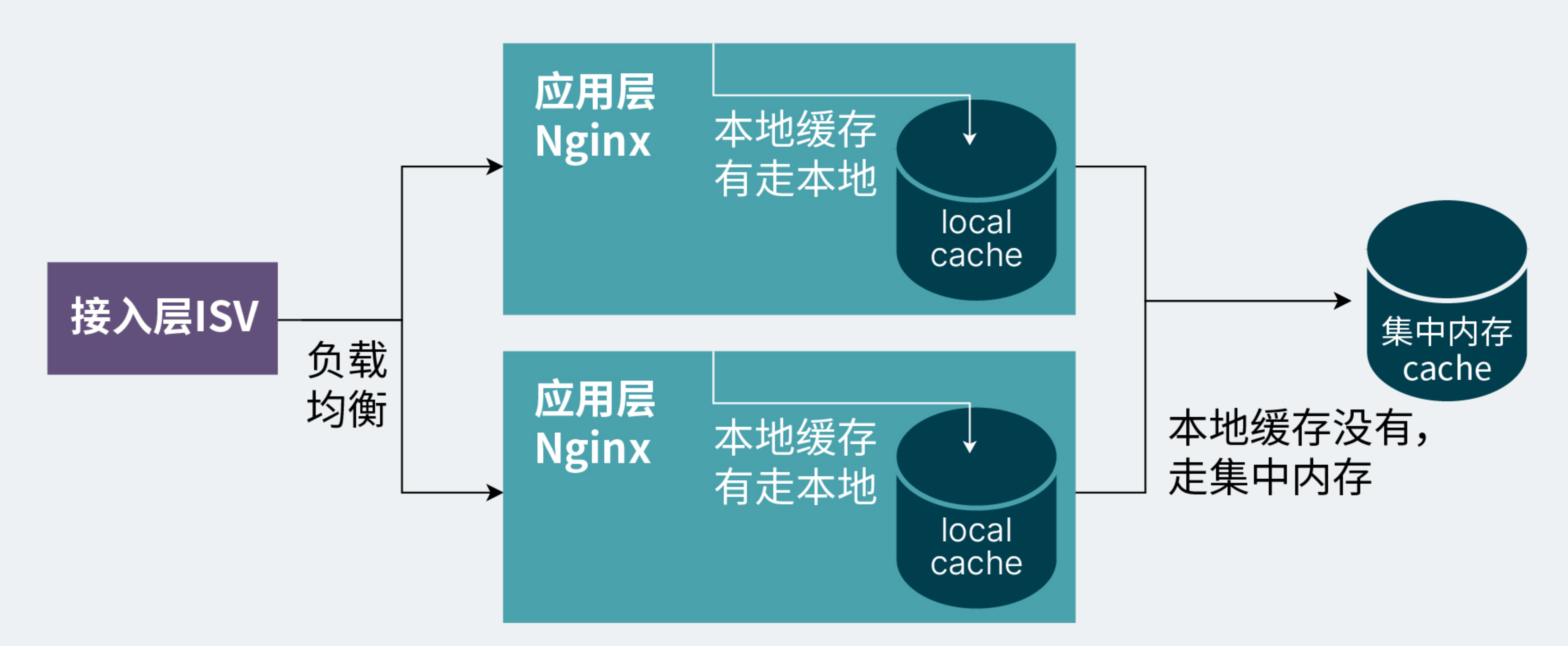
遗留问题
- 设置缓存,已完成
- 获取缓存,已实现
- 删除缓存,已实现
- 查询所有key,带查询参数:active只查激活的,value包含value默认只获取key
- 查询缓存大小
- 清空缓存
- 判断是否为管理员
实现删除缓存的接口
async def delete(req):
"""删除缓存的接口"""
data = await api.req.get_json(req)
key = data.get("key")
admin_cache.delete(key)
return api.resp.success()
测试:
req -X DELETE -d '{\"key\":1}' http://127.0.0.1:8888/zdppy_cache
查询缓存接口
基本设计
批量查询缓存信息:
```bash
# 默认查询所有的key,
req http://127.0.0.1:8888/zdppy_caches
# 只查询未过期的keys
req -d '{\"active\":true}' http://127.0.0.1:8888/zdppy_caches
# 查看key-value格式
req -d '{\"active\":true, \"value\":true}' http://127.0.0.1:8888/zdppy_caches
# 查询详细缓存信息
req -d '{\"active\":true, \"value\":true, \"detail\":true}' http://127.0.0.1:8888/zdppy_caches
先实现默认查询所有的key
async def query(req):
"""查询缓存的接口"""
params = await api.req.get_json(req)
if params.get("error"):
params = None
data = admin_cache.get_all_keys()
return api.resp.success({
"query": params,
"data": data,
})
只查询未过期的
async def query(req):
"""查询缓存的接口"""
params = await api.req.get_json(req)
data = []
if params.get("error"):
params = None
# 查询所有的key
data = admin_cache.get_all_keys()
elif params.get("active"):
# 只查询未过期的
data = admin_cache.get_all_keys(True)
return api.resp.success({
"query": params,
"data": data,
})
设置缓存:
req -X POST -d '{\"key\":1,\"value\":111, \"expire\": 1}' http://127.0.0.1:8888/zdppy_cache
req -X POST -d '{\"key\":2,\"value\":222, \"expire\": 2}' http://127.0.0.1:8888/zdppy_cache
req -X POST -d '{\"key\":3,\"value\":333, \"expire\": 333}' http://127.0.0.1:8888/zdppy_cache
先查询所有的key:
req http://127.0.0.1:8888/zdppy_caches
只查询未过期的key:
req -d '{\"active\":true}' http://127.0.0.1:8888/zdppy_caches
自动清理缓存的逻辑
底层核心代码
def _cull(self, now, sql, cleanup, limit=None):
"""
这个方法是用来清空过期缓存的,无论是否超过限制
:param now: 当前时间的秒值,浮点数
:param sql: 执行清除的SQL语句
:param cleanup: 要清除的文件夹(缓存对象)
:param limit: 限制多少
"""
cull_limit = self.cull_limit if limit is None else limit
if cull_limit == 0:
return
# 查询已经过期的key
select_expired_template = (
'SELECT %s FROM Cache'
' WHERE expire_time IS NOT NULL AND expire_time < ?'
