Python 数据分析之Numpy学习(二)
接上文:Python 数据分析之Numpy学习(一)
四、数组的索引和切片
索引即通过一个无符号整数值获取数组里的值。Python索引是从0的位置开始。
切片即对数组里某个片段的描述。
# 载入库
import numpy as np
4.1 一维数组的索引和切片
一维数组的索引和切片与list(列表)类似
4.1.1 一维数组的索引
一维数组的索引:从0开始的序列,或者从-1开始的反向序列
# 列表的索引
list1 = list(range(10))
list1
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 第一个元素
list1[0]
0
# 最后一个元素
list1[-1]
9
# 中间某个元素,例如第七个元素
list1[6]
6
# 一维数组的索引
arr1 = np.arange(10)
arr1
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 数组中的第一个元素
arr1[0]
0
# 数组中的最后一个元素
arr1[-1]
9
# 数组中间某一个元素,第七个元素
arr1[6]
6
# 列表中,索引值超出有效范围会报错
# list1[10]
# IndexError: list index out of range
# 同样,在数组中索引值超出有效范围也会报错
# arr1[10]
# IndexError: index 10 is out of bounds for axis 0 with size 10
4.1.2 一维数组的切片
切片不检查索引的有效范围,不在有效范围内的数值,得不到对应的结果,但不会报错
# 列表的切片
# 去掉第一个元素和最后一个元素
list1[1:-1]
[1, 2, 3, 4, 5, 6, 7, 8]
# 得到前三个元素
list1[:3]
[0, 1, 2]
# 得到后三个元素
list1[-3:]
[7, 8, 9]
# 列表的倒置
list1[::-1]
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
# 数组的切片
# 去掉第一个元素和最后一个元素
arr1[1:-1]
array([1, 2, 3, 4, 5, 6, 7, 8])
# 得到前三个元素
arr1[:3]
array([0, 1, 2])
# 得到后三个元素
arr1[-3:]
array([7, 8, 9])
# 数组的倒置
arr1[::-1]
array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])
4.2 多维数组的索引和切片
4.2.1 多维数组的索引
在多维数组中,如果像列表一样用一维的索引进行访问,会返回一个维度减1的子数组
以一维数组的索引方式访问时,获取的是一个一维数组,在高维数组中,用一维索引进行访问,得到是 维度 减 1 的子数组
# 嵌套列表的索引
list2 = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
]
list2
[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
# 要返回7这个元素
list2[1][2]
7
# 多维数组的索引
arr2 = np.arange(1,13).reshape(3,4)
arr2
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
# 返回7这个元素
arr2[1][2]
# 缺陷:arr2[1]会在内存中生成一个临时子数组,会增加系统内存的开销,降低效率
7
数组方式:使用多维索引进行访问,在索引中区分维度信息(列表上不能使用该方式)
- 二维数组: array[行的索引, 列的索引]
- 高维数组: array[维度1上的索引, 维度2上的索引,…,维度n上的索引]
在索引中用,区分维度
# 获取7的索引,这样的方式简化了索引的操作,且不会返回临时的子数组
arr2[1, 2]
7
arr3 = np.arange(1,37).reshape(3,3,4)
arr3
array([[[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]],
[[13, 14, 15, 16],
[17, 18, 19, 20],
[21, 22, 23, 24]],
[[25, 26, 27, 28],
[29, 30, 31, 32],
[33, 34, 35, 36]]])
# 返回三维数组中 23,该元素在第二层 第三行 第三列
arr3[1, 2, 2]
23
4.2.2 多维数组的切片
一维数组的切片:array[start:stop:step]
多维数组的切片:array[start1:stop1:step1, start2:stop2:step2, ... startn:stopn:stepn
多维数组切片在一维数组切片的基础上增加对维度的处理,用 , 分隔维度, 用 : 分隔切片的需求]
arr2
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
# 得到前两行的数据
arr2[0:2,0:100]
# 前两行,所有列
# 简化
arr2[:2,:]
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
# 如果是靠后的维度不需要切(返回全部的内容),则可以省略切片的书写
arr2[:2]
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
# 如果要返回后两列的数据
arr2[-2:] # 返回的是后两行
array([[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
# 靠前的维度不需要切的时候,不能省略
arr2[:,-2:]
array([[ 3, 4],
[ 7, 8],
[11, 12]])
# 行上面截头去尾
arr2[1:-1]
array([[5, 6, 7, 8]])
# 索引和切片混用
# 返回 6元素
arr2[1:-1,1]
array([6])
# 在列上面倒置
arr2[:,::-1]
array([[ 4, 3, 2, 1],
[ 8, 7, 6, 5],
[12, 11, 10, 9]])
# 在行上面倒置
arr2[::-1]
array([[ 9, 10, 11, 12],
[ 5, 6, 7, 8],
[ 1, 2, 3, 4]])
# 在行列上同时进行倒置
arr2[::-1,::-1]
