在本文中,我们将深入探讨神经网络背景下的 MAC(乘法累加运算)和 FLOP(浮点运算)概念。通过学习如何使用笔和纸手动计算这些内容,你将对各种网络结构的计算复杂性和效率有基本的了解。
这是 colab 笔记本中一个功能齐全的示例。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、为什么要计算MAC和FLOP
首先让我们看下MAC和FLOP的定义。
- FLOP:FLOP(浮点运算)可视为加法、减法、乘法或除法运算。
- MAC:MAC(乘法累加)运算本质上是乘法后跟加法,即 MAC = a * b + c。它算作两个 FLOP(一个用于乘法,一个用于加法)。
解 MAC 和 FLOP 不仅仅是一项学术活动;它是优化神经网络性能和效率的关键组成部分。它有助于设计计算效率高且有效的模型,最终在训练和推理阶段节省时间和资源。
- 资源效率。了解 FLOP 有助于估计神经网络的计算成本。通过优化 FLOP 的数量,可以减少训练或运行神经网络所需的时间。
- 内存效率。MAC 操作通常决定网络的内存使用量,因为它们与网络中的参数和激活数量直接相关。减少 MAC 有助于提高网络内存效率。
- 功率效率。FLOP 和 MAC 操作都会影响运行神经网络的硬件的功耗。通过优化这些指标,可以潜在地降低运行网络的能耗,这在移动和嵌入式设备中尤为重要。
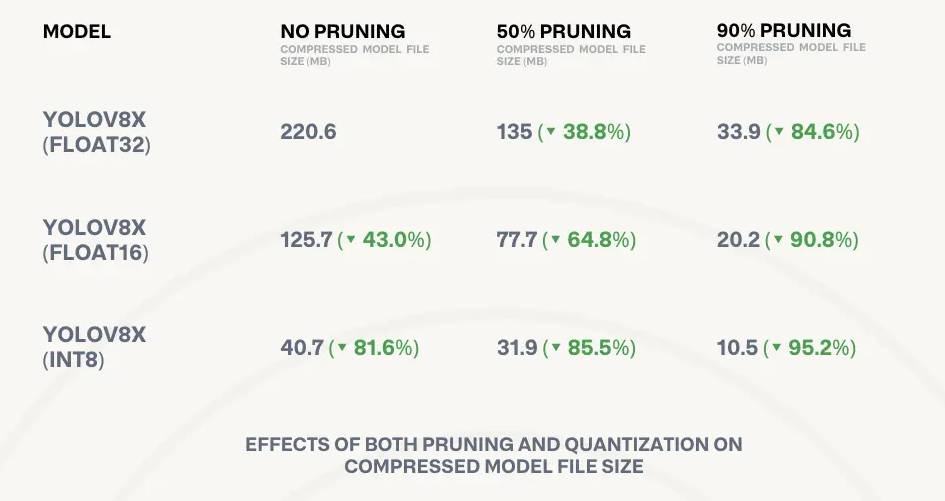
- 修剪和量化。了解 FLOP 和 MAC 有助于通过修剪(删除不必要的连接)和量化(降低权重和激活的精度)等技术优化神经网络,旨在降低计算和内存成本。
- 模型之间的比较。FLOP 和 MAC 提供了一种比较不同模型的计算复杂度的方法,这可以作为选择特定应用模型的标准。
- 硬件基准测试。这些指标还可用于对不同硬件平台在运行神经网络时的性能进行基准测试。
- 实时应用。对于实时应用,尤其是在计算资源有限的边缘设备上,理解和优化这些指标对于确保网络能够在应用的时间限制内运行至关重要。
- 电池寿命。在电池供电的设备中,降低神经网络的计算成本(从而降低能耗)有助于延长电池寿命。
- 设计新算法。研究人员可以在开发新算法或神经网络架构时使用这些指标作为指导方针,旨在提高计算效率而不牺牲准确性。
2、神经网络层的MAC和FLOP计算
接下来让我们计算浮点运算或乘法累加运算的数量,以了解每层的计算复杂度。
2.1 全连接层(密集层)
现在,我们将创建一个具有 3 层的简单神经网络,并开始计算所涉及的运算。以下是计算第一线性层(即全连接(或密集)层)中的运算的公式:
对于具有 I 个输入和 O 个输出的全连接层,运算数量如下:
- MAC:I × O
- FLOP:2 × (I × O)(因为每个 MAC 算作两个 FLOP)
class SimpleLinearModel(nn.Module):
def __init__(self):
super(SimpleLinearModel,self).__init__()
self.fc1 = nn.Linear(in_features=10, out_features=20, bias=False)
self.fc2 = nn.Linear(in_features=20, out_features=15, bias=False)
self.fc3 = nn.Linear(in_features=15, out_features=1, bias=False)
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
F.relu(x)
x = self.fc3(x)
return x
linear_model = SimpleLinearModel().cuda()
sample_data = torch.randn(1, 10).cuda()步骤 1:确定层参数对于给定的模型,我们有三个线性层,定义为:
- fc1:10 个输入特征,20 个输出特征
- fc2:20 个输入特征,15 个输出特征
- fc3:15 个输入特征,1 个输出特征
步骤 2:计算 FLOP 和 MAC 现在,计算每个层的 MAC 和 FLOP:
层 fc1:
- MACs = 10 × 20 = 200
- FLOPs = 2 × MACs = 2 × 200 = 400
层 fc2:
- MACs = 20 × 15 = 300
- FLOPs = 2 × MACs = 2 × 300 = 600
层 fc3:
- MACs = 15 × 1 = 15
- FLOPs = 2 × MACs = 2 × 15 = 30
步骤 3:总结结果最后,为了找到单个输入通过整个网络的 MAC 和 FLOP 总数,我们将所有层的结果相加:
- 总 MAC = MACs(fc1) + MACs(fc2) + MACs(fc3) = 200 + 300 + 15 = 515
