想象一下,你正站在一座巨大的仓库前。这座仓库不是用来存放普通商品的,而是存储着海量的数据 - 这就是数据仓库。在大数据时代,数据仓库已经成为企业数据管理的核心。但它究竟是什么?又为什么如此重要?让我们一起揭开数据仓库的神秘面纱,探索它与我们熟知的传统数据库有何不同。

目录
- 什么是数据仓库?
- 数据仓库vs传统数据库:关键区别
- 数据仓库的核心特征
- 数据仓库架构深度解析
- 1. 数据源(Data Sources)
- 2. 数据暂存区(Staging Area)
- 3. ETL层(Extract, Transform, Load)
- 4. 核心数据仓库(Core Data Warehouse)
- 5. 数据集市(Data Marts)
- 6. 元数据仓库(Metadata Repository)
- 7. 前端工具(Front-end Tools)
- 数据仓库的ETL过程
- 1. 提取(Extract)
- 2. 转换(Transform)
- 3. 加载(Load)
- ETL最佳实践
- 数据建模技术:维度建模详解
- 事实表(Fact Table)
- 维度表(Dimension Table)
- 星型模式(Star Schema)
- 雪花模式(Snowflake Schema)
- 缓慢变化维度(Slowly Changing Dimensions, SCD)
- 实际应用案例:电商数据仓库
- 需求分析
- 数据模型设计
- ETL过程
- 数据分析查询
- 数据仓库的优势与挑战
- 优势
- 挑战
- 未来展望:数据湖与云数据仓库
- 数据湖
- 云数据仓库
- 总结
什么是数据仓库?
数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。这个定义来自被誉为"数据仓库之父"的Bill Inmon。但这个定义可能对初学者来说有点抽象,让我们通过一个类比来更好地理解它:

想象你是一家大型超市的经理。每天,你的超市都会产生大量的交易数据:销售记录、库存变化、客户信息等。这些数据分散在不同的系统中:收银系统、库存管理系统、会员管理系统等。如果你想分析过去一年的销售趋势,或者预测未来的库存需求,你需要从这些分散的系统中提取数据,然后进行整合和分析。这个过程可能既耗时又容易出错。

这时,数据仓库就像是一个巨大的"数据超市",它将所有这些分散的、原始的数据收集起来,经过清洗、转换和整合,形成一个统一的、易于分析的数据集合。在这个"数据超市"中,数据被组织成便于分析的形式,你可以轻松地进行各种复杂的查询和分析,而不会影响日常业务系统的运行。
数据仓库vs传统数据库:关键区别
虽然数据仓库和传统的关系型数据库(如MySQL、Oracle)都用于存储数据,但它们在设计目的、数据组织方式和使用场景上有着本质的区别。让我们通过一个表格来直观地比较它们的不同:
| 特征 | 传统数据库 | 数据仓库 |
|---|---|---|
| 主要目的 | 支持日常事务处理 | 支持决策分析 |
| 数据更新 | 频繁的实时更新 | 定期批量更新 |
| 数据模型 | 高度规范化 | 部分反规范化 |
| 查询类型 | 简单、标准化的查询 | 复杂的分析性查询 |
| 数据范围 | 当前业务数据 | 历史数据(通常跨越多年) |
| 数据粒度 | 细粒度(单条交易) | 多粒度(汇总和细节) |
| 数据冗余 | 最小化 | 有计划的冗余 |
| 优化重点 | 事务处理速度 | 查询性能 |
 | ||
| 让我们通过一个具体的例子来说明这些区别: |
假设你正在管理一个在线书店。在传统的关系型数据库中,你可能有这样的表结构:
-- 用户表
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100),
registration_date DATE
);
-- 书籍表
CREATE TABLE books (
book_id INT PRIMARY KEY,
title VARCHAR(200),
author VARCHAR(100),
price DECIMAL(10, 2),
stock INT
);
-- 订单表
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT,
order_date DATE,
total_amount DECIMAL(10, 2),
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
-- 订单详情表
CREATE TABLE order_details (
order_id INT,
book_id INT,
quantity INT,
price DECIMAL(10, 2),
PRIMARY KEY (order_id, book_id),
FOREIGN KEY (order_id) REFERENCES orders(order_id),
FOREIGN KEY (book_id) REFERENCES books(book_id)
);
这种结构非常适合处理日常的交易,如创建新订单、更新库存等。但是,如果你想分析过去一年的销售趋势,或者找出最受欢迎的作者,你可能需要编写复杂的SQL查询,并且可能会影响系统的性能。
相比之下,在数据仓库中,数据可能会被组织成这样的形式:
-- 销售事实表
CREATE TABLE sales_fact (
date_key INT,
book_key INT,
customer_key INT,
store_key INT,
quantity_sold INT,
sales_amount DECIMAL(10, 2)
);
-- 时间维度表
CREATE TABLE date_dim (
date_key INT PRIMARY KEY,
date DATE,
day_of_week VARCHAR(10),
month VARCHAR(10),
quarter INT,
year INT
);
-- 书籍维度表
CREATE TABLE book_dim (
book_key INT PRIMARY KEY,
book_id INT,
title VARCHAR(200),
author VARCHAR(100),
genre VARCHAR(50),
publisher VARCHAR(100)
);
-- 客户维度表
CREATE TABLE customer_dim (
customer_key INT PRIMARY KEY,
customer_id INT,
name VARCHAR(100),
email VARCHAR(100),
city VARCHAR(50),
state VARCHAR(50),
country VARCHAR(50)
);
这种结构被称为"星型模式"或"雪花模式",它是数据仓库中常用的数据模型。在这种结构中:
- 中心的"事实表"(sales_fact)包含了业务过程的度量值(如销售数量、销售金额)。
- 周围的"维度表"(date_dim, book_dim, customer_dim)包含了描述业务实体的属性。
这种结构使得复杂的分析查询变得简单和高效。例如,要找出2023年每个月最畅销的前10本书,你可以这样查询:
SELECT
d.month,
b.title,
b.author,
SUM(s.quantity_sold) as total_sold
FROM
sales_fact s
JOIN date_dim d ON s.date_key = d.date_key
JOIN book_dim b ON s.book_key = b.book_key
WHERE
d.year = 2023
GROUP BY
d.month, b.title, b.author
ORDER BY
d.month, total_sold DESC
LIMIT
10
这个查询在数据仓库中可以快速执行,即使是在包含数百万或数十亿条记录的大型数据集上。而在传统的关系型数据库中,同样的分析可能需要复杂的多表连接和子查询,执行起来可能需要很长时间。
数据仓库的核心特征

