目录
一、数组 / 字符串
1.交替合并字符串 (简单)
2.字符串的最大公因子 (简单)
3.拥有最多糖果的孩子(简单)
4.种花问题(简单)
5.反转字符串中的元音字母(简单)
6.反转字符串中的单词(中等)
7.除自身以外数组的乘积(中等)
8.递增的三元子序列(中等)
9.压缩字符串(中等)
二、双指针
10.移动零(简单)
11.判断子序列(简单)
12.盛最多水的容器 (中等)
13.K 和数对的最大数目(中等)
三、滑动窗口
14.子数组最大平均数 I(简单)
15.定长子串中元音的最大数目(中等)
16.最大连续1的个数 III(中等)
17.删掉一个元素以后全为 1 的最长子数组(中等)
四、前缀和
18.找到最高海拔(简单)
19.寻找数组的中心下标(简单)
五、哈希表 / 哈希集合
20.找出两数组的不同(简单)
21.独一无二的出现次数(简单)
22.确定两个字符串是否接近 (中等)
23.相等行列对(中等)
六、栈
24.从字符串中移除星号(中等)
25.小行星碰撞(中等)
26.字符串解码(中等)
七、队列
27.最近的请求次数(简单)
28.Dota2 参议院(中等)
八、连表
29.删除链表的中间节点(中等)
30.奇偶链表(中等)
31.反转链表(简单)
32.链表最大孪生和(中等)
九、二叉树 - 深度优先搜索
33.二叉树的最大深度(简单)
34.叶子相似的树(简单)
35.统计二叉树中好节点的数目(中等)
36.路径总和 III(中等)
37.二叉树中的最长交错路径(中等)
38.二叉树的最近公共祖先(中等)
十、二叉树 - 广度优先搜索
39.二叉树的右视图(中等)
40.最大层内元素和(中等)
十一、二叉搜索树
41.二叉搜索树中的搜索(简单)
42.删除二叉搜索树中的节点(中等)
十二、图 - 深度优先搜索
43.钥匙和房间(中等)
44.省份数量(中等)
45.重新规划路线(中等)
46.除法求值(中等)
十三、图 - 广度优先搜索
47.迷宫中离入口最近的出口(中等)
48.腐烂的橘子(中等)
十四、堆 / 优先队列
49.数组中的第K个最大元素(中等)
50.无限集中的最小数字(中等)
51.最大子序列的分数(中等)
52.雇佣 K 位工人的总代价(中等)
十五、二分查找
53.猜数字大小(简单)
54.咒语和药水的成功对数(中等)
55.寻找峰值(中等)
56.爱吃香蕉的珂珂(中等)
十六、回溯
57.电话号码的字母组合(中等)
58.组合总和 III(中等)
十七、动态规划 - 一维
59.第 N 个泰波那契数(简单)
60.使用最小花费爬楼梯(简单)
61.打家劫舍(中等)
62.多米诺和托米诺平铺 (中等)
十八、动态规划 - 多维
63.不同路径 (中等)
64.最长公共子序列 (中等)
65.买卖股票的最佳时机含手续费(中等)
66.编辑距离(中等)
十九、位运算
67.比特位计数(简单)
68.只出现一次的数字(简单)
69.或运算的最小翻转次数(中等)
二十、前缀树
70.实现 Trie (前缀树)(中等)
71.搜索推荐系统(中等)
二十一、区间集合
72.无重叠区间(中等)
73.用最少数量的箭引爆气球(中等)
二十二、单调栈
74.每日温度(中等)
75.股票价格跨度(中等)
干货分享,感谢您的阅读!

