1 项目目标
(1)熟练部署alertmanager
(2)熟练整合alertmanager+Prometheus
(3)熟练alertmanager分组、抑制、静默
2 项目准备
2.1 规划节点
| 主机名 | 主机IP | 节点规划 |
| prome-master01 | 10.0.1.10 | 服务端 |
| prome-node01 | 10.0.1.20 | 客户端 |
2.2 基础准备
系统镜像:centos7.9
安装包下载网址:Releases · prometheus/alertmanager (github.com)
环境准备:详情看我主页前几篇文章
3 项目实施
3.1 alertmanager简介及部署
Alertmanager处理由诸如Prometheus服务器之类的客户端应用程序发送的警报。
核心功能点
| 英文 | 中文 | 含义 |
| deduplicating | 重复数据删除 | prometheus产生同一条报警 |
| grouping | 分组 | 告警可以分组处理,同一个组里共享等待时长等参数 |
| route | 路由 | 路由匹配树,可以理解为告警订阅 |
| silencing | 静默 | 灵活的告警静默,如按tag |
| inhibition | 抑制 | 如果某些其他警报已经触发,则抑制某些警报的通知 |
| HA | 高可用性 | gossip实现 |
去这里下最新版Releases · prometheus/alertmanager (github.com)
wget https://github.com/prometheus/alertmanager/releases/download/v0.27.0/alertmanager-0.27.0.linux-amd64.tar.gz
tar xf alertmanager-0.27.0.linux-amd64.tar.gz -C /usr/local/
mv /usr/local/alertmanager-0.27.0.linux-amd64/ /usr/local/alertmanager
vim /usr/lib/systemd/system/alertmanager.service
[Unit]
Description="alertmanager"
Documentation=https://alertmanager.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml --storage.path=/usr/local/alertmanager/data/
Restart=on-failure
RestartSecs=5s
SuccessExitStatus=0
LimitNOFILE=65536
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=alertmanager
[Install]