理解了数据仓库与传统数据库的区别后,让我们深入探讨数据仓库的核心特征。Bill Inmon在他的定义中提到了四个关键特征:面向主题的、集成的、相对稳定的、反映历史变化的。这些特征是什么意思呢?
- 面向主题的(Subject-Oriented)
数据仓库的数据是围绕企业的主要主题(如客户、产品、销售)组织的,而不是围绕具体的应用程序。这使得分析人员可以从多个角度来分析业务。
例如,在我们的在线书店案例中,我们可能有以下主题:
- 客户分析
- 产品(书籍)分析
- 销售分析
- 库存分析
每个主题都会包含相关的所有数据,无论这些数据最初来自哪个系统。
- 集成的(Integrated)
数据仓库整合了来自多个源系统的数据,解决了数据不一致性的问题。这包括命名约定的统一、度量单位的统一、编码结构的统一等。
例如,在不同的源系统中,性别可能被编码为:
- 系统A: ‘M’/‘F’
- 系统B: ‘1’/‘0’
- 系统C: ‘Male’/‘Female’
在数据仓库中,这些会被统一为一种表示方式,比如 ‘M’/‘F’。
- 相对稳定的(Nonvolatile)
一旦数据被加载到数据仓库中,就不会频繁更改。数据仓库通常采用批量更新的方式,而不是实时更新。这保证了数据的一致性,使得复杂的分析查询可以在一个稳定的数据集上执行。
- 反映历史变化的(Time-Variant)
数据仓库保存历史数据,允许进行趋势分析和时间比较。每条数据通常都带有时间戳,使得我们可以看到数据随时间的变化。
例如,在我们的书店数据仓库中,我们可能会保存每本书每天的销售数据,这样我们就可以分析:
- 某本书在不同时期的销售趋势
- 不同年份的畅销书对比
- 季节性销售模式等
这些核心特征使得数据仓库成为支持决策的理想工具。让我们通过一个简单的SQL示例来说明这些特征:
-- 创建一个销售事实表,体现了面向主题、集成和时间变化的特征
CREATE TABLE sales_fact (
date_key INT,
product_key INT,
customer_key INT,
store_key INT,
sales_amount DECIMAL(10, 2),
quantity INT,
cost_amount DECIMAL(10, 2),
profit_amount DECIMAL(10, 2)
);
-- 查询示例:分析2023年各季度的销售趋势
SELECT
d.quarter,
SUM(s.sales_amount) as total_sales,
SUM(s.quantity) as total_quantity,
SUM(s.profit_amount) as total_profit
FROM
sales_fact s
JOIN date_dim d ON s.date_key = d.date_key
WHERE
d.year = 2023
GROUP BY
d.quarter
ORDER BY
d.quarter;
这个查询展示了数据仓库如何支持复杂的分析需求。它可以快速地给出2023年每个季度的销售总额、销售数量和利润,这在传统的操作型数据库中可能需要复杂的多表连接和大量的实时计算。
数据仓库架构深度解析
理解了数据仓库的核心特征后,让我们深入探讨数据仓库的架构。一个典型的数据仓库架构通常包括以下几个主要组件:
- 数据源(Data Sources)
- 数据暂存区(Staging Area)
- ETL层(Extract, Transform, Load)
- 核心数据仓库(Core Data Warehouse)
- 数据集市(Data Marts)
- 元数据仓库(Metadata Repository)
- 前端工具(Front-end Tools)
让我们详细探讨每个组件:
1. 数据源(Data Sources)