一、数组 / 字符串
1.交替合并字符串 (简单)
题目描述
给你两个字符串
word1和word2。请你从word1开始,通过交替添加字母来合并字符串。如果一个字符串比另一个字符串长,就将多出来的字母追加到合并后字符串的末尾。返回 合并后的字符串 。
示例 1:输入:word1 = "abc", word2 = "pqr" 输出:"apbqcr" 解释:字符串合并情况如下所示: word1: a b c word2: p q r 合并后: a p b q c r
示例 2:输入:word1 = "ab", word2 = "pqrs" 输出:"apbqrs" 解释:注意,word2 比 word1 长,"rs" 需要追加到合并后字符串的末尾。 word1: a b word2: p q r s 合并后: a p b q r s
示例 3:输入:word1 = "abcd", word2 = "pq" 输出:"apbqcd" 解释:注意,word1 比 word2 长,"cd" 需要追加到合并后字符串的末尾。 word1: a b c d word2: p q 合并后: a p b q c d
提示:
1 <= word1.length, word2.length <= 100word1和word2由小写英文字母组成
解题思路
要解决这个问题,可以使用双指针法遍历两个字符串,然后依次添加字符到结果字符串中。如果其中一个字符串遍历完了,直接将另一个字符串剩余的部分追加到结果字符串末尾。这样可以确保交替添加字符,并处理字符串长度不等的情况。
复杂度分析
- 时间复杂度:O(n),其中 n 是两个字符串中较长的长度。我们只需要遍历两个字符串一遍。
- 空间复杂度:O(1),除了输出结果字符串外,我们不需要额外的空间。
代码实现
package org.zyf.javabasic.letcode.featured75.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 交替合并字符串
* @author: zhangyanfeng
* @create: 2024-08-23 22:10
**/
public class MergeStrings {
public static String mergeAlternately(String word1, String word2) {
StringBuilder merged = new StringBuilder();
int i = 0, j = 0;
int n1 = word1.length(), n2 = word2.length();
// 交替添加字符
while (i < n1 && j < n2) {
merged.append(word1.charAt(i++));
merged.append(word2.charAt(j++));
}
// 将剩余部分追加到结果中
while (i < n1) {
merged.append(word1.charAt(i++));
}
while (j < n2) {
merged.append(word2.charAt(j++));
}
return merged.toString();
}
// 测试方法
public static void main(String[] args) {
System.out.println(mergeAlternately("abc", "pqr")); // 输出: "apbqcr"
System.out.println(mergeAlternately("ab", "pqrs")); // 输出: "apbqrs"
System.out.println(mergeAlternately("abcd", "pq")); // 输出: "apbqcd"
}
}
2.字符串的最大公因子 (简单)
题目描述
对于字符串
s和t,只有在s = t + t + t + ... + t + t(t自身连接 1 次或多次)时,我们才认定 “t能除尽s”。给定两个字符串
str1和str2。返回 最长字符串x,要求满足x能除尽str1且x能除尽str2。示例 1:输入:str1 = "ABCABC", str2 = "ABC" 输出:"ABC"
示例 2:输入:str1 = "ABABAB", str2 = "ABAB" 输出:"AB"
示例 3:输入:str1 = "LEET", str2 = "CODE" 输出:""
提示:
1 <= str1.length, str2.length <= 1000str1和str2由大写英文字母组成
解题思路
要找到两个字符串的最长公共除数,我们可以使用最大公因数(GCD)的思路来解决这个问题。思路解析:
- 字符串能被自身多次重复构成: 如果字符串
s可以通过字符串t重复若干次构成,那么t就是s的一个除数。 - 最大公因数 (GCD): 要找到两个字符串
str1和str2的最长公共除数,可以考虑先找出两个字符串长度的最大公因数,然后检查这个长度的子串是否能重复构成原始字符串。
复杂度分析
- 时间复杂度: O(n + m),其中 n 和 m 分别是两个字符串的长度。计算字符串的最大公因数长度需要 O(1) 时间,然后验证子串的重复性需要遍历两个字符串。
- 空间复杂度: O(1),我们只需要常数空间来存储中间变量。
代码实现
package org.zyf.javabasic.letcode.featured75.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 字符串的最大公因子
* @author: zhangyanfeng
* @create: 2024-08-23 22:18
**/
public class GreatestCommonDivisorOfStrings {
public static String gcdOfStrings(String str1, String str2) {
// 如果 str1 + str2 和 str2 + str1 不相等,则说明不存在公共除数
if (!(str1 + str2).equals(str2 + str1)) {
return "";
}
// 计算 str1 和 str2 长度的最大公因数
int gcdLength = gcd(str1.length(), str2.length());
// 返回最大公因数长度的子串
return str1.substring(0, gcdLength);
}
// 辅助方法:计算两个整数的最大公因数(GCD)
private static int gcd(int a, int b) {
return b == 0 ? a : gcd(b, a % b);
}
// 测试方法
public static void main(String[] args) {
System.out.println(gcdOfStrings("ABCABC", "ABC")); // 输出: "ABC"
System.out.println(gcdOfStrings("ABABAB", "ABAB")); // 输出: "AB"
System.out.println(gcdOfStrings("LEET", "CODE")); // 输出: ""
}
}
3.拥有最多糖果的孩子(简单)
题目描述
给你一个数组
candies和一个整数extraCandies,其中candies[i]代表第i个孩子拥有的糖果数目。对每一个孩子,检查是否存在一种方案,将额外的
extraCandies个糖果分配给孩子们之后,此孩子有 最多 的糖果。注意,允许有多个孩子同时拥有 最多 的糖果数目。示例 1:输入:candies = [2,3,5,1,3], extraCandies = 3 输出:[true,true,true,false,true] 解释: 孩子 1 有 2 个糖果,如果他得到所有额外的糖果(3个),那么他总共有 5 个糖果,他将成为拥有最多糖果的孩子。 孩子 2 有 3 个糖果,如果他得到至少 2 个额外糖果,那么他将成为拥有最多糖果的孩子。 孩子 3 有 5 个糖果,他已经是拥有最多糖果的孩子。 孩子 4 有 1 个糖果,即使他得到所有额外的糖果,他也只有 4 个糖果,无法成为拥有糖果最多的孩子。 孩子 5 有 3 个糖果,如果他得到至少 2 个额外糖果,那么他将成为拥有最多糖果的孩子。
示例 2:输入:candies = [4,2,1,1,2], extraCandies = 1 输出:[true,false,false,false,false] 解释:只有 1 个额外糖果,所以不管额外糖果给谁,只有孩子 1 可以成为拥有糖果最多的孩子。
示例 3:输入:candies = [12,1,12], extraCandies = 10 输出:[true,false,true]
提示:
2 <= candies.length <= 1001 <= candies[i] <= 1001 <= extraCandies <= 50
解题思路
要解决这个问题,我们需要找出当前数组 candies 中的最大值,然后对于每个孩子,判断他在获得 extraCandies 之后是否能拥有等于或超过这个最大值的糖果数。解题思路:
- 找到最大值: 先遍历数组
candies找到当前的最大值maxCandies。 - 逐个判断: 对于每个孩子,计算其当前糖果数与
extraCandies之和,如果这个和大于或等于maxCandies,那么该孩子可以成为拥有最多糖果的孩子,否则不能。 - 返回结果: 最终返回一个布尔值数组,表示每个孩子在加上额外糖果后是否能成为拥有最多糖果的孩子。
复杂度分析
- 时间复杂度: O(n),其中 n 是数组
candies的长度。我们需要遍历数组两次,一次找最大值,一次判断结果。 - 空间复杂度: O(n),因为我们需要存储一个长度为 n 的布尔数组。
代码实现
package org.zyf.javabasic.letcode.featured75.stringarray;
import java.util.ArrayList;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 拥有最多糖果的孩子
* @author: zhangyanfeng
* @create: 2024-08-23 22:26
**/
public class KidsWithCandies {
public static List<Boolean> kidsWithCandies(int[] candies, int extraCandies) {
int maxCandies = 0;
// 找到当前糖果数量的最大值
for (int candy : candies) {
if (candy > maxCandies) {
maxCandies = candy;
}
}
List<Boolean> result = new ArrayList<>();
// 判断每个孩子在得到额外糖果后是否能拥有最多的糖果
for (int candy : candies) {
result.add(candy + extraCandies >= maxCandies);
}
return result;
}
// 测试方法
public static void main(String[] args) {
int[] candies1 = {2, 3, 5, 1, 3};
int extraCandies1 = 3;
System.out.println(kidsWithCandies(candies1, extraCandies1)); // 输出: [true, true, true, false, true]
int[] candies2 = {4, 2, 1, 1, 2};
int extraCandies2 = 1;
System.out.println(kidsWithCandies(candies2, extraCandies2)); // 输出: [true, false, false, false, false]
int[] candies3 = {12, 1, 12};
int extraCandies3 = 10;
System.out.println(kidsWithCandies(candies3, extraCandies3)); // 输出: [true, false, true]
}
}
4.种花问题(简单)
题目描述
假设有一个很长的花坛,一部分地块种植了花,另一部分却没有。可是,花不能种植在相邻的地块上,它们会争夺水源,两者都会死去。
给你一个整数数组
flowerbed表示花坛,由若干0和1组成,其中0表示没种植花,1表示种植了花。另有一个数n,能否在不打破种植规则的情况下种入n朵花?能则返回true,不能则返回false。示例 1:输入:flowerbed = [1,0,0,0,1], n = 1 输出:true
示例 2:输入:flowerbed = [1,0,0,0,1], n = 2 输出:false
提示:
1 <= flowerbed.length <= 2 * 104flowerbed[i]为0或1flowerbed中不存在相邻的两朵花0 <= n <= flowerbed.length
解题思路
要判断是否可以在给定的花坛 flowerbed 中种下 n 朵花,同时保持相邻的地块上不能种植花的规则,可以使用贪心算法逐一检查每个地块,尽量在可以种花的地块上种植花,并减少需要种植的花的数量。解题思路:
- 遍历花坛: 逐个检查花坛中的每个地块,找到可以种花的地块。一个地块能种花的条件是它自身和相邻的两个地块都没有种花(即
flowerbed[i-1] == 0 && flowerbed[i] == 0 && flowerbed[i+1] == 0),边界情况只需检查一侧。 - 种植花朵: 每找到一个可以种花的地块,我们将该地块的值设置为
1,同时将n减 1。 - 提前退出: 如果在遍历过程中,
n减为0,则提前返回true。 - 结束条件: 遍历结束后,如果
n > 0,则返回false,否则返回true。
复杂度分析
- 时间复杂度: O(m),其中
m是数组flowerbed的长度。我们只需要遍历一次数组。 - 空间复杂度: O(1),除了几个变量外,没有使用额外的空间。
代码实现
package org.zyf.javabasic.letcode.featured75.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 种花问题
* @author: zhangyanfeng
* @create: 2024-08-23 22:33
**/
public class CanPlaceFlowers {
public static boolean canPlaceFlowers(int[] flowerbed, int n) {
int length = flowerbed.length;
for (int i = 0; i < length && n > 0; i++) {
// 如果当前位置是0,并且前后(考虑边界)也是0,说明可以种花
if (flowerbed[i] == 0) {
// 检查左边(i == 0 时,左边没有地块)
boolean leftEmpty = (i == 0) || (flowerbed[i - 1] == 0);
// 检查右边(i == length - 1 时,右边没有地块)
boolean rightEmpty = (i == length - 1) || (flowerbed[i + 1] == 0);
if (leftEmpty && rightEmpty) {
// 种花
flowerbed[i] = 1;
n--;
}
}
}
return n <= 0;
}
// 测试方法
public static void main(String[] args) {
int[] flowerbed1 = {1, 0, 0, 0, 1};
int n1 = 1;
System.out.println(canPlaceFlowers(flowerbed1, n1)); // 输出: true
int[] flowerbed2 = {1, 0, 0, 0, 1};
int n2 = 2;
System.out.println(canPlaceFlowers(flowerbed2, n2)); // 输出: false
}
}
5.反转字符串中的元音字母(简单)
题目描述
给你一个字符串
s,仅反转字符串中的所有元音字母,并返回结果字符串。元音字母包括
'a'、'e'、'i'、'o'、'u',且可能以大小写两种形式出现不止一次。示例 1:输入:s = "hello" 输出:"holle"
示例 2:输入:s = "leetcode" 输出:"leotcede"
提示:
1 <= s.length <= 3 * 105s由 可打印的 ASCII 字符组成
解题思路
要反转字符串中的所有元音字母,可以使用双指针的方法,分别从字符串的左右两端向中间遍历,将左右指针指向的元音字母互换,直到两个指针相遇。解题思路:
- 双指针初始化: 使用两个指针
left和right,分别从字符串的头部和尾部开始遍历。 - 跳过非元音字母: 当
left指向的字符不是元音字母时,left右移;当right指向的字符不是元音字母时,right左移。 - 交换元音字母: 当两个指针都指向元音字母时,交换它们,然后移动两个指针(
left右移,right左移)。 - 继续直到指针相遇: 重复上述步骤,直到
left指针超过或等于right指针为止。
复杂度分析
- 时间复杂度: O(n),其中 n 是字符串
s的长度。我们最多只需要遍历字符串一次,因此时间复杂度是线性的。 - 空间复杂度: O(n),由于字符串在 Java 中是不可变的,我们需要使用额外的空间来存储修改后的字符串。
代码实现
package org.zyf.javabasic.letcode.featured75.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 反转字符串中的元音字母
* @author: zhangyanfeng
* @create: 2024-08-23 22:48
**/
public class ReverseVowels {
public static String reverseVowels(String s) {
// 将字符串转换为字符数组
char[] chars = s.toCharArray();
// 定义元音字母集
String vowels = "aeiouAEIOU";
int left = 0;
int right = chars.length - 1;
while (left < right) {
// 如果左指针指向的不是元音,向右移动
while (left < right && vowels.indexOf(chars[left]) == -1) {
left++;
}
// 如果右指针指向的不是元音,向左移动
while (left < right && vowels.indexOf(chars[right]) == -1) {
right--;
}
// 交换左指针和右指针的元音字母
if (left < right) {
char temp = chars[left];
chars[left] = chars[right];
chars[right] = temp;
// 移动指针
left++;
right--;
}
}
// 将字符数组转换为字符串并返回
return new String(chars);
}
// 测试方法
public static void main(String[] args) {
System.out.println(reverseVowels("hello")); // 输出: "holle"
System.out.println(reverseVowels("leetcode")); // 输出: "leotcede"
}
}
6.反转字符串中的单词(中等)
题目描述
给你一个字符串
s,请你反转字符串中 单词 的顺序。单词 是由非空格字符组成的字符串。
s中使用至少一个空格将字符串中的 单词 分隔开。返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
注意:输入字符串
s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。示例 1:输入:s = "
the sky is blue" 输出:"blue is sky the"示例 2:输入:s = " hello world " 输出:"world hello" 解释:反转后的字符串中不能存在前导空格和尾随空格。
示例 3:输入:s = "a good example" 输出:"example good a" 解释:如果两个单词间有多余的空格,反转后的字符串需要将单词间的空格减少到仅有一个。
提示:
1 <= s.length <= 104s包含英文大小写字母、数字和空格' 's中 至少存在一个 单词进阶:如果字符串在你使用的编程语言中是一种可变数据类型,请尝试使用
O(1)额外空间复杂度的 原地 解法。
解题思路
要反转字符串 s 中单词的顺序,并处理前导、尾随和多余空格的问题,可以按照以下步骤来实现:
- 移除多余空格: 首先去除字符串
s中的前导空格、尾随空格,并将单词之间的多个空格缩减为一个。 - 分割单词: 将处理后的字符串按空格分割成一个个单词。
- 反转单词顺序: 将这些单词按顺序反转。
- 重新拼接单词: 将反转后的单词用单个空格拼接成一个新的字符串。
- 返回结果: 返回拼接后的结果字符串。
复杂度分析
- 时间复杂度: O(n),其中 n 是字符串
s的长度。去除空格、分割单词、反转顺序和拼接结果的过程都可以在 O(n) 时间内完成。 - 空间复杂度: O(n),我们使用了额外的空间来存储分割后的单词列表和最终结果字符串。
代码实现
package org.zyf.javabasic.letcode.featured75.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 反转字符串中的单词
* @author: zhangyanfeng
* @create: 2024-08-23 22:52
**/
public class ReverseWords {
public static String reverseWords(String s) {
// 去除首尾的空格,并将中间多个空格缩减为一个空格
s = s.trim().replaceAll("\\s+", " ");
// 将字符串按空格分割成单词数组
String[] words = s.split(" ");
// 反转单词数组
int left = 0, right = words.length - 1;
while (left < right) {
String temp = words[left];
words[left] = words[right];
words[right] = temp;
left++;
right--;
}
// 将反转后的单词数组拼接成一个字符串
return String.join(" ", words);
}
// 测试方法
public static void main(String[] args) {
System.out.println(reverseWords("the sky is blue")); // 输出: "blue is sky the"
System.out.println(reverseWords(" hello world ")); // 输出: "world hello"
System.out.println(reverseWords("a good example")); // 输出: "example good a"
}
}
7.除自身以外数组的乘积(中等)
题目描述
给你一个整数数组
nums,返回 数组answer,其中answer[i]等于nums中除nums[i]之外其余各元素的乘积 。题目数据 保证 数组
nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。请 不要使用除法,且在
O(n)时间复杂度内完成此题。示例 1:输入: nums =
[1,2,3,4]输出:[24,12,8,6]示例 2:输入: nums = [-1,1,0,-3,3] 输出: [0,0,9,0,0]
提示:
2 <= nums.length <= 105-30 <= nums[i] <= 30- 保证 数组
nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内进阶:你可以在
O(1)的额外空间复杂度内完成这个题目吗?( 出于对空间复杂度分析的目的,输出数组 不被视为 额外空间。)
解题思路
我们需要返回一个数组 answer,其中 answer[i] 是 nums 数组中除 nums[i] 之外其余各元素的乘积,并且要求在 O(n) 时间复杂度内完成,且不能使用除法。
要解决这个问题,可以将其分为两步:
- 计算前缀乘积: 创建一个数组
leftProducts,其中leftProducts[i]表示从nums[0]到nums[i-1]的乘积。 - 计算后缀乘积: 创建另一个数组
rightProducts,其中rightProducts[i]表示从nums[i+1]到nums[n-1]的乘积。 - 组合结果: 对于每个元素
i,answer[i]等于leftProducts[i]和rightProducts[i]的乘积。
优化空间复杂度的进阶做法是直接在 answer 数组中完成前缀乘积的计算,然后再反向计算后缀乘积,直接与 answer 中存储的前缀乘积相乘,从而节省空间。
复杂度分析
- 时间复杂度: O(n),我们需要遍历两次数组,分别计算前缀乘积和后缀乘积。
- 空间复杂度: O(1)(不包括输出数组
answer的空间),使用answer数组作为存储前缀乘积的数组,避免额外的空间开销。
代码实现
package org.zyf.javabasic.letcode.featured75.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 除自身以外数组的乘积
* @author: zhangyanfeng
* @create: 2024-08-23 22:56
**/
public class ProductExceptSelf {
public static int[] productExceptSelf(int[] nums) {
int n = nums.length;
int[] answer = new int[n];
// 第一次遍历:计算前缀乘积
answer[0] = 1;
for (int i = 1; i < n; i++) {
answer[i] = answer[i - 1] * nums[i - 1];
}
// 第二次遍历:计算后缀乘积并与前缀乘积相乘
int rightProduct = 1;
for (int i = n - 1; i >= 0; i--) {
answer[i] = answer[i] * rightProduct;
rightProduct *= nums[i];
}
return answer;
}
// 测试方法
public static void main(String[] args) {
int[] nums1 = {1, 2, 3, 4};
int[] result1 = productExceptSelf(nums1);
for (int num : result1) {
System.out.print(num + " ");
}
// 输出: [24, 12, 8, 6]
System.out.println();
int[] nums2 = {-1, 1, 0, -3, 3};
int[] result2 = productExceptSelf(nums2);
for (int num : result2) {
System.out.print(num + " ");
}
// 输出: [0, 0, 9, 0, 0]
}
}
8.递增的三元子序列(中等)
题目描述
给你一个整数数组
nums,判断这个数组中是否存在长度为3的递增子序列。如果存在这样的三元组下标
(i, j, k)且满足i < j < k,使得nums[i] < nums[j] < nums[k],返回true;否则,返回false。示例 1:输入:nums = [1,2,3,4,5] 输出:true 解释:任何 i < j < k 的三元组都满足题意
示例 2:输入:nums = [5,4,3,2,1] 输出:false 解释:不存在满足题意的三元组
示例 3:输入:nums = [2,1,5,0,4,6] 输出:true 解释:三元组 (3, 4, 5) 满足题意,因为 nums[3] == 0 < nums[4] == 4 < nums[5] == 6
提示:
1 <= nums.length <= 5 * 105-231 <= nums[i] <= 231 - 1
解题思路
我们需要在数组 nums 中找到一个递增的三元组 (i, j, k),使得 i < j < k 且 nums[i] < nums[j] < nums[k]。该问题要求在 O(n) 时间复杂度内解决。
为了解决这个问题,可以维护两个变量 first 和 second,分别表示当前找到的最小元素和第二小的元素。然后遍历数组,更新这两个变量:
- 如果当前元素小于或等于
first,更新first。 - 如果当前元素大于
first且小于或等于second,更新second。 - 如果当前元素大于
second,说明我们找到了一个递增的三元组,直接返回true。
复杂度分析
- 时间复杂度: O(n),我们只需要遍历数组一次。
- 空间复杂度: O(1),只用了常数空间来存储两个变量。
代码实现
package org.zyf.javabasic.letcode.featured75.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 递增的三元子序列
* @author: zhangyanfeng
* @create: 2024-08-23 23:00
**/
public class IncreasingTripletSubsequence {
public static boolean increasingTriplet(int[] nums) {
// 初始化两个变量,first 表示最小值,second 表示第二小值
int first = Integer.MAX_VALUE, second = Integer.MAX_VALUE;
// 遍历数组
for (int num : nums) {
if (num <= first) {
// 如果当前元素比 first 小或相等,更新 first
first = num;
} else if (num <= second) {
// 如果当前元素比 second 小或相等,更新 second
second = num;
} else {
// 如果当前元素大于 second,则找到递增三元组,返回 true
return true;
}
}
// 如果遍历完数组没有找到符合条件的三元组,返回 false
return false;
}
// 测试方法
public static void main(String[] args) {
int[] nums1 = {1, 2, 3, 4, 5};
System.out.println(increasingTriplet(nums1)); // 输出: true
int[] nums2 = {5, 4, 3, 2, 1};
System.out.println(increasingTriplet(nums2)); // 输出: false
int[] nums3 = {2, 1, 5, 0, 4, 6};
System.out.println(increasingTriplet(nums3)); // 输出: true
}
}
9.压缩字符串(中等)
题目描述
给你一个字符数组
chars,请使用下述算法压缩:从一个空字符串
s开始。对于chars中的每组 连续重复字符 :
- 如果这一组长度为
1,则将字符追加到s中。- 否则,需要向
s追加字符,后跟这一组的长度。压缩后得到的字符串
s不应该直接返回 ,需要转储到字符数组chars中。需要注意的是,如果组长度为10或10以上,则在chars数组中会被拆分为多个字符。请在 修改完输入数组后 ,返回该数组的新长度。
你必须设计并实现一个只使用常量额外空间的算法来解决此问题。
示例 1:输入:chars = ["a","a","b","b","c","c","c"] 输出:返回 6 ,输入数组的前 6 个字符应该是:["a","2","b","2","c","3"] 解释:"aa" 被 "a2" 替代。"bb" 被 "b2" 替代。"ccc" 被 "c3" 替代。
示例 2:输入:chars = ["a"] 输出:返回 1 ,输入数组的前 1 个字符应该是:["a"] 解释:唯一的组是“a”,它保持未压缩,因为它是一个字符。
示例 3:输入:chars = ["a","b","b","b","b","b","b","b","b","b","b","b","b"] 输出:返回 4 ,输入数组的前 4 个字符应该是:["a","b","1","2"]。 解释:由于字符 "a" 不重复,所以不会被压缩。"bbbbbbbbbbbb" 被 “b12” 替代。
提示:
1 <= chars.length <= 2000chars[i]可以是小写英文字母、大写英文字母、数字或符号
解题思路
这个问题的核心在于如何原地压缩字符数组。我们可以通过双指针来实现压缩:
- 指针
i: 用于遍历字符数组chars。 - 指针
write: 用于记录压缩后字符数组的写入位置。
步骤:
- 遍历字符数组,用
i指针找到每一组连续相同的字符。 - 对于每组连续字符:将该字符写入到
chars[write]位置,write指针向前移动;如果该组字符的长度大于 1,需要将长度转换为字符串并逐个写入到chars数组中。 - 当遍历完所有字符后,
write指针的位置即为新数组的长度。
复杂度分析
- 时间复杂度: O(n),因为我们遍历了字符数组一次。
- 空间复杂度: O(1),使用了常量空间,只在原数组上操作。
代码实现
package org.zyf.javabasic.letcode.featured75.stringarray;
/**
* @program: zyfboot-javabasic
* @description: 压缩字符串
* @author: zhangyanfeng
* @create: 2024-08-23 23:04
**/
public class StringCompression {
public static int compress(char[] chars) {
// write 指针用于记录写入位置
int write = 0;
int i = 0;
while (i < chars.length) {
char currentChar = chars[i];
int count = 0;
// 计算连续字符的数量
while (i < chars.length && chars[i] == currentChar) {
i++;
count++;
}
// 写入当前字符到压缩后的位置
chars[write++] = currentChar;
// 如果字符数量大于1,写入数量
if (count > 1) {
for (char c : String.valueOf(count).toCharArray()) {
chars[write++] = c;
}
}
}
// 返回新的长度
return write;
}
// 测试方法
public static void main(String[] args) {
char[] chars1 = {'a', 'a', 'b', 'b', 'c', 'c', 'c'};
System.out.println(compress(chars1)); // 输出: 6
char[] chars2 = {'a'};
System.out.println(compress(chars2)); // 输出: 1
char[] chars3 = {'a', 'b', 'b', 'b', 'b', 'b', 'b', 'b', 'b', 'b', 'b', 'b', 'b'};
System.out.println(compress(chars3)); // 输出: 4
}
}
二、双指针
10.移动零(简单)
题目描述
给定一个数组
nums,编写一个函数将所有0移动到数组的末尾,同时保持非零元素的相对顺序。请注意 ,必须在不复制数组的情况下原地对数组进行操作。
示例 1:输入: nums =
[0,1,0,3,12]输出:[1,3,12,0,0]示例 2:输入: nums =
[0]输出:[0]提示:
1 <= nums.length <=-<= nums[i] <=- 1进阶:你能尽量减少完成的操作次数吗?
解题思路
为了在不复制数组的情况下原地移动所有 0 到数组末尾,同时保持非零元素的相对顺序,我们可以使用双指针技术来实现。具体步骤如下:
- 使用双指针:我们使用两个指针,
i和j。其中,i用于遍历整个数组,j用于记录下一个非零元素应该放置的位置。 - 遍历数组:遍历数组,当遇到非零元素时,将其移动到
j指针的位置,然后将j向前移动一位。 - 填充零:当所有非零元素都按顺序放置好之后,
j之后的位置都应该填充为0,直到数组结束。
复杂度分析
-
时间复杂度:O(n)。数组中的每个元素最多被遍历两次(一次在第一次遍历时移动非零元素,另一次在填充零时),因此时间复杂度为 O(n)。
-
空间复杂度:O(1)。只使用了常数级别的额外空间,即指针
j,因此空间复杂度为 O(1)。
代码实现
package org.zyf.javabasic.letcode.hot100.twopoint;
import java.util.Arrays;
/**
* @program: zyfboot-javabasic
* @description: 移动零
* @author: zhangyanfeng
* @create: 2024-08-21 20:44
**/
public class MoveZeroesSolution {
public void moveZeroes(int[] nums) {
int j = 0; // j指针用于记录下一个非零元素的位置
// 遍历数组,将所有非零元素按顺序移动到前面
for (int i = 0; i < nums.length; i++) {
if (nums[i] != 0) {
nums[j] = nums[i];
j++;
}
}
// 将剩下的位置全部填充为0
for (int i = j; i < nums.length; i++) {
nums[i] = 0;
}
}
public static void main(String[] args) {
MoveZeroesSolution solution = new MoveZeroesSolution();
int[] nums1 = {0, 1, 0, 3, 12};
solution.moveZeroes(nums1);
System.out.println(Arrays.toString(nums1)); // 输出: [1, 3, 12, 0, 0]
int[] nums2 = {0};
solution.moveZeroes(nums2);
System.out.println(Arrays.toString(nums2)); // 输出: [0]
}
}
11.判断子序列(简单)
题目描述
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,
"ace"是"abcde"的一个子序列,而"aec"不是)。进阶:
如果有大量输入的 S,称作 S1, S2, ... , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
示例 1:输入:s = "abc", t = "ahbgdc" 输出:true
示例 2:输入:s = "axc", t = "ahbgdc" 输出:false
提示:
0 <= s.length <= 1000 <= t.length <= 10^4- 两个字符串都只由小写字符组成。
解题思路
使用 动态规划 的方法来解决 s 是否是 t 的子序列的问题。主要思想是预处理字符串 t 的每个字符的后续位置,以便在查找子序列时能高效定位字符的位置。
步骤:
-
预处理:构建一个二维数组
f,f[i][j]表示在t的位置i之后,字符j的下一个出现位置。这样可以在 O(1) 的时间复杂度下查询任何字符在t中的位置。 -
填充
初始化:f数组:f[m][i]为m,表示在t的末尾之后,所有字符的下一个位置都是m;从后向前填充:遍历t,更新每个位置i对应的字符j的下一个位置。 -
查找子序列:
遍历字符串s,使用f数组来查找每个字符s[i]在t中的下一个位置。如果找不到,返回false;更新当前位置add为字符s[i]的下一个出现位置,加 1。
复杂度分析
- 预处理:构建
f数组的时间复杂度为 O(m * 26),其中 m 是t的长度,26 是字符集大小。 - 查找子序列:时间复杂度为 O(n),其中 n 是
s的长度。
整体时间复杂度为 O(m * 26 + n),空间复杂度为 O(m * 26),主要用于存储 f 数组。
代码实现
package org.zyf.javabasic.letcode.featured75.twopoint;
/**
* @program: zyfboot-javabasic
* @description: 判断子序列
* @author: zhangyanfeng
* @create: 2024-08-23 23:16
**/
public class Subsequence {
public boolean isSubsequence(String s, String t) {
int n = s.length(); // s 的长度
int m = t.length(); // t 的长度
// 预处理:f[i][j] 表示在 t 的位置 i 之后,字符 j 的下一个出现位置
int[][] f = new int[m + 1][26];
// 初始化:t 的末尾之后所有字符的下一个位置都是 m
for (int i = 0; i < 26; i++) {
f[m][i] = m;
}
// 从后向前填充 f 数组
for (int i = m - 1; i >= 0; i--) {
for (int j = 0; j < 26; j++) {
if (t.charAt(i) == j + 'a') {
// 如果当前字符是 j,则下一个位置是当前位置 i
f[i][j] = i;
} else {
// 否则,下一个位置继承自 f[i + 1][j]
f[i][j] = f[i + 1][j];
}
}
}
int add = 0; // 当前在 t 中的位置
for (int i = 0; i < n; i++) {
// 查找 s[i] 在 t 中的下一个出现位置
if (f[add][s.charAt(i) - 'a'] == m) {
// 如果找不到,返回 false
return false;
}
// 更新 add 为 s[i] 的下一个出现位置 + 1
add = f[add][s.charAt(i) - 'a'] + 1;
}
return true; // 如果能遍历完 s,返回 true
}
// 测试方法
public static void main(String[] args) {
Subsequence subsequence = new Subsequence();
// 基本解法测试
System.out.println(subsequence.isSubsequence("abc", "ahbgdc")); // 输出: true
System.out.println(subsequence.isSubsequence("axc", "ahbgdc")); // 输出: false
}
}
12.盛最多水的容器 (中等)
题目描述
给定一个长度为
n的整数数组height。有n条垂线,第i条线的两个端点是(i, 0)和(i, height[i])。找出其中的两条线,使得它们与
x轴共同构成的容器可以容纳最多的水。返回容器可以储存的最大水量。
说明:你不能倾斜容器。
示例 1:
输入:[1,8,6,2,5,4,8,3,7] 输出:49 解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。示例 2:输入:height = [1,1] 输出:1
提示:
n == height.length2 <= n <=0 <= height[i] <=
解题思路
这个问题可以通过使用双指针的方式来解决。因为我们想要找到两个垂线,使得它们能形成的容器容纳最多的水,所以可以通过以下步骤实现:
- 初始化双指针:一个指针
left指向数组的起始位置,另一个指针right指向数组的末尾位置。 - 计算容积:在每一步中,计算由
left和right指针指向的垂线所形成的容器的容积,公式为min(height[left], height[right]) * (right - left)。 - 移动指针:为了找到更大的容积,比较
height[left]和height[right],将较小的那个指针向中间移动一位(如果左侧较小,则左指针右移,否则右指针左移)。 - 更新最大值:在每次计算中,记录最大容积的值。
- 终止条件:当两个指针相遇时,遍历结束,最大容积即为结果。
复杂度分析
-
时间复杂度:O(n)。在双指针法中,每一步只移动一个指针,一共需要遍历整个数组一次,因此时间复杂度为 O(n)。
-
空间复杂度:O(1)。只使用了固定的额外空间来存储指针和最大面积,因此空间复杂度为 O(1)。
代码实现
package org.zyf.javabasic.letcode.hot100.twopoint;
/**
* @program: zyfboot-javabasic
* @description: 盛最多水的容器
* @author: zhangyanfeng
* @create: 2024-08-21 20:54
**/
public class MaxAreaSolution {
public int maxArea(int[] height) {
int left = 0, right = height.length - 1;
int maxArea = 0;
// 使用双指针法计算最大面积
while (left < right) {
// 计算当前指针指向的垂线形成的容器的面积
int currentArea = Math.min(height[left], height[right]) * (right - left);
// 更新最大面积
maxArea = Math.max(maxArea, currentArea);
// 移动较小的一端的指针
if (height[left] < height[right]) {
left++;
} else {
right--;
}
}
return maxArea;
}
public static void main(String[] args) {
MaxAreaSolution solution = new MaxAreaSolution();
int[] height1 = {1,8,6,2,5,4,8,3,7};
System.out.println(solution.maxArea(height1)); // 输出: 49
int[] height2 = {1,1};
System.out.println(solution.maxArea(height2)); // 输出: 1
}
}
13.K 和数对的最大数目(中等)
题目描述
给你一个整数数组
nums和一个整数k。每一步操作中,你需要从数组中选出和为
k的两个整数,并将它们移出数组。返回你可以对数组执行的最大操作数。
示例 1:输入:nums = [1,2,3,4], k = 5 输出:2 解释:开始时 nums = [1,2,3,4]: - 移出 1 和 4 ,之后 nums = [2,3] - 移出 2 和 3 ,之后 nums = [] 不再有和为 5 的数对,因此最多执行 2 次操作。
示例 2:输入:nums = [3,1,3,4,3], k = 6 输出:1 解释:开始时 nums = [3,1,3,4,3]: - 移出前两个 3 ,之后nums = [1,4,3] 不再有和为 6 的数对,因此最多执行 1 次操作。
提示:
1 <= nums.length <= 1051 <= nums[i] <= 1091 <= k <= 109
解题思路
经典的两指针算法问题,目的是在一个排序好的数组中找到和为指定值 kkk 的最大对数。
-
排序数组:首先将数组排序。这是因为有序数组允许我们使用两指针技术来高效地找到目标和。
-
初始化两个指针:
i指向数组的起始位置(最小值);j指向数组的结束位置(最大值)。 -
使用两指针技术:
- 计算
nums[i]和nums[j]的和。 - 如果和等于 kkk,这意味着找到了一个有效的对,增加结果计数,并且移动两个指针(即
i++和j--)。 - 如果和小于 kkk,则需要增加较小的数,移动左指针
i++。 - 如果和大于 kkk,则需要减小较大的数,移动右指针
j--。
- 计算
-
重复直到两个指针相遇:循环继续直到
i不再小于j,即两个指针相遇。
复杂度分析
-
时间复杂度:
- 排序时间复杂度为 O(nlogn)O(n \log n)O(nlogn)。
- 两指针遍历时间复杂度为 O(n)O(n)O(n)。
- 总的时间复杂度为 O(nlogn)O(n \log n)O(nlogn)。
-
空间复杂度:
- 排序操作是原地排序,空间复杂度为 O(1)O(1)O(1)。
- 总的空间复杂度为 O(1)O(1)O(1),除了输入数组以外没有额外的空间使用。
代码实现
package org.zyf.javabasic.letcode.featured75.twopoint;
import java.util.Arrays;
/**
* @program: zyfboot-javabasic
* @description: K 和数对的最大数目
* @author: zhangyanfeng
* @create: 2024-08-23 23:26
**/
public class MaxOperations {
public int maxOperations(int[] nums, int k) {
int result = 0; // 用于记录最大操作数
// 排序数组
Arrays.sort(nums);
// 初始化两个指针
int i = 0; // 左指针
int j = nums.length - 1; // 右指针
// 使用两指针法
while (i < j) {
int sum = nums[i] + nums[j]; // 计算当前两个指针指向的元素和
if (sum == k) { // 如果和等于目标值k
result++; // 增加操作计数
i++; // 移动左指针
j--; // 移动右指针
} else if (sum < k) { // 如果和小于目标值k
i++; // 移动左指针以增大和
} else { // 如果和大于目标值k
j--; // 移动右指针以减小和
}
}
return result; // 返回最大操作数
}
public static void main(String[] args) {
MaxOperations solution = new MaxOperations();
// 测试用例 1
int[] nums1 = {1, 2, 3, 4};
int k1 = 5;
System.out.println("Test Case 1: " + (solution.maxOperations(nums1, k1) == 2 ? "Passed" : "Failed"));
// 测试用例 2
int[] nums2 = {3, 1, 3, 4, 3};
int k2 = 6;
System.out.println("Test Case 2: " + (solution.maxOperations(nums2, k2) == 1 ? "Passed" : "Failed"));
// 测试用例 3
int[] nums3 = {1, 1, 1, 1};
int k3 = 2;
System.out.println("Test Case 3: " + (solution.maxOperations(nums3, k3) == 2 ? "Passed" : "Failed"));
// 测试用例 4
int[] nums4 = {1, 2, 3, 4, 5, 6};
int k4 = 7;
System.out.println("Test Case 4: " + (solution.maxOperations(nums4, k4) == 3 ? "Passed" : "Failed"));
// 测试用例 5
int[] nums5 = {2, 2, 2, 2, 2, 2};
int k5 = 4;
System.out.println("Test Case 5: " + (solution.maxOperations(nums5, k5) == 3 ? "Passed" : "Failed"));
// 边界测试用例
int[] nums6 = {1, 2, 3, 4, 5, 6};
int k6 = 10;
System.out.println("Test Case 6: " + (solution.maxOperations(nums6, k6) == 0 ? "Passed" : "Failed"));
}
}
三、滑动窗口
14.子数组最大平均数 I(简单)
题目描述
给你一个由
n个元素组成的整数数组nums和一个整数k。请你找出平均数最大且 长度为
k的连续子数组,并输出该最大平均数。任何误差小于
10-5的答案都将被视为正确答案。示例 1:输入:nums = [1,12,-5,-6,50,3], k = 4 输出:12.75 解释:最大平均数 (12-5-6+50)/4 = 51/4 = 12.75
示例 2:输入:nums = [5], k = 1 输出:5.00000
提示:
n == nums.length1 <= k <= n <= 105-104 <= nums[i] <= 104
解题思路
要找到长度为 k 的连续子数组的最大平均数,可以使用滑动窗口技术:
-
初始化窗口:首先计算数组
nums中前k个元素的和,作为初始窗口和;设置当前最大平均数为这个窗口的平均数。 -
滑动窗口:
- 从第
k个元素开始,滑动窗口一次移动一个元素。 - 在每次滑动时,将窗口中的第一个元素移出,同时将下一个元素添加到窗口中。
- 更新窗口和,并计算新的窗口平均数。
- 更新最大平均数。
- 从第
-
返回结果:返回最大平均数。
复杂度分析
- 时间复杂度:
O(n),因为每个元素只被访问一次。 - 空间复杂度:
O(1),只使用了常量级别的额外空间。
代码实现
package org.zyf.javabasic.letcode.featured75.slidingwindow;
/**
* @program: zyfboot-javabasic
* @description: 子数组最大平均数 I
* @author: zhangyanfeng
* @create: 2024-08-23 23:34
**/
public class MaxAverage {
public double findMaxAverage(int[] nums, int k) {
// 计算初始窗口的和
double windowSum = 0;
for (int i = 0; i < k; i++) {
windowSum += nums[i];
}
// 初始化最大平均数为初始窗口的平均数
double maxAverage = windowSum / k;
// 滑动窗口,计算每个窗口的和并更新最大平均数
for (int i = k; i < nums.length; i++) {
windowSum += nums[i] - nums[i - k]; // 滑动窗口的更新
double currentAverage = windowSum / k; // 当前窗口的平均数
maxAverage = Math.max(maxAverage, currentAverage); // 更新最大平均数
}
return maxAverage;
}
public static void main(String[] args) {
MaxAverage solution = new MaxAverage();
// 测试用例 1
int[] nums1 = {1, 12, -5, -6, 50, 3};
int k1 = 4;
System.out.println("Test Case 1: " + (Math.abs(solution.findMaxAverage(nums1, k1) - 12.75) < 1e-5 ? "Passed" : "Failed"));
// 测试用例 2
int[] nums2 = {5};
int k2 = 1;
System.out.println("Test Case 2: " + (Math.abs(solution.findMaxAverage(nums2, k2) - 5.0) < 1e-5 ? "Passed" : "Failed"));
// 测试用例 3
int[] nums3 = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int k3 = 3;
System.out.println("Test Case 3: " + (Math.abs(solution.findMaxAverage(nums3, k3) - 8.0) < 1e-5 ? "Passed" : "Failed"));
// 测试用例 4
int[] nums4 = {1, 1, 1, 1, 1, 1, 1, 1, 1};
int k4 = 5;
System.out.println("Test Case 4: " + (Math.abs(solution.findMaxAverage(nums4, k4) - 1.0) < 1e-5 ? "Passed" : "Failed"));
// 测试用例 5
int[] nums5 = {-1, -2, -3, -4, -5, -6, -7, -8, -9, -10};
int k5 = 4;
System.out.println("Test Case 5: " + (Math.abs(solution.findMaxAverage(nums5, k5) - (-5.5)) < 1e-5 ? "Passed" : "Failed"));
}
}
15.定长子串中元音的最大数目(中等)
题目描述
给你字符串
s和整数k。请返回字符串
s中长度为k的单个子字符串中可能包含的最大元音字母数。英文中的 元音字母 为(
a,e,i,o,u)。示例 1:输入:s = "abciiidef", k = 3 输出:3 解释:子字符串 "iii" 包含 3 个元音字母。
示例 2:输入:s = "aeiou", k = 2 输出:2 解释:任意长度为 2 的子字符串都包含 2 个元音字母。
示例 3:输入:s = "leetcode", k = 3 输出:2 解释:"lee"、"eet" 和 "ode" 都包含 2 个元音字母。
示例 4:输入:s = "rhythms", k = 4 输出:0 解释:字符串 s 中不含任何元音字母。
示例 5:输入:s = "tryhard", k = 4 输出:1
提示:
1 <= s.length <= 10^5s由小写英文字母组成1 <= k <= s.length
解题思路
为了找到字符串 s 中长度为 k 的子字符串中可能包含的最大元音字母数,我们可以使用滑动窗口技术来优化性能:
-
初始化窗口:首先计算字符串
s中前k个字符的元音字母数量;记录这个数量为当前的最大元音数。 -
滑动窗口:
- 从第
k个字符开始,滑动窗口一次移动一个字符。 - 在每次滑动时,将窗口中新增的字符和移出的字符分别检查是否为元音字母。
- 更新当前窗口的元音字母数量,并与记录的最大元音数进行比较,更新最大值。
- 从第
-
返回结果:返回在所有窗口中计算得到的最大元音字母数量。
复杂度分析
- 时间复杂度:
O(n),因为每个字符被访问和检查的次数都是常量级的。 - 空间复杂度:
O(1),只使用了常量级别的额外空间。
代码实现
package org.zyf.javabasic.letcode.featured75.slidingwindow;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
/**
* @program: zyfboot-javabasic
* @description: 定长子串中元音的最大数目
* @author: zhangyanfeng
* @create: 2024-08-23 23:39
**/
public class MaxVowels {
public int maxVowels(String s, int k) {
// 元音字母集合
Set<Character> vowels = new HashSet<>(Arrays.asList('a', 'e', 'i', 'o', 'u'));
// 计算初始窗口中元音字母的数量
int maxVowelsCount = 0;
int currentVowelsCount = 0;
// 初始化窗口的元音字母数量
for (int i = 0; i < k; i++) {
if (vowels.contains(s.charAt(i))) {
currentVowelsCount++;
}
}
// 设置初始的最大元音字母数量
maxVowelsCount = currentVowelsCount;
// 滑动窗口,更新元音字母数量
for (int i = k; i < s.length(); i++) {
// 移出窗口左边的字符
if (vowels.contains(s.charAt(i - k))) {
currentVowelsCount--;
}
// 添加窗口右边的字符
if (vowels.contains(s.charAt(i))) {
currentVowelsCount++;
}
// 更新最大元音字母数量
maxVowelsCount = Math.max(maxVowelsCount, currentVowelsCount);
}
return maxVowelsCount;
}
public static void main(String[] args) {
MaxVowels solution = new MaxVowels();
// 测试用例 1
String s1 = "abciiidef";
int k1 = 3;
System.out.println("Test Case 1: " + (solution.maxVowels(s1, k1) == 3 ? "Passed" : "Failed"));
// 测试用例 2
String s2 = "aeiou";
int k2 = 2;
System.out.println("Test Case 2: " + (solution.maxVowels(s2, k2) == 2 ? "Passed" : "Failed"));
// 测试用例 3
String s3 = "leetcode";
int k3 = 3;
System.out.println("Test Case 3: " + (solution.maxVowels(s3, k3) == 2 ? "Passed" : "Failed"));
// 测试用例 4
String s4 = "rhythms";
int k4 = 4;
System.out.println("Test Case 4: " + (solution.maxVowels(s4, k4) == 0 ? "Passed" : "Failed"));
// 测试用例 5
String s5 = "tryhard";
int k5 = 4;
System.out.println("Test Case 5: " + (solution.maxVowels(s5, k5) == 1 ? "Passed" : "Failed"));
}
}
16.最大连续1的个数 III(中等)
题目描述
给定一个二进制数组
nums和一个整数k,如果可以翻转最多k个0,则返回 数组中连续1的最大个数 。示例 1:输入:nums = [1,1,1,0,0,0,1,1,1,1,0], K = 2 输出:6 解释:[1,1,1,0,0,1,1,1,1,1,1] 粗体数字从 0 翻转到 1,最长的子数组长度为 6。
示例 2:输入:nums = [0,0,1,1,0,0,1,1,1,0,1,1,0,0,0,1,1,1,1], K = 3 输出:10 解释:[0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,1] 粗体数字从 0 翻转到 1,最长的子数组长度为 10。
提示:
1 <= nums.length <= 105nums[i]不是0就是10 <= k <= nums.length
解题思路
要解决这个问题,可以使用滑动窗口(双指针)技术来优化性能:
-
滑动窗口初始化:使用两个指针
left和right,初始化窗口的左右边界;通过移动right指针扩展窗口,计算窗口内的 0 的数量。 -
控制 0 的数量:当窗口内的 0 的数量超过
k时,移动left指针收缩窗口,直到窗口内的 0 的数量不超过k。 -
更新最大长度:在每一步,计算当前窗口的长度,并更新最大长度。
-
返回结果:返回找到的最大长度。
复杂度分析
- 时间复杂度:
O(n),因为每个元素被访问和处理的次数都是常量级的。 - 空间复杂度:
O(1),只使用了常量级别的额外空间。
代码实现
package org.zyf.javabasic.letcode.featured75.slidingwindow;
/**
* @program: zyfboot-javabasic
* @description: 最大连续1的个数 III
* @author: zhangyanfeng
* @create: 2024-08-23 23:43
**/
public class LongestOnes {
public int longestOnes(int[] nums, int k) {
int left = 0; // 滑动窗口的左边界
int zeroCount = 0; // 当前窗口内 0 的数量
int maxLength = 0; // 最大子数组长度
// 使用右指针扩展窗口
for (int right = 0; right < nums.length; right++) {
// 如果当前元素是 0,增加 0 的计数
if (nums[right] == 0) {
zeroCount++;
}
// 当窗口内的 0 的数量超过 k 时,移动左边界
while (zeroCount > k) {
if (nums[left] == 0) {
zeroCount--;
}
left++;
}
// 更新最大长度
maxLength = Math.max(maxLength, right - left + 1);
}
return maxLength;
}
public static void main(String[] args) {
LongestOnes solution = new LongestOnes();
// 测试用例 1
int[] nums1 = {1,1,1,0,0,0,1,1,1,1,0};
int k1 = 2;
System.out.println("Test Case 1: " + (solution.longestOnes(nums1, k1) == 6 ? "Passed" : "Failed"));
// 测试用例 2
int[] nums2 = {0,0,1,1,0,0,1,1,1,0,1,1,0,0,0,1,1,1,1};
int k2 = 3;
System.out.println("Test Case 2: " + (solution.longestOnes(nums2, k2) == 10 ? "Passed" : "Failed"));
// 测试用例 3
int[] nums3 = {1,1,0,0,1,1,1,0,0,1,1};
int k3 = 2;
System.out.println("Test Case 3: " + (solution.longestOnes(nums3, k3) == 6 ? "Passed" : "Failed"));
// 测试用例 4
int[] nums4 = {0,0,0,0,0,0,0,0};
int k4 = 5;
System.out.println("Test Case 4: " + (solution.longestOnes(nums4, k4) == 5 ? "Passed" : "Failed"));
// 测试用例 5
int[] nums5 = {1,1,1,1,1,1,1};
int k5 = 0;
System.out.println("Test Case 5: " + (solution.longestOnes(nums5, k5) == 7 ? "Passed" : "Failed"));
}
}
17.删掉一个元素以后全为 1 的最长子数组(中等)
题目描述
给你一个二进制数组
nums,你需要从中删掉一个元素。请你在删掉元素的结果数组中,返回最长的且只包含 1 的非空子数组的长度。
如果不存在这样的子数组,请返回 0 。
提示 1:输入:nums = [1,1,0,1] 输出:3 解释:删掉位置 2 的数后,[1,1,1] 包含 3 个 1 。
示例 2:输入:nums = [0,1,1,1,0,1,1,0,1] 输出:5 解释:删掉位置 4 的数字后,[0,1,1,1,1,1,0,1] 的最长全 1 子数组为 [1,1,1,1,1] 。
示例 3:输入:nums = [1,1,1] 输出:2 解释:你必须要删除一个元素。
提示:
1 <= nums.length <= 105nums[i]要么是0要么是1。
解题思路
要解决这个问题,我们可以使用滑动窗口(双指针)技术来优化性能:
-
滑动窗口初始化:使用两个指针
left和right,初始化窗口的左右边界;需要维护一个变量zeroCount来记录当前窗口内的 0 的数量。 -
控制 0 的数量:当窗口内的 0 的数量超过 1 时,移动
left指针收缩窗口,直到窗口内的 0 的数量不超过 1;计算当前窗口内的 1 的长度,并更新最大长度。 -
特殊情况:如果整个数组都是 1,最长的 1 的子数组为
n-1(删除一个元素)。
复杂度分析
- 时间复杂度:
O(n),因为每个元素被访问和处理的次数都是常量级的。 - 空间复杂度:
O(1),只使用了常量级别的额外空间。
代码实现
package org.zyf.javabasic.letcode.featured75.slidingwindow;
/**
* @program: zyfboot-javabasic
* @description: 删掉一个元素以后全为 1 的最长子数组
* @author: zhangyanfeng
* @create: 2024-08-23 23:47
**/
public class LongestSubarray {
public int longestSubarray(int[] nums) {
int left = 0; // 滑动窗口的左边界
int zeroCount = 0; // 当前窗口内 0 的数量
int maxLength = 0; // 最大子数组长度
// 使用右指针扩展窗口
for (int right = 0; right < nums.length; right++) {
// 如果当前元素是 0,增加 0 的计数
if (nums[right] == 0) {
zeroCount++;
}
// 当窗口内的 0 的数量超过 1 时,移动左边界
while (zeroCount > 1) {
if (nums[left] == 0) {
zeroCount--;
}
left++;
}
// 更新最大长度,注意删除一个元素,所以需要减去 1
maxLength = Math.max(maxLength, right - left);
}
return maxLength;
}
public static void main(String[] args) {
LongestSubarray solution = new LongestSubarray();
// 测试用例 1
int[] nums1 = {1,1,0,1};
System.out.println("Test Case 1: " + (solution.longestSubarray(nums1) == 3 ? "Passed" : "Failed"));
// 测试用例 2
int[] nums2 = {0,1,1,1,0,1,1,0,1};
System.out.println("Test Case 2: " + (solution.longestSubarray(nums2) == 5 ? "Passed" : "Failed"));
// 测试用例 3
int[] nums3 = {1,1,1};
System.out.println("Test Case 3: " + (solution.longestSubarray(nums3) == 2 ? "Passed" : "Failed"));
// 测试用例 4
int[] nums4 = {1,0,1,0,1,0,1};
System.out.println("Test Case 4: " + (solution.longestSubarray(nums4) == 4 ? "Passed" : "Failed"));
// 测试用例 5
int[] nums5 = {0,0,0,0,0};
System.out.println("Test Case 5: " + (solution.longestSubarray(nums5) == 0 ? "Passed" : "Failed"));
}
}
四、前缀和
18.找到最高海拔(简单)
题目描述
有一个自行车手打算进行一场公路骑行,这条路线总共由
n + 1个不同海拔的点组成。自行车手从海拔为0的点0开始骑行。给你一个长度为
n的整数数组gain,其中gain[i]是点i和点i + 1的 净海拔高度差(0 <= i < n)。请你返回 最高点的海拔 。示例 1:输入:gain = [-5,1,5,0,-7] 输出:1 解释:海拔高度依次为 [0,-5,-4,1,1,-6] 。最高海拔为 1 。
示例 2:输入:gain = [-4,-3,-2,-1,4,3,2] 输出:0 解释:海拔高度依次为 [0,-4,-7,-9,-10,-6,-3,-1] 。最高海拔为 0 。
提示:
n == gain.length1 <= n <= 100-100 <= gain[i] <= 100
解题思路
要解决这个问题,我们需要找到骑行过程中最高的海拔高度,这里的海拔高度通过累积每段路程的净高度差来计算。我们可以通过以下步骤来实现:
-
初始化:从海拔为 0 的起点开始;使用一个变量
currentAltitude来记录当前的海拔高度;使用另一个变量maxAltitude来记录遇到的最高海拔。 -
遍历
gain数组:从gain数组的第一个元素开始,更新currentAltitude;每次更新后,检查currentAltitude是否大于maxAltitude,如果是,更新maxAltitude。 -
返回结果:遍历结束后,
maxAltitude即为最高海拔。
复杂度分析
- 时间复杂度:
O(n),其中n是gain数组的长度,因为我们只需遍历一次gain数组。 - 空间复杂度:
O(1),只使用了常量级别的额外空间来存储变量。
代码实现
package org.zyf.javabasic.letcode.featured75.prefix;
/**
* @program: zyfboot-javabasic
* @description: 找到最高海拔
* @author: zhangyanfeng
* @create: 2024-08-23 23:54
**/
public class LargestAltitude {
public int largestAltitude(int[] gain) {
int currentAltitude = 0; // 当前海拔高度,初始为 0
int maxAltitude = 0; // 最高海拔高度,初始为 0
// 遍历 gain 数组
for (int g : gain) {
// 更新当前海拔高度
currentAltitude += g;
// 更新最高海拔高度
maxAltitude = Math.max(maxAltitude, currentAltitude);
}
return maxAltitude; // 返回最高海拔高度
}
public static void main(String[] args) {
LargestAltitude solution = new LargestAltitude();
// 测试用例 1
int[] gain1 = {-5, 1, 5, 0, -7};
System.out.println("Test Case 1: " + (solution.largestAltitude(gain1) == 1 ? "Passed" : "Failed"));
// 测试用例 2
int[] gain2 = {-4, -3, -2, -1, 4, 3, 2};
System.out.println("Test Case 2: " + (solution.largestAltitude(gain2) == 0 ? "Passed" : "Failed"));
// 测试用例 3
int[] gain3 = {1, 2, 3, 4, 5};
System.out.println("Test Case 3: " + (solution.largestAltitude(gain3) == 15 ? "Passed" : "Failed"));
// 测试用例 4
int[] gain4 = {-1, -2, -3, -4};
System.out.println("Test Case 4: " + (solution.largestAltitude(gain4) == 0 ? "Passed" : "Failed"));
// 测试用例 5
int[] gain5 = {10, -5, -1, 2, 6};
System.out.println("Test Case 5: " + (solution.largestAltitude(gain5) == 12 ? "Passed" : "Failed"));
}
}
19.寻找数组的中心下标(简单)
题目描述
给你一个整数数组
nums,请计算数组的 中心下标 。数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
如果中心下标位于数组最左端,那么左侧数之和视为
0,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。如果数组有多个中心下标,应该返回 最靠近左边 的那一个。如果数组不存在中心下标,返回
-1。示例 1:输入:nums = [1, 7, 3, 6, 5, 6] 输出:3 解释: 中心下标是 3 。 左侧数之和 sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11 , 右侧数之和 sum = nums[4] + nums[5] = 5 + 6 = 11 ,二者相等。
示例 2:输入:nums = [1, 2, 3] 输出:-1 解释: 数组中不存在满足此条件的中心下标。
示例 3:输入:nums = [2, 1, -1] 输出:0 解释: 中心下标是 0 。 左侧数之和 sum = 0 ,(下标 0 左侧不存在元素), 右侧数之和 sum = nums[1] + nums[2] = 1 + -1 = 0 。
提示:
1 <= nums.length <= 104-1000 <= nums[i] <= 1000
解题思路
要找出数组的中心下标,我们需要找到一个下标,使得该下标左侧的所有元素的和等于右侧所有元素的和。下面是解决这个问题的最优解题思路和代码实现。
-
计算总和:首先计算整个数组的总和。
-
遍历数组:
- 使用一个变量
leftSum来记录当前下标左侧所有元素的和。初始时leftSum为 0。 - 遍历数组,对于每个下标
i,可以通过总和减去leftSum和当前元素nums[i]来计算右侧的和。 - 如果
leftSum等于右侧的和,则当前下标i是中心下标,返回i。 - 更新
leftSum以包含当前下标的元素,继续遍历。
- 使用一个变量
-
返回结果:如果遍历完整个数组没有找到符合条件的下标,返回 -1。
复杂度分析
- 时间复杂度:
O(n),其中n是nums数组的长度。因为我们只需要遍历一次数组来计算总和并找到中心下标。 - 空间复杂度:
O(1),只使用了常量级别的额外空间来存储变量。
代码实现
package org.zyf.javabasic.letcode.featured75.prefix;
/**
* @program: zyfboot-javabasic
* @description: 寻找数组的中心下标
* @author: zhangyanfeng
* @create: 2024-08-23 23:59
**/
public class PivotIndex {
public int pivotIndex(int[] nums) {
int totalSum = 0; // 计算数组的总和
int leftSum = 0; // 当前下标左侧元素的和
// 计算总和
for (int num : nums) {
totalSum += num;
}
// 遍历数组
for (int i = 0; i < nums.length; i++) {
// 右侧元素的和 = 总和 - 左侧元素的和 - 当前元素
int rightSum = totalSum - leftSum - nums[i];
// 检查当前下标是否是中心下标
if (leftSum == rightSum) {
return i;
}
// 更新左侧元素的和
leftSum += nums[i];
}
// 没有找到中心下标
return -1;
}
public static void main(String[] args) {
PivotIndex solution = new PivotIndex();
// 测试用例 1
int[] nums1 = {1, 7, 3, 6, 5, 6};
System.out.println("Test Case 1: " + (solution.pivotIndex(nums1) == 3 ? "Passed" : "Failed"));
// 测试用例 2
int[] nums2 = {1, 2, 3};
System.out.println("Test Case 2: " + (solution.pivotIndex(nums2) == -1 ? "Passed" : "Failed"));
// 测试用例 3
int[] nums3 = {2, 1, -1};
System.out.println("Test Case 3: " + (solution.pivotIndex(nums3) == 0 ? "Passed" : "Failed"));
// 测试用例 4
int[] nums4 = {1, 1, 1, 1, 1, 1, 1};
System.out.println("Test Case 4: " + (solution.pivotIndex(nums4) == 3 ? "Passed" : "Failed"));
// 测试用例 5
int[] nums5 = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
System.out.println("Test Case 5: " + (solution.pivotIndex(nums5) == -1 ? "Passed" : "Failed"));
}
}
五、哈希表 / 哈希集合
20.找出两数组的不同(简单)
题目描述
给你两个下标从
0开始的整数数组nums1和nums2,请你返回一个长度为2的列表answer,其中:
answer[0]是nums1中所有 不 存在于nums2中的 不同 整数组成的列表。answer[1]是nums2中所有 不 存在于nums1中的 不同 整数组成的列表。注意:列表中的整数可以按 任意 顺序返回。
示例 1:输入:nums1 = [1,2,3], nums2 = [2,4,6] 输出:[[1,3],[4,6]] 解释: 对于 nums1 ,nums1[1] = 2 出现在 nums2 中下标 0 处,然而 nums1[0] = 1 和 nums1[2] = 3 没有出现在 nums2 中。因此,answer[0] = [1,3]。 对于 nums2 ,nums2[0] = 2 出现在 nums1 中下标 1 处,然而 nums2[1] = 4 和 nums2[2] = 6 没有出现在 nums2 中。因此,answer[1] = [4,6]。
示例 2:输入:nums1 = [1,2,3,3], nums2 = [1,1,2,2] 输出:[[3],[]] 解释: 对于 nums1 ,nums1[2] 和 nums1[3] 没有出现在 nums2 中。由于 nums1[2] == nums1[3] ,二者的值只需要在 answer[0] 中出现一次,故 answer[0] = [3]。 nums2 中的每个整数都在 nums1 中出现,因此,answer[1] = [] 。
提示:
1 <= nums1.length, nums2.length <= 1000-1000 <= nums1[i], nums2[i] <= 1000
解题思路
要解决这个问题,我们需要找到两个数组中各自独有的元素。具体来说,我们需要找出:
nums1中不在nums2中的所有不同整数。nums2中不在nums1中的所有不同整数。
解题思路
-
使用集合:使用两个集合分别存储
nums1和nums2中的不同整数;使用两个额外的集合来存储nums1和nums2中的独有元素。 -
填充集合:将
nums1和nums2的元素分别添加到两个集合中。 -
找出差集:计算
nums1集合与nums2集合的差集,得到nums1中不在nums2中的不同元素;计算nums2集合与nums1集合的差集,得到nums2中不在nums1中的不同元素。 -
返回结果:将上述两个差集转化为列表,并作为结果返回。
复杂度分析
- 时间复杂度:
O(n + m),其中n和m是nums1和nums2的长度。由于使用集合进行操作,插入和查找的时间复杂度为O(1),因此总体复杂度是线性的。 - 空间复杂度:
O(n + m),用于存储两个集合中的元素。
代码实现
package org.zyf.javabasic.letcode.featured75.hash;
import java.util.*;
/**
* @program: zyfboot-javabasic
* @description: 找出两数组的不同
* @author: zhangyanfeng
* @create: 2024-08-24 00:05
**/
public class FindDifference {
public List<List<Integer>> findDifference(int[] nums1, int[] nums2) {
// 创建两个集合用于存储 nums1 和 nums2 中的不同整数
Set<Integer> set1 = new HashSet<>();
Set<Integer> set2 = new HashSet<>();
// 填充 set1
for (int num : nums1) {
set1.add(num);
}
// 填充 set2
for (int num : nums2) {
set2.add(num);
}
// 找到 nums1 中不在 nums2 中的不同整数
Set<Integer> uniqueToNums1 = new HashSet<>(set1);
uniqueToNums1.removeAll(set2);
// 找到 nums2 中不在 nums1 中的不同整数
Set<Integer> uniqueToNums2 = new HashSet<>(set2);
uniqueToNums2.removeAll(set1);
// 转化为列表并返回结果
List<Integer> result1 = new ArrayList<>(uniqueToNums1);
List<Integer> result2 = new ArrayList<>(uniqueToNums2);
List<List<Integer>> result = new ArrayList<>();
result.add(result1);
result.add(result2);
return result;
}
public static void main(String[] args) {
FindDifference solution = new FindDifference();
// 测试用例 1
int[] nums1 = {1, 2, 3};
int[] nums2 = {2, 4, 6};
System.out.println("Test Case 1: " + (solution.findDifference(nums1, nums2).equals(Arrays.asList(Arrays.asList(1, 3), Arrays.asList(4, 6))) ? "Passed" : "Failed"));
// 测试用例 2
int[] nums3 = {1, 2, 3, 3};
int[] nums4 = {1, 1, 2, 2};
System.out.println("Test Case 2: " + (solution.findDifference(nums3, nums4).equals(Arrays.asList(Arrays.asList(3), Collections.emptyList())) ? "Passed" : "Failed"));
// 测试用例 3
int[] nums5 = {4, 5, 6};
int[] nums6 = {7, 8, 9};
System.out.println("Test Case 3: " + (solution.findDifference(nums5, nums6).equals(Arrays.asList(Arrays.asList(4, 5, 6), Arrays.asList(7, 8, 9))) ? "Passed" : "Failed"));
// 测试用例 4
int[] nums7 = {1, 1, 1};
int[] nums8 = {1, 1, 1};
System.out.println("Test Case 4: " + (solution.findDifference(nums7, nums8).equals(Arrays.asList(Collections.emptyList(), Collections.emptyList())) ? "Passed" : "Failed"));
// 测试用例 5
int[] nums9 = {1, 2, 3, 4, 5};
int[] nums10 = {5, 6, 7, 8, 9};
System.out.println("Test Case 5: " + (solution.findDifference(nums9, nums10).equals(Arrays.asList(Arrays.asList(1, 2, 3, 4), Arrays.asList(6, 7, 8, 9))) ? "Passed" : "Failed"));
}
}
21.独一无二的出现次数(简单)
题目描述
给你一个整数数组
arr,请你帮忙统计数组中每个数的出现次数。如果每个数的出现次数都是独一无二的,就返回
true;否则返回false。示例 1:输入:arr = [1,2,2,1,1,3] 输出:true 解释:在该数组中,1 出现了 3 次,2 出现了 2 次,3 只出现了 1 次。没有两个数的出现次数相同。
示例 2:输入:arr = [1,2] 输出:false
示例 3:输入:arr = [-3,0,1,-3,1,1,1,-3,10,0] 输出:true
提示:
1 <= arr.length <= 1000-1000 <= arr[i] <= 1000
解题思路
为了确定数组中每个数的出现次数是否都是独一无二的,我们可以采用以下思路:
-
统计每个数的出现次数:使用一个
HashMap来记录每个数的出现次数。键是数组中的数,值是该数出现的次数。 -
统计出现次数的频率:使用另一个
HashMap来记录每个出现次数的频率。键是出现的次数,值是这些次数出现的次数。 -
检查频率是否唯一:遍历记录出现次数频率的
HashMap,如果发现某个次数的出现频率大于 1,则返回false;否则返回true。
复杂度分析
- 时间复杂度:
O(n),其中n是数组的长度。我们遍历数组两次,一次用于统计次数,另一次用于检查次数的唯一性。 - 空间复杂度:
O(n),用于存储两个HashMap。
代码实现
package org.zyf.javabasic.letcode.featured75.hash;
import java.util.HashMap;
import java.util.Map;
/**
* @program: zyfboot-javabasic
* @description: 独一无二的出现次数
* @author: zhangyanfeng
* @create: 2024-08-24 00:12
**/
public class UniqueOccurrences {
public boolean uniqueOccurrences(int[] arr) {
// 统计每个数的出现次数
Map<Integer, Integer> countMap = new HashMap<>();
for (int num : arr) {
countMap.put(num, countMap.getOrDefault(num, 0) + 1);
}
// 统计出现次数的频率
Map<Integer, Integer> freqMap = new HashMap<>();
for (int count : countMap.values()) {
freqMap.put(count, freqMap.getOrDefault(count, 0) + 1);
}
// 检查出现次数的频率是否唯一
for (int freq : freqMap.values()) {
if (freq > 1) {
return false; // 存在相同的出现次数
}
}
return true; // 所有出现次数都是唯一的
}
public static void main(String[] args) {
UniqueOccurrences solution = new UniqueOccurrences();
// 测试用例 1
int[] arr1 = {1, 2, 2, 1, 1, 3};
System.out.println("Test Case 1: " + (solution.uniqueOccurrences(arr1) ? "Passed" : "Failed")); // 应输出 true
// 测试用例 2
int[] arr2 = {1, 2};
System.out.println("Test Case 2: " + (solution.uniqueOccurrences(arr2) ? "Passed" : "Failed")); // 应输出 false
// 测试用例 3
int[] arr3 = {-3, 0, 1, -3, 1, 1, 1, -3, 10, 0};
System.out.println("Test Case 3: " + (solution.uniqueOccurrences(arr3) ? "Passed" : "Failed")); // 应输出 true
// 测试用例 4
int[] arr4 = {1, 1, 1, 2, 2, 3, 3, 3, 3};
System.out.println("Test Case 4: " + (solution.uniqueOccurrences(arr4) ? "Passed" : "Failed")); // 应输出 false
// 测试用例 5
int[] arr5 = {1, 2, 2, 3, 3, 3};
System.out.println("Test Case 5: " + (solution.uniqueOccurrences(arr5) ? "Passed" : "Failed")); // 应输出 false
}
}
22.确定两个字符串是否接近 (中等)
题目描述
如果可以使用以下操作从一个字符串得到另一个字符串,则认为两个字符串 接近 :
- 操作 1:交换任意两个 现有 字符。
- 例如,
abcde -> aecdb- 操作 2:将一个 现有 字符的每次出现转换为另一个 现有 字符,并对另一个字符执行相同的操作。
- 例如,
aacabb -> bbcbaa(所有a转化为b,而所有的b转换为a)你可以根据需要对任意一个字符串多次使用这两种操作。
给你两个字符串,
word1和word2。如果word1和word2接近 ,就返回true;否则,返回false。示例 1:输入:word1 = "abc", word2 = "bca" 输出:true 解释:2 次操作从 word1 获得 word2 。 执行操作 1:"abc" -> "acb" 执行操作 1:"acb" -> "bca"
示例 2:输入:word1 = "a", word2 = "aa" 输出:false 解释:不管执行多少次操作,都无法从 word1 得到 word2 ,反之亦然。
示例 3:输入:word1 = "cabbba", word2 = "abbccc" 输出:true 解释:3 次操作从 word1 获得 word2 。 执行操作 1:"cabbba" -> "caabbb" 执行操作 2:
"caabbb" -> "baaccc" 执行操作 2:"baaccc" -> "abbccc"提示:
1 <= word1.length, word2.length <= 105word1和word2仅包含小写英文字母
解题思路
两个字符串 word1 和 word2 是否接近,可以通过以下步骤来判断:
-
字符集合相同:
首先,两个字符串中必须包含相同的字符集合。如果word1中有word2中不存在的字符,或者word2中有word1中不存在的字符,那么它们无法通过任何操作互相转换,因此直接返回false。 -
字符频率相同:
接着,两个字符串中每个字符出现的频率在排序后也应该相同。如果word1中字符的频率分布与word2中的频率分布不一致,即便它们包含相同的字符集合,也无法通过允许的操作互相转换,因此返回false。
如果两个字符串包含相同的字符集合,并且这些字符的频率分布在排序后相同,那么我们就可以通过操作 1 和操作 2 将一个字符串转换为另一个字符串。因此返回 true。
复杂度分析
- 时间复杂度:
O(n),其中n是字符串的长度。主要时间花费在统计字符频率和对频率进行排序。 - 空间复杂度:
O(1),因为只需常数级别的额外空间用于存储频率信息(假设字符集大小是固定的,即只有小写字母)。
代码实现
package org.zyf.javabasic.letcode.featured75.hash;
import java.util.Arrays;
/**
* @program: zyfboot-javabasic
* @description: 确定两个字符串是否接近
* @author: zhangyanfeng
* @create: 2024-08-24 09:02
**/
public class CloseStrings {
public boolean closeStrings(String word1, String word2) {
// 如果长度不同,直接返回 false
if (word1.length() != word2.length()) {
return false;
}
// 初始化两个数组用于记录两个字符串中每个字符的频率
int[] freq1 = new int[26];
int[] freq2 = new int[26];
// 遍历 word1 并记录频率
for (char c : word1.toCharArray()) {
freq1[c - 'a']++;
}
// 遍历 word2 并记录频率
for (char c : word2.toCharArray()) {
freq2[c - 'a']++;
}
// 检查两个字符串的字符集合是否相同
for (int i = 0; i < 26; i++) {
if ((freq1[i] == 0 && freq2[i] > 0) || (freq2[i] == 0 && freq1[i] > 0)) {
return false; // 字符集合不同,返回 false
}
}
// 对频率数组进行排序
Arrays.sort(freq1);
Arrays.sort(freq2);
// 如果频率分布不同,返回 false
for (int i = 0; i < 26; i++) {
if (freq1[i] != freq2[i]) {
return false;
}
}
// 如果通过以上检查,则返回 true
return true;
}
public static void main(String[] args) {
CloseStrings solution = new CloseStrings();
// 测试用例 1
String word1 = "abc";
String word2 = "bca";
System.out.println("Test Case 1: " + (solution.closeStrings(word1, word2) ? "Passed" : "Failed")); // 应输出 true
// 测试用例 2
word1 = "a";
word2 = "aa";
System.out.println("Test Case 2: " + (solution.closeStrings(word1, word2) ? "Passed" : "Failed")); // 应输出 false
// 测试用例 3
word1 = "cabbba";
word2 = "abbccc";
System.out.println("Test Case 3: " + (solution.closeStrings(word1, word2) ? "Passed" : "Failed")); // 应输出 true
// 测试用例 4
word1 = "uio";
word2 = "oiu";
System.out.println("Test Case 4: " + (solution.closeStrings(word1, word2) ? "Passed" : "Failed")); // 应输出 true
// 测试用例 5
word1 = "abcd";
word2 = "dcba";
System.out.println("Test Case 5: " + (solution.closeStrings(word1, word2) ? "Passed" : "Failed")); // 应输出 true
}
}
23.相等行列对(中等)
题目描述
给你一个下标从 0 开始、大小为
n x n的整数矩阵grid,返回满足Ri行和Cj列相等的行列对(Ri, Cj)的数目。如果行和列以相同的顺序包含相同的元素(即相等的数组),则认为二者是相等的。
示例 1:
输入:grid = [[3,2,1],[1,7,6],[2,7,7]] 输出:1 解释:存在一对相等行列对: - (第 2 行,第 1 列):[2,7,7]示例 2:
输入:grid = [[3,1,2,2],[1,4,4,5],[2,4,2,2],[2,4,2,2]] 输出:3 解释:存在三对相等行列对: - (第 0 行,第 0 列):[3,1,2,2] - (第 2 行, 第 2 列):[2,4,2,2] - (第 3 行, 第 2 列):[2,4,2,2]提示:
n == grid.length == grid[i].length1 <= n <= 2001 <= grid[i][j] <= 105
解题思路
为了找到矩阵中所有相等的行和列对,可以采取以下方法:
-
行与列的比较:
由于行和列需要相等才能构成有效的行列对,我们可以遍历所有行,并将每一行视为一个数组;然后,遍历每一列,查看该列是否与当前的行相同;如果行和列相等,则计数器加一。 -
哈希映射(优化方案):
可以使用哈希映射来优化比较过程。具体而言,首先将所有行存储到一个哈希映射中,键为行内容(转换为元组形式),值为出现的次数;然后,遍历所有列并检查该列是否在哈希映射中存在。如果存在,则计数器加上该行对应的出现次数。
复杂度分析
- 时间复杂度:
O(n^2),其中n是矩阵的大小。构造哈希表的时间复杂度为O(n^2),随后检查每一列在哈希表中的存在性同样为O(n^2)。 - 空间复杂度:
O(n^2),用于存储行的哈希映射。
代码实现
package org.zyf.javabasic.letcode.featured75.hash;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @program: zyfboot-javabasic
* @description: 相等行列对
* @author: zhangyanfeng
* @create: 2024-08-24 09:10
**/
public class EqualPairs {
public int equalPairs(int[][] grid) {
int n = grid.length;
int count = 0;
// 使用 HashMap 存储每一行及其出现的次数
Map<List<Integer>, Integer> rowMap = new HashMap<>();
// 遍历所有行
for (int i = 0; i < n; i++) {
List<Integer> rowList = new ArrayList<>();
for (int j = 0; j < n; j++) {
rowList.add(grid[i][j]);
}
rowMap.put(rowList, rowMap.getOrDefault(rowList, 0) + 1);
}
// 遍历所有列
for (int j = 0; j < n; j++) {
List<Integer> colList = new ArrayList<>();
for (int i = 0; i < n; i++) {
colList.add(grid[i][j]);
}
// 如果列的数组在 rowMap 中存在,则增加对应的计数
if (rowMap.containsKey(colList)) {
count += rowMap.get(colList);
}
}
return count;
}
public static void main(String[] args) {
EqualPairs solution = new EqualPairs();
// 测试用例 1
int[][] grid1 = {{3, 2, 1}, {1, 7, 6}, {2, 7, 7}};
System.out.println("Test Case 1: " + solution.equalPairs(grid1)); // 应输出 1
// 测试用例 2
int[][] grid2 = {{3, 1, 2, 2}, {1, 4, 4, 5}, {2, 4, 2, 2}, {2, 4, 2, 2}};
System.out.println("Test Case 2: " + solution.equalPairs(grid2)); // 应输出 3
}
}
六、栈
24.从字符串中移除星号(中等)
题目描述
给你一个包含若干星号
*的字符串s。在一步操作中,你可以:
- 选中
s中的一个星号。- 移除星号 左侧 最近的那个 非星号 字符,并移除该星号自身。
返回移除 所有 星号之后的字符串。
注意:
- 生成的输入保证总是可以执行题面中描述的操作。
- 可以证明结果字符串是唯一的。
示例 1:输入:s = "leet**cod*e" 输出:"lecoe" 解释:从左到右执行移除操作: - 距离第 1 个星号最近的字符是 "leet**cod*e" 中的 't' ,s 变为 "lee*cod*e" 。 - 距离第 2 个星号最近的字符是 "lee*cod*e" 中的 'e' ,s 变为 "lecod*e" 。 - 距离第 3 个星号最近的字符是 "lecod*e" 中的 'd' ,s 变为 "lecoe" 。 不存在其他星号,返回 "lecoe" 。
示例 2:输入:s = "erase*****" 输出:"" 解释:整个字符串都会被移除,所以返回空字符串。
提示:
1 <= s.length <= 105s由小写英文字母和星号*组成s可以执行上述操作
解题思路
要求我们移除所有星号以及每个星号左侧最近的非星号字符,由于我们需要对字符串进行多次移除操作,最合适的方式是利用栈这种数据结构来处理。
- 初始化一个空栈,用于存放非星号字符。
- 遍历字符串中的每一个字符:如果字符不是星号,则将其压入栈中;如果字符是星号,则弹出栈顶的非星号字符(即移除最近的非星号字符),并继续遍历。
- 遍历结束后,栈中的所有字符即为最终的结果。
- 最后将栈中的字符拼接成结果字符串并返回。
复杂度分析
- 时间复杂度:
O(n),其中n是字符串的长度。每个字符最多被压入和弹出栈一次。 - 空间复杂度:
O(n),最坏情况下,栈中需要存储所有非星号字符。
代码实现
package org.zyf.javabasic.letcode.featured75.stack;
import java.util.Stack;
/**
* @program: zyfboot-javabasic
* @description: 从字符串中移除星号
* @author: zhangyanfeng
* @create: 2024-08-24 09:17
**/
public class RemoveStars {
public String removeStars(String s) {
// 初始化一个栈,用于存放非星号字符
Stack<Character> stack = new Stack<>();
// 遍历字符串中的每个字符
for (char c : s.toCharArray()) {
if (c != '*') {
// 如果字符不是星号,将其压入栈中
stack.push(c);
} else {
// 如果字符是星号,弹出栈顶字符
if (!stack.isEmpty()) {
stack.pop();
}
}
}
// 将栈中的字符拼接成结果字符串
StringBuilder result = new StringBuilder();
while (!stack.isEmpty()) {
result.append(stack.pop());
}
// 由于栈的性质,最后的字符顺序是相反的,因此我们需要翻转字符串
return result.reverse().toString();
}
public static void main(String[] args) {
RemoveStars solution = new RemoveStars();
// 测试用例 1
String s1 = "leet**cod*e";
System.out.println(solution.removeStars(s1)); // 输出: "lecoe"
// 测试用例 2
String s2 = "erase*****";
System.out.println(solution.removeStars(s2)); // 输出: ""
}
}
25.小行星碰撞(中等)
题目描述
给定一个整数数组
asteroids,表示在同一行的小行星。对于数组中的每一个元素,其绝对值表示小行星的大小,正负表示小行星的移动方向(正表示向右移动,负表示向左移动)。每一颗小行星以相同的速度移动。
找出碰撞后剩下的所有小行星。碰撞规则:两个小行星相互碰撞,较小的小行星会爆炸。如果两颗小行星大小相同,则两颗小行星都会爆炸。两颗移动方向相同的小行星,永远不会发生碰撞。
示例 1:输入:asteroids = [5,10,-5] 输出:[5,10] 解释:10 和 -5 碰撞后只剩下 10 。 5 和 10 永远不会发生碰撞。
示例 2:输入:asteroids = [8,-8] 输出:[] 解释:8 和 -8 碰撞后,两者都发生爆炸。
示例 3:输入:asteroids = [10,2,-5] 输出:[10] 解释:2 和 -5 发生碰撞后剩下 -5 。10 和 -5 发生碰撞后剩下 10 。
提示:
2 <= asteroids.length <= 104-1000 <= asteroids[i] <= 1000asteroids[i] != 0
解题思路
小行星碰撞问题可以利用栈来有效解决。由于碰撞规则涉及到相邻元素的比较,并且一旦发生碰撞,前一个小行星可能会被移除或保留,栈的数据结构非常适合这个过程。
- 初始化一个栈:用于存放在碰撞后剩余的小行星。
- 遍历小行星数组:
- 如果当前小行星向右 (
asteroid > 0),直接将其压入栈中。 - 如果当前小行星向左 (
asteroid < 0),则需要检查栈顶的小行星:- 如果栈顶小行星向右移动,可能发生碰撞。此时我们需要比较两个小行星的大小:
- 如果栈顶小行星更大(绝对值更大),继续检查下一个小行星。
- 如果当前小行星更大,弹出栈顶小行星,继续与新的栈顶小行星比较,直到栈为空或者栈顶小行星向左移动。
- 如果两者相等,则两者都爆炸,弹出栈顶小行星,不再将当前小行星压入栈。
- 如果栈顶小行星向右移动,可能发生碰撞。此时我们需要比较两个小行星的大小:
- 如果当前小行星向右 (
- 返回栈中剩余的小行星:遍历完成后,栈中存放的就是所有未发生碰撞的剩余小行星。
复杂度分析
- 时间复杂度:
O(n),每个小行星最多会被压入和弹出栈一次。 - 空间复杂度:
O(n),栈在最坏情况下需要存储所有小行星。
代码实现
package org.zyf.javabasic.letcode.featured75.stack;
import java.util.Stack;
/**
* @program: zyfboot-javabasic
* @description: 小行星碰撞
* @author: zhangyanfeng
* @create: 2024-08-24 09:21
**/
public class AsteroidCollision {
public int[] asteroidCollision(int[] asteroids) {
// 初始化栈,用于存放剩余的小行星
Stack<Integer> stack = new Stack<>();
// 遍历所有小行星
for (int asteroid : asteroids) {
boolean isDestroyed = false;
// 处理向左移动的小行星
while (!stack.isEmpty() && asteroid < 0 && stack.peek() > 0) {
// 比较栈顶和当前小行星的大小
if (stack.peek() < -asteroid) {
// 栈顶小行星较小,被摧毁
stack.pop();
continue;
} else if (stack.peek() == -asteroid) {
// 两颗小行星大小相同,双双毁灭
stack.pop();
}
// 当前小行星被摧毁
isDestroyed = true;
break;
}
// 当前小行星未被摧毁,压入栈中
if (!isDestroyed) {
stack.push(asteroid);
}
}
// 将栈中的小行星转换为数组
int[] result = new int[stack.size()];
for (int i = result.length - 1; i >= 0; i--) {
result[i] = stack.pop();
}
return result;
}
public static void main(String[] args) {
AsteroidCollision solution = new AsteroidCollision();
// 测试用例 1
int[] asteroids1 = {5, 10, -5};
int[] result1 = solution.asteroidCollision(asteroids1);
System.out.println(java.util.Arrays.toString(result1)); // 输出: [5, 10]
// 测试用例 2
int[] asteroids2 = {8, -8};
int[] result2 = solution.asteroidCollision(asteroids2);
System.out.println(java.util.Arrays.toString(result2)); // 输出: []
// 测试用例 3
int[] asteroids3 = {10, 2, -5};
int[] result3 = solution.asteroidCollision(asteroids3);
System.out.println(java.util.Arrays.toString(result3)); // 输出: [10]
}
}
26.字符串解码(中等)
题目描述
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为:
k[encoded_string],表示其中方括号内部的encoded_string正好重复k次。注意k保证为正整数。你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数
k,例如不会出现像3a或2[4]的输入。示例 1:输入:s = "3[a]2[bc]" 输出:"aaabcbc"
示例 2:输入:s = "3[a2[c]]" 输出:"accaccacc"
示例 3:输入:s = "2[abc]3[cd]ef" 输出:"abcabccdcdcdef"
示例 4:输入:s = "abc3[cd]xyz" 输出:"abccdcdcdxyz"
提示:
1 <= s.length <= 30s由小写英文字母、数字和方括号'[]'组成s保证是一个 有效 的输入。s中所有整数的取值范围为[1, 300]
解题思路
要解码经过编码的字符串,我们可以使用栈来解决问题。我们可以遍历字符串,当遇到数字时,记录重复的次数;当遇到方括号时,开始收集需要重复的字符串;当遇到闭括号时,弹出栈顶的内容,并进行解码。
-
栈的使用:
数字栈countStack:用于保存当前的重复次数;字符串栈stringStack:用于保存当前处理的字符串;当前字符串currentString:用于累积当前字符直到遇到]。 -
遍历字符串:
- 当遇到数字时,可能是一个多位数,继续读取直到完整数字并入栈。
- 当遇到
[时,将当前累积的字符串和数字分别压入stringStack和countStack,然后重置currentString以开始收集新的字符串。 - 当遇到
]时,弹出栈顶的字符串和数字,进行重复并将结果附加到栈顶字符串后,继续处理。 - 当遇到普通字符时,直接添加到
currentString。
-
处理完字符串后,将结果合并返回。
复杂度分析
- 时间复杂度:O(n),其中 nnn 是字符串的长度。我们只遍历一次字符串并且在栈操作中,所有操作均为常数时间。
- 空间复杂度:O(n,其中 nnn 是字符串的长度。使用的栈空间取决于嵌套的深度和字符串长度。
代码实现
package org.zyf.javabasic.letcode.hot100.stack;
import java.util.Stack;
/**
* @program: zyfboot-javabasic
* @description: 字符串解码(中等)
* @author: zhangyanfeng
* @create: 2024-08-22 14:34
**/
public class DecodeString {
public String decodeString(String s) {
Stack<Integer> countStack = new Stack<>();
Stack<StringBuilder> stringStack = new Stack<>();
StringBuilder currentString = new StringBuilder();
int k = 0;
for (char ch : s.toCharArray()) {
if (Character.isDigit(ch)) {
k = k * 10 + (ch - '0'); // 计算数字(可能是多位数)
} else if (ch == '[') {
countStack.push(k); // 保存当前的重复次数
stringStack.push(currentString); // 保存当前字符串
currentString = new StringBuilder(); // 重置 currentString 开始处理新字符
k = 0; // 重置 k
} else if (ch == ']') {
int count = countStack.pop(); // 弹出重复次数
StringBuilder decodedString = stringStack.pop(); // 弹出栈顶字符串
for (int i = 0; i < count; i++) {
decodedString.append(currentString); // 重复并拼接字符串
}
currentString = decodedString; // 将结果存入 currentString
} else {
currentString.append(ch); // 普通字符直接添加
}
}
return currentString.toString(); // 返回最终解码后的字符串
}
public static void main(String[] args) {
DecodeString ds = new DecodeString();
System.out.println(ds.decodeString("3[a]2[bc]")); // 输出 "aaabcbc"
System.out.println(ds.decodeString("3[a2[c]]")); // 输出 "accaccacc"
System.out.println(ds.decodeString("2[abc]3[cd]ef")); // 输出 "abcabccdcdcdef"
System.out.println(ds.decodeString("abc3[cd]xyz")); // 输出 "abccdcdcdxyz"
}
}
七、队列
27.最近的请求次数(简单)
题目描述
写一个
RecentCounter类来计算特定时间范围内最近的请求。请你实现
RecentCounter类:
RecentCounter()初始化计数器,请求数为 0 。int ping(int t)在时间t添加一个新请求,其中t表示以毫秒为单位的某个时间,并返回过去3000毫秒内发生的所有请求数(包括新请求)。确切地说,返回在[t-3000, t]内发生的请求数。保证 每次对
ping的调用都使用比之前更大的t值。示例 1:输入: ["RecentCounter", "ping", "ping", "ping", "ping"] [[], [1], [100], [3001], [3002]] 输出: [null, 1, 2, 3, 3] 解释: RecentCounter recentCounter = new RecentCounter(); recentCounter.ping(1); // requests = [1],范围是 [-2999,1],返回 1 recentCounter.ping(100); // requests = [1, 100],范围是 [-2900,100],返回 2 recentCounter.ping(3001); // requests = [1, 100, 3001],范围是 [1,3001],返回 3 recentCounter.ping(3002); // requests = [1, 100, 3001, 3002],范围是 [2,3002],返回 3
提示:
1 <= t <= 109- 保证每次对
ping调用所使用的t值都 严格递增- 至多调用
ping方法104次
解题思路
RecentCounter 类用于计算过去 3000 毫秒内发生的请求数量。这个问题可以通过**队列(Queue)**来解决,因为队列遵循先进先出的原则,能够很好地处理时间窗口的问题。
具体步骤如下:
- 使用队列存储请求的时间:当新请求到达时,我们将其时间戳添加到队列中。
- 移除过期请求:检查队列中的请求时间是否在
[t-3000, t]的范围内。如果不在这个范围内,就将其从队列中移除。 - 返回队列的大小:队列中的元素个数即为过去 3000 毫秒内的请求数量。
复杂度分析
- 每次 ping 的操作:队列中的元素最多是 3000 毫秒内的请求数,因此在最坏情况下,每次
ping的时间复杂度为O(1)进行入队和O(n)进行出队(n为不在时间范围内的请求数量)。 - 总体复杂度:由于每个请求只能被加入和移除一次,因此对于最多
10^4次ping操作,时间复杂度为O(n),其中n是ping操作的总次数。
代码实现
package org.zyf.javabasic.letcode.featured75.queue;
import java.util.LinkedList;
import java.util.Queue;
/**
* @program: zyfboot-javabasic
* @description: 最近的请求次数
* @author: zhangyanfeng
* @create: 2024-08-24 09:27
**/
public class RecentCounter {
// 定义队列来存储请求的时间戳
private Queue<Integer> queue;
// 初始化计数器,创建队列
public RecentCounter() {
queue = new LinkedList<>();
}
// 在时间 t 添加一个新请求,并返回过去 3000 毫秒内的请求数
public int ping(int t) {
// 将当前请求时间戳加入队列
queue.add(t);
// 移除不在 [t-3000, t] 范围内的请求
while (queue.peek() < t - 3000) {
queue.poll();
}
// 返回队列的大小,即为在过去 3000 毫秒内的请求数
return queue.size();
}
public static void main(String[] args) {
RecentCounter recentCounter = new RecentCounter();
// 测试用例
System.out.println(recentCounter.ping(1)); // 输出: 1
System.out.println(recentCounter.ping(100)); // 输出: 2
System.out.println(recentCounter.ping(3001));// 输出: 3
System.out.println(recentCounter.ping(3002));// 输出: 3
}
}
28.Dota2 参议院(中等)
题目描述
Dota2 的世界里有两个阵营:
Radiant(天辉)和Dire(夜魇)Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。他们以一个基于轮为过程的投票进行。在每一轮中,每一位参议员都可以行使两项权利中的 一 项:
- 禁止一名参议员的权利:参议员可以让另一位参议员在这一轮和随后的几轮中丧失 所有的权利 。
- 宣布胜利:如果参议员发现有权利投票的参议员都是 同一个阵营的 ,他可以宣布胜利并决定在游戏中的有关变化。
给你一个字符串
senate代表每个参议员的阵营。字母'R'和'D'分别代表了Radiant(天辉)和Dire(夜魇)。然后,如果有n个参议员,给定字符串的大小将是n。以轮为基础的过程从给定顺序的第一个参议员开始到最后一个参议员结束。这一过程将持续到投票结束。所有失去权利的参议员将在过程中被跳过。
假设每一位参议员都足够聪明,会为自己的政党做出最好的策略,你需要预测哪一方最终会宣布胜利并在 Dota2 游戏中决定改变。输出应该是
"Radiant"或"Dire"。示例 1:输入:senate = "RD" 输出:"Radiant" 解释:
第 1 轮时,第一个参议员来自 Radiant 阵营,他可以使用第一项权利让第二个参议员失去所有权利。 这一轮中,第二个参议员将会被跳过,因为他的权利被禁止了。 第 2 轮时,第一个参议员可以宣布胜利,因为他是唯一一个有投票权的人。示例 2:输入:senate = "RDD" 输出:"Dire" 解释: 第 1 轮时,第一个
来自 Radiant 阵营的参议员可以使用第一项权利禁止第二个参议员的权利。这一轮中,第二个来自 Dire 阵营的参议员会将被跳过,因为他的权利被禁止了。这一轮中,第三个来自 Dire 阵营的参议员可以使用他的第一项权利禁止第一个参议员的权利。 因此在第二轮只剩下第三个参议员拥有投票的权利,于是他可以宣布胜利提示:
n == senate.length1 <= n <= 104senate[i]为'R'或'D'
解题思路
这个问题可以通过队列来解决。我们使用两个队列分别存储 Radiant(天辉)和 Dire(夜魇) 阵营参议员的索引。当每个参议员投票时,我们通过比较两个队列的前端元素来决定哪个阵营的参议员可以行使“禁止”对方阵营参议员权利的操作:
-
两个队列存储各自阵营的参议员索引:我们使用两个队列分别存储 Radiant 和 Dire 阵营参议员的索引。
-
模拟投票过程:
每次从两个队列的队首取出一个参议员的索引,较小的索引表示该参议员在投票顺序中靠前,因此他可以行使权利禁止对方阵营的参议员投票权;被禁止权利的参议员从他的队列中移除,而行使权利的参议员将其索引加上n(表示他下一次投票的顺序)后重新加入队列。 -
判断胜利:当其中一个队列为空时,另一个队列的阵营就是胜利的阵营。
复杂度分析
每个参议员最多只能进入和移出队列一次,因此时间复杂度为 O(n),其中 n 为字符串的长度。
代码实现
package org.zyf.javabasic.letcode.featured75.queue;
import java.util.LinkedList;
import java.util.Queue;
/**
* @program: zyfboot-javabasic
* @description: Dota2 参议院
* @author: zhangyanfeng
* @create: 2024-08-24 09:30
**/
public class Dota2Senate {
public String predictPartyVictory(String senate) {
// 创建两个队列分别存储 Radiant 和 Dire 阵营参议员的索引
Queue<Integer> radiant = new LinkedList<>();
Queue<Integer> dire = new LinkedList<>();
int n = senate.length();
// 将每个参议员的索引分别加入对应的队列
for (int i = 0; i < n; i++) {
if (senate.charAt(i) == 'R') {
radiant.add(i);
} else {
dire.add(i);
}
}
// 模拟投票过程
while (!radiant.isEmpty() && !dire.isEmpty()) {
int rIndex = radiant.poll();
int dIndex = dire.poll();
// 谁的索引小谁就可以禁用对方阵营的参议员,并将自己放回队列
if (rIndex < dIndex) {
radiant.add(rIndex + n); // 将索引加上 n,表示下一轮的顺序
} else {
dire.add(dIndex + n); // 将索引加上 n,表示下一轮的顺序
}
}
// 如果 Radiant 阵营的队列为空,Dire 胜利;否则 Radiant 胜利
return radiant.isEmpty() ? "Dire" : "Radiant";
}
public static void main(String[] args) {
Dota2Senate solution = new Dota2Senate();
// 测试用例
System.out.println(solution.predictPartyVictory("RD")); // 输出: Radiant
System.out.println(solution.predictPartyVictory("RDD")); // 输出: Dire
}
}
八、连表
29.删除链表的中间节点(中等)
题目描述
给你一个链表的头节点
head。删除 链表的 中间节点 ,并返回修改后的链表的头节点head。长度为
n链表的中间节点是从头数起第⌊n / 2⌋个节点(下标从 0 开始),其中⌊x⌋表示小于或等于x的最大整数。
- 对于
n=1、2、3、4和5的情况,中间节点的下标分别是0、1、1、2和2。示例 1:
输入:head = [1,3,4,7,1,2,6] 输出:[1,3,4,1,2,6] 解释: 上图表示给出的链表。节点的下标分别标注在每个节点的下方。 由于 n = 7 ,值为 7 的节点 3 是中间节点,用红色标注。 返回结果为移除节点后的新链表。示例 2:
输入:head = [1,2,3,4] 输出:[1,2,4] 解释: 上图表示给出的链表。 对于 n = 4 ,值为 3 的节点 2 是中间节点,用红色标注。示例 3:
输入:head = [2,1] 输出:[2] 解释: 上图表示给出的链表。 对于 n = 2 ,值为 1 的节点 1 是中间节点,用红色标注。 值为 2 的节点 0 是移除节点 1 后剩下的唯一一个节点。提示:
- 链表中节点的数目在范围
[1, 105]内1 <= Node.val <= 105
解题思路
删除链表的中间节点可以通过使用双指针法来高效地解决。双指针法通常涉及两个指针,一个快指针和一个慢指针:
- 快慢指针遍历链表:快指针每次移动两步,慢指针每次移动一步。当快指针到达链表末尾时,慢指针正好位于链表的中间位置。
- 找到中间节点并删除:在找到中间节点后,可以通过调整链表的指针,跳过这个节点,从而将它从链表中移除。
复杂度分析
- 时间复杂度:
O(n),其中n是链表的长度。快慢指针遍历链表一次即可找到中间节点。 - 空间复杂度:
O(1),只需要使用常数级别的额外空间来存储指针。
代码实现
package org.zyf.javabasic.letcode.featured75.list;
import org.zyf.javabasic.letcode.list.base.ListNode;
/**
* @program: zyfboot-javabasic
* @description: 删除链表的中间节点
* @author: zhangyanfeng
* @create: 2024-08-24 09:35
**/
public class RemoveMiddleNode {
public ListNode deleteMiddle(ListNode head) {
// 如果链表只有一个节点,直接返回 null
if (head == null || head.next == null) {
return null;
}
// 初始化快指针和慢指针
ListNode slow = head;
ListNode fast = head;
ListNode prev = null; // 用于记录慢指针的前一个节点
// 快指针移动两步,慢指针移动一步
while (fast != null && fast.next != null) {
prev = slow; // 记录慢指针的前一个节点
slow = slow.next; // 慢指针移动一步
fast = fast.next.next; // 快指针移动两步
}
// 此时 slow 指向中间节点,将其删除
if (prev != null) {
prev.next = slow.next; // 跳过中间节点
}
return head; // 返回删除中间节点后的链表头节点
}
public static void main(String[] args) {
RemoveMiddleNode solution = new RemoveMiddleNode();
// 测试用例1
ListNode head1 = new ListNode(1);
head1.next = new ListNode(3);
head1.next.next = new ListNode(4);
head1.next.next.next = new ListNode(7);
head1.next.next.next.next = new ListNode(1);
head1.next.next.next.next.next = new ListNode(2);
head1.next.next.next.next.next.next = new ListNode(6);
ListNode newHead1 = solution.deleteMiddle(head1);
printList(newHead1); // 输出: [1, 3, 4, 1, 2, 6]
// 测试用例2
ListNode head2 = new ListNode(1);
head2.next = new ListNode(2);
head2.next.next = new ListNode(3);
head2.next.next.next = new ListNode(4);
ListNode newHead2 = solution.deleteMiddle(head2);
printList(newHead2); // 输出: [1, 2, 4]
// 测试用例3
ListNode head3 = new ListNode(2);
head3.next = new ListNode(1);
ListNode newHead3 = solution.deleteMiddle(head3);
printList(newHead3); // 输出: [2]
}
// 辅助函数:打印链表
private static void printList(ListNode head) {
while (head != null) {
System.out.print(head.val + " ");
head = head.next;
}
System.out.println();
}
}
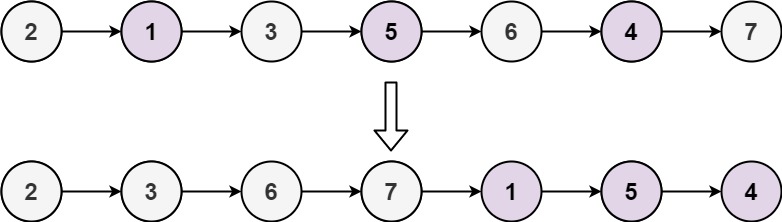
30.奇偶链表(中等)
题目描述
给定单链表的头节点
head,将所有索引为奇数的节点和索引为偶数的节点分别组合在一起,然后返回重新排序的列表。第一个节点的索引被认为是 奇数 , 第二个节点的索引为 偶数 ,以此类推。
请注意,偶数组和奇数组内部的相对顺序应该与输入时保持一致。
你必须在
O(1)的额外空间复杂度和O(n)的时间复杂度下解决这个问题。示例 1:
输入: head = [1,2,3,4,5] 输出: [1,3,5,2,4]示例 2:
输入: head = [2,1,3,5,6,4,7] 输出: [2,3,6,7,1,5,4]提示:
n ==链表中的节点数0 <= n <= 104-106 <= Node.val <= 106