' ORDER BY expire_time LIMIT ?'
)
select_expired = select_expired_template % 'filename'
rows = sql(select_expired, (now, cull_limit)).fetchall()
if rows:
# 如果查询到了就删除
delete_expired = 'DELETE FROM Cache WHERE rowid IN (%s)' % (
select_expired_template % 'rowid'
)
sql(delete_expired, (now, cull_limit))
for (filename,) in rows:
cleanup(filename)
cull_limit -= len(rows)
if cull_limit == 0:
return
# Evict keys by policy.
select_policy = EVICTION_POLICY[self.eviction_policy]['cull']
if select_policy is None or self.volume() < self.size_limit:
return
select_filename = select_policy.format(fields='filename', now=now)
rows = sql(select_filename, (cull_limit,)).fetchall()
if rows:
delete = 'DELETE FROM Cache WHERE rowid IN (%s)' % (
select_policy.format(fields='rowid', now=now)
)
sql(delete, (cull_limit,))
for (filename,) in rows:
cleanup(filename)
现在的问题
我们每次set的时候,它都会触发,默认会删除最早过期的十个缓存。
这样不太合理?
因为我只有三个缓存,但是因为过期时间可能比较短,会导致每次set的时候,另一个都可能被删除,这样的库里面找不到全量的记录。
这个方法默认只删除十条,少的时候删除了不爽。多的时候,比如一下子几百个过期,只删除10条好像也没啥用?
你拿过期的缓存来干啥?
- 1、开发运维的时候可以查询
- 2、可以感知到别人的攻击,留底别人的记录,比如一下子多了很多失效的验证码,这属于异常数据,可以被分析出来
什么时候清除合适?
- 1、定时任务,但是这个成本比较高,因为有个定时任务必须随时跑着,可能需要消耗不少系统资源
- 2、通过物理上限,也就是size_limit这个参数去控制,这个是比较合理的
size_limit 到底有没有生效?
通过全局密码搜索,我们可以发现,只有_cull这个方法用到了size_limit这个参数。

这段代码是:
# 根据policy执行删除
# least-recently-stored
select_policy = EVICTION_POLICY[self.eviction_policy]['cull']
# 默认是:SELECT {fields} FROM Cache ORDER BY store_time LIMIT ?
if select_policy is None or self.volume() < self.size_limit:
return
select_filename = select_policy.format(fields='filename', now=now)
rows = sql(select_filename, (cull_limit,)).fetchall()
if rows:
delete = 'DELETE FROM Cache WHERE rowid IN (%s)' % (
select_policy.format(fields='rowid', now=now)
)
sql(delete, (cull_limit,))
for (filename,) in rows:
cleanup(filename)
这里的代码从理论上来说是没啥问题的,但是确实不太符合如下需求:
- 1、开发运维的时候可以查询已过期的缓存
- 2、可以感知到别人的攻击,留底别人的记录,比如一下子多了很多失效的验证码,这属于异常数据,可以被分析出来
得出结论:这个方法应该被优化。
怎么优化?
- 1、set的时候执行的清空缓存的逻辑,没有必要特别的复杂,我们只希望,如果超过了size_limit,则清空缓存。
- 2、到底清空多少呢?
- 1、最早过期的10,100,1000条
- 2、所有已过期的缓存
- 3、想法:除了最近过期的1000条缓存,其他的都删除!!!
SQL怎么实现清空逻辑
想法:除了最近过期的1000条缓存,其他的都删除!!!
最近的1000条数据的ID。
select id from cache order by add_time desc limit 1000
删除不是这些ID的:ids
delete from cache where id not in ids
核心代码:
DELETE FROM your_table_name WHERE id NOT IN (1, 3, 5);
如果封装成子查询就是:
DELETE FROM your_table_name WHERE id NOT IN (select id from cache order by add_time desc limit 1000);
封装方法
def resize(self):
"""
根据size_limit缓存上限清理缓存
会删除除了最近1000条已过期的缓存以外的其他所有缓存
"""
child_sql = "SELECT rowid FROM Cache ORDER BY expire_time DESC LIMIT 1000"
delete_sql = f'DELETE FROM Cache WHERE rowid NOT IN {child_sql}'
self._sql(delete_sql)
测试:sizelimit设置的小一点,比如100。插入2000条1秒过期的数据,查询所有的keys个数。调用resize方法,再查询所有的keys的个数。
from zdppy_cache import Cache
# 实例化缓存对象,指定缓存目录
cache = Cache('tmp')
for i in range(2000):
cache.set(f"k{i}", i, 1)
print(len(cache.get_all_keys()))
cache.resize(1111)
print("resize之后", len(cache.get_all_keys()))
# 关闭缓存对象
cache.close()
清除总结
- 1、delete_all:物理删除,整个文件夹删除
- 2、delte:删除key对应的
- 3、resize:只保留最近limit条删除
需求
- 1、将resize封装为api接口
- 2、查询所有key,带查询参数:active只查激活的,value包含value默认只获取key
- 3、查询缓存大小
- 4、清空缓存
- 5、判断是否为管理员
![[C语言]一、C语言基础](https://i-blog.csdnimg.cn/direct/96c750060199403f83267fb253274983.png)