数据源是所有进入数据仓库的数据的来源。这可能包括:
- 操作型数据库(如MySQL, Oracle)
- 外部数据源(如合作伙伴提供的数据)
- 平面文件(如CSV, Excel文件)
- 物联网设备数据
- 社交媒体数据等
例如,在我们的在线书店案例中,数据源可能包括:
- 交易系统数据库(订单信息)
- 客户关系管理(CRM)系统
- 库存管理系统
- 网站点击流数据
- 社交媒体评论数据
2. 数据暂存区(Staging Area)

数据暂存区是一个中间存储区域,用于临时存储从源系统提取的原始数据。它的主要目的是:
- 减少对源系统的影响
- 提供一个进行数据清洗和转换的工作空间
- 保存原始数据的快照,以便于审计和重新处理
在实践中,数据暂存区通常是一个简单的数据库或文件系统。例如:
-- 创建一个订单数据的暂存表
CREATE TABLE stg_orders (
order_id VARCHAR(20),
order_date VARCHAR(10),
customer_id VARCHAR(20),
total_amount VARCHAR(10),
raw_data TEXT -- 存储原始数据,用于审计
);
3. ETL层(Extract, Transform, Load)
ETL是数据仓库中最关键的过程之一。它负责:
- 从源系统提取数据(Extract)
- 清洗、转换和集成数据(Transform)
- 将处理后的数据加载到数据仓库(Load)
ETL过程通常使用专门的ETL工具(如Informatica, Talend)或自定义脚本来实现。这里是一个简单的Python ETL脚本示例:
import pandas as pd
from sqlalchemy import create_engine
# 连接到源数据库和目标数据仓库
source_engine = create_engine('mysql://user:password@localhost/source_db')
dw_engine = create_engine('postgresql://user:password@localhost/data_warehouse')
# 提取数据
df = pd.read_sql('SELECT * FROM orders', source_engine)
# 转换数据
df['order_date'] = pd.to_datetime(df['order_date'])
df['total_amount'] = df['total_amount'].astype(float)
# 加载数据到数据仓库
df.to_sql('fact_orders', dw_engine, if_exists='append', index=False)
4. 核心数据仓库(Core Data Warehouse)
核心数据仓库是存储所有集成、清洗后数据的中央存储库。它通常采用星型模式或雪花模式进行设计。例如:
-- 创建订单事实表
CREATE TABLE fact_orders (
order_key SERIAL PRIMARY KEY,
date_key INT,
customer_key INT,
product_key INT,
quantity INT,
sales_amount DECIMAL(10, 2)
);
-- 创建日期维度表
CREATE TABLE dim_date (
date_key INT PRIMARY KEY,
date DATE,
day_of_week VARCHAR(10),
month VARCHAR(10),
quarter INT,
year INT
);
-- 创建客户维度表
CREATE TABLE dim_customer (
customer_key INT PRIMARY KEY,
customer_id VARCHAR(20),
customer_name VARCHAR(100),
customer_email VARCHAR(100),
customer_address TEXT
);
5. 数据集市(Data Marts)
数据集市是面向特定业务线或部门的小型数据仓库。它们通常从核心数据仓库中提取数据,并针对特定的分析需求进行优化。例如:
-- 创建销售部门的数据集市
CREATE TABLE sales_mart.monthly_sales AS
SELECT
d.year,
d.month,
c.customer_segment,
SUM(f.sales_amount) as total_sales
FROM
fact_orders f
JOIN dim_date d ON f.date_key = d.date_key
JOIN dim_customer c ON f.customer_key = c.customer_key
GROUP BY
d.year, d.month, c.customer_segment;
6. 元数据仓库(Metadata Repository)
元数据仓库存储有关数据仓库的数据,包括:
- 数据的业务定义
- 数据的技术特征(如数据类型、长度)
- 数据血缘(数据的来源和转换过程)
- ETL作业的调度信息
元数据对于数据仓库的管理和维护至关重要。例如:
-- 创建一个简单的元数据表
CREATE TABLE metadata.table_info (
table_name VARCHAR(100),
column_name VARCHAR(100),
data_type VARCHAR(50),
business_definition TEXT,
source_system VARCHAR(100),
last_etl_run TIMESTAMP
);
7. 前端工具(Front-end Tools)