解题思路
这道题要求将单链表中的奇数索引节点和偶数索引节点分别组合在一起,最终返回重新排序后的链表。解题的关键在于保持奇偶节点内部的相对顺序,并且在 O(1) 的空间复杂度和 O(n) 的时间复杂度下完成。
我们可以使用两个指针来分别处理奇数索引节点和偶数索引节点。具体步骤如下:
-
初始化两个指针:
odd指针指向链表的第一个节点(奇数索引);even指针指向链表的第二个节点(偶数索引),并且保存偶数链表的头节点evenHead。 -
重新链接节点:
通过遍历链表,将odd节点指向下一个奇数节点,将even节点指向下一个偶数节点;继续遍历直到even或者even.next为空,这时已经处理完所有的奇数和偶数节点。 -
连接两个子链表:将
odd指针的最后一个节点指向evenHead,这样就完成了奇偶链表的合并。 -
返回重排后的链表头节点。
复杂度分析
- 时间复杂度:
O(n),其中n是链表的节点数。我们只需要遍历一次链表。 - 空间复杂度:
O(1),我们只使用了常数个额外空间。
代码实现
package org.zyf.javabasic.letcode.featured75.list;
import org.zyf.javabasic.letcode.list.base.ListNode;
/**
* @program: zyfboot-javabasic
* @description: 奇偶链表
* @author: zhangyanfeng
* @create: 2024-08-24 09:40
**/
public class OddEvenList {
public ListNode oddEvenList(ListNode head) {
// 如果链表为空或只有一个节点,直接返回
if (head == null || head.next == null) {
return head;
}
// 初始化奇数指针odd,偶数指针even,以及偶数链表头evenHead
ListNode odd = head;
ListNode even = head.next;
ListNode evenHead = even;
// 遍历链表,重排节点
while (even != null && even.next != null) {
odd.next = even.next;
odd = odd.next;
even.next = odd.next;
even = even.next;
}
// 将奇数链表的末尾连接到偶数链表头部
odd.next = evenHead;
return head;
}
public static void main(String[] args) {
// 测试用例 1
ListNode head1 = new ListNode(1);
head1.next = new ListNode(2);
head1.next.next = new ListNode(3);
head1.next.next.next = new ListNode(4);
head1.next.next.next.next = new ListNode(5);
OddEvenList solution = new OddEvenList();
ListNode result1 = solution.oddEvenList(head1);
printList(result1); // 输出应为: 1 -> 3 -> 5 -> 2 -> 4
// 测试用例 2
ListNode head2 = new ListNode(2);
head2.next = new ListNode(1);
head2.next.next = new ListNode(3);
head2.next.next.next = new ListNode(5);
head2.next.next.next.next = new ListNode(6);
head2.next.next.next.next.next = new ListNode(4);
head2.next.next.next.next.next.next = new ListNode(7);
ListNode result2 = solution.oddEvenList(head2);
printList(result2); // 输出应为: 2 -> 3 -> 6 -> 7 -> 1 -> 5 -> 4
}
// 辅助函数,用于打印链表
public static void printList(ListNode head) {
ListNode current = head;
while (current != null) {
System.out.print(current.val);
if (current.next != null) {
System.out.print(" -> ");
}
current = current.next;
}
System.out.println();
}
}
31.反转链表(简单)
题目描述
给你单链表的头节点
head,请你反转链表,并返回反转后的链表。示例 1:
输入:head = [1,2,3,4,5] 输出:[5,4,3,2,1]示例 2:
输入:head = [1,2] 输出:[2,1]示例 3:输入:head = [] 输出:[]
提示:
- 链表中节点的数目范围是
[0, 5000]-5000 <= Node.val <= 5000进阶:链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?