WantedBy=multi-user.target
systemctl start alertmanager
systemctl enable alertmanager
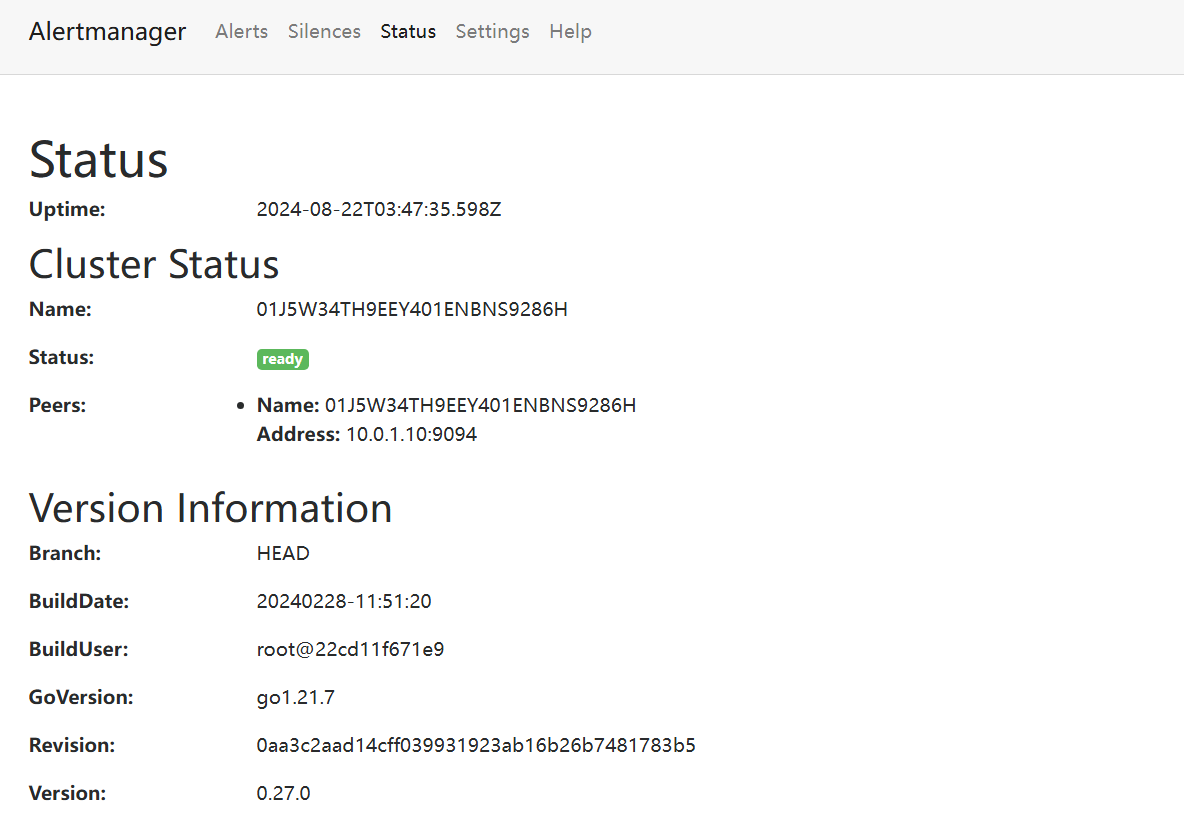
systemctl status alertmanager访问IP:9093

查看status
config文件
global:
# 如果一个告警不包括EndsAt,经过此时间后,如果尚未更新警报,则可以将警报声明为已恢复。
# 这对Prometheus的警报没有影响,因为它们始终包含EndsAt。
resolve_timeout: 5m
# 默认的httpconfig 如果下面webhook为空的时候用这个
http_config: {}
# smtp配置
smtp_hello: localhost
smtp_require_tls: true
# 几个默认支持地址
pagerduty_url: https://events.pagerduty.com/v2/enqueue
opsgenie_api_url: https://api.opsgenie.com/
wechat_api_url: https://qyapi.weixin.qq.com/cgi-bin/
victorops_api_url: https://alert.victorops.com/integrations/generic/20131114/alert/
route:
# 代表路由树的默认receiver
# 匹配不中就走这个
receiver: web.hook
# 分组依据,比如按alertname分组
group_by:
- alertname
# 代表新的报警最小聚合时间,第一次来的时候最短间隔
group_wait: 10s
# 代表同一个组里面告警聚合时间 同一个group_by 里面不同tag的聚合时间
group_interval: 10s
# 代表同一个报警(label完全相同)的最小发送间隔
repeat_interval: 1h
# 抑制规则
# 可以有效的防止告警风暴
# 下面的含义: 当拥有相同 alertname,dev ,instance标签的多条告警触发时
# 如果severity=critical的已出发,抑制severity=warning的
inhibit_rules:
- source_match:
severity: critical
target_match:
severity: warning
equal:
- alertname
- dev
- instance
# 接受者配置
receivers:
- name: web.hook
webhook_configs:
- send_resolved: true
http_config: {}
url: http://127.0.0.1:5001/
max_alerts: 0
# 文本模板
templates: []3.2 测试报警