前端工具是用户与数据仓库交互的接口。这可能包括:
- BI(商业智能)工具(如Tableau, Power BI)
- OLAP工具
- 自定义报表工具
- 数据挖掘工具
这些工具允许用户进行数据可视化、创建报表、执行复杂的分析查询等。
数据仓库的ETL过程
ETL(Extract, Transform, Load)是数据仓库中最关键和复杂的过程之一。让我们深入探讨ETL的每个阶段:
1. 提取(Extract)

提取阶段涉及从各种源系统中获取数据。这可能包括:
- 全量提取:提取整个数据集
- 增量提取:只提取自上次提取以来发生变化的数据
示例Python代码(使用pandas):
import pandas as pd
from sqlalchemy import create_engine
# 连接到源数据库
source_engine = create_engine('mysql://user:password@localhost/source_db')
# 增量提取示例
last_extract_date = '2023-01-01' # 假设这是上次提取的日期
df = pd.read_sql(f"SELECT * FROM orders WHERE order_date > '{last_extract_date}'", source_engine)
2. 转换(Transform)

转换阶段包括数据清洗、规范化、去重、计算衍生字段等。常见的转换操作包括:
- 数据类型转换
- 日期格式统一
- 缺失值处理
- 代码映射(如将性别代码’1’/‘0’转换为’M’/‘F’)
- 计算衍生字段
示例Python代码:
# 日期格式统一
df['order_date'] = pd.to_datetime(df['order_date'])
# 代码映射
gender_map = {'1': 'M', '0': 'F'}
df['gender'] = df['gender'].map(gender_map)
# 计算衍生字段
df['total_amount'] = df['quantity'] * df['unit_price']
# 缺失值处理
df['customer_name'].fillna('Unknown', inplace=True)
3. 加载(Load)
加载阶段将转换后的数据插入到目标数据仓库中。这可能是批量加载或实时流式加载。
示例Python代码:
# 连接到目标数据仓库
dw_engine = create_engine('postgresql://user:password@localhost/data_warehouse')
# 批量加载数据
df.to_sql('fact_orders', dw_engine, if_exists='append', index=False)
ETL最佳实践
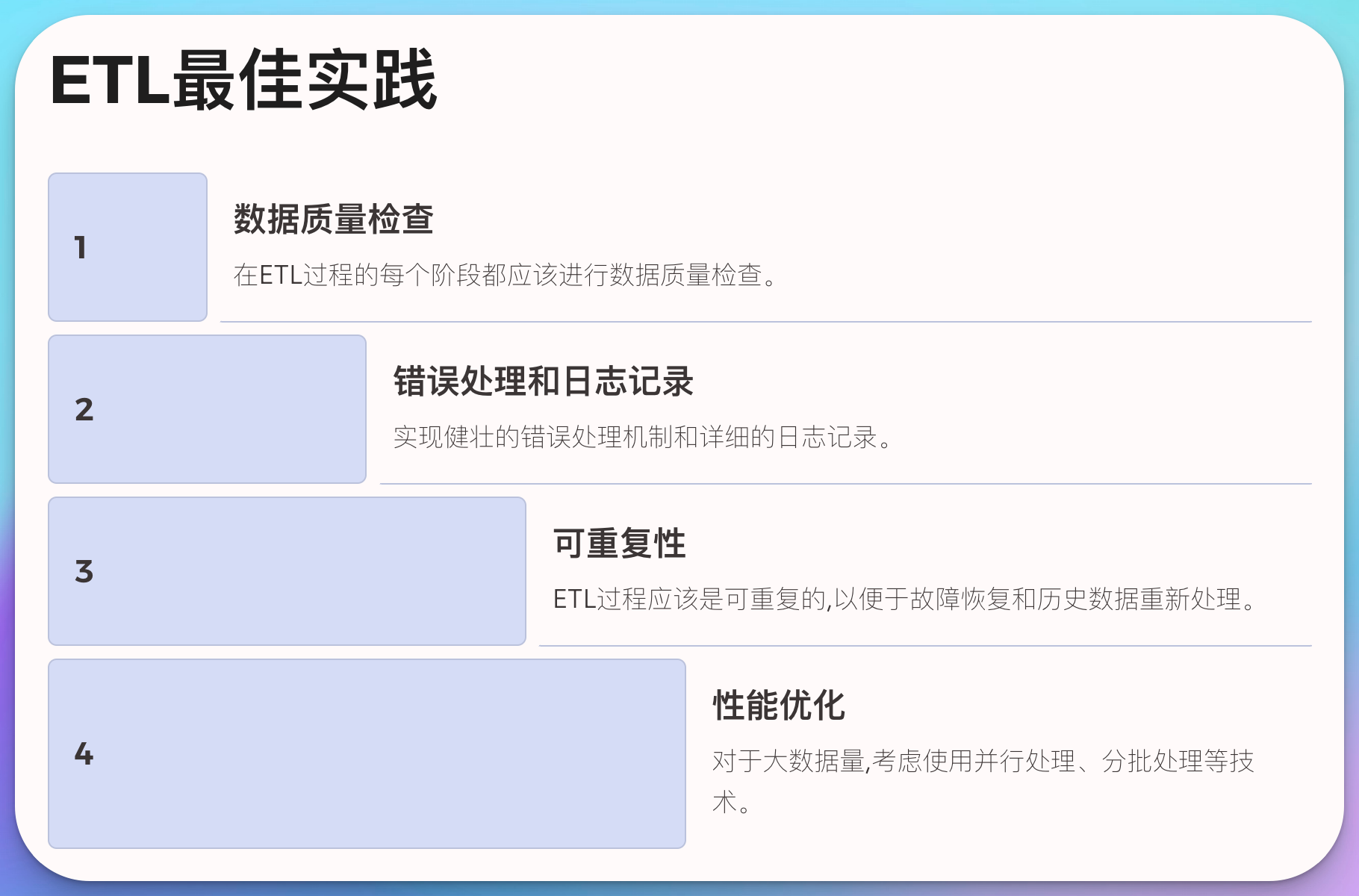