array([[12, 11, 10, 9],
[ 8, 7, 6, 5],
[ 4, 3, 2, 1]])
# 高维数组
arr3
array([[[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]],
[[13, 14, 15, 16],
[17, 18, 19, 20],
[21, 22, 23, 24]],
[[25, 26, 27, 28],
[29, 30, 31, 32],
[33, 34, 35, 36]]])
# 在每个维度上都进行截头去尾
arr3[1:-1, 1:-1, 1:-1]
array([[[18, 19]]])
切片和索引的作用:返回数组中的特定位置元素,或者用来对特定位置的元素进行修改
arr4 = np.arange(1,36).reshape(5,7)
arr4
array([[ 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14],
[15, 16, 17, 18, 19, 20, 21],
[22, 23, 24, 25, 26, 27, 28],
[29, 30, 31, 32, 33, 34, 35]])
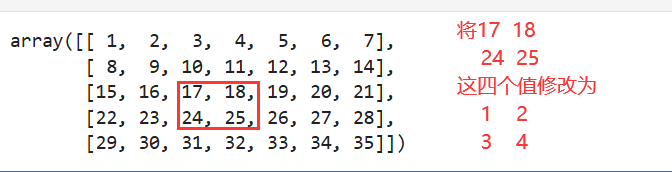
# 定位到指定位置
arr4[2:-1,2:4]
array([[17, 18],
[24, 25]])
# 赋值,可以用一个值
arr4[2:-1,2:4] = 0
arr4
array([[ 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14],
[15, 16, 0, 0, 19, 20, 21],
[22, 23, 0, 0, 26, 27, 28],
[29, 30, 31, 32, 33, 34, 35]])
# 赋值,也可以用和指定位置形状一致的类数组对象进行赋值
arr4[2:-1,2:4] = [[1,2],[3,4]]
arr4
array([[ 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14],
[15, 16, 1, 2, 19, 20, 21],
[22, 23, 3, 4, 26, 27, 28],
[29, 30, 31, 32, 33, 34, 35]])
4.3 花式索引
花式索引:用整数构成的列表/数组 作为数组的索引进行元素的提取
优点:该索引可以按照特定的位置和形状进行元素的访问和重塑
4.3.1 一维数组的花式索引
按照给定的索引中的 列表/数组 中的索引位置,从原始数组中提取元素,再按照 列表/数组 的形状生成一个新的数组
x1 = np.arange(10)
x1
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
要求:提取数组中的1,2,7,返回一个一维的数组
# 方式一:利用普通索引,得到元组,然后转数组 缺点:很麻烦
x1[1],x1[2],x1[7]
(1, 2, 7)
np.array([x1[1],x1[2],x1[7]])
array([1, 2, 7])
# 错误写法:直接得到3个数
# x1[1,2,7]
# IndexError: too many indices for array: array is 1-dimensional, but 3 were indexed
# 方式二:花式索引,用整数构成的列表(只能在数组中使用)
x1[[1,2,7]]
array([1, 2, 7])
花式索引的索引值只要在数组的有效索引中均可使用,不需要考虑顺序和重复问题,即按照给定的索引提取元素,构建一个新的数组
# 例如
x1[[1,5,2,6,1,8,2,1,5]]
array([1, 5, 2, 6, 1, 8, 2, 1, 5])
# 索引超出有效范围,报错
# x1[[28,4,1,6,2]]
# IndexError: index 28 is out of bounds for axis 0 with size 10
花式索引:可以改变数组的形状
index1 = np.array([
[5,1],
[2,1]
])
# 二维数组
index1
array([[5, 1],
[2, 1]])
x1[index1]
# 按 index1 的索引提取元素,再按照 index1 的形状构建一个新的二维数组
array([[5, 1],
[2, 1]])
x1x = x1 *7
x1x
array([ 0, 7, 14, 21, 28, 35, 42, 49, 56, 63])
x1x[index1]
array([[35, 7],
[14, 7]])
4.3.2 多维数组的花式索引(二维⭐⭐⭐)
x2 = np.arange(20).reshape(4,5)
x2
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
# 提取第一行和第二行
# 方式一:切片
x2[:2]
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
# 方式二:花式索引
x2[[0,1]]
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
# 提取第二、四、五列
# 方式:花式索引,也遵循多维数组索引的书写规则:靠后的维度不处理,可以省略,靠前的维度不处理,不能省略
x2[:, [1,3,4]]
# 含义:所有的行,特定的列
array([[ 1, 3, 4],
[ 6, 8, 9],
[11, 13, 14],
[16, 18, 19]])
# 在行和列上同时使用花式索引
x2[[0,1,3],[0,2,4]]
array([ 0, 7, 19])
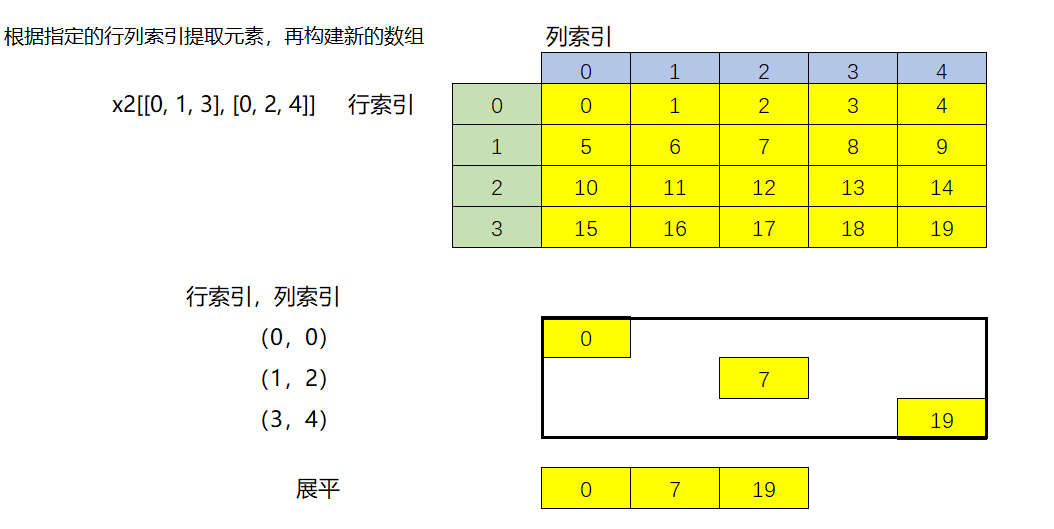
注意:
- 二维数组在行和列上同时使用花式索引,本质上是按照花式索引中行和列的对应索引位置提取元素,再用这些元素构成一个新的数组,返回的结果是一个一维数组
- 行和列上的元素要一致
- 花式索引也要在有效范围之内
4.4 条件索引(布尔索引)
条件索引:使用条件表达式作为数组的索引
按照特定条件对数据进行筛选
4.4.1 一维数组的条件索引
x1
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 找出数组中大于5的数字,构建一个新的数组
数组可以直接进行运算
x1 + 10
array([10, 11, 12, 13, 14, 15, 16, 17, 18, 19])
x1 ** 3
array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729], dtype=int32)