与Prometheus整合
vim /usr/local/prometheus/prometheus.yml
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['10.0.1.10:9093']
systemctl daemon-reload
systemctl restart prometheus测试报警
1.使用 alert_receive.py 作为告警接受端
2.使用 alertm_send.py 调alerm的接口发送告警
3.查看alert_receive.py 日志和alertm页面
准备好以下这两个文件。
alert_send.py
import requests
"""
可以把各种云的云监控信息调用alertmanager 的api 把告警接入:
1. 注册公有云消息通知服务SMN 接收推送消息
2. etl后调 /api/v1/alerts
"""
def send(host):
uri = "http://{}:9093/api/v2/alerts".format(host)
data = [
{
"labels": {
"alertname": "2024-8-23-alart-test",
"group": "abc",
# "unionProject": "net_monitor",
"severity": "2",
"job": "node_exporter",
"k1": "v1",
},
"annotations": {
"value": "100ms"
},
},
]
res = requests.post(uri,json=data)
print(res.status_code)
print(res.text)
send("10.0.1.10")alert_receive.py
import json
from flask import request, Flask, jsonify, redirect
import logging
logging.basicConfig(
format='%(asctime)s %(levelname)s %(filename)s [func:%(funcName)s] [line:%(lineno)d]:%(message)s',
datefmt="%Y-%m-%d %H:%M:%S",
level="INFO"
)
app = Flask(__name__)
"""
2021-05-02 10:40:31 INFO a.py [func:push_metrics_redirect] [line:28]:[host:127.0.0.1:5001][path:/alert][data:b'{"receiver":"web\\\\.hook","status":"firing","alerts":[{"status":"firing","labels":{"alertname":"node_load","instance":"192.168.43.114:9100","job":"node_exporter","severity":"critical"},"annotations":{"summary":"\xe6\x9c\xba\xe5\x99\xa8\xe5\xa4\xaa\xe7\xb4\xaf\xe4\xba\x86"},"startsAt":"2021-05-02T02:39:16.628934947Z","endsAt":"0001-01-01T00:00:00Z","generatorURL":"http://prome-master01:9090/graph?g0.expr=node_load1+%3E+0\\u0026g0.tab=1","fingerprint":"40ee791929e72e8b"}],"groupLabels":{"alertname":"node_load"},"commonLabels":{"alertname":"node_load","instance":"192.168.43.114:9100","job":"node_exporter","severity":"critical"},"commonAnnotations":{"summary":"\xe6\x9c\xba\xe5\x99\xa8\xe5\xa4\xaa\xe7\xb4\xaf\xe4\xba\x86"},"externalURL":"http://prome-master01:9093","version":"4","groupKey":"{}:{alertname=\\"node_load\\"}","truncatedAlerts":0}\n']
2021-05-02 10:40:31 INFO _internal.py [func:_log] [line:113]:127.0.0.1 - - [02/May/2021 10:40:31] "POST /alert HTTP/1.1" 200 -
data = {'receiver': 'web\\.hook', 'status': 'resolved', 'alerts': [{'status': 'resolved',
'labels': {'alertname': 'node_load',
'instance': '10.0.1.10:9100',
'job': 'node_exporter',
'severity': 'critical'},
'annotations': {'summary': '机器太累了'},
'startsAt': '2021-05-02T02:39:16.628934947Z',
'endsAt': '2021-05-02T02:54:31.628934947Z',
'generatorURL': 'http://prome-master01:9090/graph?g0.expr=node_load1+%3E+0&g0.tab=1',
