前面介绍过,只要某条流的 inflt 在 bdp 之外再增加一个相等的余量 I,即 inflt = bdp + I,比如 I = 2,I = 3,…,就一定会收敛到公平,且不会占据过多 buffer,因此 rtt 不会膨胀,I 的大小影响收敛速度,I 越大,收敛越快,但 buffer 占据也更多,I 越小,收敛越慢,但 buffer 占据更少,所以效率和公平的 tradeoff 在此体现。
记住这个简洁的结论,然后将 I 调整为动态的负反馈,就是一个新算法,该算法占据 “一定量” 的 buffer 而不是像 aimd 那样抖动,占据 buffer 的大小由 I 的均值决定。平稳压倒一切,抖动是低效的根源,始终占据一定量的 buffer 是可以接受的,通过调参可以将这个 “一定量” 压到尽可能小。
简单用 c 实现了一版 inflight 守恒算法,非常简洁:
#include <stdio.h>
#include <stdlib.h>
#define BW_FILTER_LEN 10
double RTPROP = 1;
double C = 100.0; // bottleneck_link_bw
double I = 0.0;
struct es {
double E;
double bw;
};
struct ebest_flow {
int index; /* flow identifier */
int status;
double I;
double inflt;
double min_rtt;
double srtt;
double sending_bw; /* current receive bw */
double receive_bw; /* current receive bw */
struct es max_e; /* current estimated bw */
struct es e_samples[BW_FILTER_LEN];
int phase_offset;
};
struct ebest_flow f1;
struct ebest_flow f2;
struct ebest_flow f3;
struct ebest_flow f4;
int t = 0;
int bw_filter_index = 0;
#define max(a, b) (a > b) ? (a) : (b)
#define min(a, b) (a < b) ? (a) : (b)
void ebest_set_max_e(struct ebest_flow *f)
{
int i = 0;
f->max_e.bw = 0;
for (i = 0; i < BW_FILTER_LEN; i++) {
f->max_e.E = max(f->max_e.E, f->e_samples[i].E);
f->max_e.bw = f->e_samples[i].bw;
}
f->I = 0.7 * f->I + 0.3 * 40 * f->min_rtt * f->max_e.bw/(20 * f->min_rtt + f->max_e.bw * f->srtt) * (f->min_rtt / f->srtt);
}
void ebest_update_maxbw_minrtt(struct ebest_flow *f, double rtt)
{
rtt = (rtt > RTPROP)?:RTPROP;
f->e_samples[bw_filter_index].E = f->receive_bw / rtt;
f->e_samples[bw_filter_index].bw = f->receive_bw;
ebest_set_max_e(f);
if (rtt <= f->min_rtt) {
f->srtt = f->min_rtt = rtt;
} else {
f->srtt = rtt;
}
}
void ebest_update_sending_bw(struct ebest_flow *f)
{
f->inflt = f->max_e.bw * f->min_rtt + f->I;
printf("#### f: %d %.3f\n", f->index, f->I);
f->sending_bw = f->max_e.bw;
printf("flow %d phase: %d max_bw: %.3f sending_bw: %.3f\n",
f->index, 0, f->max_e.bw, f->sending_bw);
}
void simulate_one_phase(int i)
{
double rtt;
//if (i == 1500)
// C = 160;
//if (i == 2500)
// C = 40;
ebest_update_sending_bw(&f1);
ebest_update_sending_bw(&f2);
ebest_update_sending_bw(&f3);
ebest_update_sending_bw(&f4);
printf("t= %04d sending: f1: %.3f f2: %.3f f3: %.3f f4: %.3f\n",
t, f1.sending_bw, f2.sending_bw, f3.sending_bw, f4.sending_bw);
double total_I = 0;
if (i < 1000) {
rtt = (f1.inflt + f2.inflt + f3.inflt) / C;
f1.receive_bw = C * f1.inflt / (f1.inflt + f2.inflt + f3.inflt);
f2.receive_bw = C * f2.inflt / (f1.inflt + f2.inflt + f3.inflt);
f3.receive_bw = C * f3.inflt / (f1.inflt + f2.inflt + f3.inflt);
f4.receive_bw = 0;
f4.max_e.bw = 0;
f4.inflt = 0;
if (i == 999) {
f4.max_e.bw = 0.1 * C;
f4.inflt = 0.1 * C * RTPROP + I;
f4.I = I;
f4.receive_bw = 0.1 * C;
printf("@@@@### time: %d f1: %.3f f2: %.3f f3: %.3f f4: %.3f \n", t, f1.inflt, f2.inflt, f3.inflt, f4.inflt);
}
total_I = f1.I + f2.I + f3.I;
printf("t= %04d remain: f1: %.3f f2: %.3f f3: %.3f f4: %.3f\n",
t, f1.I, f2.I, f3.I, total_I);
} else if (i >= 1000 && i < 2000) {
rtt = (f1.inflt + f2.inflt + f3.inflt + f4.inflt) / C;