- 数据质量检查: 在ETL过程的每个阶段都应该进行数据质量检查。
# 数据质量检查示例
assert df['order_id'].is_unique, "Duplicate order IDs found"
assert df['total_amount'].min() >= 0, "Negative total amount found"
- 错误处理和日志记录: 实现健壮的错误处理机制和详细的日志记录。
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
try:
# ETL操作
logger.info("ETL process started")
# ...
except Exception as e:
logger.error(f"ETL process failed: {str(e)}")
else:
logger.info("ETL process completed successfully")
-
可重复性: ETL过程应该是可重复的,以便于故障恢复和历史数据重新处理。
-
性能优化: 对于大数据量,考虑使用并行处理、分批处理等技术。
# 使用multiprocessing进行并行处理
from multiprocessing import Pool
def process_chunk(chunk):
# 处理数据块的逻辑
return processed_chunk
with Pool(4) as p: # 使用4个进程
results = p.map(process_chunk, np.array_split(df, 4))
processed_df = pd.concat(results)

数据建模技术:维度建模详解
维度建模是数据仓库中最常用的数据建模技术之一,由Ralph Kimball提出。它的核心思想是将数据分为事实(Facts)和维度(Dimensions)。
事实表(Fact Table)
事实表存储业务过程的度量值。它通常包含:
- 外键(指向各个维度表)
- 度量值(如销售金额、数量等)
示例SQL:
CREATE TABLE fact_sales (
date_key INT,
product_key INT,
store_key INT,
customer_key INT,
sales_amount DECIMAL(10, 2),
quantity INT,
FOREIGN KEY (date_key) REFERENCES dim_date(date_key),
FOREIGN KEY (product_key) REFERENCES dim_product(product_key),
FOREIGN KEY (store_key) REFERENCES dim_store(store_key),
FOREIGN KEY (customer_key) REFERENCES dim_customer(customer_key)
);
维度表(Dimension Table)