'fingerprint': '40ee791929e72e8b'},
{'status': 'resolved',
'labels': {'alertname': 'node_load',
'instance': '10.0.1.10:9100',
'job': 'node_exporter',
'severity': 'critical'},
'annotations': {'summary': '机器太累了'},
'startsAt': '2021-05-02T02:41:46.628934947Z',
'endsAt': '2021-05-02T02:46:16.628934947Z',
'generatorURL': 'http://prome-master01:9090/graph?g0.expr=node_load1+%3E+0&g0.tab=1',
'fingerprint': '0fd88a48463c0b87'}],
'groupLabels': {'alertname': 'node_load'},
'commonLabels': {'alertname': 'node_load', 'job': 'node_exporter', 'severity': 'critical'},
'commonAnnotations': {'summary': '机器太累了'}, 'externalURL': 'http://prome-master01:9093', 'version': '4',
'groupKey': '{}:{alertname="node_load"}', 'truncatedAlerts': 0}
"""
@app.route('/', methods=['GET', 'PUT', 'POST'])
def push_metrics_redirect():
req_data = request.data
req_path = request.path
req_host = request.host
msg = "[host:{}][path:{}][data:{}]".format(
req_host,
req_path,
req_data,
)
logging.info(msg)
return jsonify("haha"), 200
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5001, threaded=True, processes=1)
到prom-node1将receive部署执行,作为接收端
mkdir alert_receive
cd alert_receive
pip3 install flask
vim alert_receive.py
python3 alert_receive.py在pycharm执行send,作为告警发送端
python alert_receive.py发现接收端收到,告警