f1.receive_bw = C * f1.inflt / (f1.inflt + f2.inflt + f3.inflt + f4.inflt);
f2.receive_bw = C * f2.inflt / (f1.inflt + f2.inflt + f3.inflt + f4.inflt);
f3.receive_bw = C * f3.inflt / (f1.inflt + f2.inflt + f3.inflt + f4.inflt);
f4.receive_bw = C * f4.inflt / (f1.inflt + f2.inflt + f3.inflt + f4.inflt);
if (i < 1100) {
printf("@@@@### time: %d f1: %.3f f2: %.3f f3: %.3f f4: %.3f \n", t, f1.inflt, f2.inflt, f3.inflt, f4.inflt);
}
total_I = f1.I + f2.I + f3.I + f4.I;
printf("t= %04d remain: f1: %.3f f2: %.3f f3: %.3f f4: %.3f\n",
t, f1.I, f2.I, f3.I, total_I);
} else {
rtt = (f1.inflt + f2.inflt) / C;
f1.receive_bw = C * f1.inflt / (f1.inflt + f2.inflt);
f2.receive_bw = C * f2.inflt / (f1.inflt + f2.inflt);
f3.receive_bw = 0;
f4.receive_bw = 0;
f3.max_e.bw = 0;
f4.max_e.bw = 0;
f3.inflt = 0;
f4.inflt = 0;
total_I = f1.I + f2.I;
printf("t= %04d remain: f1: %.3f f2: %.3f f3: %.3f f4: %.3f\n",
t, f1.I, f2.I, f3.I, total_I);
}
if (rtt < RTPROP)
rtt = RTPROP;
printf("t= %04d receive: f1: %.3f f2: %.3f f3: %.3f f4: %.3f\n",
t, f1.receive_bw, f2.receive_bw, f3.receive_bw, f4.receive_bw);
ebest_update_maxbw_minrtt(&f1, rtt);
ebest_update_maxbw_minrtt(&f2, rtt);
ebest_update_maxbw_minrtt(&f3, rtt);
ebest_update_maxbw_minrtt(&f4, rtt);
printf("t= %04d max_bw: f1: %.3f f2: %.3f f3: %.3f f4: %.3f\n",
t, f1.max_e.bw, f2.max_e.bw, f3.max_e.bw, f4.max_e.bw);
printf("t= %04d inflt: f1: %.3f f2: %.3f f3: %.3f f4: %.3f\n",
t, f1.inflt, f2.inflt, f3.inflt, f4.inflt);
printf("t= %04d min_rtt: f1: %.3f f2: %.3f f3: %.3f f4: %.3f\n",
t, rtt, f2.min_rtt, f3.min_rtt, f4.min_rtt);
t++;
bw_filter_index = (bw_filter_index + 1) % BW_FILTER_LEN;
}
int main(int argc, char *argv[])
{
int i = 0;
if (argc > 1) I = atof(argv[1]);
f1.index = 1;
f2.index = 2;
f3.index = 3;
f4.index = 4;
f1.max_e.bw = 0.9 * C;
f2.max_e.bw = 0.3 * C;
f3.max_e.bw = 0.6 * C;
f1.max_e.E = f1.max_e.bw / RTPROP;
f2.max_e.E = f2.max_e.bw / RTPROP;
f3.max_e.E = f3.max_e.bw / RTPROP;
f1.I = I;
f2.I = I;
f3.I = I;
f4.I = 0;
f1.srtt = f1.min_rtt = RTPROP;
f2.srtt = f2.min_rtt = RTPROP;
f3.srtt = f3.min_rtt = RTPROP;
f4.srtt = f4.min_rtt = RTPROP;
f1.inflt = 0.1 * C * RTPROP;
f2.inflt = 0.3 * C * RTPROP;
f3.inflt = 0.6 * C * RTPROP;
f1.e_samples[BW_FILTER_LEN - 1] = f1.max_e;
f2.e_samples[BW_FILTER_LEN - 1] = f2.max_e;
f3.e_samples[BW_FILTER_LEN - 1] = f3.max_e;
for (i = 0; i < 3000; i++) {
simulate_one_phase(i);
}
return 0;
}
算法和建模分别参见 inflight 守恒背后的哲学 与 inflight 守恒数学建模.
这个算法的核心只需要设置 remain 余量,剩下的跟踪 E_best = max(bw / delay) 即可,因此 remain 一定是个负反馈方程:
R e m a i n = α ⋅ R T T m i n ⋅ B W w h e n _ E _ b e s t β ⋅ R T T m i n + B W w h e n _ E _ b e s t ⋅ R T T s m o o t h ⋅ R T T m i n R T T s m o o t h Remain=\dfrac{\alpha\cdot RTT_{min}\cdot BW_{when\_E\_best}}{\beta \cdot RTT_{min}+BW_{when\_E\_best}\cdot RTT_{smooth}}\cdot \dfrac{RTT_{min}}{RTT_{smooth}} Remain=β⋅RTTmin+BWwhen_E_best⋅RTTsmoothα⋅RTTmin⋅BWwhen_E_best⋅RTTsmoothRTTmin
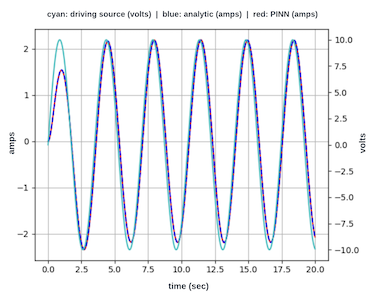
效果如下:

明显有负反馈效果,但还是需要增加自由度,继续调参,我需要的效果是无论多少条流,所有流的 Remain 之和在一个有限范围内。
而 inflt 收敛效果如下:

rtt 平稳且并未膨胀:

浙江温州皮鞋湿,下雨进水不会胖。