解题思路
反转单链表是一道经典的链表操作题目。可以使用两种主要的方法来实现:迭代和递归。
1. 迭代方法思路
- 使用三个指针来反转链表:
prev(前一个节点),curr(当前节点),和next(下一个节点)。 - 遍历链表,将当前节点的
next指针指向前一个节点,更新prev和curr指针,直到遍历完成。
2. 递归方法思路
- 递归处理链表的尾部,并将每个节点的
next指针指向当前节点,从而实现反转。 - 基本的递归策略是:反转链表的其余部分,然后将当前节点追加到反转链表的尾部。
复杂度分析
1. 迭代方法复杂度
- 时间复杂度: O(n)O(n)O(n),其中 nnn 是链表的节点数,每个节点仅遍历一次。
- 空间复杂度: O(1)O(1)O(1),仅使用常量级别的额外空间。
2. 递归方法思路复杂度
- 时间复杂度: O(n)O(n)O(n),其中 nnn 是链表的节点数,每个节点仅处理一次。
- 空间复杂度: O(n)O(n)O(n),递归调用栈的空间复杂度为 O(n)O(n)O(n)。
代码实现
package org.zyf.javabasic.letcode.hot100.list;
import org.zyf.javabasic.letcode.list.base.ListNode;
/**
* @program: zyfboot-javabasic
* @description: 反转链表
* @author: zhangyanfeng
* @create: 2024-08-21 23:54
**/
public class ReverseListSolution {
public ListNode reverseList1(ListNode head) {
ListNode prev = null; // 前一个节点
ListNode curr = head; // 当前节点
while (curr != null) {
ListNode next = curr.next; // 保存下一个节点
curr.next = prev; // 反转当前节点的指针
prev = curr; // 更新前一个节点
curr = next; // 移动到下一个节点
}
return prev; // 返回新头节点
}
public ListNode reverseList2(ListNode head) {
// 递归基准条件:链表为空或只有一个节点
if (head == null || head.next == null) {
return head;
}
// 递归反转链表的剩余部分
ListNode newHead = reverseList2(head.next);
// 反转当前节点和下一个节点
head.next.next = head;
head.next = null;
return newHead; // 返回新的头节点
}
public static void main(String[] args) {
ReverseListSolution solution = new ReverseListSolution();
// 测试用例 1: 普通链表
System.out.println("Test Case 1: [1, 2, 3, 4, 5]");
ListNode head1 = new ListNode(1);
head1.next = new ListNode(2);
head1.next.next = new ListNode(3);
head1.next.next.next = new ListNode(4);
head1.next.next.next.next = new ListNode(5);
ListNode result1 = solution.reverseList1(head1);
printList(result1);
// 测试用例 2: 两个节点的链表
System.out.println("Test Case 2: [1, 2]");
ListNode head2 = new ListNode(1);
head2.next = new ListNode(2);
ListNode result2 = solution.reverseList1(head2);
printList(result2);
// 测试用例 3: 空链表
System.out.println("Test Case 3: []");
ListNode head3 = null;
ListNode result3 = solution.reverseList2(head3);
printList(result3);
// 测试用例 4: 单节点链表
System.out.println("Test Case 4: [1]");
ListNode head4 = new ListNode(1);
ListNode result4 = solution.reverseList2(head4);
printList(result4);
}
// 打印链表的方法
public static void printList(ListNode head) {
if (head == null) {
System.out.println("null");
return;
}
ListNode curr = head;
while (curr != null) {
System.out.print(curr.val + " ");
curr = curr.next;
}
System.out.println();
}
}
32.链表最大孪生和(中等)
题目描述
在一个大小为
n且n为 偶数 的链表中,对于0 <= i <= (n / 2) - 1的i,第i个节点(下标从 0 开始)的孪生节点为第(n-1-i)个节点 。
- 比方说,
n = 4那么节点0是节点3的孪生节点,节点1是节点2的孪生节点。这是长度为n = 4的链表中所有的孪生节点。孪生和 定义为一个节点和它孪生节点两者值之和。
给你一个长度为偶数的链表的头节点
head,请你返回链表的 最大孪生和 。示例 1:
输入:head = [5,4,2,1] 输出:6 解释: 节点 0 和节点 1 分别是节点 3 和 2 的孪生节点。孪生和都为 6 。 链表中没有其他孪生节点。 所以,链表的最大孪生和是 6 。示例 2:
输入:head = [4,2,2,3] 输出:7 解释: 链表中的孪生节点为: - 节点 0 是节点 3 的孪生节点,孪生和为 4 + 3 = 7 。 - 节点 1 是节点 2 的孪生节点,孪生和为 2 + 2 = 4 。 所以,最大孪生和为 max(7, 4) = 7 。示例 3:
输入:head = [1,100000] 输出:100001 解释: 链表中只有一对孪生节点,孪生和为 1 + 100000 = 100001 。提示:
- 链表的节点数目是
[2, 105]中的 偶数 。1 <= Node.val <= 105


解题思路
我们需要找到链表的最大孪生和,这意味着要计算链表中每一对孪生节点的和,然后找出其中的最大值。孪生节点是链表中一个从头开始的节点和一个从尾部开始的节点。
-
使用快慢指针找到链表的中点:使用快慢指针法找到链表的中点。这将帮助我们将链表分成两半。
-
反转链表的后半部分:为了便于计算孪生和,我们需要反转链表的后半部分。
-
计算孪生和:遍历前半部分和反转后的后半部分,计算对应节点的和,并更新最大孪生和。
-
返回最大孪生和。
复杂度分析
时间复杂度:O(n)
- 找到链表的中点需要 O(n) 时间。
- 反转链表的后半部分需要 O(n) 时间。
- 遍历链表来计算孪生和也需要 O(n) 时间。
空间复杂度:O(1)
- 只使用了几个额外的指针变量,没有使用额外的空间。
代码实现
package org.zyf.javabasic.letcode.featured75.list;
import org.zyf.javabasic.letcode.list.base.ListNode;
/**
* @program: zyfboot-javabasic
* @description: 链表最大孪生和
* @author: zhangyanfeng
* @create: 2024-08-24 09:56
**/
public class PairSum {
public int pairSum(ListNode head) {
// 快慢指针找到链表的中点
ListNode slow = head, fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
// 反转链表的后半部分
ListNode prev = null;
while (slow != null) {
ListNode next = slow.next;
slow.next = prev;
prev = slow;
slow = next;
}
// 计算孪生和的最大值
int maxSum = 0;
ListNode start = head;
while (prev != null) {
maxSum = Math.max(maxSum, start.val + prev.val);
start = start.next;
prev = prev.next;
}
return maxSum;
}
public static void main(String[] args) {
// 示例1
ListNode head1 = new ListNode(5);
head1.next = new ListNode(4);
head1.next.next = new ListNode(2);
head1.next.next.next = new ListNode(1);
PairSum solution = new PairSum();
System.out.println(solution.pairSum(head1)); // 输出应为 6
// 示例2
ListNode head2 = new ListNode(4);
head2.next = new ListNode(2);
head2.next.next = new ListNode(2);
head2.next.next.next = new ListNode(3);
System.out.println(solution.pairSum(head2)); // 输出应为 7
// 示例3
ListNode head3 = new ListNode(1);
head3.next = new ListNode(100000);
System.out.println(solution.pairSum(head3)); // 输出应为 100001
}
}
九、二叉树 - 深度优先搜索
33.二叉树的最大深度(简单)
题目描述
给定一个二叉树
root,返回其最大深度。二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
示例 1:
输入:root = [3,9,20,null,null,15,7] 输出:3示例 2:输入:root = [1,null,2] 输出:2
提示:
- 树中节点的数量在
[0, 104]区间内。-100 <= Node.val <= 100

解题思路
递归方法较为简洁直观。它的基本思想是:
- 对于每个节点,最大深度是其左子树和右子树深度的最大值加上 1。
- 基础情况是,如果节点为空,则深度为 0。
代码实现
package org.zyf.javabasic.letcode.hot100.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
/**
* @program: zyfboot-javabasic
* @description: 二叉树的最大深度(简单)
* @author: zhangyanfeng
* @create: 2024-08-22 10:51
**/
public class MaxDepthSolution {
// 递归计算二叉树的最大深度
public int maxDepth(TreeNode root) {
if (root == null) {
return 0;
}
// 计算左右子树的深度
int leftDepth = maxDepth(root.left);
int rightDepth = maxDepth(root.right);
// 返回较大深度加上根节点本身
return Math.max(leftDepth, rightDepth) + 1;
}
// 测试主函数
public static void main(String[] args) {
// 构造测试用例
TreeNode root1 = new TreeNode(3);
root1.left = new TreeNode(9);
root1.right = new TreeNode(20);
root1.right.left = new TreeNode(15);
root1.right.right = new TreeNode(7);
TreeNode root2 = new TreeNode(1);
root2.right = new TreeNode(2);
// 创建 Solution 实例并进行测试
MaxDepthSolution solution = new MaxDepthSolution();
int depth1 = solution.maxDepth(root1);
int depth2 = solution.maxDepth(root2);
// 打印结果
System.out.println(depth1); // 输出应为 3
System.out.println(depth2); // 输出应为 2
}
}
34.叶子相似的树(简单)
题目描述
请考虑一棵二叉树上所有的叶子,这些叶子的值按从左到右的顺序排列形成一个 叶值序列 。
举个例子,如上图所示,给定一棵叶值序列为
(6, 7, 4, 9, 8)的树。如果有两棵二叉树的叶值序列是相同,那么我们就认为它们是 叶相似 的。
如果给定的两个根结点分别为
root1和root2的树是叶相似的,则返回true;否则返回false。示例 1:
输入:root1 = [3,5,1,6,2,9,8,null,null,7,4], root2 = [3,5,1,6,7,4,2,null,null,null,null,null,null,9,8] 输出:true示例 2:
输入:root1 = [1,2,3], root2 = [1,3,2] 输出:false提示:
- 给定的两棵树结点数在
[1, 200]范围内- 给定的两棵树上的值在
[0, 200]范围内


解题思路
要判断两棵二叉树是否叶相似,我们需要比较两棵树的叶节点值序列是否相同:
-
遍历二叉树找到叶节点:我们需要遍历二叉树,收集所有叶节点的值。叶节点是没有左右子节点的节点。
-
比较两棵树的叶节点值序列:一旦我们获得了两棵树的叶节点值序列,就可以直接比较这两个序列是否相同。
步骤
-
定义辅助函数
遍历过程中如果遇到叶节点,就将其值加入到结果列表中。getLeafValues:使用深度优先搜索(DFS)遍历二叉树并收集叶节点值。 -
比较两个叶节点序列:使用两个列表存储每棵树的叶节点值序列,然后比较这两个列表是否相等。
复杂度分析
时间复杂度
- 遍历二叉树:每个节点仅被访问一次,因此时间复杂度为 O(n)O(n)O(n),其中 nnn 是树中节点的数量。
- 比较两个列表:时间复杂度为 O(k)O(k)O(k),其中 kkk 是叶节点的数量(在最坏情况下是 n/2n/2n/2)。
空间复杂度
- 存储叶节点值:需要额外的空间来存储叶节点值,最坏情况下空间复杂度为 O(n)O(n)O(n)。
- 递归调用栈:最坏情况下深度为树的高度 O(h)O(h)O(h),其中 hhh 是树的高度。
代码实现
package org.zyf.javabasic.letcode.featured75.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
import java.util.ArrayList;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 叶子相似的树
* @author: zhangyanfeng
* @create: 2024-08-24 10:05
**/
public class LeafSimilar {
// 获取叶节点值的辅助函数
private void getLeafValues(TreeNode node, List<Integer> leafValues) {
if (node == null) {
return;
}
// 如果是叶节点,添加到结果列表
if (node.left == null && node.right == null) {
leafValues.add(node.val);
return;
}
// 递归遍历左右子树
getLeafValues(node.left, leafValues);
getLeafValues(node.right, leafValues);
}
public boolean leafSimilar(TreeNode root1, TreeNode root2) {
// 存储两棵树的叶节点值
List<Integer> leaves1 = new ArrayList<>();
List<Integer> leaves2 = new ArrayList<>();
// 获取两棵树的叶节点值
getLeafValues(root1, leaves1);
getLeafValues(root2, leaves2);
// 比较两个叶节点值序列
return leaves1.equals(leaves2);
}
public static void main(String[] args) {
// 示例 1
TreeNode root1 = new TreeNode(3,
new TreeNode(5,
new TreeNode(6),
new TreeNode(2,
new TreeNode(7),
new TreeNode(4))
),
new TreeNode(1,
new TreeNode(9),
new TreeNode(8))
);
TreeNode root2 = new TreeNode(3,
new TreeNode(5,
new TreeNode(6),
new TreeNode(7)),
new TreeNode(1,
new TreeNode(4),
new TreeNode(2,
new TreeNode(9),
new TreeNode(8)))
);
LeafSimilar solution = new LeafSimilar();
System.out.println(solution.leafSimilar(root1, root2)); // 输出应为 true
// 示例 2
TreeNode root3 = new TreeNode(1,
new TreeNode(2),
new TreeNode(3)
);
TreeNode root4 = new TreeNode(1,
new TreeNode(3),
new TreeNode(2)
);
System.out.println(solution.leafSimilar(root3, root4)); // 输出应为 false
}
}
35.统计二叉树中好节点的数目(中等)
题目描述
给你一棵根为
root的二叉树,请你返回二叉树中好节点的数目。「好节点」X 定义为:从根到该节点 X 所经过的节点中,没有任何节点的值大于 X 的值。
示例 1:
输入:root = [3,1,4,3,null,1,5] 输出:4 解释:图中蓝色节点为好节点。 根节点 (3) 永远是个好节点。 节点 4 -> (3,4) 是路径中的最大值。 节点 5 -> (3,4,5) 是路径中的最大值。 节点 3 -> (3,1,3) 是路径中的最大值。示例 2:
输入:root = [3,3,null,4,2] 输出:3 解释:节点 2 -> (3, 3, 2) 不是好节点,因为 "3" 比它大。示例 3:输入:root = [1] 输出:1 解释:根节点是好节点。
提示:
- 二叉树中节点数目范围是
[1, 10^5]。- 每个节点权值的范围是
[-10^4, 10^4]。
解题思路
要解决问题,即找出二叉树中“好节点”的数量,我们可以使用深度优先搜索(DFS)来遍历树,同时跟踪当前路径上的最大节点值。一个节点是“好节点”当且仅当它的值大于或等于路径上所有节点的最大值。
-
定义“好节点”的条件:一个节点 X 被认为是“好节点”,当且仅当从根节点到该节点 X 的路径上所有节点的值都不大于 X 的值。
-
遍历树并统计“好节点”:
- 使用深度优先搜索(DFS)遍历二叉树。
- 在每个节点访问时,检查该节点是否符合“好节点”的条件。
- 维护一个变量
maxValue记录当前路径上的最大值。
-
递归函数:
- 在递归函数中,传递当前路径上的最大值。
- 如果当前节点的值大于或等于
maxValue,则该节点是“好节点”。 - 更新
maxValue并递归地检查左右子树。
复杂度分析
时间复杂度
- 遍历二叉树:每个节点仅被访问一次,时间复杂度为 O(n)O(n)O(n),其中 nnn 是树中节点的数量。
空间复杂度
- 递归调用栈:树的高度为 hhh,最坏情况下为 O(h)O(h)O(h),其中 hhh 是树的高度。在平衡树中,空间复杂度为 O(logn)O(\log n)O(logn),在不平衡树中,空间复杂度为 O(n)O(n)O(n)。
- 额外空间:存储节点的计数,空间复杂度为 O(1)O(1)O(1)。
代码实现
package org.zyf.javabasic.letcode.featured75.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
/**
* @program: zyfboot-javabasic
* @description: 统计二叉树中好节点的数目
* @author: zhangyanfeng
* @create: 2024-08-24 10:13
**/
public class GoodNodes {
// 计数好节点的变量
private int goodNodeCount = 0;
// 主函数,调用递归函数进行遍历
public int goodNodes(TreeNode root) {
// 从根节点开始遍历,初始最大值为负无穷
dfs(root, Integer.MIN_VALUE);
return goodNodeCount;
}
// 深度优先搜索递归函数
private void dfs(TreeNode node, int maxValue) {
if (node == null) {
return;
}
// 如果当前节点值大于或等于路径上的最大值,更新计数器
if (node.val >= maxValue) {
goodNodeCount++;
}
// 更新当前路径的最大值
maxValue = Math.max(maxValue, node.val);
// 递归遍历左子树和右子树
dfs(node.left, maxValue);
dfs(node.right, maxValue);
}
public static void main(String[] args) {
// 示例 1
TreeNode root1 = new TreeNode(3,
new TreeNode(1),
new TreeNode(4,
new TreeNode(1),
new TreeNode(5))
);
GoodNodes solution = new GoodNodes();
System.out.println(solution.goodNodes(root1)); // 输出应为 4
// 示例 2
TreeNode root2 = new TreeNode(3,
new TreeNode(3,
new TreeNode(4),
null),
new TreeNode(2)
);
System.out.println(solution.goodNodes(root2)); // 输出应为 3
// 示例 3
TreeNode root3 = new TreeNode(1);
System.out.println(solution.goodNodes(root3)); // 输出应为 1
}
}
36.路径总和 III(中等)
题目描述
给定一个二叉树的根节点
root,和一个整数targetSum,求该二叉树里节点值之和等于targetSum的 路径 的数目。路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
示例 1:
输入:root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 8 输出:3 解释:和等于 8 的路径有 3 条,如图所示。示例 2:输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22 输出:3
提示:
- 二叉树的节点个数的范围是
[0,1000]-109 <= Node.val <= 109-1000 <= targetSum <= 1000

解题思路
-
定义前缀和:
- 使用哈希表
prefix存储从根节点到当前节点的路径和的前缀和及其出现次数。 prefix.getOrDefault(curr - targetSum, 0)用于计算当前路径和减去目标和的前缀和的出现次数,这个次数就是当前节点作为路径终点时的路径数。
- 使用哈希表
-
递归深度优先搜索(DFS):
- 在递归过程中,更新当前路径和
curr。 - 使用哈希表
prefix记录当前路径和的出现次数,并更新路径和的计数。 - 递归访问左子树和右子树。
- 递归结束后,恢复哈希表的状态,移除当前路径和的计数,以便继续处理其他路径。
- 在递归过程中,更新当前路径和
-
处理路径和:
- 每次访问一个节点时,检查当前路径和
curr减去targetSum的值是否在哈希表中出现过。如果出现,说明存在从某个祖先节点到当前节点的路径和等于targetSum。 - 通过累加满足条件的路径数,得到最终结果。
- 每次访问一个节点时,检查当前路径和
复杂度分析
-
时间复杂度:每个节点访问一次,哈希表的操作(插入、查找、删除)平均时间复杂度为
O(1)。因此,总时间复杂度是O(n),其中n是树的节点数。 -
空间复杂度:哈希表
prefix的空间复杂度为O(n),在最坏情况下,哈希表需要存储所有节点的路径和;递归调用栈的深度在最坏情况下为树的高度h,对平衡树而言,h为O(log n),对退化树(链状树)而言,h为O(n)。因此,总体空间复杂度是O(n)。
代码实现
package org.zyf.javabasic.letcode.hot100.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
import java.util.HashMap;
import java.util.Map;
/**
* @program: zyfboot-javabasic
* @description: 路径总和 III(中等)
* @author: zhangyanfeng
* @create: 2024-08-22 12:12
**/
public class PathSumSolution {
public int pathSum(TreeNode root, int targetSum) {
// 哈希表存储前缀和及其出现次数
Map<Long, Integer> prefix = new HashMap<>();
// 初始前缀和为0,出现次数为1
prefix.put(0L, 1);
// 进行深度优先搜索
return dfs(root, prefix, 0, targetSum);
}
private int dfs(TreeNode node, Map<Long, Integer> prefix, long curr, int targetSum) {
if (node == null) {
return 0;
}
int result = 0;
// 更新当前路径和
curr += node.val;
// 当前路径和减去目标和的前缀和出现次数
result = prefix.getOrDefault(curr - targetSum, 0);
// 更新前缀和出现次数
prefix.put(curr, prefix.getOrDefault(curr, 0) + 1);
// 递归访问左子树和右子树
result += dfs(node.left, prefix, curr, targetSum);
result += dfs(node.right, prefix, curr, targetSum);
// 恢复哈希表状态
prefix.put(curr, prefix.getOrDefault(curr, 0) - 1);
return result;
}
public static void main(String[] args) {
// 构造测试用例1
TreeNode root1 = new TreeNode(10);
root1.left = new TreeNode(5);
root1.right = new TreeNode(-3);
root1.left.left = new TreeNode(3);
root1.left.right = new TreeNode(2);
root1.right.right = new TreeNode(11);
root1.left.left.left = new TreeNode(3);
root1.left.left.right = new TreeNode(-2);
root1.left.right.right = new TreeNode(1);
PathSumSolution solution = new PathSumSolution();
int result1 = solution.pathSum(root1, 8);
System.out.println("Test Case 1 Result: " + result1); // Expected output: 3
// 构造测试用例2
TreeNode root2 = new TreeNode(5);
root2.left = new TreeNode(4);
root2.right = new TreeNode(8);
root2.left.left = new TreeNode(11);
root2.right.left = new TreeNode(13);
root2.right.right = new TreeNode(4);
root2.left.left.left = new TreeNode(7);
root2.left.left.right = new TreeNode(2);
root2.right.right.right = new TreeNode(1);
int result2 = solution.pathSum(root2, 22);
System.out.println("Test Case 2 Result: " + result2); // Expected output: 3
}
}
37.二叉树中的最长交错路径(中等)
题目描述
给你一棵以
root为根的二叉树,二叉树中的交错路径定义如下:
- 选择二叉树中 任意 节点和一个方向(左或者右)。
- 如果前进方向为右,那么移动到当前节点的的右子节点,否则移动到它的左子节点。
- 改变前进方向:左变右或者右变左。
- 重复第二步和第三步,直到你在树中无法继续移动。
交错路径的长度定义为:访问过的节点数目 - 1(单个节点的路径长度为 0 )。
请你返回给定树中最长 交错路径 的长度。
示例 1:
输入:root = [1,null,1,1,1,null,null,1,1,null,1,null,null,null,1,null,1] 输出:3 解释:蓝色节点为树中最长交错路径(右 -> 左 -> 右)。示例 2:
输入:root = [1,1,1,null,1,null,null,1,1,null,1] 输出:4 解释:蓝色节点为树中最长交错路径(左 -> 右 -> 左 -> 右)。示例 3:输入:root = [1] 输出:0
提示:
- 每棵树最多有
50000个节点。- 每个节点的值在
[1, 100]之间。
解题思路
基于广度优先搜索(BFS),通过记录从每个节点出发的最长交错路径来解决问题:
-
定义状态:
f[u]:从节点u向左方向出发的最长交错路径的长度;g[u]:从节点u向右方向出发的最长交错路径的长度。 -
广度优先搜索(BFS):
- 使用队列
q来进行广度优先遍历。队列中保存每个节点及其父节点。 - 对每个节点,根据其父节点的方向更新当前节点的
f和g值。 - 如果当前节点是其父节点的左子节点,则从右方向的路径
g更新到当前节点的左方向路径f,反之亦然。
- 使用队列
-
初始化:使用
f和g两个哈希表来记录每个节点的状态;从根节点开始,初始化队列。 -
遍历所有节点:计算每个节点的
f和g值,并更新最长交错路径长度maxAns。
复杂度分析
- 时间复杂度:
O(n),其中n是树中节点的数量。每个节点被处理一次,因此复杂度为线性。 - 空间复杂度:
O(n),需要额外的哈希表和队列来存储节点的状态和队列的元素。
代码实现
package org.zyf.javabasic.letcode.featured75.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.Map;
import java.util.Queue;
/**
* @program: zyfboot-javabasic
* @description: 二叉树中的最长交错路径
* @author: zhangyanfeng
* @create: 2024-08-24 10:21
**/
public class LongestZigZag {
// f[u] 记录从节点 u 向左的最长交错路径长度
// g[u] 记录从节点 u 向右的最长交错路径长度
Map<TreeNode, Integer> f = new HashMap<>();
Map<TreeNode, Integer> g = new HashMap<>();
// 队列用于广度优先遍历
Queue<TreeNode[]> q = new LinkedList<>();
public int longestZigZag(TreeNode root) {
// 初始化树的状态
dp(root);
int maxAns = 0;
// 遍历所有节点,找到最长交错路径
for (TreeNode u : f.keySet()) {
maxAns = Math.max(maxAns, Math.max(f.get(u), g.get(u)));
}
return maxAns;
}
public void dp(TreeNode o) {
// 初始化状态
f.put(o, 0);
g.put(o, 0);
// 根节点入队
q.offer(new TreeNode[]{o, null});
while (!q.isEmpty()) {
TreeNode[] y = q.poll();
TreeNode u = y[0], x = y[1];
// 初始化当前节点的状态
f.put(u, 0);
g.put(u, 0);
// 更新状态
if (x != null) {
if (x.left == u) {
// 如果当前节点是其父节点的左子节点,更新 f[u]
f.put(u, g.get(x) + 1);
}
if (x.right == u) {
// 如果当前节点是其父节点的右子节点,更新 g[u]
g.put(u, f.get(x) + 1);
}
}
// 左子节点入队
if (u.left != null) {
q.offer(new TreeNode[]{u.left, u});
}
// 右子节点入队
if (u.right != null) {
q.offer(new TreeNode[]{u.right, u});
}
}
}
public static void main(String[] args) {
// 示例 1
TreeNode root1 = new TreeNode(1,
null,
new TreeNode(1,
new TreeNode(1,
new TreeNode(1),
new TreeNode(1)),
null)
);
LongestZigZag solution = new LongestZigZag();
System.out.println(solution.longestZigZag(root1)); // 输出应为 3
}
}
38.二叉树的最近公共祖先(中等)
题目描述
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
示例 1:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出:3 解释:节点 5 和节点 1 的最近公共祖先是节点 3 。示例 2:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出:5 解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。示例 3:输入:root = [1,2], p = 1, q = 2 输出:1
提示:
- 树中节点数目在范围
[2, 105]内。-109 <= Node.val <= 109- 所有
Node.val互不相同。p != qp和q均存在于给定的二叉树中。


解题思路
要找到二叉树中两个指定节点的最近公共祖先(LCA),可以通过递归算法实现。我们将利用递归来查找左右子树的最近公共祖先,并根据节点的情况决定返回的结果。
-
递归遍历:
对于每个节点,递归地查找其左右子树中是否存在节点p和q;如果在当前节点的左子树中找到了p或q,并且在右子树中也找到了另外一个节点,那么当前节点就是p和q的最近公共祖先;如果在某一侧的子树中找到了p或q,而另一侧子树没有找到,则返回找到的节点。 -
返回条件:
当节点为空时(递归到叶子节点),返回null;当节点等于p或q时,返回该节点本身;合并左右子树的结果来确定当前节点是否为 LCA。
复杂度分析
- 时间复杂度:
O(N),其中N是树中节点的数量。每个节点在递归中被访问一次。 - 空间复杂度:
O(H),其中H是树的高度。递归调用栈的深度与树的高度成正比。对于平衡树,空间复杂度为O(log N);对于不平衡树,空间复杂度为O(N)。
代码实现
package org.zyf.javabasic.letcode.hot100.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
/**
* @program: zyfboot-javabasic
* @description: 二叉树的最近公共祖先(中等)
* @author: zhangyanfeng
* @create: 2024-08-22 12:18
**/
public class LowestCommonAncestorSolution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
// 递归终止条件:如果当前节点为空或等于 p 或 q,直接返回当前节点
if (root == null || root == p || root == q) {
return root;
}
// 递归查找左子树
TreeNode left = lowestCommonAncestor(root.left, p, q);
// 递归查找右子树
TreeNode right = lowestCommonAncestor(root.right, p, q);
// 如果左子树和右子树都找到了 p 或 q,那么当前节点是 LCA
if (left != null && right != null) {
return root;
}
// 如果左子树找到了 p 或 q,则返回左子树的结果,否则返回右子树的结果
return left != null ? left : right;
}
public static void main(String[] args) {
// 构造测试用例1
TreeNode root1 = new TreeNode(3);
root1.left = new TreeNode(5);
root1.right = new TreeNode(1);
root1.left.left = new TreeNode(6);
root1.left.right = new TreeNode(2);
root1.right.left = new TreeNode(0);
root1.right.right = new TreeNode(8);
root1.left.right.left = new TreeNode(7);
root1.left.right.right = new TreeNode(4);
LowestCommonAncestorSolution solution = new LowestCommonAncestorSolution();
TreeNode p1 = root1.left; // Node 5
TreeNode q1 = root1.right; // Node 1
TreeNode result1 = solution.lowestCommonAncestor(root1, p1, q1);
System.out.println("Test Case 1 Result: " + result1.val); // Expected output: 3
// 构造测试用例2
TreeNode root2 = new TreeNode(3);
root2.left = new TreeNode(5);
root2.right = new TreeNode(1);
root2.left.left = new TreeNode(6);
root2.left.right = new TreeNode(2);
root2.right.left = new TreeNode(0);
root2.right.right = new TreeNode(8);
root2.left.right.left = new TreeNode(7);
root2.left.right.right = new TreeNode(4);
TreeNode p2 = root2.left; // Node 5
TreeNode q2 = root2.left.right.right; // Node 4
TreeNode result2 = solution.lowestCommonAncestor(root2, p2, q2);
System.out.println("Test Case 2 Result: " + result2.val); // Expected output: 5
// 构造测试用例3
TreeNode root3 = new TreeNode(1);
root3.left = new TreeNode(2);
LowestCommonAncestorSolution solution3 = new LowestCommonAncestorSolution();
TreeNode p3 = root3; // Node 1
TreeNode q3 = root3.left; // Node 2
TreeNode result3 = solution3.lowestCommonAncestor(root3, p3, q3);
System.out.println("Test Case 3 Result: " + result3.val); // Expected output: 1
}
}
十、二叉树 - 广度优先搜索
39.二叉树的右视图(中等)
题目描述
给定一个二叉树的 根节点
root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。示例 1:
输入: [1,2,3,null,5,null,4] 输出: [1,3,4]示例 2:输入: [1,null,3] 输出: [1,3]
示例 3:输入: [] 输出: []
提示:
- 二叉树的节点个数的范围是
[0,100]-100 <= Node.val <= 100
解题思路
要从二叉树的右侧查看并返回节点值,我们可以使用层序遍历(广度优先遍历)来实现。具体来说,我们需要从右侧依次访问每一层的节点,并从每一层的最右侧节点开始返回结果。
-
层序遍历:
使用一个队列来实现层序遍历;遍历每一层的节点时,记录每层的最后一个节点值,因为它代表了从右侧可以看到的节点;将每一层的节点值添加到结果列表中。 -
实现步骤:
- 初始化一个队列,将根节点加入队列。
- 对于每一层,记录层的节点数(即队列的当前大小)。
- 遍历该层的所有节点,并更新队列(将当前节点的左子节点和右子节点加入队列)。
- 记录每层最后一个节点的值(即右侧可见节点)。
- 返回结果列表。
复杂度分析
- 时间复杂度:
O(n),其中n是树中的节点数。每个节点被访问一次。 - 空间复杂度:
O(w),其中w是树的最大宽度(即队列中最大的元素数)。在最坏的情况下,队列的大小等于树的最大宽度。
代码实现
package org.zyf.javabasic.letcode.hot100.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
/**
* @program: zyfboot-javabasic
* @description: 二叉树的右视图(中等)
* @author: zhangyanfeng
* @create: 2024-08-22 11:53
**/
public class RightSideViewSolution {
public List<Integer> rightSideView(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null) {
return result;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
int levelSize = queue.size();
Integer rightMostValue = null;
for (int i = 0; i < levelSize; i++) {
TreeNode node = queue.poll();
rightMostValue = node.val;
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
result.add(rightMostValue);
}
return result;
}
public static void main(String[] args) {
RightSideViewSolution solution = new RightSideViewSolution();
// Example 1
TreeNode root1 = new TreeNode(1);
root1.left = new TreeNode(2);
root1.right = new TreeNode(3);
root1.left.right = new TreeNode(5);
root1.right.right = new TreeNode(4);
System.out.println(solution.rightSideView(root1)); // Output: [1, 3, 4]
// Example 2
TreeNode root2 = new TreeNode(1);
root2.right = new TreeNode(3);
System.out.println(solution.rightSideView(root2)); // Output: [1, 3]
// Example 3
TreeNode root3 = null;
System.out.println(solution.rightSideView(root3)); // Output: []
}
}
40.最大层内元素和(中等)
题目描述
给你一个二叉树的根节点
root。设根节点位于二叉树的第1层,而根节点的子节点位于第2层,依此类推。请返回层内元素之和 最大 的那几层(可能只有一层)的层号,并返回其中 最小 的那个。
示例 1:
输入:root = [1,7,0,7,-8,null,null] 输出:2 解释: 第 1 层各元素之和为 1, 第 2 层各元素之和为 7 + 0 = 7, 第 3 层各元素之和为 7 + -8 = -1, 所以我们返回第 2 层的层号,它的层内元素之和最大。示例 2:输入:root = [989,null,10250,98693,-89388,null,null,null,-32127] 输出:2
提示:
- 树中的节点数在
[1, 104]范围内-105 <= Node.val <= 105
解题思路
为了找出二叉树中层内元素之和最大的层,并返回其中最小的层号,可以采用层次遍历(广度优先搜索,BFS)来解决这个问题:
-
层次遍历(BFS):使用一个队列来存储每一层的节点。队列的节点包括当前节点及其层级信息;遍历每一层的所有节点,计算该层节点值的和;记录每一层的和,并跟踪最大和及其对应的层号。
-
记录层内元素之和:在遍历每一层时,计算当前层的节点值的总和;更新最大和以及相应的层号。
-
返回结果:遍历完所有层后,返回最大和的最小层号。
复杂度分析
- 时间复杂度:
O(n),其中n是树中节点的数量。每个节点被访问一次,复杂度为线性。 - 空间复杂度:
O(m),其中m是树的宽度。在最坏情况下,队列中可能存储一层的所有节点,即宽度m。
代码实现
package org.zyf.javabasic.letcode.featured75.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
import java.util.LinkedList;
import java.util.Queue;
/**
* @program: zyfboot-javabasic
* @description: 最大层内元素和
* @author: zhangyanfeng
* @create: 2024-08-24 10:58
**/
public class MaxLevelSum {
public int maxLevelSum(TreeNode root) {
if (root == null) return 0;
// 队列用于层次遍历,存储每一层的节点
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int level = 0;
int maxSum = Integer.MIN_VALUE; // 最大和初始化为负无穷
int minLevel = 0; // 记录最大和的最小层号
while (!queue.isEmpty()) {
level++;
int levelSize = queue.size();
int levelSum = 0;
// 计算当前层的节点和
for (int i = 0; i < levelSize; i++) {
TreeNode node = queue.poll();
levelSum += node.val;
// 添加下一层的节点到队列
if (node.left != null) queue.offer(node.left);
if (node.right != null) queue.offer(node.right);
}
// 更新最大和及其对应的层号
if (levelSum > maxSum) {
maxSum = levelSum;
minLevel = level;
}
}
return minLevel;
}
// 主函数用于测试
public static void main(String[] args) {
MaxLevelSum solution = new MaxLevelSum();
// 示例 1
TreeNode root1 = new TreeNode(1,
new TreeNode(7,
new TreeNode(7),
new TreeNode(-8)
),
new TreeNode(0)
);
System.out.println(solution.maxLevelSum(root1)); // 输出: 2
// 示例 2
TreeNode root2 = new TreeNode(989,
null,
new TreeNode(10250,
new TreeNode(98693),
new TreeNode(-89388)
)
);
System.out.println(solution.maxLevelSum(root2)); // 输出: 2
// 示例 3
TreeNode root3 = new TreeNode(1);
System.out.println(solution.maxLevelSum(root3)); // 输出: 1
// 自定义测试用例
TreeNode root4 = new TreeNode(1,
new TreeNode(2,
new TreeNode(4),
new TreeNode(5)
),
new TreeNode(3,
new TreeNode(6),
null
)
);
System.out.println(solution.maxLevelSum(root4)); // 输出: 2 (层次和分别为 1, 5, 11)
TreeNode root5 = new TreeNode(10,
new TreeNode(-5,
new TreeNode(1),
new TreeNode(2)
),
new TreeNode(15,
null,
new TreeNode(8)
)
);
System.out.println(solution.maxLevelSum(root5)); // 输出: 2 (层次和分别为 10, 10, 11)
}
}
十一、二叉搜索树
41.二叉搜索树中的搜索(简单)
题目描述
给定二叉搜索树(BST)的根节点
root和一个整数值val。你需要在 BST 中找到节点值等于
val的节点。 返回以该节点为根的子树。 如果节点不存在,则返回null。示例 1:
输入:root = [4,2,7,1,3], val = 2 输出:[2,1,3]示例 2:
输入:root = [4,2,7,1,3], val = 5 输出:[]提示:
- 树中节点数在
[1, 5000]范围内1 <= Node.val <= 107root是二叉搜索树1 <= val <= 107

