harmless 的要求。Rainbow Teaming 中模型的 Feedback 被用作“适应度评价”的输入信息,来对父代和变异的子代 Red team prompts 进行筛选,哪个 Prompts 更能引起目标模型产生有害的回答,就说明该 Prompts 的适应度更高。
自动搜索模型表现欠佳的任务
在不同任务上 LLM 的表现情况也可以被当做 Feedback,此时需要其他模型对任务表现进行打分评价。AutoDetect 根据模型的回答情况来寻找缺点,他们设计了 Examiner、Questioner、Assessor 三种身份的 LLM,模型回答情况一方面提供给 Questioner 进行分析合成新的问题,另一方面则提供给 Examiner 进行知识点的更新,这些新产生的知识点将继续指导 Questioner 合成问题。
另外,除了根据 Feedback 进行 Instructions 合成,还可以根据 Feedback 对合成 Instructions 进行筛选,也能起到定向适配的效果。Selective Reflection-Tuning 让 Teacher model 对 Instructions 润色合成后,利用 Student model 的困惑度计算 IFD 分数,筛选出对于 Student model 比较困难的指令。
目前基于反馈的工作更偏向于被动反馈,需要对模型表现情况进行主动询问测试才可以得到,可能会面临搜索空间过大的问题,需要大量测试样本才能得到有效的反馈。未来可以考虑:1. 如何减小搜索空间;2.是否存在模型测试表现之外的其他反馈形式;3. 是否可以让待测模型主动反馈。
总结
本文我们重点探讨了“如何让 LLM 合成 Instructions”,解决了 Instructions 从哪里来的问题。下一篇文章,我们将重点探讨“如何让 LLM 采集 Response”,敬请期待哦!



