# 比较运算
x1 > 5
# 返回的结果是一个布尔数组
array([False, False, False, False, False, False, True, True, True,
True])
index_bool = x1 > 5
# index_bool作为数组的索引
x1[index_bool]
# 用布尔数组作为数组的索引,会将数组中对应布尔数组中 值为True 位置的元素提取出来,构成一个新的数组
array([6, 7, 8, 9])
# 简化
x1[x1 > 5]
# 返回数组中符合条件的元素
array([6, 7, 8, 9])
需求:将数组中>5的数字转换为1,<=5的数字转换为0(特征二值化)
x1[x1 <= 5]
array([0, 1, 2, 3, 4, 5])
x1[x1 <= 5] = 0
x1[x1 >5] = 1
x1
array([0, 0, 0, 0, 0, 0, 1, 1, 1, 1])
# 如果先将大于5的转换成1,再将小于5的转换为0,得到的结果全为0,因为第一步把大于5的值全部转换为小于5的1
x1[x1 >5] = 1
x1[x1 <= 5] = 0
x1
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
4.4.2 二维数组的条件索引
x2
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
x2 > 5
array([[False, False, False, False, False],
[False, True, True, True, True],
[ True, True, True, True, True],
[ True, True, True, True, True]])
# 找出x2中 > 5 的元素
x2[x2 > 5]
# 返回的结果是一个一维数组,因为得到的True的形状不是一个规范的二维数组的结构
array([ 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19])
在二维数组中,更多的是设定范围
# 找出x2中第四列 > 5的元素
# 先拿到第四列
x2[:,3]
array([ 3, 8, 13, 18])
# 条件索引
x2[:,3] > 5
array([False, True, True, True])
# 将位置和索引进行组合(要同时写上条件和范围)
x2[:, 3][x2[:, 3] > 5]
array([ 8, 13, 18])
# 错误写法:这种是包含所有列的
x2[x2[:,3] > 5]
array([[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
4.4.3 条件索引中的逻辑运算
条件索引中不能直接使用and or not 进行逻辑运算,原因是条件索引得到的结果是集合(数组中满足条件的元素集合),不是布尔值
- & 交集:对应 and,提取两个集合中(数组元素的集合)都存在的元素, 对应sql中的inner join
- | 并集:对应 or,提取两个集合中所有的元素 对应sql中的full join
- ~ 补集:对应 not,从原始数据中提取不在集合中的元素
另外,不同条件的组合需要用()对运算的优先级进行修正,否则会出错
传统的逻辑运算:and / or / not 只能针对布尔值,布尔型数组/普通型数组均无法直接用 and / or / not 进行逻辑运算
# np.array([True, False]) and np.array([True, True])
# ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
# 布尔型数组不能直接做逻辑运算
# np.array([1, 2, 3]) and np.array([2, 3, 4])
# ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
# 数组不能直接进行逻辑运算,因为数组是一个集合对象
# 正确写法,利用 & / | / ~,这三个操作是针对条件,而不是针对数组
需求:找出x2中第四列中 >4 的数字或奇数
# 第四列中>4的数字
x2[:,3][x2[:,3] > 4]
array([ 8, 13, 18])
# 第四列中的奇数
x2[:,3][x2[:,3] % 2 == 1]
array([ 3, 13])
# x2[:,3][x2[:,3] > 4] | x2[:,3][x2[:,3] % 2 == 1]
# 注意:交并补最好是针对条件进行组合,尽量不要针对数组
# ValueError: operands could not be broadcast together with shapes (3,) (2,)
x2[:,3][(x2[:, 3] > 4) | (x2[:, 3] % 2 == 1)]
# 1.先确定范围
# 2.再写条件,不同的条件需要用()括起来,保证运算的优先级
# 3.最后写逻辑运算 并集 |
array([ 3, 8, 13, 18])
需求:找第四列中 > 4的奇数
x2[:,3][(x2[:, 3] > 4) & (x2[:, 3] % 2 == 1)]
array([13])
需求:找出x2第四列中的偶数
# 求奇数的补集
x2[:,3][~ (x2[:,3] % 2 == 1)]
array([ 8, 18])
五、数组的维度处理
5.1 维度的扩充(低维变高维(一维变多维⭐⭐⭐))
5.1.1 reshape方法
np.reshape(a, newshape, order='C')
a.reshape(shape, order='C')
说明:
(1)a:要调整维度的数组,如果写成array.reshape,则可以省略
(2)newshape:要改变的维度,用元组形式,注意改变维度前后数组的元素要保持一致
(3)reshape返回新的改变了维度的数组
需求:24个元素的一维数组,扩充成2层3行4列
arr1 = np.arange(24)
arr1
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23])
arr1.reshape(2,3,4)
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
arr1a = arr1.reshape(2,3,4)
arr1a
# reshape是生成了一个新的数组,并不影响原始的数组
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
np.reshape(arr1,(2,3,4))