解题思路
为了在二叉搜索树(BST)中找到指定值 val 对应的节点,并返回以该节点为根的子树,我们可以利用 BST 的性质来实现高效查找。BST 的性质保证了在树中每个节点的左子树上的值都小于节点值,右子树上的值都大于节点值。 利用 BST 的性质:
- 从根节点开始遍历树。
- 如果当前节点的值等于
val,直接返回当前节点,因为当前节点就是目标节点,其子树即为所需。 - 如果
val小于当前节点的值,则继续在左子树中查找。 - 如果
val大于当前节点的值,则继续在右子树中查找。 - 如果遍历到空节点,说明树中没有该值,返回
null。
复杂度分析
- 时间复杂度:
O(h),其中h是树的高度。最坏情况下,需要遍历整棵树的高度,树的高度h最多为log(n),其中n是节点的数量(对于平衡树),在最坏情况下可以是n(对于退化成链表的树)。 - 空间复杂度:
O(h),由于递归调用栈的深度等于树的高度。
代码实现
package org.zyf.javabasic.letcode.featured75.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
/**
* @program: zyfboot-javabasic
* @description: 二叉搜索树中的搜索
* @author: zhangyanfeng
* @create: 2024-08-24 11:04
**/
public class SearchBST {
public TreeNode searchBST(TreeNode root, int val) {
// 从根节点开始查找
if (root == null) return null; // 根节点为空,返回 null
if (root.val == val) {
return root; // 找到值为 val 的节点,返回该节点及其子树
} else if (val < root.val) {
return searchBST(root.left, val); // 在左子树中继续查找
} else {
return searchBST(root.right, val); // 在右子树中继续查找
}
}
// 主函数用于测试
public static void main(String[] args) {
SearchBST solution = new SearchBST();
// 示例 1
TreeNode root1 = new TreeNode(4,
new TreeNode(2,
new TreeNode(1),
new TreeNode(3)
),
new TreeNode(7)
);
TreeNode result1 = solution.searchBST(root1, 2);
printTree(result1); // 输出: 2 1 3
// 示例 2
TreeNode root2 = new TreeNode(4,
new TreeNode(2,
new TreeNode(1),
new TreeNode(3)
),
new TreeNode(7)
);
TreeNode result2 = solution.searchBST(root2, 5);
printTree(result2); // 输出: []
// 自定义测试用例
TreeNode root3 = new TreeNode(10,
new TreeNode(5,
new TreeNode(3),
new TreeNode(7)
),
new TreeNode(15)
);
TreeNode result3 = solution.searchBST(root3, 7);
printTree(result3); // 输出: 7
}
// 打印树节点的辅助函数
public static void printTree(TreeNode root) {
if (root == null) {
System.out.println("[]");
return;
}
List<Integer> result = new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
if (node != null) {
result.add(node.val);
queue.offer(node.left);
queue.offer(node.right);
}
}
System.out.println(result);
}
}
42.删除二叉搜索树中的节点(中等)
题目描述
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
一般来说,删除节点可分为两个步骤:
- 首先找到需要删除的节点;
- 如果找到了,删除它。
示例 1:
输入:root = [5,3,6,2,4,null,7], key = 3 输出:[5,4,6,2,null,null,7] 解释:给定需要删除的节点值是 3,所以我们首先找到 3 这个节点,然后删除它。 一个正确的答案是 [5,4,6,2,null,null,7], 如下图所示。 另一个正确答案是 [5,2,6,null,4,null,7]。
示例 2:输入: root = [5,3,6,2,4,null,7], key = 0 输出: [5,3,6,2,4,null,7] 解释: 二叉树不包含值为 0 的节点
示例 3:输入: root = [], key = 0 输出: []
提示:
- 节点数的范围
[0, 104].-105 <= Node.val <= 105- 节点值唯一
root是合法的二叉搜索树-105 <= key <= 105进阶: 要求算法时间复杂度为 O(h),h 为树的高度。

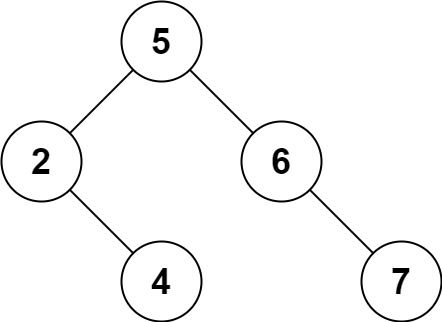
解题思路
要从二叉搜索树(BST)中删除一个节点并保持BST的性质不变,我们需要遵循以下步骤:
-
查找节点:
由于BST的性质,我们可以通过比较key与当前节点的值来决定是向左子树还是右子树递归查找;如果当前节点的值等于key,我们需要删除该节点。 -
删除节点:
- 节点没有子节点:直接将其删除,返回
null。 - 节点有一个子节点:将其父节点的相应子节点指针指向该节点的唯一子节点。
- 节点有两个子节点:
- 找到节点的右子树中的最小值节点(即中序遍历中节点的下一个节点),用这个节点的值替换当前节点的值。
- 删除右子树中最小值节点的原位置。
- 节点没有子节点:直接将其删除,返回
复杂度分析
- 时间复杂度:
O(h),其中h是树的高度。因为在BST中查找和删除节点的操作的时间复杂度与树的高度成正比。 - 空间复杂度:
O(h),由于递归调用栈的深度等于树的高度。
代码实现
package org.zyf.javabasic.letcode.featured75.tree;
import org.zyf.javabasic.letcode.tree.base.TreeNode;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
/**
* @program: zyfboot-javabasic
* @description: 删除二叉搜索树中的节点
* @author: zhangyanfeng
* @create: 2024-08-24 11:10
**/
public class DeleteNode {
public TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return null; // 空树,直接返回 null
// 找到要删除的节点
if (key < root.val) {
root.left = deleteNode(root.left, key); // 在左子树中递归删除
} else if (key > root.val) {
root.right = deleteNode(root.right, key); // 在右子树中递归删除
} else {
// 找到要删除的节点
if (root.left == null) {
return root.right; // 节点没有左子树,返回右子树
} else if (root.right == null) {
return root.left; // 节点没有右子树,返回左子树
}
// 节点有两个子树
TreeNode minNode = getMin(root.right); // 找到右子树中的最小节点
root.val = minNode.val; // 用最小节点的值替换当前节点的值
root.right = deleteNode(root.right, minNode.val); // 删除右子树中的最小节点
}
return root; // 返回更新后的根节点
}
// 找到以 root 为根的树中的最小节点
private TreeNode getMin(TreeNode root) {
while (root.left != null) {
root = root.left;
}
return root;
}
// 主函数用于测试
public static void main(String[] args) {
DeleteNode solution = new DeleteNode();
// 示例 1
TreeNode root1 = new TreeNode(5,
new TreeNode(3,
new TreeNode(2),
new TreeNode(4)
),
new TreeNode(6, null, new TreeNode(7))
);
TreeNode result1 = solution.deleteNode(root1, 3);
printTree(result1); // 输出: [5, 4, 6, 2, null, null, 7]
// 示例 2
TreeNode root2 = new TreeNode(5,
new TreeNode(3,
new TreeNode(2),
new TreeNode(4)
),
new TreeNode(6, null, new TreeNode(7))
);
TreeNode result2 = solution.deleteNode(root2, 0);
printTree(result2); // 输出: [5, 3, 6, 2, 4, null, 7]
// 示例 3
TreeNode root3 = null;
TreeNode result3 = solution.deleteNode(root3, 0);
printTree(result3); // 输出: []
}
// 打印树节点的辅助函数
public static void printTree(TreeNode root) {
if (root == null) {
System.out.println("[]");
return;
}
List<Integer> result = new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
if (node != null) {
result.add(node.val);
queue.offer(node.left);
queue.offer(node.right);
}
}
System.out.println(result);
}
}
十二、图 - 深度优先搜索
43.钥匙和房间(中等)
题目描述
有
n个房间,房间按从0到n - 1编号。最初,除0号房间外的其余所有房间都被锁住。你的目标是进入所有的房间。然而,你不能在没有获得钥匙的时候进入锁住的房间。当你进入一个房间,你可能会在里面找到一套 不同的钥匙,每把钥匙上都有对应的房间号,即表示钥匙可以打开的房间。你可以拿上所有钥匙去解锁其他房间。
给你一个数组
rooms其中rooms[i]是你进入i号房间可以获得的钥匙集合。如果能进入 所有 房间返回true,否则返回false。示例 1:输入:rooms = [[1],[2],[3],[]] 输出:true 解释: 我们从 0 号房间开始,拿到钥匙 1。 之后我们去 1 号房间,拿到钥匙 2。 然后我们去 2 号房间,拿到钥匙 3。 最后我们去了 3 号房间。 由于我们能够进入每个房间,我们返回 true。
示例 2:输入:rooms = [[1,3],[3,0,1],[2],[0]] 输出:false 解释:我们不能进入 2 号房间。
提示:
n == rooms.length2 <= n <= 10000 <= rooms[i].length <= 10001 <= sum(rooms[i].length) <= 30000 <= rooms[i][j] < n- 所有
rooms[i]的值 互不相同
解题思路
要解决这个问题,我们可以将其视为图遍历的问题。每个房间代表图中的一个节点,房间中找到的钥匙代表从一个节点到另一个节点的边。我们需要检查是否可以从初始的房间(节点 0)出发,遍历所有的房间(节点)。
-
建图:每个房间表示图中的一个节点。房间中找到的钥匙表示从当前房间节点到其他房间节点的边。
-
图遍历:使用广度优先搜索(BFS)或深度优先搜索(DFS)来遍历图。从初始的房间(节点 0)开始,尝试访问所有可以通过钥匙解锁的房间。
-
检查访问情况:维护一个布尔数组
visited来记录每个房间是否被访问过。如果所有房间都被访问到,返回true,否则返回false。
复杂度分析
- 时间复杂度:
O(n + E),其中n是房间的数量,E是钥匙的数量。因为我们需要遍历每个房间及其钥匙。 - 空间复杂度:
O(n + E),用于存储图的结构以及访问状态。
代码实现
package org.zyf.javabasic.letcode.featured75.graph;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
/**
* @program: zyfboot-javabasic
* @description: 钥匙和房间
* @author: zhangyanfeng
* @create: 2024-08-24 11:18
**/
public class CanVisitAllRooms {
public boolean canVisitAllRooms(List<List<Integer>> rooms) {
int n = rooms.size();
boolean[] visited = new boolean[n]; // 记录每个房间是否被访问过
Queue<Integer> queue = new LinkedList<>(); // BFS 队列
queue.offer(0); // 从房间 0 开始
visited[0] = true; // 标记房间 0 为已访问
while (!queue.isEmpty()) {
int room = queue.poll(); // 取出当前房间
// 遍历当前房间能获得的钥匙
for (int key : rooms.get(room)) {
if (!visited[key]) { // 如果钥匙对应的房间未被访问
visited[key] = true; // 标记房间为已访问
queue.offer(key); // 将房间放入队列中
}
}
}
// 检查所有房间是否都被访问过
for (boolean roomVisited : visited) {
if (!roomVisited) {
return false; // 如果有未访问的房间,则返回 false
}
}
return true; // 所有房间都被访问过,返回 true
}
// 主函数用于测试
public static void main(String[] args) {
CanVisitAllRooms solution = new CanVisitAllRooms();
// 示例 1
List<List<Integer>> rooms1 = Arrays.asList(
Arrays.asList(1),
Arrays.asList(2),
Arrays.asList(3),
Arrays.asList()
);
System.out.println(solution.canVisitAllRooms(rooms1)); // 输出: true
// 示例 2
List<List<Integer>> rooms2 = Arrays.asList(
Arrays.asList(1, 3),
Arrays.asList(3, 0, 1),
Arrays.asList(2),
Arrays.asList(0)
);
System.out.println(solution.canVisitAllRooms(rooms2)); // 输出: false
}
}
44.省份数量(中等)
题目描述
有
n个城市,其中一些彼此相连,另一些没有相连。如果城市a与城市b直接相连,且城市b与城市c直接相连,那么城市a与城市c间接相连。省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个
n x n的矩阵isConnected,其中isConnected[i][j] = 1表示第i个城市和第j个城市直接相连,而isConnected[i][j] = 0表示二者不直接相连。返回矩阵中 省份 的数量。
示例 1:
输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]] 输出:2示例 2:
输入:isConnected = [[1,0,0],[0,1,0],[0,0,1]] 输出:3提示:
1 <= n <= 200n == isConnected.lengthn == isConnected[i].lengthisConnected[i][j]为1或0isConnected[i][i] == 1isConnected[i][j] == isConnected[j][i]

解题思路
要解决这个问题,我们需要找出给定城市之间的连通分量,即省份的数量。我们可以将其视为图的连通分量问题。每个城市是图中的一个节点,isConnected 矩阵中的 1 表示两个城市(节点)之间存在边(直接相连)。
-
图的表示:每个城市是图中的一个节点。矩阵中的
isConnected[i][j] = 1表示城市i与城市j直接相连。 -
图的遍历:我们可以使用深度优先搜索(DFS)或广度优先搜索(BFS)来遍历图,并找出所有的连通分量。从每个未访问的节点开始,使用 DFS 或 BFS 遍历所有与其连通的节点,并将这些节点标记为已访问。
-
省份计数:每次启动一个新的 DFS 或 BFS 代表发现了一个新的省份。统计启动 DFS 或 BFS 的次数就是省份的数量。
复杂度分析
- 时间复杂度:
O(n^2),因为在最坏情况下,我们需要检查n * n的矩阵。 - 空间复杂度:
O(n),用于存储访问状态和递归栈(如果使用 DFS)。
代码实现
package org.zyf.javabasic.letcode.featured75.graph;
/**
* @program: zyfboot-javabasic
* @description: 省份数量
* @author: zhangyanfeng
* @create: 2024-08-24 11:23
**/
public class FindCircleNum {
public int findCircleNum(int[][] isConnected) {
int n = isConnected.length;
boolean[] visited = new boolean[n]; // 记录每个城市是否被访问过
int provinces = 0; // 省份计数
for (int i = 0; i < n; i++) {
if (!visited[i]) { // 如果城市 i 未被访问
dfs(isConnected, visited, i); // 使用 DFS 遍历所有与城市 i 相连的城市
provinces++; // 发现一个新的省份
}
}
return provinces;
}
// 深度优先搜索
private void dfs(int[][] isConnected, boolean[] visited, int city) {
visited[city] = true; // 标记当前城市为已访问
for (int i = 0; i < isConnected.length; i++) {
if (isConnected[city][i] == 1 && !visited[i]) { // 如果城市 i 与当前城市直接相连且未被访问
dfs(isConnected, visited, i); // 递归访问城市 i
}
}
}
// 主函数用于测试
public static void main(String[] args) {
FindCircleNum solution = new FindCircleNum();
// 示例 1
int[][] isConnected1 = {
{1, 1, 0},
{1, 1, 0},
{0, 0, 1}
};
System.out.println(solution.findCircleNum(isConnected1)); // 输出: 2
// 示例 2
int[][] isConnected2 = {
{1, 0, 0},
{0, 1, 0},
{0, 0, 1}
};
System.out.println(solution.findCircleNum(isConnected2)); // 输出: 3
}
}
45.重新规划路线(中等)
题目描述
n座城市,从0到n-1编号,其间共有n-1条路线。因此,要想在两座不同城市之间旅行只有唯一一条路线可供选择(路线网形成一颗树)。去年,交通运输部决定重新规划路线,以改变交通拥堵的状况。路线用
connections表示,其中connections[i] = [a, b]表示从城市a到b的一条有向路线。今年,城市 0 将会举办一场大型比赛,很多游客都想前往城市 0 。
请你帮助重新规划路线方向,使每个城市都可以访问城市 0 。返回需要变更方向的最小路线数。
题目数据 保证 每个城市在重新规划路线方向后都能到达城市 0 。
示例 1:
输入:n = 6, connections = [[0,1],[1,3],[2,3],[4,0],[4,5]] 输出:3 解释:更改以红色显示的路线的方向,使每个城市都可以到达城市 0 。示例 2:
输入:n = 5, connections = [[1,0],[1,2],[3,2],[3,4]] 输出:2 解释:更改以红色显示的路线的方向,使每个城市都可以到达城市 0 。示例 3:输入:n = 3, connections = [[1,0],[2,0]] 输出:0
提示:
2 <= n <= 5 * 10^4connections.length == n-1connections[i].length == 20 <= connections[i][0], connections[i][1] <= n-1connections[i][0] != connections[i][1]
解题思路
为了确保每个城市都可以到达城市 0,我们需要重新规划一些路线的方向。由于城市之间的连接构成一颗树,我们可以将问题转化为有向图中的最小边反转问题。
-
建图:使用邻接表表示有向图。遍历给定的
connections,构建图的邻接表以及反向图的邻接表。 -
反向图:反向图用于标记哪些城市通过现有的边可以直接到达城市 0。
-
广度优先搜索(BFS):从城市 0 开始进行 BFS,遍历所有能够直接或间接到达城市 0 的城市。在遍历过程中,记录需要反转的边数。即从 BFS 遍历过程中发现的那些不在反向图邻接表中的边。
-
计算最小反转次数:遍历所有与城市 0 不相连的城市,统计需要反转的边数。
复杂度分析
- 时间复杂度:
O(n),因为我们遍历所有城市和边,每个边和城市最多处理一次。 - 空间复杂度:
O(n),用于存储图和反向图。
代码实现
package org.zyf.javabasic.letcode.featured75.graph;
import java.util.*;
/**
* @program: zyfboot-javabasic
* @description: 重新规划路线
* @author: zhangyanfeng
* @create: 2024-08-24 11:26
**/
public class MinReorder {
public int minReorder(int n, int[][] connections) {
// 建立邻接表和反向图
Map<Integer, Set<Integer>> graph = new HashMap<>();
Map<Integer, Set<Integer>> reverseGraph = new HashMap<>();
for (int i = 0; i < n; i++) {
graph.put(i, new HashSet<>());
reverseGraph.put(i, new HashSet<>());
}
for (int[] conn : connections) {
int u = conn[0];
int v = conn[1];
graph.get(u).add(v); // 记录原始方向
reverseGraph.get(v).add(u); // 记录反向图方向
}
// BFS 初始化
Queue<Integer> queue = new LinkedList<>();
Set<Integer> visited = new HashSet<>();
int changes = 0;
queue.add(0); // 从城市 0 开始
visited.add(0);
while (!queue.isEmpty()) {
int current = queue.poll();
// 遍历当前城市的所有邻接城市
for (int neighbor : graph.get(current)) {
if (!visited.contains(neighbor)) {
visited.add(neighbor);
queue.add(neighbor);
changes++; // 需要反转的边
}
}
// 遍历当前城市在反向图中的所有邻接城市
for (int neighbor : reverseGraph.get(current)) {
if (!visited.contains(neighbor)) {
visited.add(neighbor);
queue.add(neighbor);
}
}
}
return changes;
}
// 主函数用于测试
public static void main(String[] args) {
MinReorder solution = new MinReorder();
// 示例 1
int[][] connections1 = {
{0,1},{1,3},{2,3},{4,0},{4,5}
};
System.out.println(solution.minReorder(6, connections1)); // 输出: 3
// 示例 2
int[][] connections2 = {
{1,0},{1,2},{3,2},{3,4}
};
System.out.println(solution.minReorder(5, connections2)); // 输出: 2
// 示例 3
int[][] connections3 = {
{1,0},{2,0}
};
System.out.println(solution.minReorder(3, connections3)); // 输出: 0
}
}
46.除法求值(中等)
题目描述
给你一个变量对数组
equations和一个实数值数组values作为已知条件,其中equations[i] = [Ai, Bi]和values[i]共同表示等式Ai / Bi = values[i]。每个Ai或Bi是一个表示单个变量的字符串。另有一些以数组
queries表示的问题,其中queries[j] = [Cj, Dj]表示第j个问题,请你根据已知条件找出Cj / Dj = ?的结果作为答案。返回 所有问题的答案 。如果存在某个无法确定的答案,则用
-1.0替代这个答案。如果问题中出现了给定的已知条件中没有出现的字符串,也需要用-1.0替代这个答案。注意:输入总是有效的。你可以假设除法运算中不会出现除数为 0 的情况,且不存在任何矛盾的结果。
注意:未在等式列表中出现的变量是未定义的,因此无法确定它们的答案。
示例 1:输入:equations = [["a","b"],["b","c"]], values = [2.0,3.0], queries = [["a","c"],["b","a"],["a","e"],["a","a"],["x","x"]] 输出:[6.00000,0.50000,-1.00000,1.00000,-1.00000] 解释: 条件:a / b = 2.0, b / c = 3.0 问题:a / c = ?, b / a = ?, a / e = ?, a / a = ?, x / x = ? 结果:[6.0, 0.5, -1.0, 1.0, -1.0 ] 注意:x 是未定义的 => -1.0
示例 2:输入:equations = [["a","b"],["b","c"],["bc","cd"]], values = [1.5,2.5,5.0], queries = [["a","c"],["c","b"],["bc","cd"],["cd","bc"]] 输出:[3.75000,0.40000,5.00000,0.20000]
示例 3:输入:equations = [["a","b"]], values = [0.5], queries = [["a","b"],["b","a"],["a","c"],["x","y"]] 输出:[0.50000,2.00000,-1.00000,-1.00000]
提示:
1 <= equations.length <= 20equations[i].length == 21 <= Ai.length, Bi.length <= 5values.length == equations.length0.0 < values[i] <= 20.01 <= queries.length <= 20queries[i].length == 21 <= Cj.length, Dj.length <= 5Ai, Bi, Cj, Dj由小写英文字母与数字组成
解题思路
这个问题可以通过图论中的广度优先搜索(BFS)算法来解决:
-
图的建模:使用一个图来表示变量之间的关系。每个变量表示图中的一个节点,每个等式
Ai / Bi = values[i]代表从Ai到Bi的带权边,权重为values[i],反向边Bi到Ai的权重为1.0 / values[i]。 -
图的构建:使用哈希表
variables将每个变量映射到一个唯一的整数索引。使用邻接表edges来存储每个节点的邻接节点和对应的边权。 -
处理查询:
对于每个查询Cj / Dj,通过 BFS 从Cj节点出发,寻找到Dj节点的路径,并计算路径上的乘积。如果找不到路径或节点不在图中,则返回-1.0。
复杂度分析
-
图的构建:构建图的时间复杂度为
O(E),其中E是边的数量,这里E最多为2 * equations.length。 -
查询处理:对于每个查询,BFS 的时间复杂度为
O(V + E),其中V是节点的数量,E是边的数量。对于所有查询,总的时间复杂度为O(Q * (V + E)),其中Q是查询的数量。
代码实现
package org.zyf.javabasic.letcode.featured75.graph;
import java.util.*;
/**
* @program: zyfboot-javabasic
* @description: 除法求值
* @author: zhangyanfeng
* @create: 2024-08-24 11:35
**/
public class CalcEquation {
public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) {
// 用于映射变量到图中的节点索引
int nvars = 0;
Map<String, Integer> variables = new HashMap<>();
// 构建变量的映射关系
int n = equations.size();
for (int i = 0; i < n; i++) {
// 如果变量不存在,则添加到映射中
if (!variables.containsKey(equations.get(i).get(0))) {
variables.put(equations.get(i).get(0), nvars++);
}
if (!variables.containsKey(equations.get(i).get(1))) {
variables.put(equations.get(i).get(1), nvars++);
}
}
// 初始化邻接表
List<Pair>[] edges = new List[nvars];
for (int i = 0; i < nvars; i++) {
edges[i] = new ArrayList<>();
}
// 构建图的边
for (int i = 0; i < n; i++) {
int va = variables.get(equations.get(i).get(0));
int vb = variables.get(equations.get(i).get(1));
edges[va].add(new Pair(vb, values[i]));
edges[vb].add(new Pair(va, 1.0 / values[i]));
}
// 处理每个查询
int queriesCount = queries.size();
double[] ret = new double[queriesCount];
for (int i = 0; i < queriesCount; i++) {
List<String> query = queries.get(i);
double result = -1.0;
// 如果查询中的变量都在图中
if (variables.containsKey(query.get(0)) && variables.containsKey(query.get(1))) {
int ia = variables.get(query.get(0));
int ib = variables.get(query.get(1));
// 如果查询的两个变量相同,结果为1.0
if (ia == ib) {
result = 1.0;
} else {
// 使用 BFS 查找从 ia 到 ib 的路径
Queue<Integer> points = new LinkedList<>();
points.offer(ia);
double[] ratios = new double[nvars];
Arrays.fill(ratios, -1.0);
ratios[ia] = 1.0;
while (!points.isEmpty() && ratios[ib] < 0) {
int x = points.poll();
for (Pair pair : edges[x]) {
int y = pair.index;
double val = pair.value;
if (ratios[y] < 0) {
ratios[y] = ratios[x] * val;
points.offer(y);
}
}
}
result = ratios[ib];
}
}
ret[i] = result;
}
return ret;
}
// 辅助类,表示图中的边
class Pair {
int index; // 目标节点的索引
double value; // 边的权重
Pair(int index, double value) {
this.index = index;
this.value = value;
}
}
public static void main(String[] args) {
CalcEquation solution = new CalcEquation();
// Test Case 1
List<List<String>> equations1 = Arrays.asList(
Arrays.asList("a", "b"),
Arrays.asList("b", "c")
);
double[] values1 = {2.0, 3.0};
List<List<String>> queries1 = Arrays.asList(
Arrays.asList("a", "c"),
Arrays.asList("b", "a"),
Arrays.asList("a", "e"),
Arrays.asList("a", "a"),
Arrays.asList("x", "x")
);
double[] result1 = solution.calcEquation(equations1, values1, queries1);
System.out.println(Arrays.toString(result1)); // Expected: [6.0, 0.5, -1.0, 1.0, -1.0]
// Test Case 2
List<List<String>> equations2 = Arrays.asList(
Arrays.asList("a", "b"),
Arrays.asList("b", "c"),
Arrays.asList("bc", "cd")
);
double[] values2 = {1.5, 2.5, 5.0};
List<List<String>> queries2 = Arrays.asList(
Arrays.asList("a", "c"),
Arrays.asList("c", "b"),
Arrays.asList("bc", "cd"),
Arrays.asList("cd", "bc")
);
double[] result2 = solution.calcEquation(equations2, values2, queries2);
System.out.println(Arrays.toString(result2)); // Expected: [3.75, 0.4, 5.0, 0.2]
// Test Case 3
List<List<String>> equations3 = Arrays.asList(
Arrays.asList("a", "b")
);
double[] values3 = {0.5};
List<List<String>> queries3 = Arrays.asList(
Arrays.asList("a", "b"),
Arrays.asList("b", "a"),
Arrays.asList("a", "c"),
Arrays.asList("x", "y")
);
double[] result3 = solution.calcEquation(equations3, values3, queries3);
System.out.println(Arrays.toString(result3)); // Expected: [0.5, 2.0, -1.0, -1.0]
// Boundary Test Case
List<List<String>> equations4 = Arrays.asList(
Arrays.asList("a", "b"),
Arrays.asList("b", "c"),
Arrays.asList("c", "d"),
Arrays.asList("d", "e")
);
double[] values4 = {2.0, 2.0, 2.0, 2.0};
List<List<String>> queries4 = Arrays.asList(
Arrays.asList("a", "e"),
Arrays.asList("e", "a"),
Arrays.asList("a", "b"),
Arrays.asList("b", "c"),
Arrays.asList("c", "d"),
Arrays.asList("d", "e")
);
double[] result4 = solution.calcEquation(equations4, values4, queries4);
System.out.println(Arrays.toString(result4)); // Expected: [16.0, 0.0625, 2.0, 2.0, 2.0, 2.0]
}
}
十三、图 - 广度优先搜索
47.迷宫中离入口最近的出口(中等)
题目描述
给你一个
m x n的迷宫矩阵maze(下标从 0 开始),矩阵中有空格子(用'.'表示)和墙(用'+'表示)。同时给你迷宫的入口entrance,用entrance = [entrancerow, entrancecol]表示你一开始所在格子的行和列。每一步操作,你可以往 上,下,左 或者 右 移动一个格子。你不能进入墙所在的格子,你也不能离开迷宫。你的目标是找到离
entrance最近 的出口。出口 的含义是maze边界 上的 空格子。entrance格子 不算 出口。请你返回从
entrance到最近出口的最短路径的 步数 ,如果不存在这样的路径,请你返回-1。示例 1:
输入:maze = [["+","+",".","+"],[".",".",".","+"],["+","+","+","."]], entrance = [1,2] 输出:1 解释:总共有 3 个出口,分别位于 (1,0),(0,2) 和 (2,3) 。 一开始,你在入口格子 (1,2) 处。 - 你可以往左移动 2 步到达 (1,0) 。 - 你可以往上移动 1 步到达 (0,2) 。 从入口处没法到达 (2,3) 。 所以,最近的出口是 (0,2) ,距离为 1 步。示例 2:
输入:maze = [["+","+","+"],[".",".","."],["+","+","+"]], entrance = [1,0] 输出:2 解释:迷宫中只有 1 个出口,在 (1,2) 处。 (1,0) 不算出口,因为它是入口格子。 初始时,你在入口与格子 (1,0) 处。 - 你可以往右移动 2 步到达 (1,2) 处。 所以,最近的出口为 (1,2) ,距离为 2 步。示例 3:
输入:maze = [[".","+"]], entrance = [0,0] 输出:-1 解释:这个迷宫中没有出口。提示:
maze.length == mmaze[i].length == n1 <= m, n <= 100maze[i][j]要么是'.',要么是'+'。entrance.length == 20 <= entrancerow < m0 <= entrancecol < nentrance一定是空格子。