- 总 FLOP = FLOPs(fc1) + FLOPs(fc2) + FLOPs(fc3) = 400 + 600 + 30 = 1030
我们可以使用 torchprofile 库来验证给定神经网络模型的 FLOP 和 MAC 计算。操作方法如下:
macs = profile_macs(linear_model, sample_data)
print(macs)
#5152.2 卷积神经网络 (CNN)
现在,让我们确定一个简单的卷积模型的 MAC(乘法累加)和 FLOP(浮点运算)。这个计算可能比我们之前使用密集层的示例更复杂一些,主要是由于步幅、填充和内核大小等因素。不过,我会将其分解,以便于我们学习。
class SimpleConv(nn.Module):
def __init__(self):
super(SimpleConv, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1)
self.fc = nn.Linear(in_features=32*28*28, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
x = torch.rand(1, 1, 28, 28).cuda()
conv_model = SimpleConv().cuda()计算卷积运算的重要注意事项:
- 计算卷积核的运算时,务必记住核中的通道数应与输入中的通道数相匹配。例如,如果我们的输入是具有三个颜色通道的 RGB 图像,则核的尺寸将为 3x3x3,以说明输入的三个通道。
- 为了演示的目的,我们将在整个卷积层中保持一致的图像大小。为此,我们将填充值和步幅值都设置为 1。
步骤 1:识别层参数
对于给定的模型,我们有两个卷积层和一个线性层,定义为:
- conv1:1 个输入通道,16 个输出通道,核大小为 3
- conv2:16 个输入通道,32 个输出通道
- fc:322828 个输入特征,1 个输出特征。因为我们的图像在卷积层中没有改变
步骤 2:计算 FLOP 和 MAC 现在,计算每个层的 MAC 和 FLOP:
公式为 output_image_size * kernel shape * output_channels
Layer conv1:
- MACs = 28 * 28 * 3 * 3 * 1 * 16 = 1,12,896
- FLOPs = 2 × MACs = 2 × 200 = 2,25,792
Layer conv2:
- MACs = 28 × 28 * 3 * 3 * 16 * 32 = 3,612,672
- FLOPs = 2 × MACs = 2 × 300 = 600 = 7,225,344
Layer fc:
- MACs = 32 * 28 * 28 * 10 = 250,880
- FLOPs = 2 × MACs = 2 × 15 = 501,760
步骤 3:总结结果最后,为了找到单个输入通过整个网络的 MAC 和 FLOP 总数,我们将所有层的结果相加:
- 总 MAC = MACs(conv1) + MACs(conv2) + MACs(fc) = 1,12,896 + 3,612,672 + 250,880 = 39,76,448
- 总 FLOPs = FLOPs(fc1) + FLOPs(fc2) + FLOPs(fc3) = 2,25,792 + 7,225,344 + 501,760 = 7,952,896
使用 torchprofile 库验证操作:
macs = profile_macs(conv_model,(x,))
print(macs)
#39764482.3 自注意力模块
在介绍了线性层和卷积层的 MAC 之后,我们的下一步是确定自注意力模块的 FLOP(浮点运算),这是大型语言模型中的关键组件。此计算对于理解此类模型的计算复杂性至关重要。让我们深入研究一下。
class SimpleAttentionBlock(nn.Module):
def __init__(self, embed_size, heads):
super(SimpleAttentionBlock, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.embed_size, self.embed_size, bias=False)
self.keys = nn.Linear(self.embed_size, self.embed_size, bias=False)
self.queries = nn.Linear(self.embed_size, self.embed_size, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, queries, mask):
N = queries.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]
print(values.shape)