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
arr1a.shape
(2, 3, 4)
arr1.shape
# get 获取对象的属性的值
(24,)
5.1.2 shape属性
ndarray.shape = newshape
说明:newshape:要改变的维度,用元组形式
注意:
- 改变维度前后数组的元素要保持一致
- 该操作直接作用于原始的数组,不会生成新的数组
arr1
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23])
需求:将arr1变为三行八列
arr1.shape = (3, 8)
# set 对对象的属性进行赋值,直接作用域
arr1
array([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15],
[16, 17, 18, 19, 20, 21, 22, 23]])
# 也可以通过负数进行自动计算
arr1.shape = (6, -1)
arr1
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]])
5.1.3 resize方法
np.resize(a, newshape)
a.resize(newshape)
说明:
(1)a:要调整维度的数组,如果写成array.resize,则可以省略
(2)newshape:要改变的维度,用元组形式,注意改变维度前后数组的元素要保持一致
(3)当用array.resize时,没有返回值,即直接修改原始的数组
arr1
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]])
arr1.shape
(6, 4)
arr1.resize(3, 8)
arr1
array([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15],
[16, 17, 18, 19, 20, 21, 22, 23]])
resize和reshape、shape的区别:
resize中不能用负数进行自动维度计算
5.1.4 副本和视图
副本是一个数据的完整的拷贝,如果对副本进行修改,它不会影响到原始数据,物理内存不在同一位置。
视图是数据的一个别称或引用,通过该别称或引用亦便可访问、操作原有数据,但原有数据不会产生拷贝。如果我们对视图进行修改,它会影响到原始数据,物理内存在同一位置。
再论reshape:用reshape表面上看是返回了一个新的数组,但实质上只是修改了数组的维度,数组本身的元素并未收到影响,reshape修改的是数组的视图,用reshape得到的数组和原始的数组在底层的数据上是共享的。针对reshape修改前后的数组进行数据的改变,另一个数组也会随之而发生改变。
arr1a
# 通过对arr1进行reshape得到的,是arr1的视图
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
arr1
array([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15],
[16, 17, 18, 19, 20, 21, 22, 23]])
将arr1的第一个元素修改为999
arr1[0, 0] = 999
arr1
array([[999, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15],
[ 16, 17, 18, 19, 20, 21, 22, 23]])
arr1a
# arr1a和arr1底层的数据是共享的
array([[[999, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[ 12, 13, 14, 15],
[ 16, 17, 18, 19],
[ 20, 21, 22, 23]]])
arr1a[-1,-1]= -1
arr1a
array([[[999, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[ 12, 13, 14, 15],
[ 16, 17, 18, 19],
[ -1, -1, -1, -1]]])
arr1
array([[999, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15],
[ 16, 17, 18, 19, -1, -1, -1, -1]])
arr1和arr1a之间互为视图的关系,底层的数据是共享的,其中任意一个发生改变,会影响到另外一个
如何得到数组的副本:利用copy方法,可以得到数组的副本,即不和原始数组共享底层数据的新对象
arr1a
# 视图
array([[[999, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[ 12, 13, 14, 15],
[ 16, 17, 18, 19],
[ -1, -1, -1, -1]]])
arr1c = arr1a.copy()
# 副本
arr1c
array([[[999, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[ 12, 13, 14, 15],
[ 16, 17, 18, 19],
[ -1, -1, -1, -1]]])
arr1a[0,0,0] =0
arr1
array([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15],
[16, 17, 18, 19, -1, -1, -1, -1]])
arr1a
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[-1, -1, -1, -1]]])
arr1c
array([[[999, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[ 12, 13, 14, 15],
[ 16, 17, 18, 19],
[ -1, -1, -1, -1]]])
arr1c[-1,-1,-1] = 1000
arr1c
array([[[ 999, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[ 12, 13, 14, 15],
[ 16, 17, 18, 19],
[ -1, -1, -1, 1000]]])
arr1a
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[-1, -1, -1, -1]]])