解题思路
该问题可以使用 广度优先搜索(BFS) 来解决,这是处理最短路径问题的经典方法,尤其是在图的无权边上。
-
初始化:
创建队列: 使用队列来进行 BFS。每次从队列中取出当前坐标和当前的步数。方向数组: 使用方向数组dx和dy来表示四个可能的移动方向(下、右、上、左)。 -
设置入口: 将入口坐标加入队列,并将入口位置标记为墙
'+',以避免重复访问。 -
BFS 遍历:
- 出队: 从队列中取出当前坐标和步数。
- 遍历邻接节点: 对于当前节点的四个方向,计算新坐标。
- 检查合法性:确保新坐标在迷宫的范围内;确保新坐标不是墙
'+'。 - 检查是否为出口:如果新坐标在迷宫的边界上,并且不是入口位置,则返回当前步数加一。
- 更新状态:将新坐标标记为墙
'+',防止重复访问;将新坐标加入队列并更新步数。
-
没有路径:如果队列为空时没有找到出口,返回
-1。
复杂度分析
- 时间复杂度:
O(m * n),其中m和n分别是迷宫的行数和列数。每个单元格最多被访问一次,每次访问的时间复杂度为常数O(1)。 - 空间复杂度:
O(m * n),主要用于队列和迷宫的状态标记。
代码实现
package org.zyf.javabasic.letcode.featured75.graph;
import java.util.LinkedList;
import java.util.Queue;
/**
* @program: zyfboot-javabasic
* @description: 迷宫中离入口最近的出口
* @author: zhangyanfeng
* @create: 2024-08-24 11:44
**/
public class NearestExit {
public int nearestExit(char[][] maze, int[] entrance) {
int m = maze.length; // 迷宫的行数
int n = maze[0].length; // 迷宫的列数
// 上下左右四个方向的行列变换量
int[] dx = {1, 0, -1, 0};
int[] dy = {0, 1, 0, -1};
// 创建一个队列用于 BFS,存储当前坐标和步数
Queue<int[]> queue = new LinkedList<>();
// 将入口坐标加入队列,并将入口位置标记为墙 '+'
queue.offer(new int[]{entrance[0], entrance[1], 0});
maze[entrance[0]][entrance[1]] = '+';
// BFS 遍历迷宫
while (!queue.isEmpty()) {
int[] curr = queue.poll();
int x = curr[0]; // 当前行
int y = curr[1]; // 当前列
int dist = curr[2]; // 当前步数
// 遍历四个方向
for (int k = 0; k < 4; k++) {
int nx = x + dx[k]; // 新的行
int ny = y + dy[k]; // 新的列
// 检查新坐标是否合法且为空格子
if (nx >= 0 && nx < m && ny >= 0 && ny < n && maze[nx][ny] == '.') {
// 检查新坐标是否为出口(边界上的空格子)
if (nx == 0 || nx == m - 1 || ny == 0 || ny == n - 1) {
return dist + 1;
}
// 标记新坐标为墙 '+'
maze[nx][ny] = '+';
// 将新坐标加入队列,并更新步数
queue.offer(new int[]{nx, ny, dist + 1});
}
}
}
// 如果没有找到出口,返回 -1
return -1;
}
public static void main(String[] args) {
NearestExit solution = new NearestExit();
// Test case 1
char[][] maze1 = {
{'+', '+', '.', '+'},
{'.', '.', '.', '+'},
{'+', '+', '+', '.'}
};
int[] entrance1 = {1, 2};
System.out.println(solution.nearestExit(maze1, entrance1)); // Output: 1
// Test case 2
char[][] maze2 = {
{'+', '+', '+'},
{'.', '.', '.'},
{'+', '+', '+'}
};
int[] entrance2 = {1, 0};
System.out.println(solution.nearestExit(maze2, entrance2)); // Output: 2
// Test case 3
char[][] maze3 = {
{'.', '+'}
};
int[] entrance3 = {0, 0};
System.out.println(solution.nearestExit(maze3, entrance3)); // Output: -1
}
}
48.腐烂的橘子(中等)
题目描述
在给定的
m x n网格grid中,每个单元格可以有以下三个值之一:
- 值
0代表空单元格;- 值
1代表新鲜橘子;- 值
2代表腐烂的橘子。每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。
返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回
-1。示例 1:
输入:grid = [[2,1,1],[1,1,0],[0,1,1]] 输出:4示例 2:输入:grid = [[2,1,1],[0,1,1],[1,0,1]] 输出:-1 解释:左下角的橘子(第 2 行, 第 0 列)永远不会腐烂,因为腐烂只会发生在 4 个方向上。
示例 3:输入:grid = [[0,2]] 输出:0 解释:因为 0 分钟时已经没新鲜橘子了,所以答案就是 0 。
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 10grid[i][j]仅为0、1或2
解题思路
这个问题可以通过广度优先搜索(BFS)来解决。使用 BFS 可以很好地模拟橘子的腐烂过程,因为 BFS 会逐层扩展,确保每分钟橘子的腐烂过程都被正确地模拟。
-
初始化:使用一个队列
queue来存储所有初始腐烂橘子的坐标;使用一个变量minutes来记录所需的时间(分钟数)。 -
遍历网格:遍历网格,找到所有初始的腐烂橘子,并将它们的坐标加入队列。
-
BFS 扩展:每次从队列中取出一个腐烂橘子,尝试将它周围的四个方向的相邻新鲜橘子腐烂;如果发现新鲜橘子腐烂了,将它们加入队列,并更新分钟数。
-
检查结果:在 BFS 结束后,检查网格中是否还有未腐烂的新鲜橘子。如果有,返回
-1;否则,返回记录的分钟数。
复杂度分析
- 时间复杂度:O(m * n),每个单元格最多被访问一次,其中 m 和 n 分别是网格的行数和列数。
- 空间复杂度:O(m * n),队列的空间复杂度,最坏情况下队列中会存储所有的单元格。
代码实现
package org.zyf.javabasic.letcode.hot100.graph;
import java.util.LinkedList;
import java.util.Queue;
/**
* @program: zyfboot-javabasic
* @description: 腐烂的橘子(中等)
* @author: zhangyanfeng
* @create: 2024-08-22 12:56
**/
public class OrangesRottingSolution {
public int orangesRotting(int[][] grid) {
// 获取网格的行数和列数
int m = grid.length;
int n = grid[0].length;
// 用于保存新鲜橘子的位置
Queue<int[]> queue = new LinkedList<>();
// 记录新鲜橘子的数量
int freshCount = 0;
// 遍历整个网格
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
// 如果当前单元格是腐烂的橘子
if (grid[i][j] == 2) {
queue.add(new int[]{i, j});
}
// 如果当前单元格是新鲜的橘子
else if (grid[i][j] == 1) {
freshCount++;
}
}
}
// 如果没有新鲜橘子,直接返回0
if (freshCount == 0) return 0;
// 记录时间步数
int minutes = 0;
// 4个方向的移动数组
int[][] directions = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};
// BFS遍历
while (!queue.isEmpty()) {
int size = queue.size();
// 对当前时间步的所有腐烂橘子进行处理
for (int i = 0; i < size; i++) {
int[] cell = queue.poll();
int x = cell[0];
int y = cell[1];
// 遍历4个方向
for (int[] dir : directions) {
int newX = x + dir[0];
int newY = y + dir[1];
// 检查新位置是否在网格内且是新鲜橘子
if (newX >= 0 && newX < m && newY >= 0 && newY < n && grid[newX][newY] == 1) {
// 将新鲜橘子腐烂
grid[newX][newY] = 2;
// 将腐烂的橘子位置添加到队列
queue.add(new int[]{newX, newY});
// 新鲜橘子数量减少
freshCount--;
}
}
}
// 如果队列不为空,增加时间步数
if (!queue.isEmpty()) {
minutes++;
}
}
// 如果还有新鲜橘子未腐烂,返回-1
return freshCount == 0 ? minutes : -1;
}
public static void main(String[] args) {
OrangesRottingSolution solution = new OrangesRottingSolution();
// 示例 1
int[][] grid1 = {
{2, 1, 1},
{1, 1, 0},
{0, 1, 1}
};
System.out.println(solution.orangesRotting(grid1)); // 输出: 4
// 示例 2
int[][] grid2 = {
{2, 1, 1},
{0, 1, 1},
{1, 0, 1}
};
System.out.println(solution.orangesRotting(grid2)); // 输出: -1
// 示例 3
int[][] grid3 = {
{0, 2}
};
System.out.println(solution.orangesRotting(grid3)); // 输出: 0
}
}
十四、堆 / 优先队列
49.数组中的第K个最大元素(中等)
题目描述
给定整数数组
nums和整数k,请返回数组中第k个最大的元素。请注意,你需要找的是数组排序后的第
k个最大的元素,而不是第k个不同的元素。你必须设计并实现时间复杂度为
O(n)的算法解决此问题。示例 1:输入:
[3,2,1,5,6,4],k = 2 输出: 5示例 2:输入:
[3,2,3,1,2,4,5,5,6],k = 4 输出: 4提示:
1 <= k <= nums.length <= 105-104 <= nums[i] <= 104
解题思路
要找到数组中的第 k 个最大的元素,可以使用快速选择算法(Quickselect),它的平均时间复杂度为 O(n),可以满足题目要求。
快速选择算法与快速排序(Quicksort)类似,都是基于分治思想。不同的是,快速选择只需要找到第 k 大的元素,而不需要对整个数组排序。
- 选择一个基准元素(pivot),通常选择数组的最后一个元素。
- 分区操作:将数组划分为两部分,左边的元素都大于等于基准元素,右边的元素都小于基准元素。
- 递归选择:检查基准元素的位置是否就是第 k 大的元素。如果是,则直接返回基准元素;如果不是,根据基准元素的位置判断要在哪一部分继续寻找。
复杂度分析
- 时间复杂度:平均时间复杂度为 O(n)。在最坏情况下,时间复杂度为 O(n^2),但通过随机选择基准元素可以有效避免最坏情况。
- 空间复杂度:O(1),只使用了常数级别的额外空间。
代码实现
package org.zyf.javabasic.letcode.hot100.heap;
import java.util.Random;
/**
* @program: zyfboot-javabasic
* @description: 数组中的第K个最大元素(中等)
* @author: zhangyanfeng
* @create: 2024-08-22 14:50
**/
public class KthLargestElement {
public int findKthLargest(int[] nums, int k) {
int n = nums.length;
return quickSelect(nums, 0, n - 1, n - k);
}
private int quickSelect(int[] nums, int left, int right, int k) {
if (left == right) {
return nums[left];
}
// 随机选择一个pivot,避免最坏情况
Random random = new Random();
int pivotIndex = left + random.nextInt(right - left + 1);
// 分区操作,返回pivot的最终位置
pivotIndex = partition(nums, left, right, pivotIndex);
// 根据k的位置,选择递归方向
if (k == pivotIndex) {
return nums[k];
} else if (k < pivotIndex) {
return quickSelect(nums, left, pivotIndex - 1, k);
} else {
return quickSelect(nums, pivotIndex + 1, right, k);
}
}
private int partition(int[] nums, int left, int right, int pivotIndex) {
int pivotValue = nums[pivotIndex];
// 先将pivot放到最后
swap(nums, pivotIndex, right);
int storeIndex = left;
for (int i = left; i < right; i++) {
if (nums[i] < pivotValue) {
swap(nums, storeIndex, i);
storeIndex++;
}
}
// 将pivot放回到它最终的位置
swap(nums, storeIndex, right);
return storeIndex;
}
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
public static void main(String[] args) {
KthLargestElement solver = new KthLargestElement();
int[] nums1 = {3, 2, 1, 5, 6, 4};
int k1 = 2;
System.out.println(solver.findKthLargest(nums1, k1)); // 输出: 5
int[] nums2 = {3, 2, 3, 1, 2, 4, 5, 5, 6};
int k2 = 4;
System.out.println(solver.findKthLargest(nums2, k2)); // 输出: 4
}
}
50.无限集中的最小数字(中等)
题目描述
现有一个包含所有正整数的集合
[1, 2, 3, 4, 5, ...]。实现
SmallestInfiniteSet类:
SmallestInfiniteSet()初始化 SmallestInfiniteSet 对象以包含 所有 正整数。int popSmallest()移除 并返回该无限集中的最小整数。void addBack(int num)如果正整数num不 存在于无限集中,则将一个num添加 到该无限集最后。示例:输入 ["SmallestInfiniteSet", "addBack", "popSmallest", "popSmallest", "popSmallest", "addBack", "popSmallest", "popSmallest", "popSmallest"] [[], [2], [], [], [], [1], [], [], []] 输出 [null, null, 1, 2, 3, null, 1, 4, 5] 解释 SmallestInfiniteSet smallestInfiniteSet = new SmallestInfiniteSet(); smallestInfiniteSet.addBack(2); // 2 已经在集合中,所以不做任何变更。 smallestInfiniteSet.popSmallest(); // 返回 1 ,因为 1 是最小的整数,并将其从集合中移除。 smallestInfiniteSet.popSmallest(); // 返回 2 ,并将其从集合中移除。 smallestInfiniteSet.popSmallest(); // 返回 3 ,并将其从集合中移除。 smallestInfiniteSet.addBack(1); // 将 1 添加到该集合中。 smallestInfiniteSet.popSmallest(); // 返回 1 ,因为 1 在上一步中被添加到集合中, // 且 1 是最小的整数,并将其从集合中移除。 smallestInfiniteSet.popSmallest(); // 返回 4 ,并将其从集合中移除。 smallestInfiniteSet.popSmallest(); // 返回 5 ,并将其从集合中移除。
提示:
1 <= num <= 1000- 最多调用
popSmallest和addBack方法 共计1000次
解题思路
为了实现 SmallestInfiniteSet 类,我们需要一个高效的数据结构来支持 popSmallest 和 addBack 操作。这个问题的核心在于管理两个方面:
- 追踪最小的整数:
popSmallest操作需要能够快速地找到并返回当前最小的整数。 - 管理回退的整数:
addBack操作需要能够将被移除的整数重新放回集合中,并确保这些整数能够被适时地返回。
设计思路
- 最小整数追踪:使用一个变量
current记录当前最小的整数,这样每次popSmallest操作可以直接返回current并递增current。 - 回退整数管理:使用一个优先队列(最小堆)来存储回退的整数。这使得我们可以在 O(log k) 时间复杂度内获取到当前最小的回退整数(其中
k是回退整数的数量)。
数据结构
- 优先队列(PriorityQueue):用于存储被添加回集合中的整数,保证了我们能在 O(log k) 时间内获取到最小回退整数。
- 变量
current:记录当前集合中的最小整数。
操作分析
-
如果优先队列为空,返回并移除popSmallest():current并将current增加 1。如果优先队列不为空,返回并移除优先队列中的最小值。 -
addBack(num):如果num小于current且不在优先队列中,则将num加入优先队列。
复杂度分析
popSmallest():在优先队列为空时,时间复杂度为 O(1);当优先队列不为空时,时间复杂度为 O(log k),其中 k 是优先队列中的元素数量。addBack(num):时间复杂度为 O(log k) 由于插入操作,和 O(1) 由于集合操作。
代码实现
package org.zyf.javabasic.letcode.featured75.heapqueue;
import java.util.HashSet;
import java.util.PriorityQueue;
import java.util.Set;
/**
* @program: zyfboot-javabasic
* @description: 无限集中的最小数字
* @author: zhangyanfeng
* @create: 2024-08-24 11:53
**/
public class SmallestInfiniteSet {
private int current; // 当前最小整数
private PriorityQueue<Integer> minHeap; // 优先队列存储回退的整数
private Set<Integer> inHeap; // 记录优先队列中的元素,避免重复添加
public SmallestInfiniteSet() {
this.current = 1; // 初始化当前最小整数为 1
this.minHeap = new PriorityQueue<>(); // 初始化优先队列
this.inHeap = new HashSet<>(); // 初始化哈希集合用于跟踪优先队列中的元素
}
// 移除并返回集合中的最小整数
public int popSmallest() {
if (minHeap.isEmpty()) {
// 如果优先队列为空,则返回并移除当前最小整数,并更新当前最小整数
return current++;
} else {
// 否则,从优先队列中取出并返回最小的回退整数
int smallest = minHeap.poll();
inHeap.remove(smallest); // 从哈希集合中移除该整数
return smallest;
}
}
// 将一个整数添加回集合
public void addBack(int num) {
// 只有在 num 小于当前最小整数且不在优先队列中时才添加
if (num < current && !inHeap.contains(num)) {
minHeap.offer(num); // 将 num 加入优先队列
inHeap.add(num); // 将 num 加入哈希集合
}
}
public static void main(String[] args) {
SmallestInfiniteSet smallestInfiniteSet = new SmallestInfiniteSet();
smallestInfiniteSet.addBack(2);
System.out.println(smallestInfiniteSet.popSmallest()); // 1
System.out.println(smallestInfiniteSet.popSmallest()); // 2
System.out.println(smallestInfiniteSet.popSmallest()); // 3
smallestInfiniteSet.addBack(1);
System.out.println(smallestInfiniteSet.popSmallest()); // 1
System.out.println(smallestInfiniteSet.popSmallest()); // 4
System.out.println(smallestInfiniteSet.popSmallest()); // 5
}
}
51.最大子序列的分数(中等)
题目描述
给你两个下标从 0 开始的整数数组
nums1和nums2,两者长度都是n,再给你一个正整数k。你必须从nums1中选一个长度为k的 子序列 对应的下标。对于选择的下标
i0,i1,...,ik - 1,你的 分数 定义如下:
nums1中下标对应元素求和,乘以nums2中下标对应元素的 最小值 。- 用公式表示:
(nums1[i0] + nums1[i1] +...+ nums1[ik - 1]) * min(nums2[i0] , nums2[i1], ... ,nums2[ik - 1])。请你返回 最大 可能的分数。
一个数组的 子序列 下标是集合
{0, 1, ..., n-1}中删除若干元素得到的剩余集合,也可以不删除任何元素。示例 1:输入:nums1 = [1,3,3,2], nums2 = [2,1,3,4], k = 3 输出:12 解释: 四个可能的子序列分数为: - 选择下标 0 ,1 和 2 ,得到分数 (1+3+3) * min(2,1,3) = 7 。 - 选择下标 0 ,1 和 3 ,得到分数 (1+3+2) * min(2,1,4) = 6 。 - 选择下标 0 ,2 和 3 ,得到分数 (1+3+2) * min(2,3,4) = 12 。 - 选择下标 1 ,2 和 3 ,得到分数 (3+3+2) * min(1,3,4) = 8 。 所以最大分数为 12 。
示例 2:输入:nums1 = [4,2,3,1,1], nums2 = [7,5,10,9,6], k = 1 输出:30 解释: 选择下标 2 最优:nums1[2] * nums2[2] = 3 * 10 = 30 是最大可能分数。
提示:
n == nums1.length == nums2.length1 <= n <= 1050 <= nums1[i], nums2[j] <= 1051 <= k <= n
解题思路
这是一个优化问题,我们需要从 nums1 中选择一个长度为 k 的子序列,并且计算分数最大化。分数的定义是 (nums1中选择的k个元素之和) * (nums2中对应k个下标的最小值)。要找到最大的可能分数,我们可以使用以下思路和优化方法:
-
排序
首先,我们需要考虑nums2的下标:nums2中的每个值。为了找到每个可能的最小值(min_val),我们可以先将nums2中的下标按照其对应值的降序排序。这样,我们可以确保当我们选择最小值时,它是最大的。 -
使用最大堆优化选择
k个nums1元素:- 我们使用最大堆(
PriorityQueue)来维护nums1中的k个最大的元素。通过这样的维护方式,我们可以在每一步中快速地获取到k个最大元素的和。 - 先将排序后的前
k个元素放入堆中,计算初始的分数。 - 然后逐步替换堆中最小的元素,保证总和是最大的,同时更新分数。
- 我们使用最大堆(
复杂度分析
-
时间复杂度:
- 排序:O(n log n)。我们对
n个元素进行排序。 - 维护最大堆:初始化前
k个元素的时间复杂度为 O(k log k)。替换和更新最大堆的时间复杂度为 O((n - k) log k),因为每次替换操作需要对堆进行插入和删除操作。 - 总的时间复杂度为 O(n log n + (n - k) log k),通常认为是 O(n log n)。
- 排序:O(n log n)。我们对
-
空间复杂度:
- 最大堆:O(k),用于存储
k个最大值。索引数组:O(n),用于排序。 - 总的空间复杂度为 O(n + k)。
- 最大堆:O(k),用于存储
代码实现
package org.zyf.javabasic.letcode.featured75.heapqueue;
import java.util.Arrays;
import java.util.PriorityQueue;
/**
* @program: zyfboot-javabasic
* @description: 最大子序列的分数
* @author: zhangyanfeng
* @create: 2024-08-24 12:01
**/
public class MaxScore {
public long maxScore(int[] nums1, int[] nums2, int k) {
int n = nums1.length;
// 存储索引的数组
Integer[] ids = new Integer[n];
for (int i = 0; i < n; i++) {
ids[i] = i;
}
// 按 nums2 中的值降序排序索引
Arrays.sort(ids, (i, j) -> nums2[j] - nums2[i]);
// 最大堆(优先队列)用来维护 nums1 中的 k 个最大值
PriorityQueue<Integer> pq = new PriorityQueue<>();
long sum = 0;
// 初始化前 k 个元素的和
for (int i = 0; i < k; i++) {
sum += nums1[ids[i]];
pq.offer(nums1[ids[i]]);
}
// 初始分数
long ans = sum * nums2[ids[k - 1]];
// 遍历后续的元素,尝试替换堆中最小的元素
for (int i = k; i < n; i++) {
int x = nums1[ids[i]];
if (x > pq.peek()) { // 如果当前元素比堆中最小的元素大
sum += x - pq.poll(); // 更新总和
pq.offer(x); // 将新元素加入堆
// 更新最大分数
ans = Math.max(ans, sum * nums2[ids[i]]);
}
}
return ans;
}
public static void main(String[] args) {
MaxScore sol = new MaxScore();
int[] nums1 = {1, 3, 3, 2};
int[] nums2 = {2, 1, 3, 4};
int k = 3;
System.out.println(sol.maxScore(nums1, nums2, k)); // 输出 12
int[] nums1_2 = {4, 2, 3, 1, 1};
int[] nums2_2 = {7, 5, 10, 9, 6};
int k_2 = 1;
System.out.println(sol.maxScore(nums1_2, nums2_2, k_2)); // 输出 30
}
}
52.雇佣 K 位工人的总代价(中等)
题目描述
给你一个下标从 0 开始的整数数组
costs,其中costs[i]是雇佣第i位工人的代价。同时给你两个整数
k和candidates。我们想根据以下规则恰好雇佣k位工人:
- 总共进行
k轮雇佣,且每一轮恰好雇佣一位工人。- 在每一轮雇佣中,从最前面
candidates和最后面candidates人中选出代价最小的一位工人,如果有多位代价相同且最小的工人,选择下标更小的一位工人。
- 比方说,
costs = [3,2,7,7,1,2]且candidates = 2,第一轮雇佣中,我们选择第4位工人,因为他的代价最小[3,2,7,7,1,2]。- 第二轮雇佣,我们选择第
1位工人,因为他们的代价与第4位工人一样都是最小代价,而且下标更小,[3,2,7,7,2]。注意每一轮雇佣后,剩余工人的下标可能会发生变化。- 如果剩余员工数目不足
candidates人,那么下一轮雇佣他们中代价最小的一人,如果有多位代价相同且最小的工人,选择下标更小的一位工人。- 一位工人只能被选择一次。
返回雇佣恰好
k位工人的总代价。示例 1:输入:costs = [17,12,10,2,7,2,11,20,8], k = 3, candidates = 4 输出:11 解释:我们总共雇佣 3 位工人。总代价一开始为 0 。 - 第一轮雇佣,我们从 [17,12,10,2,7,2,11,20,8] 中选择。最小代价是 2 ,有两位工人,我们选择下标更小的一位工人,即第 3 位工人。总代价是 0 + 2 = 2 。 - 第二轮雇佣,我们从 [17,12,10,7,2,11,20,8] 中选择。最小代价是 2 ,下标为 4 ,总代价是 2 + 2 = 4 。 - 第三轮雇佣,我们从 [17,12,10,7,11,20,8] 中选择,最小代价是 7 ,下标为 3 ,总代价是 4 + 7 = 11 。注意下标为 3 的工人同时在最前面和最后面 4 位工人中。 总雇佣代价是 11 。
示例 2:输入:costs = [1,2,4,1], k = 3, candidates = 3 输出:4 解释:我们总共雇佣 3 位工人。总代价一开始为 0 。 - 第一轮雇佣,我们从 [1,2,4,1] 中选择。最小代价为 1 ,有两位工人,我们选择下标更小的一位工人,即第 0 位工人,总代价是 0 + 1 = 1 。注意,下标为 1 和 2 的工人同时在最前面和最后面 3 位工人中。 - 第二轮雇佣,我们从 [2,4,1] 中选择。最小代价为 1 ,下标为 2 ,总代价是 1 + 1 = 2 。 - 第三轮雇佣,少于 3 位工人,我们从剩余工人 [2,4] 中选择。最小代价是 2 ,下标为 0 。总代价为 2 + 2 = 4 。 总雇佣代价是 4 。
提示:
1 <= costs.length <= 1051 <= costs[i] <= 1051 <= k, candidates <= costs.length
解题思路
这个问题要求在每轮选择从前 candidates 个工人和后 candidates 个工人中代价最小的工人,直到雇佣 k 位工人为止。我们使用优先队列(PriorityQueue)来高效地选择代价最小的工人:
-
特殊情况处理:如果
candidates * 2 + k大于工人总数n,即候选人数和需要雇佣的人数加起来超出了总工人数,直接将所有工人按代价排序后,选取最小的k个工人。 -
初始化:使用两个优先队列(
PriorityQueue)分别维护前candidates和后candidates个工人的代价。pre队列管理前candidates个工人的代价。suf队列管理后candidates个工人的代价。 -
雇佣工人:
在每一轮中,从两个优先队列中选择代价最小的工人,更新总代价,并将新的工人代价添加到对应的队列中。更新候选工人范围,确保队列中的工人始终是最新的。 -
返回结果:完成
k轮雇佣后,返回总雇佣代价。
复杂度分析
-
时间复杂度:
- 插入和删除操作在优先队列中是 O(log m) 的时间复杂度,其中
m为队列中的元素个数。 - 总体来说,每轮雇佣操作涉及对两个优先队列的插入和删除操作,总时间复杂度为 O(k log c),其中
c是候选工人的数量。 - 处理特殊情况时,时间复杂度为 O(n log n),因为需要对所有工人进行排序。
- 插入和删除操作在优先队列中是 O(log m) 的时间复杂度,其中
-
空间复杂度:
- 使用了两个优先队列,每个队列最多包含
candidates个元素,所以空间复杂度为 O(candidates)。
- 使用了两个优先队列,每个队列最多包含
代码实现
package org.zyf.javabasic.letcode.featured75.heapqueue;
import java.util.Arrays;
import java.util.PriorityQueue;
/**
* @program: zyfboot-javabasic
* @description: 雇佣 K 位工人的总代价
* @author: zhangyanfeng
* @create: 2024-08-24 12:07
**/
public class TotalCost {
public long totalCost(int[] costs, int k, int candidates) {
int n = costs.length;
long ans = 0;
// 如果候选人数和雇佣人数加起来超出总工人数,则直接排序选择
if (candidates * 2 + k > n) {
Arrays.sort(costs);
for (int i = 0; i < k; i++) {
ans += costs[i];
}
return ans;
}
// 使用优先队列分别维护前 candidates 和后 candidates 的工人代价
PriorityQueue<Integer> pre = new PriorityQueue<>();
PriorityQueue<Integer> suf = new PriorityQueue<>();
// 初始化前 candidates 和后 candidates 的工人代价
for (int i = 0; i < candidates; i++) {
pre.offer(costs[i]);
suf.offer(costs[n - 1 - i]);
}
// 用于跟踪当前需要从中选择的工人的索引
int i = candidates; // 下一个前候选工人的索引
int j = n - 1 - candidates; // 下一个后候选工人的索引
// 雇佣 k 位工人
while (k-- > 0) {
// 从前和后候选工人中选择代价最小的工人
if (pre.peek() <= suf.peek()) {
ans += pre.poll(); // 选择前候选工人
if (i <= j) { // 检查是否还有工人可以添加到队列中
pre.offer(costs[i++]);
}
} else {
ans += suf.poll(); // 选择后候选工人
if (i <= j) { // 检查是否还有工人可以添加到队列中
suf.offer(costs[j--]);
}
}
}
return ans;
}
public static void main(String[] args) {
TotalCost sol = new TotalCost();
int[] costs1 = {17, 12, 10, 2, 7, 2, 11, 20, 8};
int k1 = 3;
int candidates1 = 4;
System.out.println(sol.totalCost(costs1, k1, candidates1)); // 输出 11
int[] costs2 = {1, 2, 4, 1};
int k2 = 3;
int candidates2 = 3;
System.out.println(sol.totalCost(costs2, k2, candidates2)); // 输出 4
}
}
十五、二分查找
53.猜数字大小(简单)
题目描述
我们正在玩猜数字游戏。猜数字游戏的规则如下:
我会从
1到n随机选择一个数字。 请你猜选出的是哪个数字。如果你猜错了,我会告诉你,我选出的数字比你猜测的数字大了还是小了。
你可以通过调用一个预先定义好的接口
int guess(int num)来获取猜测结果,返回值一共有三种可能的情况:
-1:你猜的数字比我选出的数字大 (即num > pick)。1:你猜的数字比我选出的数字小 (即num < pick)。0:你猜的数字与我选出的数字相等。(即num == pick)。返回我选出的数字。
示例 1:输入:n = 10, pick = 6 输出:6
示例 2:输入:n = 1, pick = 1 输出:1
示例 3:输入:n = 2, pick = 1 输出:1
提示:
1 <= n <= 231 - 11 <= pick <= n
解题思路
我们使用二分查找来在 1 到 n 的范围内找到目标数字。
- 初始时,定义搜索区间
[left, right]为[1, n]。 - 在每一步中,计算中点
mid,并通过guess(mid)获取反馈:- 如果
guess(mid)返回0,说明mid是正确的数字,直接返回mid。 - 如果
guess(mid)返回-1,说明目标数字小于mid,因此将搜索区间缩小为[left, mid]。 - 如果
guess(mid)返回1,说明目标数字大于mid,因此将搜索区间缩小为[mid+1, right]。
- 如果
- 继续这个过程,直到
left和right相等,此时区间缩小为一个点,即为目标数字。
复杂度分析
- 时间复杂度:
O(log n)。每次通过二分查找将搜索区间缩小一半,因此总的时间复杂度是对数级别的。 - 空间复杂度:
O(1)。只使用了常量级的额外空间来存储变量left,right, 和mid。
代码实现
package org.zyf.javabasic.letcode.featured75.binary;
/**
* @program: zyfboot-javabasic
* @description: 猜数字大小
* @author: zhangyanfeng
* @create: 2024-08-24 12:26
**/
public class GuessNumber {
public int guessNumber(int n) {
int left = 1; // 初始搜索区间的左端点
int right = n; // 初始搜索区间的右端点
// 二分查找直到左端点和右端点相同
while (left < right) {
// 计算中点,避免溢出
int mid = left + (right - left) / 2;
// 调用 guess 方法获取中点的猜测结果
int result = guess(mid);
if (result == 0) {
// 猜对了,返回中点
return mid;
} else if (result == -1) {
// 目标数字小于 mid,缩小右边界
right = mid;
} else {
// 目标数字大于 mid,缩小左边界
left = mid + 1;
}
}
// 当左端点和右端点相等时,即找到目标数字
return left;
}
// 猜测接口方法,实际实现由平台提供
private int guess(int num) {
// 具体实现由平台提供
return 0; // placeholder
}
}
54.咒语和药水的成功对数(中等)
题目描述
给你两个正整数数组
spells和potions,长度分别为n和m,其中spells[i]表示第i个咒语的能量强度,potions[j]表示第j瓶药水的能量强度。同时给你一个整数
success。一个咒语和药水的能量强度 相乘 如果 大于等于success,那么它们视为一对 成功 的组合。请你返回一个长度为
n的整数数组pairs,其中pairs[i]是能跟第i个咒语成功组合的 药水 数目。示例 1:输入:spells = [5,1,3], potions = [1,2,3,4,5], success = 7 输出:[4,0,3] 解释: - 第 0 个咒语:5 * [1,2,3,4,5] = [5,10,15,20,25] 。总共 4 个成功组合。 - 第 1 个咒语:1 * [1,2,3,4,5] = [1,2,3,4,5] 。总共 0 个成功组合。 - 第 2 个咒语:3 * [1,2,3,4,5] = [3,6,9,12,15] 。总共 3 个成功组合。 所以返回 [4,0,3] 。
示例 2:输入:spells = [3,1,2], potions = [8,5,8], success = 16 输出:[2,0,2] 解释: - 第 0 个咒语:3 * [8,5,8] = [24,15,24] 。总共 2 个成功组合。 - 第 1 个咒语:1 * [8,5,8] = [8,5,8] 。总共 0 个成功组合。 - 第 2 个咒语:2 * [8,5,8] = [16,10,16] 。总共 2 个成功组合。 所以返回 [2,0,2] 。
提示:
n == spells.lengthm == potions.length1 <= n, m <= 1051 <= spells[i], potions[i] <= 1051 <= success <= 1010
解题思路
为了高效解决这个问题,我们可以利用排序和二分查找来优化查找符合条件的药水数量:
-
排序:对
potions数组进行排序。这是为了便于我们使用二分查找来快速找到符合条件的药水。 -
二分查找:对于每个
spell,我们需要找到与之配对的药水,使得spell * potion >= success。通过将potion从大到小排序后,我们可以通过计算最小需要的potion值,然后使用二分查找来快速找到满足条件的药水数量。 -
计算满足条件的药水数量:对于每个
spell[i],计算minPotion=ceil(success / spells[i])。然后在排序后的potions数组中找到第一个大于等于minPotion的元素。所有在这个位置之后的药水都满足条件,因此可以计算数量。
复杂度分析
- 排序
potions:时间复杂度为 O(mlogm)O(m \log m)O(mlogm),其中m是potions数组的长度。 - 对于每个
spell使用二分查找:时间复杂度为 O(nlogm)O(n \log m)O(nlogm),其中n是spells数组的长度,m是potions数组的长度。 - 总体时间复杂度: O(mlogm+nlogm)=O((n+m)logm)O(m \log m + n \log m) = O((n + m) \log m)O(mlogm+nlogm)=O((n+m)logm)。
代码实现
package org.zyf.javabasic.letcode.featured75.binary;
import java.util.Arrays;
import java.util.Random;
/**
* @program: zyfboot-javabasic
* @description: 咒语和药水的成功对数
* @author: zhangyanfeng
* @create: 2024-08-24 12:30
**/
public class SuccessfulPairs {
public int[] successfulPairs(int[] spells, int[] potions, long success) {
int n = spells.length;
int m = potions.length;
int[] result = new int[n];
// 对 potions 数组进行排序
Arrays.sort(potions);
// 对每个 spell 使用二分查找
for (int i = 0; i < n; i++) {
long minPotion = (success + spells[i] - 1) / spells[i]; // 计算最小的药水强度
// 使用二分查找找到第一个大于等于 minPotion 的药水
int left = 0, right = m;
while (left < right) {
int mid = left + (right - left) / 2;
if (potions[mid] >= minPotion) {
right = mid;
} else {
left = mid + 1;
}
}
// 计算符合条件的药水数量
result[i] = m - left;
}
return result;
}
public static void main(String[] args) {
Random rand = new Random();
int n = 10;
int m = 15;
int[] spells = new int[n];
int[] potions = new int[m];
for (int i = 0; i < n; i++) {
spells[i] = rand.nextInt(10) + 1;
}
for (int i = 0; i < m; i++) {
potions[i] = rand.nextInt(10) + 1;
}
long success = rand.nextInt(100) + 1;
SuccessfulPairs sol = new SuccessfulPairs();
int[] result = sol.successfulPairs(spells, potions, success);
// 打印测试数据
System.out.println("Spells: " + Arrays.toString(spells));
System.out.println("Potions: " + Arrays.toString(potions));
System.out.println("Success: " + success);
System.out.println("Result: " + Arrays.toString(result));
}
}
55.寻找峰值(中等)
题目描述
峰值元素是指其值严格大于左右相邻值的元素。
给你一个整数数组
nums,找到峰值元素并返回其索引。数组可能包含多个峰值,在这种情况下,返回 任何一个峰值 所在位置即可。你可以假设
nums[-1] = nums[n] = -∞。你必须实现时间复杂度为
O(log n)的算法来解决此问题。示例 1:输入:nums =
[1,2,3,1]输出:2 解释:3 是峰值元素,你的函数应该返回其索引 2。示例 2:输入:nums =
[1,2,1,3,5,6,4] 输出:1 或 5 解释:你的函数可以返回索引 1,其峰值元素为 2; 或者返回索引 5, 其峰值元素为 6。提示:
1 <= nums.length <= 1000-231 <= nums[i] <= 231 - 1- 对于所有有效的
i都有nums[i] != nums[i + 1]
解题思路
定义峰值:一个峰值元素是指该元素的值严格大于其左右相邻的元素。对于数组边界,假设数组外部元素是负无穷(-∞),因此边界元素如果比其唯一相邻元素大,也可以被视为峰值。
二分查找:
- 使用二分查找算法来高效地寻找峰值。我们通过不断缩小搜索范围来找到一个峰值元素。
- 在每一步中,选择数组的中间位置
mid,检查其是否为峰值。 - 如果
nums[mid]小于nums[mid + 1],则说明峰值在mid + 1的右侧(即,mid不是峰值,且右侧元素更大)。 - 如果
nums[mid]小于nums[mid - 1],则说明峰值在mid - 1的左侧。 - 如果
nums[mid]大于其相邻元素(即满足峰值条件),则返回mid。
复杂度分析
- 时间复杂度: O(logn)O(\log n)O(logn) — 二分查找将数组的搜索范围每次减半,因此时间复杂度是对数级别的。
- 空间复杂度: O(1)O(1)O(1) — 使用常量空间存储变量,空间复杂度为常量级别。
代码实现
package org.zyf.javabasic.letcode.featured75.binary;
/**
* @program: zyfboot-javabasic
* @description: 寻找峰值
* @author: zhangyanfeng
* @create: 2024-08-24 12:34
**/
public class FindPeakElement {
public int findPeakElement(int[] nums) {
int left = 0;
int right = nums.length - 1;
// 二分查找
while (left < right) {
int mid = left + (right - left) / 2;
// 比较中间位置和右侧位置的值
if (nums[mid] < nums[mid + 1]) {
// 峰值在右侧
left = mid + 1;
} else {
// 峰值在左侧或就是中间位置
right = mid;
}
}
// 此时 left == right,返回任何一个位置作为峰值位置
return left;
}
public static void main(String[] args) {
FindPeakElement sol = new FindPeakElement();
// 示例 1
int[] nums1 = {1, 2, 3, 1};
int peak1 = sol.findPeakElement(nums1);
System.out.println("示例 1 - 峰值元素的索引: " + peak1);
// 应输出 2,因为 nums[2] = 3 是一个峰值
// 示例 2
int[] nums2 = {1, 2, 1, 3, 5, 6, 4};
int peak2 = sol.findPeakElement(nums2);
System.out.println("示例 2 - 峰值元素的索引: " + peak2);
// 应输出 1 或 5,因为 nums[1] = 2 和 nums[5] = 6 都是峰值
}
}
56.爱吃香蕉的珂珂(中等)
题目描述
珂珂喜欢吃香蕉。这里有
n堆香蕉,第i堆中有piles[i]根香蕉。警卫已经离开了,将在h小时后回来。珂珂可以决定她吃香蕉的速度
k(单位:根/小时)。每个小时,她将会选择一堆香蕉,从中吃掉k根。如果这堆香蕉少于k根,她将吃掉这堆的所有香蕉,然后这一小时内不会再吃更多的香蕉。珂珂喜欢慢慢吃,但仍然想在警卫回来前吃掉所有的香蕉。
返回她可以在
h小时内吃掉所有香蕉的最小速度k(k为整数)。示例 1:输入:piles = [3,6,7,11], h = 8 输出:4
示例 2:输入:piles = [30,11,23,4,20], h = 5 输出:30
示例 3:输入:piles = [30,11,23,4,20], h = 6 输出:23
提示:
1 <= piles.length <= 104piles.length <= h <= 1091 <= piles[i] <= 109
解题思路
要解决这个问题,我们可以使用二分查找来找到珂珂在 h 小时内吃掉所有香蕉的最小速度 k:
-
定义目标: 我们需要找到一个最小的速度
k,使得珂珂能够在h小时内吃掉所有的香蕉。 -
二分查找:
- 左边界 (
left): 最小速度k为 1,因为珂珂每小时至少能吃 1 根香蕉。 - 右边界 (
right): 最速速度k为max(piles),即最大的堆香蕉数,因为在最坏情况下,如果珂珂每小时吃掉最大堆中的所有香蕉,她需要的速度至少为max(piles)。 - 使用二分查找在
left到right的区间中找到最小的满足条件的速度k。
- 左边界 (
-
检查函数 (
canEatAll): 对于每一个k值(中间值),我们计算珂珂在h小时内是否能吃完所有的香蕉。对于每一堆香蕉pile,珂珂需要ceil(pile / k)小时吃完这堆香蕉。累加所有堆的小时数,判断是否小于等于h。
复杂度分析
-
时间复杂度:
- 二分查找的时间复杂度是
O(log(max(piles)))。 - 对于每一个
k值,我们需要遍历piles数组计算需要的小时数,时间复杂度是O(n)。 - 总体时间复杂度为
O(n * log(max(piles)))。
- 二分查找的时间复杂度是
-
空间复杂度:主要是常数级的额外空间
O(1)。
代码实现
package org.zyf.javabasic.letcode.featured75.binary;
/**
* @program: zyfboot-javabasic
* @description: 爱吃香蕉的珂珂
* @author: zhangyanfeng
* @create: 2024-08-24 12:38
**/
public class MinEatingSpeed {
public int minEatingSpeed(int[] piles, int h) {
int left = 1;
int right = getMax(piles);
while (left < right) {
int mid = left + (right - left) / 2;
if (canEatAll(piles, h, mid)) {
right = mid; // 尝试更小的速度
} else {
left = mid + 1; // 速度太小,需要增加
}
}
return left;
}
// 辅助函数:获取 piles 中的最大值
private int getMax(int[] piles) {
int max = 0;
for (int pile : piles) {
max = Math.max(max, pile);
}
return max;
}
// 辅助函数:判断速度 k 是否能在 h 小时内吃完所有香蕉
private boolean canEatAll(int[] piles, int h, int k) {
int hoursNeeded = 0;
for (int pile : piles) {
hoursNeeded += (pile + k - 1) / k; // 向上取整
}
return hoursNeeded <= h;
}
public static void main(String[] args) {
MinEatingSpeed solution = new MinEatingSpeed();
// 测试用例 1
int[] piles1 = {3, 6, 7, 11};
int h1 = 8;
int result1 = solution.minEatingSpeed(piles1, h1);
System.out.println("Test Case 1: " + result1); // 预期输出: 4
// 测试用例 2
int[] piles2 = {30, 11, 23, 4, 20};
int h2 = 5;
int result2 = solution.minEatingSpeed(piles2, h2);
System.out.println("Test Case 2: " + result2); // 预期输出: 30
// 测试用例 3
int[] piles3 = {30, 11, 23, 4, 20};
int h3 = 6;
int result3 = solution.minEatingSpeed(piles3, h3);
System.out.println("Test Case 3: " + result3); // 预期输出: 23
// 测试用例 4:边界条件
int[] piles4 = {1, 1, 1, 1, 1};
int h4 = 5;
int result4 = solution.minEatingSpeed(piles4, h4);
System.out.println("Test Case 4: " + result4); // 预期输出: 1
// 测试用例 5:较大的输入
int[] piles5 = {1000000000, 1000000000, 1000000000};
int h5 = 2;
int result5 = solution.minEatingSpeed(piles5, h5);
System.out.println("Test Case 5: " + result5); // 预期输出: 1000000000
}
}
十六、回溯
57.电话号码的字母组合(中等)
题目描述
给定一个仅包含数字
2-9的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
示例 1:输入:digits = "23" 输出:["ad","ae","af","bd","be","bf","cd","ce","cf"]
示例 2:输入:digits = "" 输出:[]
示例 3:输入:digits = "2" 输出:["a","b","c"]
提示:
0 <= digits.length <= 4digits[i]是范围['2', '9']的一个数字。