values = self.values(values).reshape(N, self.heads, value_len, self.head_dim)
keys = self.keys(keys).reshape(N, self.heads, key_len, self.head_dim)
queries = self.queries(queries).reshape(N, self.heads, query_len, self.head_dim)
energy = torch.matmul(queries, keys.transpose(-2, -1))
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.nn.functional.softmax(energy, dim=3)
out = torch.matmul(attention, values).reshape(
N, query_len, self.heads * self.head_dim
)
return self.fc_out(out)步骤 1:识别层参数
线性变换
让我们定义 hyper_params
- batch_size = 1
- seq_len = 10
- embed_size = 256
在注意力块中,我们有三个线性变换(用于查询、键和值),最后一个(fc_out)。
- 输入大小:[batch_size, seq_len, embed_size]
- 线性变换矩阵:[embed_size, embed_size]
- MAC:batch_size×seq_len×embed_size×embed_size
查询、键、值线性变换:
- 查询变换的MAC = 1 * 10 * 256 * 256 = 6,55,360
- 键变换的MAC = 1 * 10 * 256 * 256 = 6,55,360
- 值变换的MAC = 1 * 10 * 256 * 256 = 6,55,360
能量计算:查询(重塑)点键(重塑)——点积运算。
- Macs:batch_size×seq_len×seq_len×heads×head_dim
查询和键点积
- MACS = 1 * 10 * 10 * 32 [32 因为 256/8 除以 heads] = 25,600
注意权重和值计算的输出:注意权重点值(重塑)——另一个点积运算。
- Macs:batch_size×seq_len×seq_len×heads×head_dim
注意力和价值点积
- Macs = 1 * 10 * 10 * 32 = 25,600
全连接输出 (fc_out)
- Macs:batch_size×seq_len×heads×head_dim×embed_size
- Macs = 1 * 10 * 8 * 32 * 256 = 6,55,360
步骤 2:总结结果
- 总 MACs = MACs(conv1) + MACs(conv2) + MACs(fc) = 6,55,360 + 6,55,360 + 6,55,360 + 25,600 + 25,600 + 6,55,360 = 26,72,640
- 总计FLOPs = 2 * 总 MAC = 53,45,280
使用 torchprofile 库验证操作:
# Create an instance of the model
model = SimpleAttentionBlock(embed_size=256, heads=8).cuda()
# Generate some sample data (batch of 5 sequences, each of length 10, embedding size 256)
values = torch.randn(1, 10, 256).cuda()
keys = torch.randn(1, 10, 256).cuda()
queries = torch.randn(1, 10, 256).cuda()
# No mask for simplicity
mask = None
# Forward pass with the sample data
macs = profile_macs(model, (values, keys, queries, mask))
print(macs)
#26726403、结束语
在整个计算过程中,我们主要考虑批次大小为 1。但是,需要注意的是,针对较大批次大小缩放 MAC 和 FLOP 非常简单。
要计算批次大小大于 1 的 MAC 或 FLOP,只需将批次大小为 1 时获得的总 MAC 或 FLOP 乘以所需的批次大小值即可。这种缩放允许你估算神经网络模型中各种批次大小的计算要求。
请记住,结果将直接随批次大小线性缩放。例如,如果批次大小为 32,则可以通过将批次大小为 1 的值乘以 32 来获得 MAC 或 FLOP。
原文链接:手算神经网络MAC和FLOP - BimAnt