arr1c是arr1a的副本,和arr1a之间的底层数据不共享,修改的时候也互不影响
5.2 维度的收缩
5.2.1 ndarray.ravel方法
a.ravel()
说明:ravel返回的结果是视图
会将多维数组展平为一维数组,其作用是为了方便对数组的元素进行遍历
arr1
array([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15],
[16, 17, 18, 19, -1, -1, -1, -1]])
arr1.shape
(3, 8)
arr1r = arr1.ravel()
arr1r
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, -1, -1, -1, -1])
arr1r.shape
(24,)
arr1r[9] = 1000
arr1r和arr1互为视图的关系,共享底层数据,改变一个中的数据的值,另一个相应改变
arr1r
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 1000, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, -1, -1,
-1, -1])
arr1
array([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 1000, 10, 11, 12, 13, 14, 15],
[ 16, 17, 18, 19, -1, -1, -1, -1]])
5.2.2 ndarray.flatten方法
a.flatten()
说明:flatten返回的结果是副本
arr1
array([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 1000, 10, 11, 12, 13, 14, 15],
[ 16, 17, 18, 19, -1, -1, -1, -1]])
arr1f = arr1.flatten()
arr1f
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 1000, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, -1, -1,
-1, -1])
arr1f[0] = 999
arr1f和arr1相互不会产生影响
arr1f
array([ 999, 1, 2, 3, 4, 5, 6, 7, 8, 1000, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, -1, -1,
-1, -1])
arr1
array([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 1000, 10, 11, 12, 13, 14, 15],
[ 16, 17, 18, 19, -1, -1, -1, -1]])
展平为一维数组,其作用是为了方便对数组的元素进行遍历
# 遍历arr1中的每个元素,直接遍历多维数组,遍历到的是比该数组的维度少一维的子数组
for item in arr1:
print(item)
[0 1 2 3 4 5 6 7]
[ 8 1000 10 11 12 13 14 15]
[16 17 18 19 -1 -1 -1 -1]
# 使用嵌套可以遍历每一个元素,但是比较麻烦
for sub_arr in arr1:
for each in sub_arr:
print(each)
0
1
2
3
4
5
6
7
8
1000
10
11
12
13
14
15
16
17
18
19
-1
-1
-1
-1
for item in arr1.flatten():
print(item)
0
1
2
3
4
5
6
7
8
1000
10
11
12
13
14
15
16
17
18
19
-1
-1
-1
-1
如果只需要遍历数组,可以直接使用flat属性,该属性返回一个展平后的迭代器,可以通过循环遍历
arr1.flat
<numpy.flatiter at 0x29e09f512c0>
for each in arr1.flat:
print(each)
0
1
2
3
4
5
6
7
8
1000
10
11
12
13
14
15
16
17
18
19
-1
-1
-1
-1
5.2.3 使用reshape/resize方法和reshape属性进行展平
arr1
array([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 1000, 10, 11, 12, 13, 14, 15],
[ 16, 17, 18, 19, -1, -1, -1, -1]])
arr1.reshape(1,-1)
# 结果是二维数组
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 1000, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, -1, -1,
-1, -1]])
arr1.reshape(-1)
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 1000, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, -1, -1,
-1, -1])
arr1.shape = -1
arr1
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 1000, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, -1, -1,
-1, -1])
5.3 转置(二维数组)
转置的作用:针对一个维度上可以做的操作,另一个维度上不能操作
- pandas中某些操作只能针对列,可以通过转置对行进行操作
- 做删除操作时,只能针对列,可以通过转置进行行的删除
5.3.1 ndarray.transpose()方法
a.transpose()
说明:transpose返回的结果是行列交换后的数组视图
arr1
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 1000, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, -1, -1,
-1, -1])
arr1d = arr1.reshape(4,-1)