解题思路
要解决这个问题,我们可以使用递归回溯算法来生成所有可能的字母组合。每个数字(2-9)对应着一定的字母,这些字母可以用于生成字母组合。我们需要根据输入的数字字符串来生成所有可能的组合。
- 映射关系:创建一个映射,将每个数字(2-9)映射到其对应的字母列表。
- 递归回溯:基准情况---当处理完所有数字时,将当前生成的字母组合加入结果列表;递归情况---对于当前数字对应的每个字母,递归生成剩余数字的所有可能的组合。
复杂度分析
- 时间复杂度:O(3^N * 4^M),其中 N 是输入中数字 2-6 的个数,M 是数字 7-9 的个数。每个数字有不同数量的字母可能性。
- 空间复杂度:O(3^N * 4^M * N),主要用于存储结果和递归调用栈。每种组合的长度为 N,并且可能的组合总数为 3^N * 4^M。
代码实现
package org.zyf.javabasic.letcode.hot100.backtracking;
import java.util.ArrayList;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 电话号码的字母组合(中等)
* @author: zhangyanfeng
* @create: 2024-08-22 13:21
**/
public class LetterCombinationsSolution {
// 映射数字到字母
private final String[] mapping = {
"", // 0
"", // 1
"abc", // 2
"def", // 3
"ghi", // 4
"jkl", // 5
"mno", // 6
"pqrs",// 7
"tuv", // 8
"wxyz" // 9
};
public List<String> letterCombinations(String digits) {
List<String> result = new ArrayList<>();
if (digits == null || digits.length() == 0) {
return result;
}
backtrack(result, new StringBuilder(), digits, 0);
return result;
}
private void backtrack(List<String> result, StringBuilder current, String digits, int index) {
// 如果当前组合的长度等于输入的数字长度,添加到结果中
if (index == digits.length()) {
result.add(current.toString());
return;
}
// 获取当前数字对应的字母
String letters = mapping[digits.charAt(index) - '0'];
// 遍历当前数字对应的每个字母
for (char letter : letters.toCharArray()) {
current.append(letter); // 选择当前字母
backtrack(result, current, digits, index + 1); // 递归处理下一个数字
current.deleteCharAt(current.length() - 1); // 撤销选择(回溯)
}
}
public static void main(String[] args) {
LetterCombinationsSolution solution = new LetterCombinationsSolution();
System.out.println(solution.letterCombinations("23")); // ["ad","ae","af","bd","be","bf","cd","ce","cf"]
System.out.println(solution.letterCombinations("")); // []
System.out.println(solution.letterCombinations("2")); // ["a","b","c"]
}
}
58.组合总和 III(中等)
题目描述
找出所有相加之和为
n的k个数的组合,且满足下列条件:
- 只使用数字1到9
- 每个数字 最多使用一次
返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。
示例 1:输入: k = 3, n = 7 输出: [[1,2,4]] 解释: 1 + 2 + 4 = 7 没有其他符合的组合了。
示例 2:输入: k = 3, n = 9 输出: [[1,2,6], [1,3,5], [2,3,4]] 解释: 1 + 2 + 6 = 9 1 + 3 + 5 = 9 2 + 3 + 4 = 9 没有其他符合的组合了。
示例 3:输入: k = 4, n = 1 输出: [] 解释: 不存在有效的组合。 在[1,9]范围内使用4个不同的数字,我们可以得到的最小和是1+2+3+4 = 10,因为10 > 1,没有有效的组合。
提示:
2 <= k <= 91 <= n <= 60
解题思路
要解决这个问题,我们可以使用回溯算法来生成所有可能的组合,并筛选出符合条件的组合:
-
回溯算法:我们可以通过回溯来生成所有可能的组合。每次选择一个数字,并递归地选择下一个数字,直到选出
k个数字的组合或者超出要求的和n。 -
选择数字的范围:由于数字必须在
1到9之间,并且每个数字最多使用一次,所以我们可以在[1, 9]的范围内选择。 -
剪枝:
如果当前组合的数字个数超过k,或者当前组合的数字和超过n,则终止当前分支;如果当前组合的数字个数等于k并且数字和等于n,则记录该组合。 -
结果存储:使用列表存储符合条件的组合。
复杂度分析
-
时间复杂度:回溯算法的时间复杂度主要取决于生成的组合的数量。最坏情况下,可能需要遍历所有可能的组合。对于
k和n的最大值(k = 9,n = 60),复杂度大约为O(2^k),因为在最坏情况下,可能需要遍历所有k的组合。 -
空间复杂度:主要包括递归栈的深度和存储结果的空间。递归栈的深度最大为
k,存储结果的空间则取决于符合条件的组合数量,最坏情况下也接近O(2^k)。
代码实现
package org.zyf.javabasic.letcode.featured75.binary;
import java.util.ArrayList;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 组合总和 III
* @author: zhangyanfeng
* @create: 2024-08-24 12:45
**/
public class CombinationSum3 {
public List<List<Integer>> combinationSum3(int k, int n) {
List<List<Integer>> result = new ArrayList<>();
backtrack(result, new ArrayList<>(), k, n, 1);
return result;
}
private void backtrack(List<List<Integer>> result, List<Integer> tempList, int k, int n, int start) {
// 终止条件
if (tempList.size() == k && n == 0) {
result.add(new ArrayList<>(tempList));
return;
}
if (tempList.size() > k || n < 0) {
return;
}
// 递归生成组合
for (int i = start; i <= 9; i++) {
tempList.add(i);
backtrack(result, tempList, k, n - i, i + 1); // 递归选择下一个数字
tempList.remove(tempList.size() - 1); // 回溯
}
}
public static void main(String[] args) {
CombinationSum3 solution = new CombinationSum3();
// 测试用例 1
System.out.println(solution.combinationSum3(3, 7)); // 预期输出: [[1, 2, 4]]
// 测试用例 2
System.out.println(solution.combinationSum3(3, 9)); // 预期输出: [[1, 2, 6], [1, 3, 5], [2, 3, 4]]
// 测试用例 3
System.out.println(solution.combinationSum3(4, 1)); // 预期输出: []
// 测试用例 4:边界条件
System.out.println(solution.combinationSum3(2, 5)); // 预期输出: [[1, 4], [2, 3]]
// 测试用例 5:较大输入
System.out.println(solution.combinationSum3(5, 15)); // 预期输出: [[1, 2, 3, 4, 5]]
}
}
十七、动态规划 - 一维
59.第 N 个泰波那契数(简单)
题目描述
泰波那契序列 Tn 定义如下:
T0 = 0, T1 = 1, T2 = 1, 且在 n >= 0 的条件下 Tn+3 = Tn + Tn+1 + Tn+2
给你整数
n,请返回第 n 个泰波那契数 Tn 的值。示例 1:输入:n = 4 输出:4 解释: T_3 = 0 + 1 + 1 = 2 T_4 = 1 + 1 + 2 = 4
示例 2:输入:n = 25 输出:1389537
提示:
0 <= n <= 37- 答案保证是一个 32 位整数,即
answer <= 2^31 - 1。
解题思路
由于泰波那契数列是一个递归定义的序列,最简单的实现方式是使用递归,但递归会导致大量的重复计算,效率较低。因此,采用动态规划(DP)是更优的解决方案。
动态规划的思路:
- 初始化:定义一个数组
dp用来存储计算结果,其中dp[i]表示第i个泰波那契数。 - 边界条件:根据题意,初始化
dp[0] = 0,dp[1] = 1,dp[2] = 1。 - 递推公式:根据泰波那契数列的定义,计算
dp[i]为dp[i-3] + dp[i-2] + dp[i-1]。 - 返回结果:最终返回
dp[n]。
复杂度分析
- 时间复杂度:O(n),因为我们只需遍历一次
0到n的区间,计算每个泰波那契数。 - 空间复杂度:O(n),由于使用了一个大小为
n+1的数组dp来存储计算结果。
代码实现
package org.zyf.javabasic.letcode.featured75.dynamic;
/**
* @program: zyfboot-javabasic
* @description: 第 N 个泰波那契数
* @author: zhangyanfeng
* @create: 2024-08-24 12:53
**/
public class Tribonacci {
public int tribonacci(int n) {
// 特殊情况处理
if (n == 0) return 0;
if (n == 1 || n == 2) return 1;
// 创建一个数组来存储泰波那契数
int[] dp = new int[n + 1];
// 初始化基础值
dp[0] = 0;
dp[1] = 1;
dp[2] = 1;
// 计算从第3个泰波那契数到第n个泰波那契数
for (int i = 3; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2] + dp[i - 3];
}
// 返回第n个泰波那契数
return dp[n];
}
public static void main(String[] args) {
Tribonacci solution = new Tribonacci();
// 测试用例 1
System.out.println(solution.tribonacci(4)); // 预期输出: 4
// 测试用例 2
System.out.println(solution.tribonacci(25)); // 预期输出: 1389537
// 测试用例 3: 边界情况
System.out.println(solution.tribonacci(0)); // 预期输出: 0
System.out.println(solution.tribonacci(1)); // 预期输出: 1
System.out.println(solution.tribonacci(2)); // 预期输出: 1
// 测试用例 4: 较大输入
System.out.println(solution.tribonacci(37)); // 预期输出: 2082876103
}
}
60.使用最小花费爬楼梯(简单)
题目描述
给你一个整数数组
cost,其中cost[i]是从楼梯第i个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。你可以选择从下标为
0或下标为1的台阶开始爬楼梯。请你计算并返回达到楼梯顶部的最低花费。
示例 1:输入:cost = [10,15,20] 输出:15 解释:你将从下标为 1 的台阶开始。 - 支付 15 ,向上爬两个台阶,到达楼梯顶部。 总花费为 15 。
示例 2:输入:cost = [1,100,1,1,1,100,1,1,100,1] 输出:6 解释:你将从下标为 0 的台阶开始。 - 支付 1 ,向上爬两个台阶,到达下标为 2 的台阶。 - 支付 1 ,向上爬两个台阶,到达下标为 4 的台阶。 - 支付 1 ,向上爬两个台阶,到达下标为 6 的台阶。 - 支付 1 ,向上爬一个台阶,到达下标为 7 的台阶。 - 支付 1 ,向上爬两个台阶,到达下标为 9 的台阶。 - 支付 1 ,向上爬一个台阶,到达楼梯顶部。 总花费为 6 。
提示:
2 <= cost.length <= 10000 <= cost[i] <= 999
解题思路
要解决爬楼梯的最低花费问题,我们可以使用动态规划来有效地计算达到楼梯顶部的最小费用。
-
定义状态:使用一个数组
dp,其中dp[i]表示到达第i个台阶的最低花费。 -
状态转移方程:
- 为了到达第
i个台阶,可以从第i-1或第i-2个台阶到达。 - 因此,
dp[i]的值可以通过以下公式得到: dp[i]=cost[i]+min(dp[i−1],dp[i−2]) - 其中,
dp[i-1]是到达第i-1个台阶的最低花费,dp[i-2]是到达第i-2个台阶的最低花费。
- 为了到达第
-
初始状态:
dp[0]是到达第 0 个台阶的费用,即cost[0];dp[1]是到达第 1 个台阶的费用,即cost[1]。 -
目标:计算到达楼梯顶部的最低花费。楼梯顶部在
cost.length处,我们可以从cost.length-1或cost.length-2台阶到达顶部。
复杂度分析
- 时间复杂度:O(n)O(n)O(n),其中 nnn 是台阶的数量,因为我们只需要遍历一次数组来计算每个台阶的最小费用。
- 空间复杂度:O(n)O(n)O(n),由于我们使用了一个大小为 nnn 的数组
dp来存储每个台阶的最低费用。
代码实现
package org.zyf.javabasic.letcode.featured75.dynamic;
/**
* @program: zyfboot-javabasic
* @description: 使用最小花费爬楼梯
* @author: zhangyanfeng
* @create: 2024-08-24 12:58
**/
public class MinCostClimbingStairs {
public int minCostClimbingStairs(int[] cost) {
int n = cost.length;
// 特殊情况处理
if (n == 2) return Math.min(cost[0], cost[1]);
// 创建 dp 数组
int[] dp = new int[n];
// 初始化 dp 数组的前两个元素
dp[0] = cost[0];
dp[1] = cost[1];
// 填充 dp 数组
for (int i = 2; i < n; i++) {
dp[i] = cost[i] + Math.min(dp[i - 1], dp[i - 2]);
}
// 返回到达顶部的最低花费
return Math.min(dp[n - 1], dp[n - 2]);
}
public static void main(String[] args) {
MinCostClimbingStairs solution = new MinCostClimbingStairs();
// 测试用例 1
int[] cost1 = {10, 15, 20};
System.out.println(solution.minCostClimbingStairs(cost1)); // 预期输出: 15
// 测试用例 2
int[] cost2 = {1, 100, 1, 1, 1, 100, 1, 1, 100, 1};
System.out.println(solution.minCostClimbingStairs(cost2)); // 预期输出: 6
// 测试用例 3: 边界情况
int[] cost3 = {0, 0};
System.out.println(solution.minCostClimbingStairs(cost3)); // 预期输出: 0
// 测试用例 4: 较长输入
int[] cost4 = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
System.out.println(solution.minCostClimbingStairs(cost4)); // 预期输出: 15
}
}
61.打家劫舍(中等)
题目描述
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
示例 1:输入:[1,2,3,1] 输出:4 解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。 偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:输入:[2,7,9,3,1] 输出:12 解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。 偷窃到的最高金额 = 2 + 9 + 1 = 12 。
提示:
1 <= nums.length <= 1000 <= nums[i] <= 400
解题思路
经典的动态规划问题,通常称为“打家劫舍”问题:我们的目标是计算在不触发警报的情况下,能偷窃到的最大金额。
-
定义状态:使用
dp[i]表示偷窃到第i个房屋时,能够获得的最大金额。 -
状态转移方程:
如果选择偷窃第i个房屋,则不能偷窃第i-1个房屋,最大金额为dp[i-2] + nums[i];如果不选择偷窃第i个房屋,则最大金额为dp[i-1];因此状态转移方程为: dp[i]=max(dp[i−1],dp[i−2]+nums[i]) -
初始状态:
dp[0] = nums[0],只有一个房屋时,只能偷窃这个房屋;dp[1] = \max(nums[0], nums[1]),只有两个房屋时,选择偷窃金额更大的那个。 -
最终结果:最终的结果是
dp[n-1],其中n是房屋的总数。
代码实现
package org.zyf.javabasic.letcode.hot100.dynamic;
/**
* @program: zyfboot-javabasic
* @description: 打家劫舍(中等)
* @author: zhangyanfeng
* @create: 2024-08-22 19:45
**/
public class HouseRobber {
public int rob(int[] nums) {
int n = nums.length;
if (n == 0) return 0;
if (n == 1) return nums[0];
// dp数组
int[] dp = new int[n];
dp[0] = nums[0];
dp[1] = Math.max(nums[0], nums[1]);
for (int i = 2; i < n; i++) {
dp[i] = Math.max(dp[i-1], dp[i-2] + nums[i]);
}
return dp[n-1];
}
public static void main(String[] args) {
HouseRobber robber = new HouseRobber();
int[] nums1 = {1, 2, 3, 1};
System.out.println(robber.rob(nums1)); // 输出: 4
int[] nums2 = {2, 7, 9, 3, 1};
System.out.println(robber.rob(nums2)); // 输出: 12
}
}
62.多米诺和托米诺平铺 (中等)
题目描述
有两种形状的瓷砖:一种是
2 x 1的多米诺形,另一种是形如 "L" 的托米诺形。两种形状都可以旋转。
给定整数 n ,返回可以平铺
2 x n的面板的方法的数量。返回对109 + 7取模 的值。平铺指的是每个正方形都必须有瓷砖覆盖。两个平铺不同,当且仅当面板上有四个方向上的相邻单元中的两个,使得恰好有一个平铺有一个瓷砖占据两个正方形。
示例 1:
输入: n = 3 输出: 5 解释: 五种不同的方法如上所示。示例 2:输入: n = 1 输出: 1
提示:
1 <= n <= 1000


解题思路
https://leetcode.cn/problems/domino-and-tromino-tiling/solutions/1962465/duo-mi-nuo-he-tuo-mi-nuo-ping-pu-by-leet-7n0j/
考虑这么一种平铺的方式:在第 i 列前面的正方形都被瓷砖覆盖,在第 i 列后面的正方形都没有被瓷砖覆盖(i 从 1 开始计数)。那么第 i 列的正方形有四种被覆盖的情况:
- 一个正方形都没有被覆盖,记为状态 0;
- 只有上方的正方形被覆盖,记为状态 1;
- 只有下方的正方形被覆盖,记为状态 2;
- 上下两个正方形都被覆盖,记为状态 3。
使用 dp[i][s] 表示平铺到第 i 列时,各个状态 s 对应的平铺方法数量。考虑第 i−1 列和第 i 列正方形,它们之间的状态转移如下图(红色条表示新铺的瓷砖):

最后平铺到第 n 列时,上下两个正方形都被覆盖的状态 dp[n][3] 对应的平铺方法数量就是总平铺方法数量。
复杂度分析
-
时间复杂度:O(n),其中 n 是总列数。
-
空间复杂度:O(n)。保存 dp 数组需要 O(n) 的空间。
代码实现
package org.zyf.javabasic.letcode.featured75.dynamic;
/**
* @program: zyfboot-javabasic
* @description: 多米诺和托米诺平铺
* @author: zhangyanfeng
* @create: 2024-08-24 13:07
**/
public class NumTilings {
static final int MOD = 1000000007;
public int numTilings(int n) {
// dp 数组定义:dp[i][j] 代表填充 2x i 面板的状态 j
int[][] dp = new int[n + 1][4];
dp[0][3] = 1; // 初始状态,空面板的填充方式
for (int i = 1; i <= n; i++) {
// 当前列的状态 0 是前一列为状态 3
dp[i][0] = dp[i - 1][3];
// 当前列的状态 1 是前一列为状态 0 和 2
dp[i][1] = (dp[i - 1][0] + dp[i - 1][2]) % MOD;
// 当前列的状态 2 是前一列为状态 0 和 1
dp[i][2] = (dp[i - 1][0] + dp[i - 1][1]) % MOD;
// 当前列的状态 3 是前一列的所有状态的和
dp[i][3] = (((dp[i - 1][0] + dp[i - 1][1]) % MOD + dp[i - 1][2]) % MOD + dp[i - 1][3]) % MOD;
}
// 返回填充 2x n 面板的所有有效方法数量
return dp[n][3];
}
public static void main(String[] args) {
NumTilings solution = new NumTilings();
// 测试用例 1
int n1 = 3;
System.out.println(solution.numTilings(n1)); // 预期输出: 5
// 测试用例 2
int n2 = 1;
System.out.println(solution.numTilings(n2)); // 预期输出: 1
// 测试用例 3: 边界情况
int n3 = 2;
System.out.println(solution.numTilings(n3)); // 预期输出: 3
// 测试用例 4: 较长输入
int n4 = 5;
System.out.println(solution.numTilings(n4)); // 预期输出: 21
}
}
十八、动态规划 - 多维
63.不同路径 (中等)
题目描述
一个机器人位于一个
m x n网格的左上角 (起始点在下图中标记为 “Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:
输入:m = 3, n = 7 输出:28示例 2:输入:m = 3, n = 2 输出:3 解释: 从左上角开始,总共有 3 条路径可以到达右下角。 1. 向右 -> 向下 -> 向下 2. 向下 -> 向下 -> 向右 3. 向下 -> 向右 -> 向下
示例 3:输入:m = 7, n = 3 输出:28
示例 4:输入:m = 3, n = 3 输出:6
提示:
1 <= m, n <= 100- 题目数据保证答案小于等于
2 * 109
解题思路
动态规划
-
定义状态:使用一个二维数组
dp,其中dp[i][j]表示从起始点到位置(i, j)的不同路径数量。 -
初始化:由于机器人只能从上面或左边到达当前位置
(i, j),所以如果i = 0或j = 0,路径数只有一种,即沿边缘移动。 -
状态转移:对于每个位置
(i, j),路径数等于上面位置和左边位置的路径数之和: dp[i][j]=dp[i−1][j]+dp[i][j−1]
代码实现
package org.zyf.javabasic.letcode.hot100.multidimensional;
/**
* @program: zyfboot-javabasic
* @description: 不同路径(中等)
* @author: zhangyanfeng
* @create: 2024-08-22 20:41
**/
public class UniquePaths {
public int uniquePaths(int m, int n) {
int[][] dp = new int[m][n];
// 初始化第一行和第一列
for (int i = 0; i < m; i++) {
dp[i][0] = 1;
}
for (int j = 0; j < n; j++) {
dp[0][j] = 1;
}
// 填充 dp 数组
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
return dp[m-1][n-1];
}
public static void main(String[] args) {
UniquePaths up = new UniquePaths();
// 测试用例1
System.out.println("测试用例1结果: " + up.uniquePaths(3, 7)); // 输出:28
// 测试用例2
System.out.println("测试用例2结果: " + up.uniquePaths(3, 2)); // 输出:3
// 测试用例3
System.out.println("测试用例3结果: " + up.uniquePaths(7, 3)); // 输出:28
// 测试用例4
System.out.println("测试用例4结果: " + up.uniquePaths(3, 3)); // 输出:6
}
}
64.最长公共子序列 (中等)
题目描述
给定两个字符串
text1和text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回0。一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
- 例如,
"ace"是"abcde"的子序列,但"aec"不是"abcde"的子序列。两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:输入:text1 = "abcde", text2 = "ace" 输出:3 解释:最长公共子序列是 "ace" ,它的长度为 3 。
示例 2:输入:text1 = "abc", text2 = "abc" 输出:3 解释:最长公共子序列是 "abc" ,它的长度为 3 。
示例 3:输入:text1 = "abc", text2 = "def" 输出:0 解释:两个字符串没有公共子序列,返回 0 。
提示:
1 <= text1.length, text2.length <= 1000text1和text2仅由小写英文字符组成。
解题思路
要解决找到两个字符串的最长公共子序列 (LCS) 的问题,可以使用动态规划方法:
-
定义状态:使用一个二维数组
dp,其中dp[i][j]表示字符串text1的前i个字符和字符串text2的前j个字符的最长公共子序列的长度。 -
初始化:
dp[0][j]和dp[i][0]都为 0,因为任何一个字符串和空字符串的公共子序列长度为 0。 -
状态转移:
- 如果
text1[i-1] == text2[j-1],则dp[i][j] = dp[i-1][j-1] + 1。 - 如果
text1[i-1] != text2[j-1],则dp[i][j] = max(dp[i-1][j], dp[i][j-1]),即去掉一个字符后计算最长公共子序列长度。
- 如果
-
目标:返回
dp[m][n],即两个字符串的最长公共子序列的长度。
复杂度分析
- 时间复杂度:O(m * n),其中
m和n分别是text1和text2的长度。 - 空间复杂度:O(m * n),用于存储动态规划表
dp。
代码实现
package org.zyf.javabasic.letcode.hot100.multidimensional;
/**
* @program: zyfboot-javabasic
* @description: 最长公共子序列 (中等)
* @author: zhangyanfeng
* @create: 2024-08-22 20:54
**/
public class LongestCommonSubsequence {
public int longestCommonSubsequence(String text1, String text2) {
int m = text1.length();
int n = text2.length();
// 创建 dp 数组
int[][] dp = new int[m + 1][n + 1];
// 填充 dp 数组
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (text1.charAt(i - 1) == text2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
// 返回最长公共子序列的长度
return dp[m][n];
}
public static void main(String[] args) {
LongestCommonSubsequence lcs = new LongestCommonSubsequence();
// 测试用例1
String text1_1 = "abcde";
String text2_1 = "ace";
System.out.println("测试用例1结果: " + lcs.longestCommonSubsequence(text1_1, text2_1)); // 输出:3
// 测试用例2
String text1_2 = "abc";
String text2_2 = "abc";
System.out.println("测试用例2结果: " + lcs.longestCommonSubsequence(text1_2, text2_2)); // 输出:3
// 测试用例3
String text1_3 = "abc";
String text2_3 = "def";
System.out.println("测试用例3结果: " + lcs.longestCommonSubsequence(text1_3, text2_3)); // 输出:0
}
}
65.买卖股票的最佳时机含手续费(中等)
题目描述
给定一个整数数组
prices,其中prices[i]表示第i天的股票价格 ;整数fee代表了交易股票的手续费用。你可以无限次地完成交易,但是你每笔交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。
返回获得利润的最大值。
注意:这里的一笔交易指买入持有并卖出股票的整个过程,每笔交易你只需要为支付一次手续费。
示例 1:输入:prices = [1, 3, 2, 8, 4, 9], fee = 2 输出:8 解释:能够达到的最大利润: 在此处买入 prices[0] = 1 在此处卖出 prices[3] = 8 在此处买入 prices[4] = 4 在此处卖出 prices[5] = 9 总利润: ((8 - 1) - 2) + ((9 - 4) - 2) = 8
示例 2:输入:prices = [1,3,7,5,10,3], fee = 3 输出:6
提示:
1 <= prices.length <= 5 * 1041 <= prices[i] < 5 * 1040 <= fee < 5 * 104
解题思路
要解决这个问题,我们可以使用动态规划来跟踪买入和卖出的最佳策略。具体地,我们可以使用两个状态变量来分别表示当前状态下的最大利润。
状态定义:hold-表示持有股票时的最大利润;cash-表示不持有股票时的最大利润。
我们需要通过这些状态来判断在每一天买入或卖出股票的最佳决策。动态规划转移
-
买入股票:
- 如果我们在某一天选择买入股票,则我们会从前一天的
cash状态转变为hold状态。即hold状态的转移方程是: hold=max(hold,cash−prices[i])\text{hold} = \max(\text{hold}, \text{cash} - \text{prices}[i])hold=max(hold,cash−prices[i]) - 这里,
cash - prices[i]表示之前的现金状态减去当前的股票价格,即当前买入股票后的持有状态。
- 如果我们在某一天选择买入股票,则我们会从前一天的
-
卖出股票:
- 如果我们在某一天选择卖出股票,则我们会从前一天的
hold状态转变为cash状态,并且需要扣除手续费。即cash状态的转移方程是: cash=max(cash,hold+prices[i]−fee)\text{cash} = \max(\text{cash}, \text{hold} + \text{prices}[i] - \text{fee})cash=max(cash,hold+prices[i]−fee) - 这里,
hold + prices[i] - fee表示当前卖出股票的利润,其中减去手续费。
- 如果我们在某一天选择卖出股票,则我们会从前一天的
初始化:初始时,我们没有持有股票,且 cash 为 0,hold 为负无穷(即 -Infinity),因为在没有任何交易前持有股票的情况是不可能的。
复杂度分析
-
时间复杂度:O(n)。我们只需要遍历一次
prices数组,每次遍历的操作为常数时间。 -
空间复杂度:O(1)。我们只需要常量的额外空间来存储
cash和hold状态。
代码实现
package org.zyf.javabasic.letcode.featured75.dynamic;
/**
* @program: zyfboot-javabasic
* @description: 买卖股票的最佳时机含手续费
* @author: zhangyanfeng
* @create: 2024-08-24 13:14
**/
public class MaxProfit {
public int maxProfit(int[] prices, int fee) {
int cash = 0; // 不持有股票时的最大利润
int hold = Integer.MIN_VALUE; // 持有股票时的最大利润,初始为负无穷
for (int price : prices) {
// 更新持有状态:当前持有股票的最大利润,可能是之前持有的状态或者从现金状态买入
hold = Math.max(hold, cash - price);
// 更新现金状态:当前不持有股票的最大利润,可能是之前现金的状态或者从持有状态卖出
cash = Math.max(cash, hold + price - fee);
}
// 返回最终的现金状态,即没有持有股票时的最大利润
return cash;
}
public static void main(String[] args) {
MaxProfit solution = new MaxProfit();
// 测试用例 1
int[] prices1 = {1, 3, 2, 8, 4, 9};
int fee1 = 2;
System.out.println(solution.maxProfit(prices1, fee1)); // 预期输出: 8
// 测试用例 2
int[] prices2 = {1, 3, 7, 5, 10, 3};
int fee2 = 3;
System.out.println(solution.maxProfit(prices2, fee2)); // 预期输出: 6
// 测试用例 3: 边界情况
int[] prices3 = {1, 2};
int fee3 = 1;
System.out.println(solution.maxProfit(prices3, fee3)); // 预期输出: 0
// 测试用例 4: 较长输入
int[] prices4 = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int fee4 = 1;
System.out.println(solution.maxProfit(prices4, fee4)); // 预期输出: 8
}
}
66.编辑距离(中等)
题目描述
给你两个单词
word1和word2, 请返回将word1转换成word2所使用的最少操作数 。你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:输入:word1 = "horse", word2 = "ros" 输出:3 解释: horse -> rorse (将 'h' 替换为 'r') rorse -> rose (删除 'r') rose -> ros (删除 'e')
示例 2:输入:word1 = "intention", word2 = "execution" 输出:5 解释: intention -> inention (删除 't') inention -> enention (将 'i' 替换为 'e') enention -> exention (将 'n' 替换为 'x') exention -> exection (将 'n' 替换为 'c') exection -> execution (插入 'u')
提示:
0 <= word1.length, word2.length <= 500word1和word2由小写英文字母组成
解题思路
要解决将一个单词 word1 转换成另一个单词 word2 的最少操作数问题,可以使用动态规划算法来计算最小编辑距离(Levenshtein Distance):
-
定义状态:使用一个二维数组
dp,其中dp[i][j]表示将word1的前i个字符转换为word2的前j个字符所需的最少操作数。 -
初始化:
dp[0][0]为 0,因为两个空字符串之间的转换成本为 0。dp[i][0]表示将word1的前i个字符转换为空字符串所需的操作数,即删除所有字符,dp[i][0] = i。dp[0][j]表示将空字符串转换为word2的前j个字符所需的操作数,即插入所有字符,dp[0][j] = j。
-
状态转移:
- 如果
word1[i-1] == word2[j-1],则dp[i][j] = dp[i-1][j-1],即不需要额外操作。 - 如果
word1[i-1] != word2[j-1],则dp[i][j]可以通过以下三种操作之一得到:- 插入:
dp[i][j] = dp[i][j-1] + 1,表示在word1的前i个字符中插入一个字符。 - 删除:
dp[i][j] = dp[i-1][j] + 1,表示在word1的前i个字符中删除一个字符。 - 替换:
dp[i][j] = dp[i-1][j-1] + 1,表示将word1的前i个字符中的一个字符替换为word2的前j个字符中的一个字符。
- 插入:
- 选择最小的操作数:
dp[i][j] = \min(dp[i-1][j] + 1, dp[i][j-1] + 1, dp[i-1][j-1] + 1)。
- 如果
-
目标:返回
dp[m][n],即将word1转换为word2所需的最少操作数,其中m和n分别是word1和word2的长度。
复杂度分析
- 时间复杂度:O(m * n),其中
m和n分别是word1和word2的长度。 - 空间复杂度:O(m * n),用于存储动态规划表
dp。
代码实现
package org.zyf.javabasic.letcode.hot100.multidimensional;
/**
* @program: zyfboot-javabasic
* @description: 编辑距离(中等)
* @author: zhangyanfeng
* @create: 2024-08-22 20:59
**/
public class EditDistance {
public int minDistance(String word1, String word2) {
int m = word1.length();
int n = word2.length();
// 创建 dp 数组
int[][] dp = new int[m + 1][n + 1];
// 初始化 dp 数组
for (int i = 0; i <= m; i++) {
dp[i][0] = i; // 将 word1 的前 i 个字符转换为空字符串
}
for (int j = 0; j <= n; j++) {
dp[0][j] = j; // 将空字符串转换为 word2 的前 j 个字符
}
// 填充 dp 数组
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = Math.min(
Math.min(dp[i - 1][j] + 1, dp[i][j - 1] + 1),
dp[i - 1][j - 1] + 1
);
}
}
}
// 返回将 word1 转换为 word2 所需的最少操作数
return dp[m][n];
}
public static void main(String[] args) {
EditDistance ed = new EditDistance();
// 测试用例1
String word1_1 = "horse";
String word2_1 = "ros";
System.out.println("测试用例1结果: " + ed.minDistance(word1_1, word2_1)); // 输出:3
// 测试用例2
String word1_2 = "intention";
String word2_2 = "execution";
System.out.println("测试用例2结果: " + ed.minDistance(word1_2, word2_2)); // 输出:5
}
}
十九、位运算
67.比特位计数(简单)
题目描述
给你一个整数
n,对于0 <= i <= n中的每个i,计算其二进制表示中1的个数 ,返回一个长度为n + 1的数组ans作为答案。示例 1:输入:n = 2 输出:[0,1,1] 解释: 0 --> 0 1 --> 1 2 --> 10
示例 2:输入:n = 5 输出:[0,1,1,2,1,2] 解释: 0 --> 0 1 --> 1 2 --> 10 3 --> 11 4 --> 100 5 --> 101
提示:
0 <= n <= 105进阶:
- 很容易就能实现时间复杂度为
O(n log n)的解决方案,你可以在线性时间复杂度O(n)内用一趟扫描解决此问题吗?- 你能不使用任何内置函数解决此问题吗?(如,C++ 中的
__builtin_popcount)
解题思路
二进制位的规律:
- 奇数:对于每个奇数
i,其二进制表示是由i-1的二进制表示加上最低位的1组成。例如,3的二进制是11,其1的个数是2,等于2(2的二进制10)的1的个数加1。 - 偶数:对于每个偶数
i,其二进制表示是i/2的二进制表示左移一位。因此,i的1的个数等于i/2的1的个数。例如,4的二进制是100,其1的个数是1,等于2的1的个数。
状态转移方程:
- 对于奇数
i,result[i] = result[i - 1] + 1。 - 对于偶数
i,result[i] = result[i / 2]。
复杂度分析
-
时间复杂度:O(n)。我们只需要遍历一次
0到num的每个数字,计算每个数字的1的个数。 -
空间复杂度:O(n)。我们需要一个长度为
num + 1的数组来存储结果。
代码实现
package org.zyf.javabasic.letcode.featured75.bitwise;
import java.util.Arrays;
/**
* @program: zyfboot-javabasic
* @description: 比特位计数
* @author: zhangyanfeng
* @create: 2024-08-24 13:36
**/
public class CountBits {
public int[] countBits(int num) {
// 创建一个数组 result,用来存储从 0 到 num 每个数的二进制中 1 的个数
int[] result = new int[num + 1];
// 遍历 1 到 num 的每个数字
for (int i = 1; i <= num; i++) {
// 如果 i 是奇数,则其 1 的个数是 i-1 的 1 的个数加 1
if (i % 2 == 1) {
result[i] = result[i - 1] + 1;
} else {
// 如果 i 是偶数,则其 1 的个数等于 i/2 的 1 的个数
result[i] = result[i / 2];
}
}
return result;
}
public static void main(String[] args) {
CountBits solution = new CountBits();
// 测试用例 1
int num1 = 2;
int[] result1 = solution.countBits(num1);
System.out.println(Arrays.toString(result1)); // 预期输出: [0, 1, 1]
// 测试用例 2
int num2 = 5;
int[] result2 = solution.countBits(num2);
System.out.println(Arrays.toString(result2)); // 预期输出: [0, 1, 1, 2, 1, 2]
// 测试用例 3: 边界情况
int num3 = 0;
int[] result3 = solution.countBits(num3);
System.out.println(Arrays.toString(result3)); // 预期输出: [0]
// 测试用例 4: 较大的输入
int num4 = 10;
int[] result4 = solution.countBits(num4);
System.out.println(Arrays.toString(result4)); // 预期输出: [0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2]
}
}
68.只出现一次的数字(简单)
题目描述
给你一个 非空 整数数组
nums,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
示例 1 :输入:nums = [2,2,1] 输出:1
示例 2 :输入:nums = [4,1,2,1,2] 输出:4
示例 3 :输入:nums = [1] 输出:1
提示:
1 <= nums.length <= 3 * 104-3 * 104 <= nums[i] <= 3 * 104- 除了某个元素只出现一次以外,其余每个元素均出现两次。
解题思路
为了找出一个整数数组中只出现一次的那个元素,而其他每个元素均出现两次,我们可以使用 异或操作 的特性来实现,异或操作的特性
- 自反性:x⊕x=0。同一个数与自己异或的结果是 0。
- 结合律:x⊕(y⊕z)=(x⊕y)⊕z。异或操作可以任意组合。
- 单位元:x⊕0=x。任何数与 0 异或的结果是它本身。
解题思路
-
初始化:使用一个变量
result来存储异或的结果,初始化为 0。 -
遍历数组:遍历数组中的每个元素,并将其与
result进行异或操作。 -
结果:最后
result中的值就是只出现一次的那个元素,因为所有其他成对出现的元素都会被消去,剩下的就是唯一出现的元素。
复杂度分析
- 时间复杂度:O(n),需要遍历数组一次。
- 空间复杂度:O(1),只使用了常量空间。
代码实现
package org.zyf.javabasic.letcode.hot100.skills;
/**
* @program: zyfboot-javabasic
* @description: 只出现一次的数字(简单)
* @author: zhangyanfeng
* @create: 2024-08-22 21:05
**/
public class SingleNumber {
public int singleNumber(int[] nums) {
int result = 0;
for (int num : nums) {
result ^= num; // 对每个数字进行异或
}
return result; // 返回只出现一次的元素
}
public static void main(String[] args) {
SingleNumber sn = new SingleNumber();
// 测试用例1
int[] nums1 = {2, 2, 1};
System.out.println("测试用例1结果: " + sn.singleNumber(nums1)); // 输出:1
// 测试用例2
int[] nums2 = {4, 1, 2, 1, 2};
System.out.println("测试用例2结果: " + sn.singleNumber(nums2)); // 输出:4
// 测试用例3
int[] nums3 = {1};
System.out.println("测试用例3结果: " + sn.singleNumber(nums3)); // 输出:1
}
}
69.或运算的最小翻转次数(中等)
题目描述
给你三个正整数
a、b和c。你可以对
a和b的二进制表示进行位翻转操作,返回能够使按位或运算aORb==c成立的最小翻转次数。「位翻转操作」是指将一个数的二进制表示任何单个位上的 1 变成 0 或者 0 变成 1 。
示例 1:
输入:a = 2, b = 6, c = 5 输出:3 解释:翻转后 a = 1 , b = 4 , c = 5 使得 a OR b == c示例 2:输入:a = 4, b = 2, c = 7 输出:1
示例 3:输入:a = 1, b = 2, c = 3 输出:0
提示:
1 <= a <= 10^91 <= b <= 10^91 <= c <= 10^9

