本文选自公众号文章:
https://mp.weixin.qq.com/s/xyUMWTyEu7-Uws8Zfxifpghttps://wx2.qq.com/cgi-bin/mmwebwx-bin/webwxcheckurl?requrl=https%3A%2F%2Fmp.weixin.qq.com%2Fs%2FxyUMWTyEu7-Uws8Zfxifpg&skey=%40crypt_963c540a_c8e6882f00ef27f0c27a8357dea508a7&deviceid=e018551237441330&pass_ticket=hKeIzPnVjzg5Gn7uOm%252BlJOTiRD7vgY4FzwOwt95fv%252FXb3GpjM6qwNVI%252FK7ofv%252F1ldF2x9nulDZZv%252FwcixkBjtw%253D%253D&opcode=2&scene=1&username=@ffc933edb70ad383b17c80ff12e7fdd90fb0657914699f6e81d16e97be7c7b28
(1)在C99标准中引入了可变长度数组 (Variable-Length Arrays, VLA) 的概念。可变长度数组允许在运行时确定数组的大小,这使得数组的大小可以在函数调用时动态决定。例如:
#include <stdio.h>
int main(void) {
int n;
scanf("%d",&n) ;
int a[n];
for(int i=0; i<n; i++) {
a[i]=i;
}
for(int i=0; i<n; i++) {
printf("%d ",a[i]);
}
printf("\n");
return 0;
}在C++中,标准C++并不直接支持可变长度数组。C++11及以后的标准没有引入类似C99中的可变长度数组特性。然而,C++中可以使用其他机制来达到类似的效果。
(2)分析下面的程序:
#include <stdio.h>
int main() {
int *pa1,*pa2, *pb1,*pb2;
int a[15]= {0};
int b[3][5]= {0};
pa1 = a;
pa2 = a+1;
pb1 = b;
pb2 = b+1;
printf("%p,%p,%d\n",pa1, pa2, pa2-pa1);
printf("%p,%p,%d\n",pb1, pb2, pb2-pb1);
return 0;
}数组名表示整个数组在存储空间中的起址,因此可以把数组名看作是一个指针,因此,a的类型为int *,b的类型为int (*)[5](指向含有5个整数的一维数组的指针)。
用C/C++语法分析第6行第7行语句。
第6行:pa1 = a;
pa1 被定义为指向整数的指针;a是一个包含15个整数的数组。
数组名a实际上是数组首元素的地址。因此,pa1 = a; 的效果是将 a 的首元素地址赋值给 pa1。结果:pa1指向 a 数组的第一个元素。
第7行:pa2 = a + 1;
pa2 同样被定义为指向整数的指针;a+1 的效果是将 a 的地址加上一个整数的大小(通常是4字节,取决于平台)。这意味着 pa2 指向 a 数组的第二个元素。结果:pa2 现在指向 a 数组的第二个元素。
总结:pa1指向 a 数组的第一个元素,pa2指向 a 数组的第二个元素。这两个语句都是正确的,并且按照预期的行为工作。
用C/C++语法分析第8行第9行语句。
通过前面的介绍知道,b的类型是 int (*)[5],而不是简单的 int*。这意味着 b 指向的是一个包含5个整数的数组,而不是单个整数。
对于语句:pb1 = b;
pb1 被定义为指向整数的指针,b 是一个二维数组,包含3行5列的整数。数组名 b 实际上是指向含有5个整数的一维数组的指针,即 int (*)[5]。因此,pb1 = b; 的效果是尝试将 b 的首元素地址赋值给 pb1。
这里有一个类型不匹配的问题。pb1 是一个指向整数的指针,而 b 的类型是 int (*)[5],即指向含有5个整数的一维数组的指针。所以,这个语句会导致编译错误,因为 pb1 的类型与 b 的类型不匹配。
同样,语句:pb2 = b + 1;
也类似。b + 1 的效果是将 b 的地址加上一个一维数组的大小(通常是5个整数的大小)。这意味着 pb2 试图指向 b 数组的第二个一维数组。与 pb1 = b; 类似,这里同样存在类型不匹配的问题。所以,这个语句也会导致编译错误,因为 pb2 的类型与 b + 1 的类型不匹配。
总之,pb1 和 pb2 的类型都是 int *,即指向整数的指针。b 的类型是 int (*)[5],即指向含有5个整数的一维数组的指针。pb1 = b; 和 pb2 = b + 1; 都会导致编译错误,因为 pb1 和 pb2 的类型与 b 的类型不匹配。
但是,该程序在C编译器下编译仅出现警告信息,但能正确编译,也能得到正确的结果。
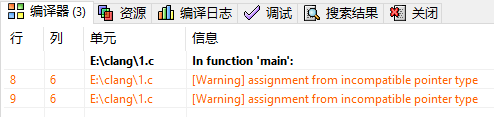
程序运行结果如下图所示。
![]()
而在C++编译器下编译出现错误信息。
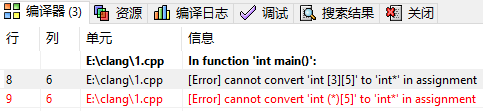
为什么?在C语言中,虽然标准不允许int (*)[5]到int *的隐式转换,但在实际编译中可能通过,这主要是因为一些 C 编译器在处理代码时可能较为宽松,对不符合标准的类型转换没有严格报错。但这并不代表这种转换是正确的行为,使用这样的转换可能会导致不可预期的结果。
而在 C++ 中编译不通过是因为 C++ 的类型检查通常更加严格。C++ 致力于提供更强的类型安全,对于不符合标准的类型转换会明确报错,以防止潜在的错误和不可预期的行为发生。C++更注重程序的安全性和正确性,不允许这种可能导致错误的隐式类型转换。如果把8和9行改为:
pb1 =(int *) b;
pb2 =(int*) b+1;在C或C++下都可编译通过。
参考文献:
[1]C语言基本概念——C与C++的不同之处
[2]李红卫,李秉璋. C程序设计与训练(第四版)[M],大连,大连理工大学出版社,2023.