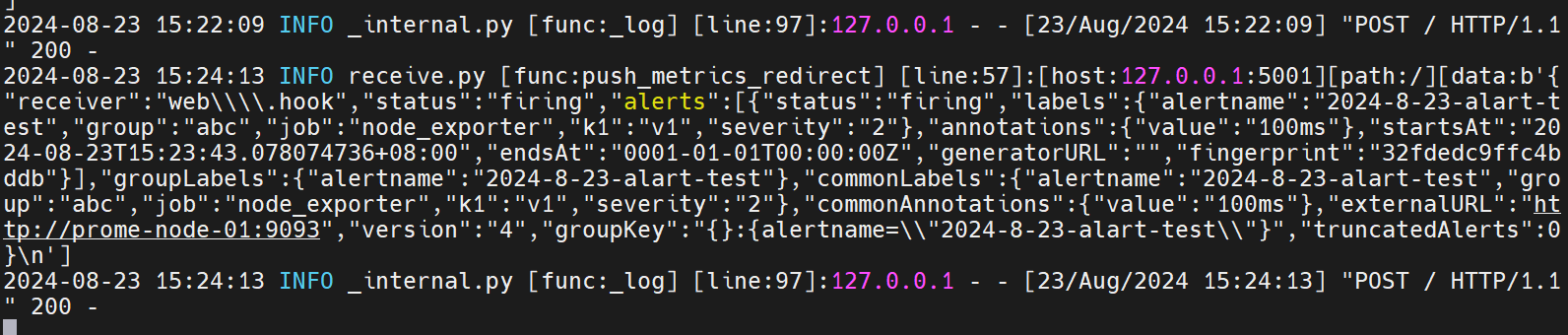
登录上alertmanager的web端
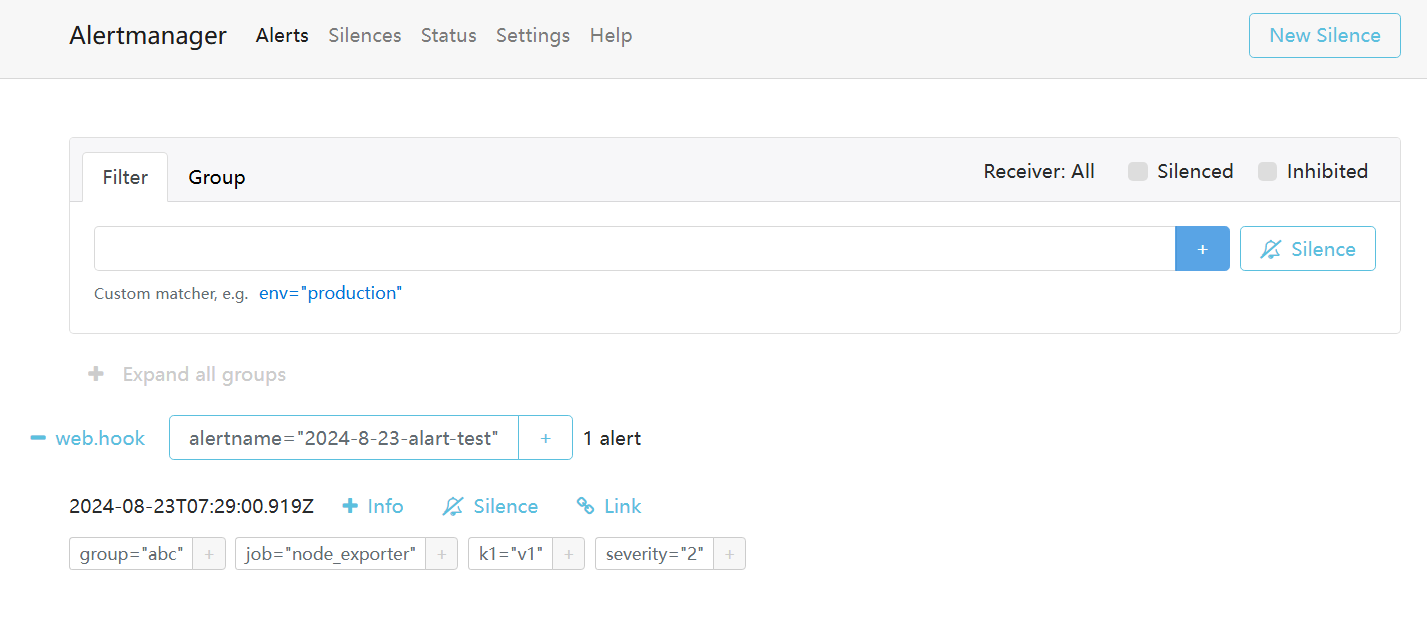
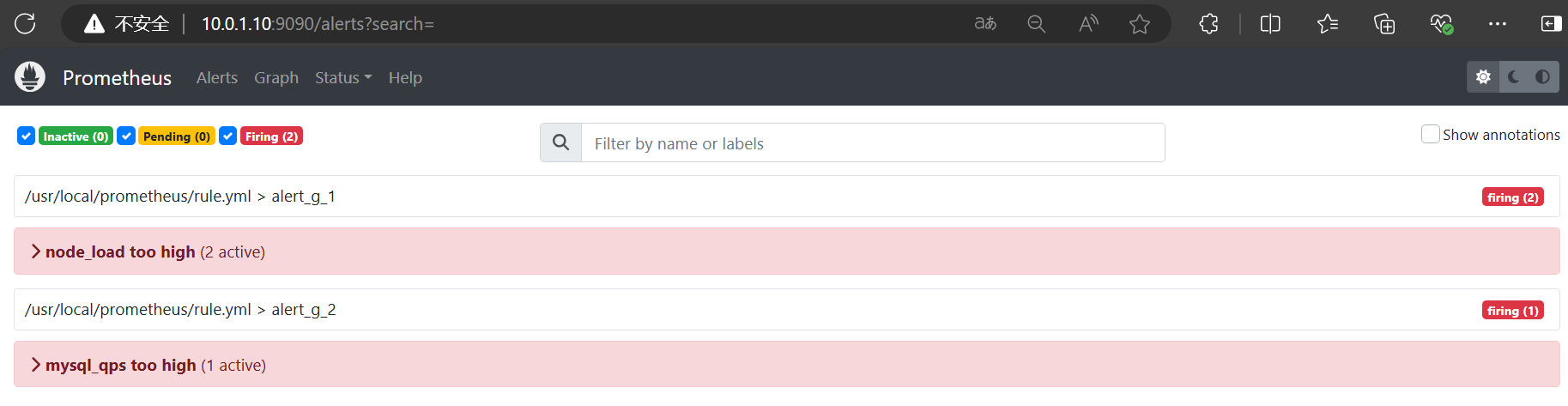
编写rule.yml文件
groups:
- name: alert_g_1
rules:
- alert: node_load too high
expr: node_memory_Active_bytes>0
labels:
severity: critical
node_name: abc
annotations:
summary: 机器太累了
- name: alert_g_2
rules:
- alert: mysql_qps too high
expr: mysql_global_status_queries >0
labels:
severity: warning
node_name: abc
annotations:
summary: mysql太累了修改Prometheus配置文件,添加rule文件地址
rule_files:
- /usr/local/prometheus/rule.yml查看prometheus的alert页面。
3.3 告警分组
Alertmanager 的分组功能可以帮助您更好地管理和组织警报,以便更高效地处理它们。分组允许您根据不同的标准将警报合并成组,从而减少通知的数量,并使得接收者更容易处理。
- job=node_exporter 由 IT_system处理 5001端口
- job=mysqld_exporter 由 IT_dba处理 5002端口
- 所有的告警 由 sre_all处理 5003端口
修改alertmanager配置文件
vim /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 30m
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 1h
receiver: 'sre_all'
routes: #子路由,父路由的所有属性都会被子路由继承
- match_re: #此路由在警报标签上执行正则表达式匹配,以捕获与服务列表相关的警报
job: node_exporter
receiver: sre_system
# 代表继续向下匹配,不然就break了
# 只能向下匹配
continue: true
- match_re:
job: mysqld_exporter
receiver: sre_dba
continue: true
# 默认all路由
- match_re:
job: .*
receiver: sre_all
continue: true
receivers:
- name: 'sre_system'
webhook_configs:
- url: 'http://127.0.0.1:5001/alert'
- name: 'sre_dba'
webhook_configs:
- url: 'http://127.0.0.1:5002/alert'
- name: 'sre_all'
webhook_configs:
- url: 'http://127.0.0.1:5003/alert'
编辑alert_receive.py文件,修改alert。
# 修改这一行
@app.route('/alert', methods=['GET', 'PUT', 'POST'])
mv alert_receive.py receive5001.py
[root@prome-node-01 alert_receive]# cp receive5001.py receive5002.py
[root@prome-node-01 alert_receive]# cp receive5001.py receive5003.py
vim receive5002.py
# 修改这一行
app.run(host='0.0.0.0', port=5002, threaded=True, processes=1)
vim receive5003.py
# 修改这一行
app.run(host='0.0.0.0', port=5003, threaded=True, processes=1)分别启动三个flask接收器。模拟三个发送/处理通道
systemctl stop alertmanager
python3 receive5001.py
python3 receive5002.py
python3 receive5003.py
systemctl start alertmanager启动服务即可

执行alert_send.py
python3 alert_send.py效果
sre_all收到所有,其余两个收到各自的。
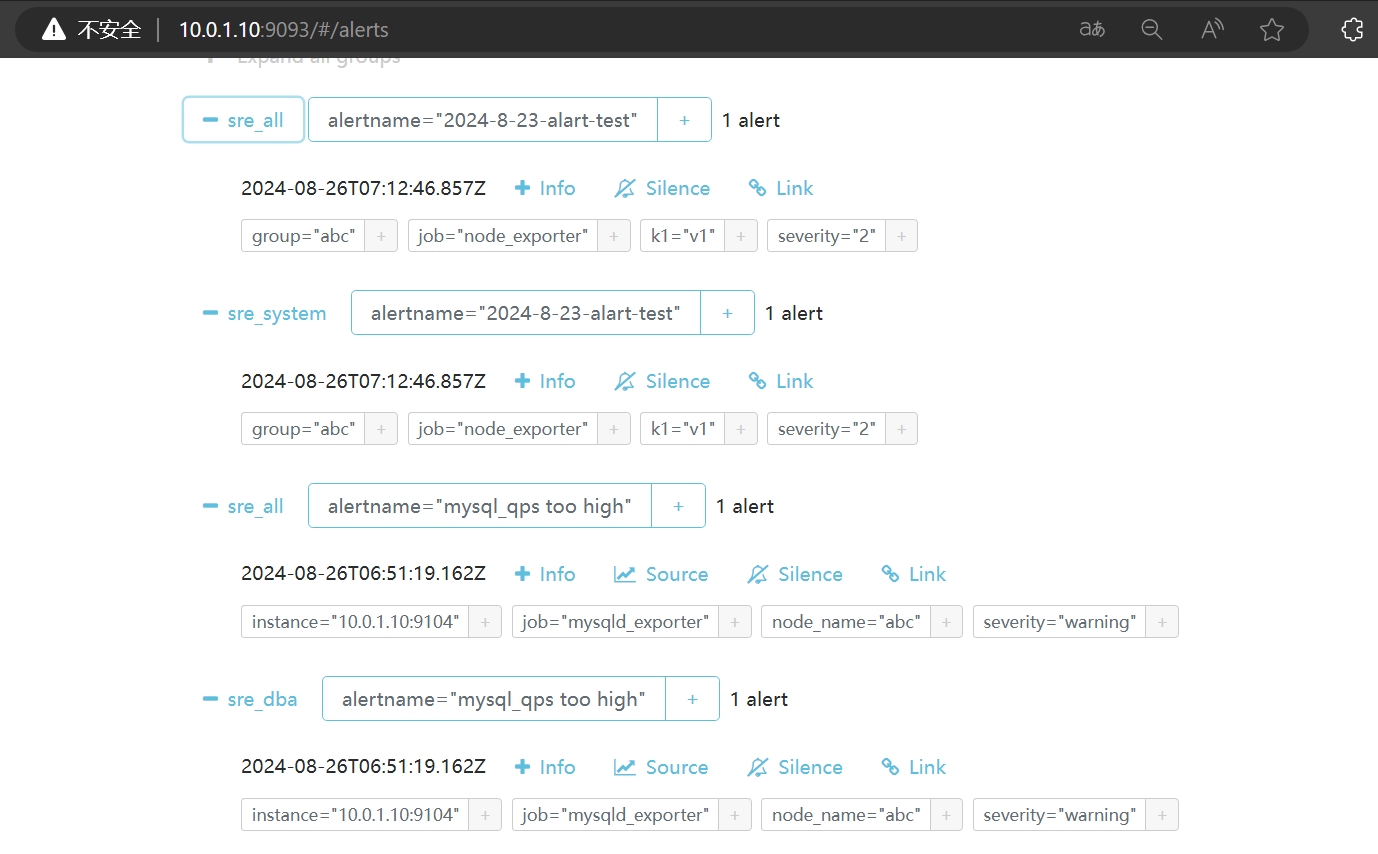
3.4 抑制
Alertmanager 的抑制(Inhibition)功能可以让您控制何时发送警报,以减少不必要的通知。通过设置抑制规则,可以避免在某些条件下触发重复或不重要的警报。
抑制的基本思想是定义一组规则,这些规则可以阻止某些警报在特定情况下被发送出去。例如,如果您有一个严重级别的警报和一个非严重级别的警报,您可以配置抑制规则来防止在严重级别警报已经触发的情况下再发送非严重级别的警报。
告警中同一个机器instance触发了的 critical告警要抑制warning的
修改alertmanager.yml配置文件,在最后添加:
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
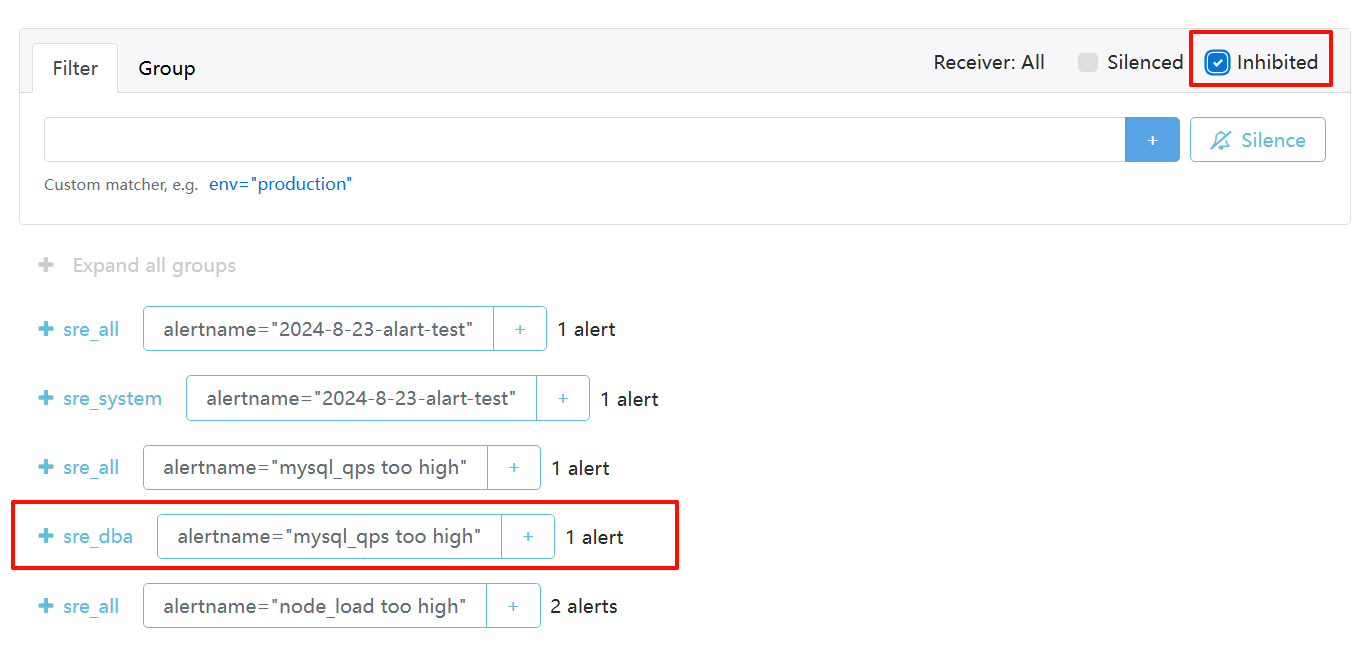
equal: ['node_name']node_name相同的,接收到critical的告警就不用发送warning了,抑制。5002 那个mysqld接收不到了