arr1d
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 1000, 10, 11],
[ 12, 13, 14, 15, 16, 17],
[ 18, 19, -1, -1, -1, -1]])
arr1d.transpose()
array([[ 0, 6, 12, 18],
[ 1, 7, 13, 19],
[ 2, 8, 14, -1],
[ 3, 1000, 15, -1],
[ 4, 10, 16, -1],
[ 5, 11, 17, -1]])
5.3.2 ndarray.T属性
a.T
说明:T属性返回的结果是行列交换后的数组视图,与transpose方法的效果相同
用transpose()方法和T属性得到的结果都是视图,如果要得到副本,要通过copy实现
arr1t = arr1d.T
arr1t
array([[ 0, 6, 12, 18],
[ 1, 7, 13, 19],
[ 2, 8, 14, -1],
[ 3, 1000, 15, -1],
[ 4, 10, 16, -1],
[ 5, 11, 17, -1]])
六、数组的组合与分割
6.1 数组的组合
numpy可以在水平、垂直或者深度方向进行数组的组合,组合得到的数组与原始数组无关,是新的数组
6.1.1 水平方向的组合
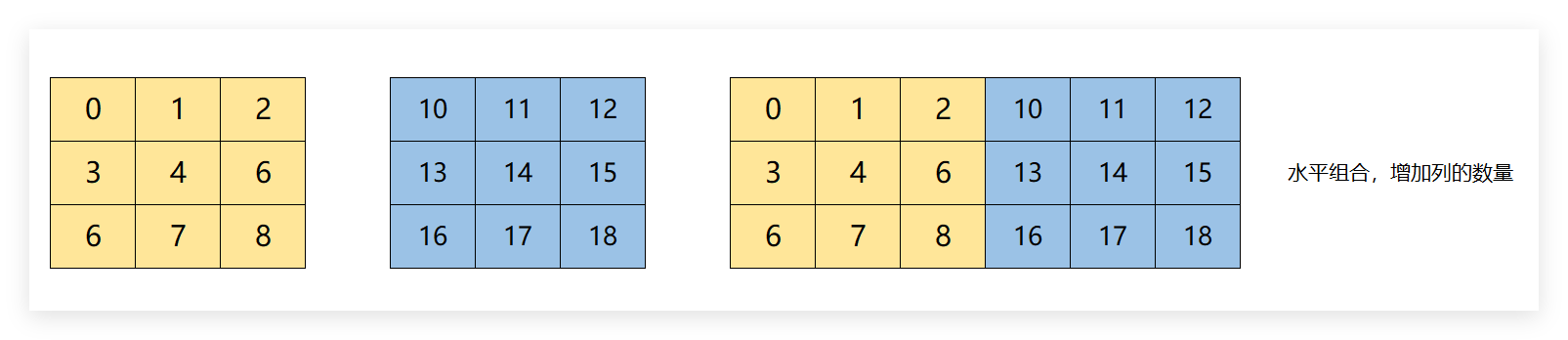
6.1.1.1 hstack进行组合
np.hstack(tup)
说明:
(1)tup:要组合的数组,放在元组中
(2)返回组合后的新数组
# 构建组合的数组
m1 = np.arange(9).reshape(3,3)
m1
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
m2 = np.arange(10,19).reshape(3,3)
m2
array([[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
# 组合不能用运算符进行操作,如果用运算符,是对数组进行计算
m1 + m2
array([[10, 12, 14],
[16, 18, 20],
[22, 24, 26]])
r1 = np.hstack((m1,m2))
r1
array([[ 0, 1, 2, 10, 11, 12],
[ 3, 4, 5, 13, 14, 15],
[ 6, 7, 8, 16, 17, 18]])
6.1.1.2 concatenate进行组合
concatenate((a1, a2, …), axis=1),在哪个维度上进行组合
说明:
(1)tup:要组合的数组,放在元组中
(2)axis:组合操作的轴向,1是垂直轴,注意水平组合是沿着垂直轴向进行的组合(列的组合)
(3)返回组合后的新数组
r1x = np.concatenate((m1,m2),axis = 1)
# axis = 1表示操作是发生在第二个维度上,在二维数组中,axis = 0表示行,axis=1表示列
r1x
array([[ 0, 1, 2, 10, 11, 12],
[ 3, 4, 5, 13, 14, 15],
[ 6, 7, 8, 16, 17, 18]])
6.1.2 垂直方向的组合
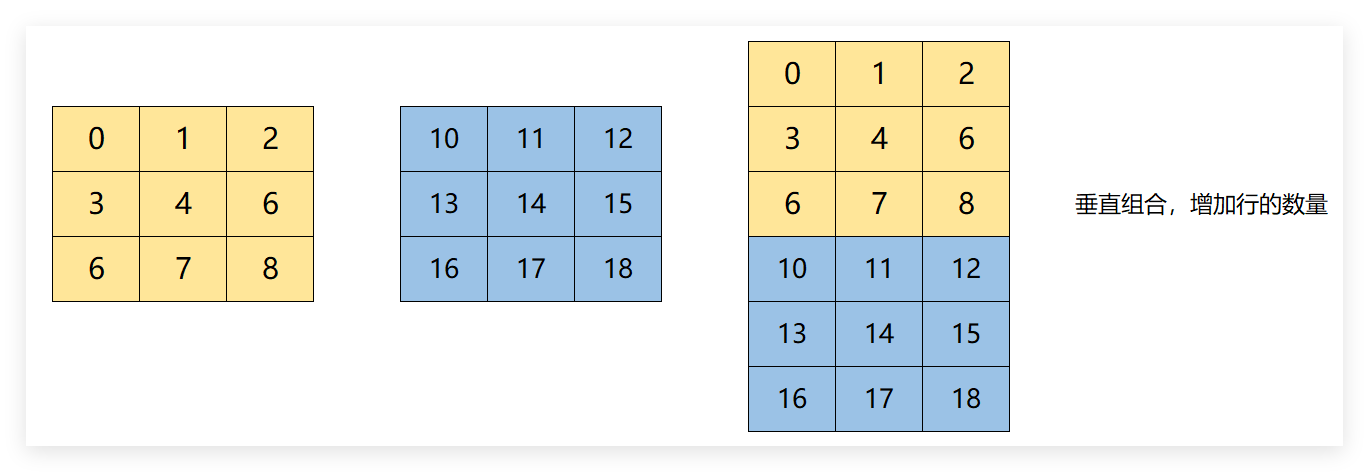
6.1.2.1 通过vstack进行组合
np.vstack(tup)
说明:
(1)tup:要组合的数组,放在元组中
(2)返回组合后的新数组
m1,m2
(array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]]),
array([[10, 11, 12],
[13, 14, 15],
[16, 17, 18]]))
np.vstack((m1,m2))
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
6.1.2.2 通过concatenate进行组合
concatenate((a1, a2, …), axis=0)
说明:
(1)tup:要组合的数组,放在元组中
(2)axis:组合操作的轴向,0是水平轴(默认),注意垂直组合是沿着水平轴向进行的组合(行的组合)
(3)返回组合后的新数组
np.concatenate((m1,m2),axis =0)
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
对于二维数组,水平和垂直组合并不会改变数组的维度数量,只是增加了某个维度的元素数量
6.1.3 深度的组合
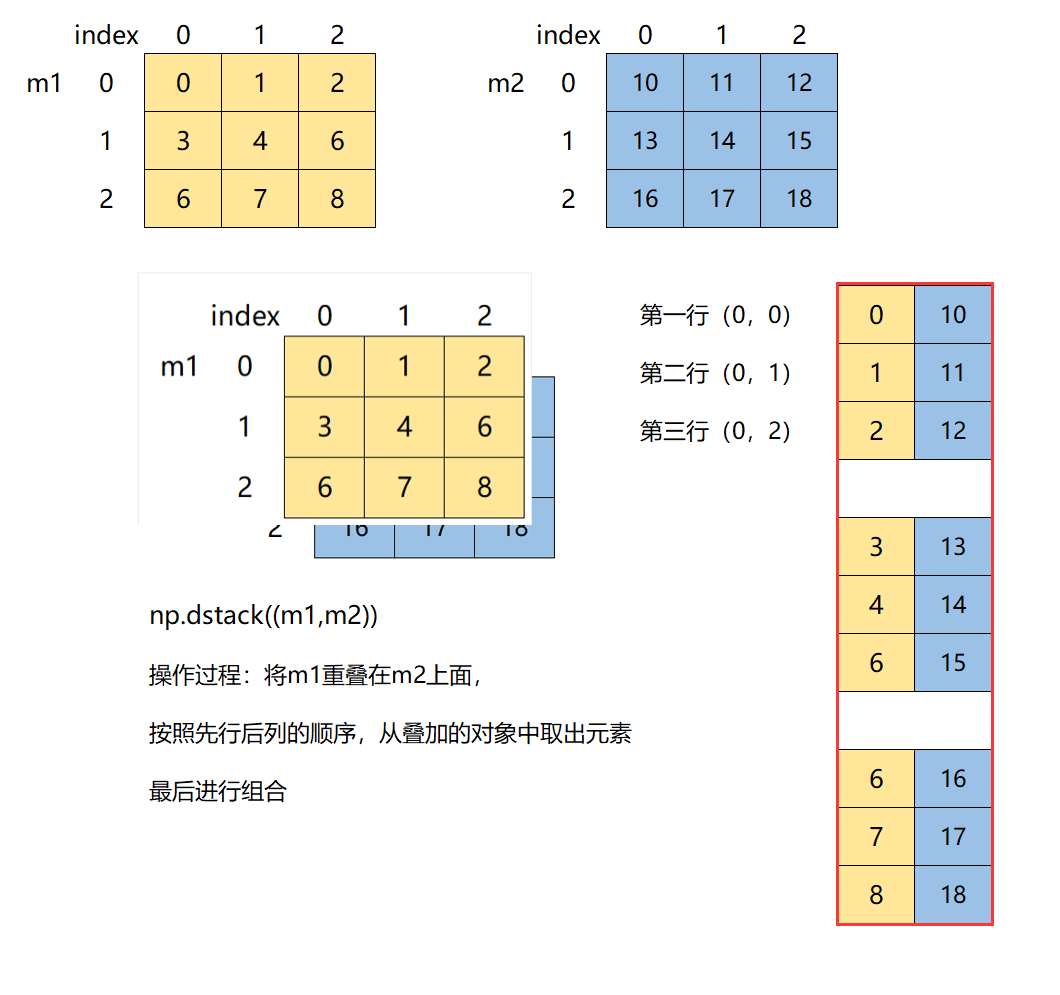
np.dstack(tup)
说明:
(1)tup:要组合的数组,放在元组中
(2)返回组合后的新数组
深度组合会改变数组的维度
r3 = np.dstack((m1,m2))
r3
array([[[ 0, 10],
[ 1, 11],
[ 2, 12]],
[[ 3, 13],
[ 4, 14],
[ 5, 15]],
[[ 6, 16],
[ 7, 17],
[ 8, 18]]])
r3.shape
(3, 3, 2)
6.1.4 列组合与行组合
行组合和列组合指明了组合的方向
np.column_stack(tup)
np.row_stack(tup)
说明:
(1)tup:要组合的数组,放在元组中
(2)返回组合后的新数组
m1,m2
(array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]]),
array([[10, 11, 12],
[13, 14, 15],
[16, 17, 18]]))
在二维上面,row_stack等价于垂直组合,column_stack等价于水平组合
np.row_stack((m1,m2))
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
# 等价于
np.vstack((m1,m2))
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
np.column_stack((m1,m2))
array([[ 0, 1, 2, 10, 11, 12],
[ 3, 4, 5, 13, 14, 15],
[ 6, 7, 8, 16, 17, 18]])
# 等价于
np.hstack((m1,m2))
array([[ 0, 1, 2, 10, 11, 12],
[ 3, 4, 5, 13, 14, 15],
[ 6, 7, 8, 16, 17, 18]])