解题思路
要解决这个问题,我们需要计算通过翻转位来使得 a | b 等于 c 所需的最小翻转次数。具体思路如下:
-
按位比较:对于每一位
i,我们分别检查a[i]、b[i]和c[i]这三位的值。基于按位或运算的规则,a[i] | b[i]需要等于c[i]。 -
判断每一位的翻转需求:
- 当
c[i]为0:如果a[i]和b[i]都是1,则需要翻转至少一个位(a[i]或b[i])来使a[i] | b[i]为0。因此,需要翻转两个1为0;如果a[i]和b[i]中至少有一个0,则无需翻转,因为0 | 0、0 | 1和1 | 0都可以得到0。 - 当
c[i]为1:如果a[i]和b[i]都是0,则需要翻转至少一个位(a[i]或b[i])来使a[i] | b[i]为1。因此,需要翻转两个0为1;如果a[i]或b[i]中有一个为1,则不需要翻转,因为1 | 0或1 | 1都可以得到1。
- 当
-
计算翻转次数:对每一位按照上述规则进行判断,并累加所需的翻转次数。
复杂度分析
-
时间复杂度:O(log(max(a,b,c))),因为我们最多需要遍历每个数的所有位,最大位数约为 30 位(因为 10^9 的二进制表示最多 30 位)。
-
空间复杂度:O(1),只使用了常数空间来存储临时变量。
代码实现
package org.zyf.javabasic.letcode.featured75.bitwise;
/**
* @program: zyfboot-javabasic
* @description: 或运算的最小翻转次数
* @author: zhangyanfeng
* @create: 2024-08-24 13:44
**/
public class MinFlips {
public int minFlips(int a, int b, int c) {
int ans = 0; // 记录总的翻转次数
// 遍历每一位(最多 31 位,因为 10^9 的二进制表示最多 30 位)
for (int i = 0; i < 31; ++i) {
// 提取当前位的值
int bitA = (a >> i) & 1;
int bitB = (b >> i) & 1;
int bitC = (c >> i) & 1;
if (bitC == 0) {
// 如果 c 的当前位为 0,a 和 b 的当前位都需要为 0
ans += bitA + bitB;
// 当 a[i] 和 b[i] 都是 1 时,需要翻转两个 1 为 0
} else {
// 如果 c 的当前位为 1,a 和 b 的当前位需要至少有一个为 1
ans += (bitA + bitB == 0) ? 1 : 0;
// 当 a[i] 和 b[i] 都是 0 时,需要翻转至少一个位为 1
}
}
return ans;
}
public static void main(String[] args) {
MinFlips solution = new MinFlips();
// 测试用例 1
int a1 = 2, b1 = 6, c1 = 5;
System.out.println(solution.minFlips(a1, b1, c1)); // 预期输出: 3
// 测试用例 2
int a2 = 4, b2 = 2, c2 = 7;
System.out.println(solution.minFlips(a2, b2, c2)); // 预期输出: 1
// 测试用例 3
int a3 = 1, b3 = 2, c3 = 3;
System.out.println(solution.minFlips(a3, b3, c3)); // 预期输出: 0
// 边界测试用例
int a4 = 1, b4 = 1, c4 = 0;
System.out.println(solution.minFlips(a4, b4, c4)); // 预期输出: 2
}
}
二十、前缀树
70.实现 Trie (前缀树)(中等)
题目描述
Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补全和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。示例:
输入 ["Trie", "insert", "search", "search", "startsWith", "insert", "search"] [[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]] 输出 [null, null, true, false, true, null, true] 解释 Trie trie = new Trie(); trie.insert("apple"); trie.search("apple"); // 返回 True trie.search("app"); // 返回 False trie.startsWith("app"); // 返回 True trie.insert("app"); trie.search("app"); // 返回 True提示:
1 <= word.length, prefix.length <= 2000word和prefix仅由小写英文字母组成insert、search和startsWith调用次数 总计 不超过3 * 104次
解题思路
Trie(前缀树)是一种高效的树形数据结构,专门用于处理字符串的前缀匹配问题。实现 Trie 需要以下几个基本操作:
-
插入字符串(
insert):从根节点开始,逐字符遍历字符串。如果字符对应的子节点不存在,则创建该子节点;插入完成后,可以在最后一个字符节点上标记该字符串的结束。 -
搜索字符串(
search):从根节点开始,逐字符遍历字符串。如果某个字符的子节点不存在,则说明该字符串不在 Trie 中;遍历完所有字符后,检查最后一个字符节点是否标记了该字符串的结束。 -
检查前缀(
startsWith):从根节点开始,逐字符遍历前缀。如果某个字符的子节点不存在,则说明没有以该前缀开头的字符串;遍历完所有字符后,只要路径存在即返回true。
Trie 数据结构
Trie 数据结构的基本组成包括:
- TrieNode 类:表示 Trie 树的节点,包含一个
children字典(子节点)和一个布尔值isEndOfWord(标记是否为一个单词的结束)。 - Trie 类:包含插入、搜索和前缀检查操作的方法。
复杂度分析
-
时间复杂度:
insert和search操作的时间复杂度为 O(L),其中 L 是字符串的长度;startsWith操作的时间复杂度为 O(P),其中 P 是前缀的长度。 -
空间复杂度:Trie 的空间复杂度取决于插入的单词数和每个单词的长度。最坏情况下,空间复杂度为 O(N * L),其中 N 是单词的数量,L 是单词的平均长度。
代码实现
package org.zyf.javabasic.letcode.hot100.graph;
import java.util.HashMap;
import java.util.Map;
/**
* @program: zyfboot-javabasic
* @description: 实现 Trie (前缀树)(中等)
* @author: zhangyanfeng
* @create: 2024-08-22 13:07
**/
public class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
// 插入一个单词到 Trie 中
public void insert(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
// 如果当前节点没有该字符的子节点,创建一个新节点
if (!node.children.containsKey(c)) {
node.children.put(c, new TrieNode());
}
// 移动到下一个节点
node = node.children.get(c);
}
// 标记单词的结尾
node.isEndOfWord = true;
}
// 检索单词是否在 Trie 中
public boolean search(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
// 如果当前节点没有该字符的子节点,单词不存在
if (!node.children.containsKey(c)) {
return false;
}
// 移动到下一个节点
node = node.children.get(c);
}
// 返回是否为单词的结尾
return node.isEndOfWord;
}
// 检查是否有单词以给定前缀开头
public boolean startsWith(String prefix) {
TrieNode node = root;
for (char c : prefix.toCharArray()) {
// 如果当前节点没有该字符的子节点,前缀不存在
if (!node.children.containsKey(c)) {
return false;
}
// 移动到下一个节点
node = node.children.get(c);
}
// 前缀存在
return true;
}
class TrieNode {
// 子节点映射
Map<Character, TrieNode> children;
// 是否为单词的结尾
boolean isEndOfWord;
public TrieNode() {
children = new HashMap<>();
isEndOfWord = false;
}
}
public static void main(String[] args) {
Trie trie = new Trie();
// 测试插入和搜索
trie.insert("apple");
System.out.println(trie.search("apple")); // 输出: true
System.out.println(trie.search("app")); // 输出: false
System.out.println(trie.startsWith("app")); // 输出: true
trie.insert("app");
System.out.println(trie.search("app")); // 输出: true
}
}
71.搜索推荐系统(中等)
题目描述
给你一个产品数组
products和一个字符串searchWord,products数组中每个产品都是一个字符串。请你设计一个推荐系统,在依次输入单词
searchWord的每一个字母后,推荐products数组中前缀与searchWord相同的最多三个产品。如果前缀相同的可推荐产品超过三个,请按字典序返回最小的三个。请你以二维列表的形式,返回在输入
searchWord每个字母后相应的推荐产品的列表。示例 1:输入:products = ["mobile","mouse","moneypot","monitor","mousepad"], searchWord = "mouse" 输出:[ ["mobile","moneypot","monitor"], ["mobile","moneypot","monitor"], ["mouse","mousepad"], ["mouse","mousepad"], ["mouse","mousepad"] ] 解释:按字典序排序后的产品列表是 ["mobile","moneypot","monitor","mouse","mousepad"] 输入 m 和 mo,由于所有产品的前缀都相同,所以系统返回字典序最小的三个产品 ["mobile","moneypot","monitor"] 输入 mou, mous 和 mouse 后系统都返回 ["mouse","mousepad"]
示例 2:输入:products = ["havana"], searchWord = "havana" 输出:[["havana"],["havana"],["havana"],["havana"],["havana"],["havana"]]
示例 3:输入:products = ["bags","baggage","banner","box","cloths"], searchWord = "bags" 输出:[["baggage","bags","banner"],["baggage","bags","banner"],["baggage","bags"],["bags"]]
示例 4:输入:products = ["havana"], searchWord = "tatiana" 输出:[[],[],[],[],[],[],[]]
提示:
1 <= products.length <= 10001 <= Σ products[i].length <= 2 * 10^4products[i]中所有的字符都是小写英文字母。1 <= searchWord.length <= 1000searchWord中所有字符都是小写英文字母。
解题思路
为了设计一个推荐系统,根据输入的单词逐步推荐匹配的产品,我们可以按照以下步骤来实现:
-
排序产品列表:首先,对
products数组中的产品进行字典序排序,保证当我们对每个前缀进行筛选时,得到的结果是按字典序排列的。 -
构建前缀匹配:
- 遍历
searchWord中的每个前缀,从第一个字符到最后一个字符。 - 对每个前缀,筛选出在产品列表中匹配该前缀的产品。
- 如果匹配的产品超过三个,取前面三个产品。
- 遍历
-
优化筛选过程:在排序后的
products中,可以利用二分查找加速前缀匹配的过程。
复杂度分析
-
排序:对
products进行排序的时间复杂度为 O(mlogm),其中 m 是products的长度。 -
前缀匹配:
- 对于每个前缀,利用二分查找可以在 O(logm) 时间复杂度内找到匹配的起始点。
- 因此,总的时间复杂度为 O(nlogm+k),其中 n 是
searchWord的长度,kkk 是匹配产品的总数。
-
空间复杂度:
- 主要是存储排序后的产品和每个前缀的推荐列表,所以空间复杂度为 O(m+n)。
代码实现
package org.zyf.javabasic.letcode.featured75.prdfixtree;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 搜索推荐系统
* @author: zhangyanfeng
* @create: 2024-08-24 13:52
**/
public class SuggestedProducts {
public List<List<String>> suggestedProducts(String[] products, String searchWord) {
List<List<String>> result = new ArrayList<>();
// 对产品进行字典序排序
Arrays.sort(products);
// 从第一个字符开始,逐步增加前缀
String prefix = "";
for (char c : searchWord.toCharArray()) {
prefix += c; // 添加当前字符到前缀
List<String> suggestions = new ArrayList<>();
// 遍历产品列表,找到以当前前缀开始的产品
for (String product : products) {
if (product.startsWith(prefix)) {
suggestions.add(product);
if (suggestions.size() == 3) {
break; // 只需要前 3 个匹配的产品
}
}
}
result.add(suggestions); // 将当前前缀的推荐列表添加到结果中
}
return result;
}
public static void main(String[] args) {
SuggestedProducts solution = new SuggestedProducts();
// 示例测试用例
String[] products1 = {"mobile", "mouse", "moneypot", "monitor", "mousepad"};
String searchWord1 = "mouse";
System.out.println(solution.suggestedProducts(products1, searchWord1));
// 输出: [["mobile","moneypot","monitor"],["mobile","moneypot","monitor"],["mouse","mousepad"],["mouse","mousepad"],["mouse","mousepad"]]
String[] products2 = {"havana"};
String searchWord2 = "havana";
System.out.println(solution.suggestedProducts(products2, searchWord2));
// 输出: [["havana"],["havana"],["havana"],["havana"],["havana"],["havana"]]
String[] products3 = {"bags", "baggage", "banner", "box", "cloths"};
String searchWord3 = "bags";
System.out.println(solution.suggestedProducts(products3, searchWord3));
// 输出: [["baggage","bags","banner"],["baggage","bags","banner"],["baggage","bags"],["bags"]]
String[] products4 = {"havana"};
String searchWord4 = "tatiana";
System.out.println(solution.suggestedProducts(products4, searchWord4));
// 输出: [[],[],[],[],[],[],[]]
}
}
二十一、区间集合
72.无重叠区间(中等)
题目描述
给定一个区间的集合
intervals,其中intervals[i] = [starti, endi]。返回 需要移除区间的最小数量,使剩余区间互不重叠 。示例 1:输入: intervals = [[1,2],[2,3],[3,4],[1,3]] 输出: 1 解释: 移除 [1,3] 后,剩下的区间没有重叠。
示例 2:输入: intervals = [ [1,2], [1,2], [1,2] ] 输出: 2 解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
示例 3:输入: intervals = [ [1,2], [2,3] ] 输出: 0 解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
提示:
1 <= intervals.length <= 105intervals[i].length == 2-5 * 104 <= starti < endi <= 5 * 104
解题思路
这个问题可以通过贪心算法来解决。目标是尽量保留最多的区间,以使移除的区间数量最少。
具体策略如下:
-
排序:先按照每个区间的结束时间从小到大进行排序。这是因为结束时间较早的区间,更有可能与后面的区间不重叠,从而可以保留更多的区间。
-
遍历:
- 使用一个变量记录当前保留的区间的结束时间
end。 - 遍历排序后的区间列表,若当前区间的开始时间
start大于等于end,则表示这个区间与之前保留的区间不重叠,可以保留此区间,并更新end为当前区间的结束时间。 - 若当前区间与之前保留的区间重叠,则需要移除该区间。
- 使用一个变量记录当前保留的区间的结束时间
-
计算移除的数量:可以通过计算需要移除的区间数量,即总区间数减去最终保留的区间数量来得到答案。
复杂度分析
- 排序:时间复杂度为 O(nlogn),其中 nnn 是区间的数量。
- 遍历:时间复杂度为 O(n),每个区间都被遍历一次。
因此,总时间复杂度为 O(nlogn)。
代码实现
package org.zyf.javabasic.letcode.featured75.interval;
import java.util.Arrays;
/**
* @program: zyfboot-javabasic
* @description: 无重叠区间
* @author: zhangyanfeng
* @create: 2024-08-24 13:58
**/
public class EraseOverlapIntervals {
public int eraseOverlapIntervals(int[][] intervals) {
if (intervals.length == 0) {
return 0;
}
// 将区间按照结束时间从小到大进行排序
Arrays.sort(intervals, (a, b) -> a[1] - b[1]);
// 初始化保留的区间数量,设置第一个区间的结束时间为初始值
int count = 1;
int end = intervals[0][1];
// 遍历区间
for (int i = 1; i < intervals.length; i++) {
// 如果当前区间的开始时间大于等于上一个保留区间的结束时间
if (intervals[i][0] >= end) {
count++; // 保留当前区间
end = intervals[i][1]; // 更新结束时间
}
}
// 返回需要移除的区间数量
return intervals.length - count;
}
public static void main(String[] args) {
EraseOverlapIntervals solution = new EraseOverlapIntervals();
// 示例测试用例
int[][] intervals1 = {{1,2},{2,3},{3,4},{1,3}};
System.out.println(solution.eraseOverlapIntervals(intervals1)); // 输出: 1
int[][] intervals2 = {{1,2},{1,2},{1,2}};
System.out.println(solution.eraseOverlapIntervals(intervals2)); // 输出: 2
int[][] intervals3 = {{1,2},{2,3}};
System.out.println(solution.eraseOverlapIntervals(intervals3)); // 输出: 0
}
}
73.用最少数量的箭引爆气球(中等)
题目描述
有一些球形气球贴在一堵用 XY 平面表示的墙面上。墙面上的气球记录在整数数组
points,其中points[i] = [xstart, xend]表示水平直径在xstart和xend之间的气球。你不知道气球的确切 y 坐标。一支弓箭可以沿着 x 轴从不同点 完全垂直 地射出。在坐标
x处射出一支箭,若有一个气球的直径的开始和结束坐标为xstart,xend, 且满足xstart ≤ x ≤ xend,则该气球会被 引爆 。可以射出的弓箭的数量 没有限制 。 弓箭一旦被射出之后,可以无限地前进。给你一个数组
points,返回引爆所有气球所必须射出的 最小 弓箭数 。示例 1:输入:points = [[10,16],[2,8],[1,6],[7,12]] 输出:2 解释:气球可以用2支箭来爆破: -在x = 6处射出箭,击破气球[2,8]和[1,6]。 -在x = 11处发射箭,击破气球[10,16]和[7,12]。
示例 2:输入:points = [[1,2],[3,4],[5,6],[7,8]] 输出:4 解释:每个气球需要射出一支箭,总共需要4支箭。
示例 3:输入:points = [[1,2],[2,3],[3,4],[4,5]] 输出:2 解释:气球可以用2支箭来爆破: - 在x = 2处发射箭,击破气球[1,2]和[2,3]。 - 在x = 4处射出箭,击破气球[3,4]和[4,5]。
提示:
1 <= points.length <= 105points[i].length == 2-231 <= xstart < xend <= 231 - 1
解题思路
这个问题可以使用贪心算法来解决。目标是尽量用最少的弓箭来引爆所有的气球。具体策略如下:
-
排序:首先将气球按照它们的右边界
xend进行排序。排序的原因是为了尽可能地用一支箭引爆更多的气球。 -
遍历:
初始化箭的数量arrowCount为1,当前射箭位置arrowPos为第一个气球的xend;遍历排序后的气球列表,对于每个气球,如果当前气球的左边界xstart大于当前的arrowPos,说明这个气球无法被当前的箭引爆,需要射出新的箭,并更新arrowPos为当前气球的xend。 -
返回结果:返回射出的箭的数量
arrowCount。
复杂度分析
- 排序:时间复杂度为 O(nlogn),其中 nnn 是气球的数量。
- 遍历:时间复杂度为 O(n),每个气球都被遍历一次。
因此,总时间复杂度为 O(nlogn)。
代码实现
package org.zyf.javabasic.letcode.featured75.interval;
import java.util.Arrays;
/**
* @program: zyfboot-javabasic
* @description: 用最少数量的箭引爆气球
* @author: zhangyanfeng
* @create: 2024-08-24 14:08
**/
public class FindMinArrowShots {
public int findMinArrowShots(int[][] points) {
if (points.length == 0) {
return 0;
}
// 按照气球的右边界 xend 进行排序
Arrays.sort(points, (a, b) -> Integer.compare(a[1], b[1]));
// 初始化箭的数量和当前的射箭位置
int arrowCount = 1;
int arrowPos = points[0][1];
// 遍历所有气球
for (int i = 1; i < points.length; i++) {
// 如果当前气球的左边界在当前箭的位置之后,则需要射出新的一箭
if (points[i][0] > arrowPos) {
arrowCount++;
arrowPos = points[i][1];
}
}
return arrowCount;
}
public static void main(String[] args) {
FindMinArrowShots solution = new FindMinArrowShots();
// 示例测试用例
int[][] points1 = {{10, 16}, {2, 8}, {1, 6}, {7, 12}};
System.out.println(solution.findMinArrowShots(points1)); // 输出: 2
int[][] points2 = {{1, 2}, {3, 4}, {5, 6}, {7, 8}};
System.out.println(solution.findMinArrowShots(points2)); // 输出: 4
int[][] points3 = {{1, 2}, {2, 3}, {3, 4}, {4, 5}};
System.out.println(solution.findMinArrowShots(points3)); // 输出: 2
}
}
二十二、单调栈
74.每日温度(中等)
题目描述
给定一个整数数组
temperatures,表示每天的温度,返回一个数组answer,其中answer[i]是指对于第i天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用0来代替。示例 1:输入:
temperatures= [73,74,75,71,69,72,76,73] 输出: [1,1,4,2,1,1,0,0]示例 2:输入: temperatures = [30,40,50,60] 输出: [1,1,1,0]
示例 3:输入: temperatures = [30,60,90] 输出: [1,1,0]
提示:
1 <= temperatures.length <= 10530 <= temperatures[i] <= 100
解题思路
要解决这个问题,我们可以使用 单调栈 来寻找每一天温度之后的第一个更高温度的天数。这个方法能够高效地解决问题并满足时间复杂度的要求。
-
单调栈的定义:我们维护一个栈,栈中的元素存储的是温度的下标。栈中的温度是递减的,这样当我们遇到一个比栈顶元素大的温度时,就可以知道栈顶元素的下一个更高温度出现在当前下标。
-
遍历温度数组:当栈非空且当前温度高于栈顶温度时,说明找到了栈顶温度的下一个更高温度。计算距离,并将栈顶元素弹出;无论如何都将当前温度的下标压入栈中,继续处理下一个温度。
-
结果数组:最终得到的
answer数组就是每一天到下一个更高温度的天数。
复杂度分析
- 时间复杂度:O(n),因为每个元素最多只会被压入和弹出栈一次。
- 空间复杂度:O(n),用于存储栈和结果数组。
代码实现
package org.zyf.javabasic.letcode.hot100.stack;
import java.util.Stack;
/**
* @program: zyfboot-javabasic
* @description: 每日温度(中等)
* @author: zhangyanfeng
* @create: 2024-08-22 14:40
**/
public class DailyTemperatures {
public int[] dailyTemperatures(int[] temperatures) {
int n = temperatures.length;
int[] answer = new int[n];
Stack<Integer> stack = new Stack<>();
for (int i = 0; i < n; i++) {
// 当前温度比栈顶温度高,计算差值
while (!stack.isEmpty() && temperatures[i] > temperatures[stack.peek()]) {
int idx = stack.pop();
answer[idx] = i - idx;
}
// 压入当前温度的下标
stack.push(i);
}
return answer;
}
public static void main(String[] args) {
DailyTemperatures dt = new DailyTemperatures();
int[] result1 = dt.dailyTemperatures(new int[]{73, 74, 75, 71, 69, 72, 76, 73});
int[] result2 = dt.dailyTemperatures(new int[]{30, 40, 50, 60});
int[] result3 = dt.dailyTemperatures(new int[]{30, 60, 90});
// 打印结果
System.out.println(java.util.Arrays.toString(result1)); // [1, 1, 4, 2, 1, 1, 0, 0]
System.out.println(java.util.Arrays.toString(result2)); // [1, 1, 1, 0]
System.out.println(java.util.Arrays.toString(result3)); // [1, 1, 0]
}
}
75.股票价格跨度(中等)
题目描述
设计一个算法收集某些股票的每日报价,并返回该股票当日价格的 跨度 。
当日股票价格的 跨度 被定义为股票价格小于或等于今天价格的最大连续日数(从今天开始往回数,包括今天)。
例如,如果未来 7 天股票的价格是
[100,80,60,70,60,75,85],那么股票跨度将是[1,1,1,2,1,4,6]。实现
StockSpanner类:
StockSpanner()初始化类对象。int next(int price)给出今天的股价price,返回该股票当日价格的 跨度 。示例:输入: ["StockSpanner", "next", "next", "next", "next", "next", "next", "next"] [[], [100], [80], [60], [70], [60], [75], [85]] 输出: [null, 1, 1, 1, 2, 1, 4, 6] 解释: StockSpanner stockSpanner = new StockSpanner(); stockSpanner.next(100); // 返回 1 stockSpanner.next(80); // 返回 1 stockSpanner.next(60); // 返回 1 stockSpanner.next(70); // 返回 2 stockSpanner.next(60); // 返回 1 stockSpanner.next(75); // 返回 4 ,因为截至今天的最后 4 个股价 (包括今天的股价 75) 都小于或等于今天的股价。 stockSpanner.next(85); // 返回 6
提示:
1 <= price <= 105- 最多调用
next方法104次
解题思路
这个问题可以通过单调栈来解决:
- 使用一个栈来存储价格和对应的跨度。当遍历到一个新的价格时,将栈中所有比当前价格小或等于的元素弹出,因为这些元素不再对后续的价格产生影响。
- 每次计算当前价格的跨度时,可以通过栈顶元素快速确定,而不需要回溯遍历之前的所有价格。
实现步骤:
- 初始化一个栈,栈中的元素为二元组
(price, span),表示某个价格及其对应的跨度。 - 每当有新的价格
price输入时,首先初始化当前天的跨度span = 1。然后,将栈中所有比当前价格小或等于的元素弹出,同时将这些元素的跨度加到当前天的跨度上。 - 最后,将
(price, span)压入栈中,并返回span作为结果。
复杂度分析
每个价格只会进栈和出栈一次,因此整个算法的时间复杂度为 O(n)O(n)O(n),其中 nnn 是 next 方法的调用次数。
代码实现
package org.zyf.javabasic.letcode.featured75.stack;
import java.util.Stack;
/**
* @program: zyfboot-javabasic
* @description: 股票价格跨度
* @author: zhangyanfeng
* @create: 2024-08-24 14:14
**/
public class StockSpanner {
// 使用栈存储价格和对应的跨度
private Stack<int[]> stack;
// 构造函数,初始化栈
public StockSpanner() {
stack = new Stack<>();
}
public int next(int price) {
int span = 1;
// 弹出所有小于等于当前价格的元素,并累加它们的跨度
while (!stack.isEmpty() && stack.peek()[0] <= price) {
span += stack.pop()[1];
}
// 将当前价格和计算得出的跨度压入栈中
stack.push(new int[]{price, span});
// 返回当前价格的跨度
return span;
}
public static void main(String[] args) {
StockSpanner stockSpanner = new StockSpanner();
System.out.println(stockSpanner.next(100)); // 输出: 1
System.out.println(stockSpanner.next(80)); // 输出: 1
System.out.println(stockSpanner.next(60)); // 输出: 1
System.out.println(stockSpanner.next(70)); // 输出: 2
System.out.println(stockSpanner.next(60)); // 输出: 1
System.out.println(stockSpanner.next(75)); // 输出: 4
System.out.println(stockSpanner.next(85)); // 输出: 6
}
}