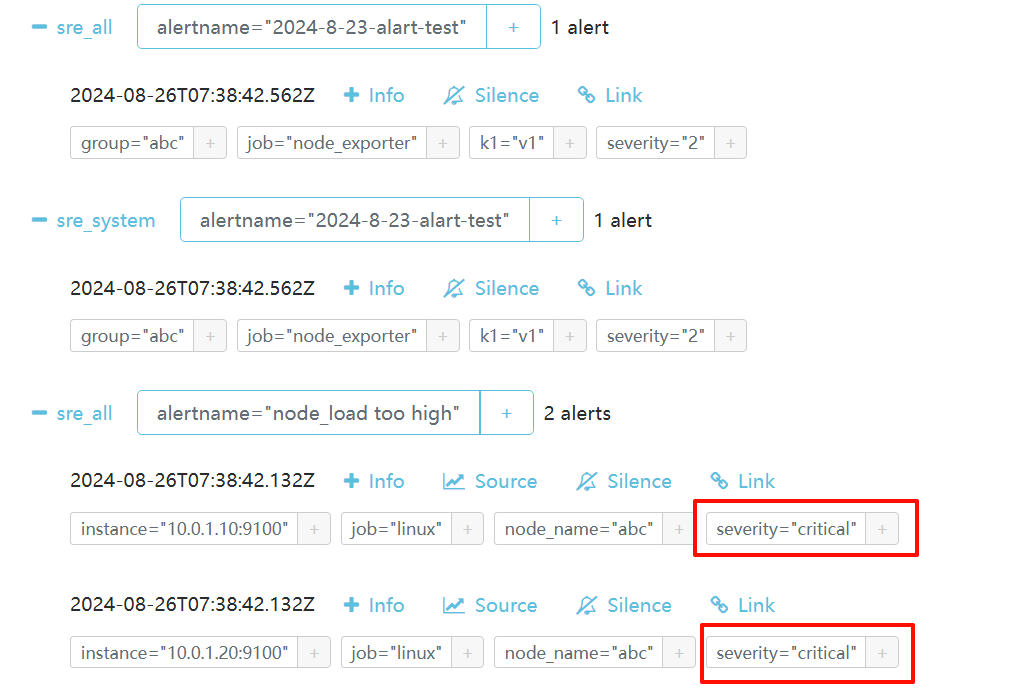
点击查看显示inhibited抑制。
3.5 静默
Alertmanager 的静默(Silencing)功能可以让临时禁止某些警报的发送。这在进行计划内的维护操作或者知道某个问题正在解决过程中时非常有用,可以避免不必要的警报通知。
编写python脚本,根据实际需求修改时间,静默条件等。
"startsAt":"2024-05-02T04:16:08.334Z",
"endsAt":"2024-09-02T06:16:08.334Z",
alert_silence.py
import json
import requests
def create_silence(host):
"""
:return {"silenceID":"85b1506f-41a9-40c0-a950-c8a460dcbfa4"}
"""
payload = {
"matchers":[
{
"name":"job",
"value":"node_exporter",
"isRegex":False
}
],
"startsAt":"2024-05-02T04:16:08.334Z",
"endsAt":"2024-09-02T06:16:08.334Z",
"createdBy":"keli",
"comment":"just test",
"id":None
}
uri = "http://{}:9093/api/v2/silences".format(host)
res = requests.post(uri,json=payload)
print(res.status_code)
create_silence("10.0.1.10")执行脚本,到网页上查看结果:
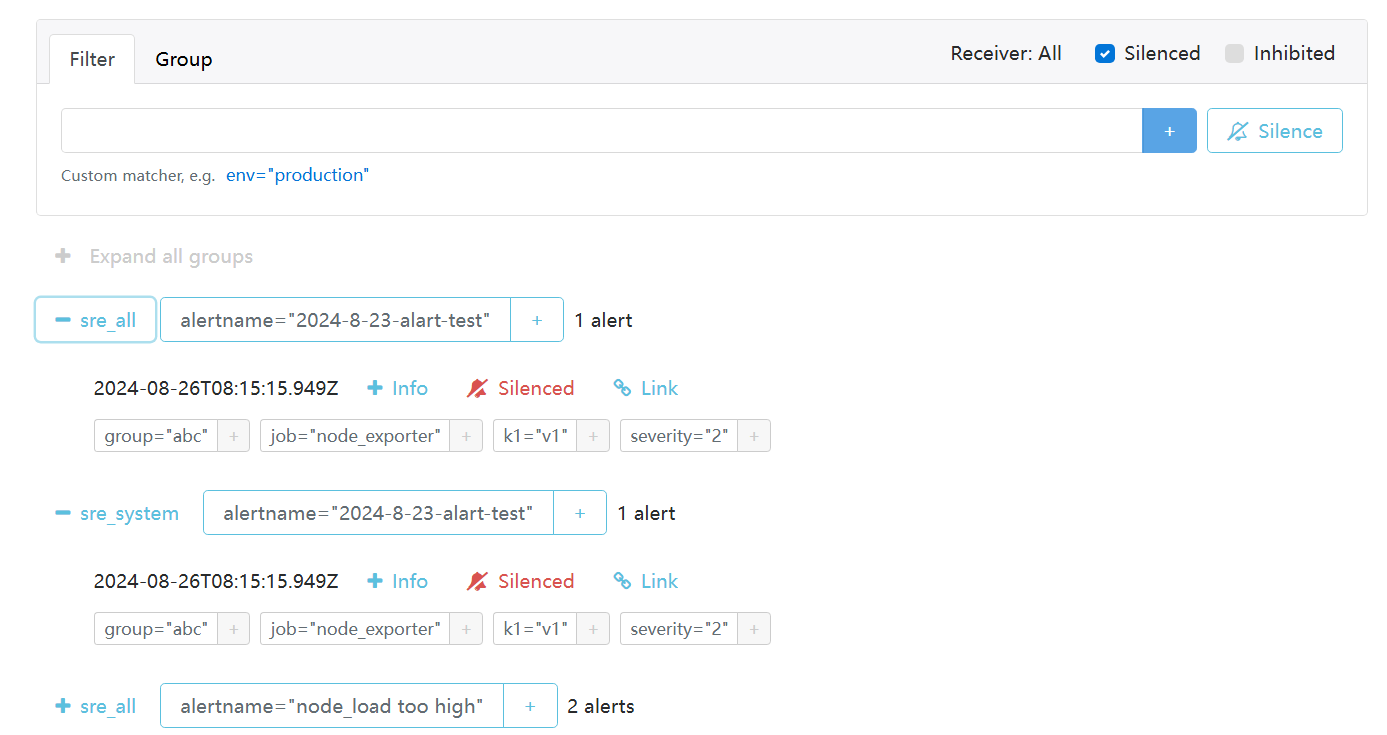
也可以在web页面直接添加silence。

还可以在钉钉中执行静默,使用交互式卡片。
3.6 高可用
Alertmanager 的高可用(High Availability, HA)部署的主要目的是确保即使在部分组件出现故障的情况下,警报管理系统仍能持续运行并且可靠地发送警报。在 Alertmanager 的高可用(HA)部署中,抑制(Inhibition)和静默(Silencing)规则也是需要在集群中同步的,以确保所有实例之间的一致性和协调。
- 其余节点启动systemd参数加上对端ip即可
在这一行上添加 --cluster.peer=10.0.1.10:9094
ExecStart=/opt/app/alertmanager/alertmanager --config.file=/opt/app/alertmanager/alertmanager.yml --storage.path=/opt/app/alertmanager/data/