在一维数组中,两个一维数组在行上的组合后变成了二维数组,在列上的组合也变成了二维数组,但是一维数组进行水平方向的组合后仍然是一维数组
n1 = np.arange(3)
n1
array([0, 1, 2])
n2 = n1 * 5
n2
array([ 0, 5, 10])
np.row_stack((n1,n2))
array([[ 0, 1, 2],
[ 0, 5, 10]])
# 等价于
np.vstack((n1,n2))
array([[ 0, 1, 2],
[ 0, 5, 10]])
np.column_stack((n1,n2))
array([[ 0, 0],
[ 1, 5],
[ 2, 10]])
np.hstack((n1,n2))
array([ 0, 1, 2, 0, 5, 10])
6.2 数组的分割
分割后的子数组和原始的数组是互为视图的关系
6.2.1 水平分割
6.2.1.1 hsplit实现
np.hsplit(array,indices_or_sections)
说明:
(1)array:要分割的数组
(2)indices_or_sections:分割的方式,如果是整(要被行数或列数整除)数,是进行均匀拆分,如果是数组/列表,是进行不均匀的拆
最终返回分割后的数组构成的列表分
# 构建用来分割的数组
as1 = np.arange(24).reshape(4,6)
as1
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
- 水平均匀分割
rs1 = np.hsplit(as1,2)
rs1
# 返回分割得到的子数组构成的列表
[array([[ 0, 1, 2],
[ 6, 7, 8],
[12, 13, 14],
[18, 19, 20]]),
array([[ 3, 4, 5],
[ 9, 10, 11],
[15, 16, 17],
[21, 22, 23]])]
type(rs1)
list
rs1[0]
array([[ 0, 1, 2],
[ 6, 7, 8],
[12, 13, 14],
[18, 19, 20]])
- 不均匀分割
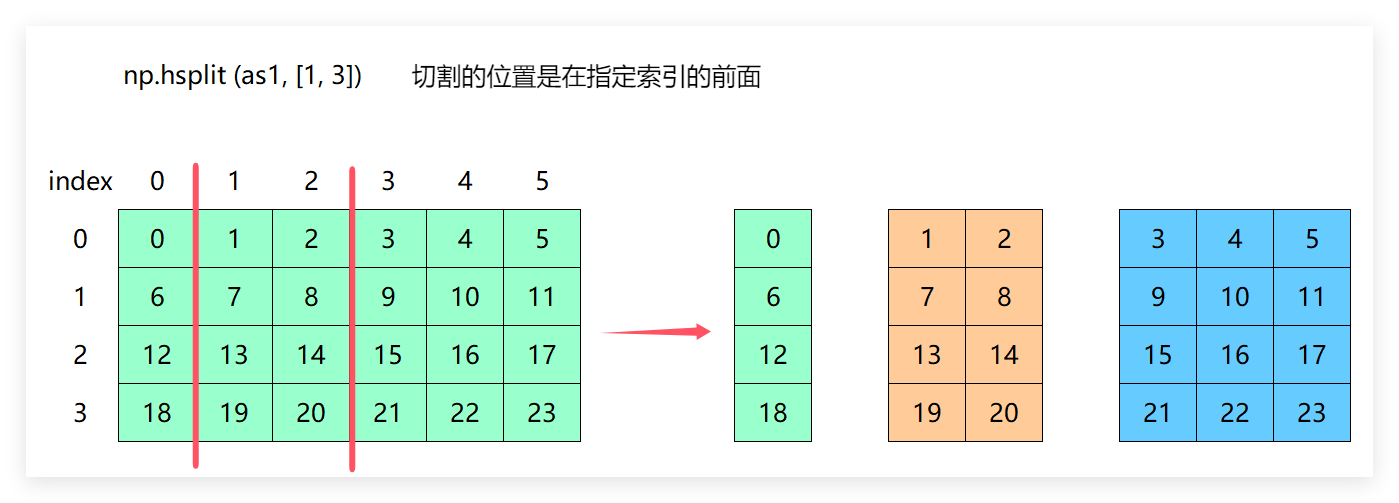
as1
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
rs3 = np.hsplit(as1,[1,3])
rs3
[array([[ 0],
[ 6],
[12],
[18]]),
array([[ 1, 2],
[ 7, 8],
[13, 14],
[19, 20]]),
array([[ 3, 4, 5],
[ 9, 10, 11],
[15, 16, 17],
[21, 22, 23]])]
rs4 = np.hsplit(as1,[0,1,4]) # 因为索引为0时,前面没有数据,在结果中就会出现一个空的子数组
rs4
[array([], shape=(4, 0), dtype=int32),
array([[ 0],
[ 6],
[12],
[18]]),
array([[ 1, 2, 3],
[ 7, 8, 9],
[13, 14, 15],
[19, 20, 21]]),
array([[ 4, 5],
[10, 11],
[16, 17],
[22, 23]])]
6.2.1.2 split实现
np.split(array,indices_or_sections,axis=1)
说明:
(1)array:要分割的数组
(2)indices_or_sections:分割的方式,如果是整数(要被行数或列数整除),是进行均匀拆分,如果是数组/列表,是进行不均匀的拆分
(3)axis:在哪个维度上操作
最终返回分割后的数组构成的列表
- 水平均匀分割
np.split(as1,2,axis = 1)
[array([[ 0, 1, 2],
[ 6, 7, 8],
[12, 13, 14],
[18, 19, 20]]),
array([[ 3, 4, 5],
[ 9, 10, 11],
[15, 16, 17],
[21, 22, 23]])]
- 不均匀分割
rs5 = np.split(as1,[1,3,4],axis = 1) # 因为索引为0时,前面没有数据,在结果中就会出现一个空的子数组
rs5
[array([[ 0],
[ 6],
[12],
[18]]),
array([[ 1, 2],
[ 7, 8],
[13, 14],
[19, 20]]),
array([[ 3],
[ 9],
[15],
[21]]),
array([[ 4, 5],
[10, 11],
[16, 17],
[22, 23]])]
6.2.2 垂直分割
6.2.2.1 vsplit实现
np.vsplit(array,indices_or_sections)
说明:
(1)array:要分割的数组
(2)indices_or_sections:分割的方式,如果是整数,是进行均匀拆分,如果是数组/列表,是进行不均匀的拆分
最终返回分割后的数组构成的列表
- 均匀分割
np.vsplit(as1,2)
[array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11]]),
array([[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])]
- 不均匀分割
np.vsplit(as1,[1,3])
[array([[0, 1, 2, 3, 4, 5]]),
array([[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17]]),
array([[18, 19, 20, 21, 22, 23]])]
6.2.2.2 split实现
np.split(array,indices_or_sections,axis=0)
说明:
(1)array:要分割的数组
(2)indices_or_sections:分割的方式,如果是整数,是进行均匀拆分,如果是数组/列表,是进行不均匀的拆分
(3)axis:在哪个维度上操作
最终返回分割后的数组构成的列表
- 均匀分割
np.split(as1,4,axis = 0)
[array([[0, 1, 2, 3, 4, 5]]),
array([[ 6, 7, 8, 9, 10, 11]]),
array([[12, 13, 14, 15, 16, 17]]),
array([[18, 19, 20, 21, 22, 23]])]
- 不均匀分割
np.split(as1,[3,4],axis = 0)
[array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17]]),
array([[18, 19, 20, 21, 22, 23]]),
array([], shape=(0, 6), dtype=int32)]
6.2.3 深度分割:dsplit
np.dsplit(array,indices_or_sections)
说明:
(1)array:要分割的数组
(2)indices_or_sections:分割的方式,如果是整数,是进行均匀拆分,如果是数组/列表,是进行不均匀的拆分
(3)返回分割后的数组构成的列表
(4)深度分割要用在3维以上的数组⭐
# 在二维数组上进行深度分割会报错
# np.dsplit(as1,2)
# ValueError: dsplit only works on arrays of 3 or more dimensions
# 构建一个三维数组
split1 = np.arange(64).reshape(4,4,4)
split1
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]],
[[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]],
[[32, 33, 34, 35],
[36, 37, 38, 39],
[40, 41, 42, 43],
[44, 45, 46, 47]],
[[48, 49, 50, 51],
[52, 53, 54, 55],
[56, 57, 58, 59],
[60, 61, 62, 63]]])
split1.ndim
3
np.dsplit(split1,2)
[array([[[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]],
[[16, 17],
[20, 21],
[24, 25],
[28, 29]],
[[32, 33],
[36, 37],
[40, 41],
[44, 45]],
[[48, 49],
[52, 53],
[56, 57],
[60, 61]]]),
array([[[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]],
[[18, 19],
[22, 23],
[26, 27],
[30, 31]],
[[34, 35],
[38, 39],
[42, 43],
[46, 47]],
[[50, 51],
[54, 55],
[58, 59],
[62, 63]]])]
as1
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
r1 = rs1[0]
r1
array([[ 0, 1, 2],
[ 6, 7, 8],
[12, 13, 14],
[18, 19, 20]])
r2 = rs1[1]
r2
array([[ 3, 4, 5],
[ 9, 10, 11],
[15, 16, 17],
[21, 22, 23]])
as1[0,0] = 999
as1
array([[999, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[ 12, 13, 14, 15, 16, 17],
[ 18, 19, 20, 21, 22, 23]])
r1
array([[999, 1, 2],
[ 6, 7, 8],
[ 12, 13, 14],
[ 18, 19, 20]])
深度分割:dsplit
np.dsplit(array,indices_or_sections)
说明:
(1)array:要分割的数组
(2)indices_or_sections:分割的方式,如果是整数,是进行均匀拆分,如果是数组/列表,是进行不均匀的拆分
(3)返回分割后的数组构成的列表
(4)深度分割要用在3维以上的数组⭐
# 在二维数组上进行深度分割会报错
# np.dsplit(as1,2)
# ValueError: dsplit only works on arrays of 3 or more dimensions
# 构建一个三维数组
split1 = np.arange(64).reshape(4,4,4)
split1
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]],
[[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]],
[[32, 33, 34, 35],
[36, 37, 38, 39],
[40, 41, 42, 43],
[44, 45, 46, 47]],
[[48, 49, 50, 51],
[52, 53, 54, 55],
[56, 57, 58, 59],
[60, 61, 62, 63]]])
split1.ndim
3
np.dsplit(split1,2)
[array([[[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]],
[[16, 17],
[20, 21],
[24, 25],
[28, 29]],
[[32, 33],
[36, 37],
[40, 41],
[44, 45]],
[[48, 49],
[52, 53],
[56, 57],
[60, 61]]]),
array([[[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]],
[[18, 19],
[22, 23],
[26, 27],
[30, 31]],
[[34, 35],
[38, 39],
[42, 43],
[46, 47]],
[[50, 51],
[54, 55],
[58, 59],
[62, 63]]])]
as1
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
r1 = rs1[0]
r1
array([[ 0, 1, 2],
[ 6, 7, 8],
[12, 13, 14],
[18, 19, 20]])
r2 = rs1[1]
r2
array([[ 3, 4, 5],
[ 9, 10, 11],
[15, 16, 17],
[21, 22, 23]])
as1[0,0] = 999
as1
array([[999, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[ 12, 13, 14, 15, 16, 17],
[ 18, 19, 20, 21, 22, 23]])
r1
array([[999, 1, 2],
[ 6, 7, 8],
[ 12, 13, 14],
[ 18, 19, 20]])