维度表存储描述业务实体的属性。常见的维度包括:
- 时间维度
- 产品维度
- 客户维度
- 地理维度
示例SQL:
CREATE TABLE dim_product (
product_key INT PRIMARY KEY,
product_id VARCHAR(20),
product_name VARCHAR(100),
category VARCHAR(50),
brand VARCHAR(50),
unit_price DECIMAL(10, 2)
);
星型模式(Star Schema)
星型模式是最简单的维度模型。它包含一个中心事实表,周围是多个维度表。
+-------------+
| dim_date |
+-------------+
^
|
+-------------+ +---------------+
| fact_sales |----->| dim_product |
+-------------+ +---------------+
|
v
+-------------+
| dim_store |
+-------------+
雪花模式(Snowflake Schema)

雪花模式是星型模式的变体,其中一些维度表被进一步规范化。
+-------------+
| dim_date |
+-------------+
^
|
+-------------+ +---------------+
| fact_sales |----->| dim_product |
+-------------+ +---------------+
| |
| v
| +---------------+
| | dim_category |
| +---------------+
v
+-------------+
| dim_store |
+-------------+
|
v
+-------------+
| dim_city |
+-------------+
缓慢变化维度(Slowly Changing Dimensions, SCD)
维度属性可能随时间变化。SCD技术用于处理这些变化。常见的SCD类型包括:
- Type 1: 直接覆盖旧值
- Type 2: 创建新记录
- Type 3: 添加新列
示例SQL(Type 2 SCD):
CREATE TABLE dim_customer (
customer_key INT PRIMARY KEY,
customer_id VARCHAR(20),
customer_name VARCHAR(100),
email VARCHAR(100),
effective_date DATE,
end_date DATE,
is_current BOOLEAN
);
-- 更新客户信息
UPDATE dim_customer
SET end_date = CURRENT_DATE, is_current = FALSE
WHERE customer_id = '12345' AND is_current = TRUE;
INSERT INTO dim_customer
(customer_key, customer_id, customer_name, email, effective_date, end_date, is_current)
VALUES
(NEXT_VAL('customer_key_seq'), '12345', 'John Doe', 'new_email@example.com', CURRENT_DATE, NULL, TRUE);
实际应用案例:电商数据仓库
让我们通过一个电商数据仓库的案例来综合应用我们所学的概念。
需求分析
假设我们的电商平台需要分析:
- 销售趋势(按时间、产品类别、地区等)
- 客户行为(购买频率、平均订单金额等)
- 库存管理(畅销商品、滞销商品等)
- 营销活动效果
数据模型设计
基于这些需求,我们可以设计以下数据模型:
-- 事实表
CREATE TABLE fact_sales (
sales_key SERIAL PRIMARY KEY,
date_key INT,
product_key INT,
customer_key INT,
store_key INT,
promotion_key INT,
quantity INT,
sales_amount DECIMAL(10, 2),
discount_amount DECIMAL(10, 2),
FOREIGN KEY (date_key) REFERENCES dim_date(date_key),
FOREIGN KEY (product_key) REFERENCES dim_product(product_key),
FOREIGN KEY (customer_key) REFERENCES dim_customer(customer_key),
FOREIGN KEY (store_key) REFERENCES dim_store(store_key),
FOREIGN KEY (promotion_key) REFERENCES dim_promotion(promotion_key)
);
-- 维度表
CREATE TABLE dim_date (
date_key INT PRIMARY KEY,
date DATE,
day_of_week VARCHAR(10),
month VARCHAR(10),
quarter INT,
year INT
);
CREATE TABLE dim_product (
product_key INT PRIMARY KEY,
product_id VARCHAR(20),
product_name VARCHAR(100),
category VARCHAR(50),
subcategory VARCHAR(50),
brand VARCHAR(50),
unit_price DECIMAL(10,unit_price DECIMAL(10, 2)
);
CREATE TABLE dim_customer (
customer_key INT PRIMARY KEY,
customer_id VARCHAR(20),
customer_name VARCHAR(100),
email VARCHAR(100),
address TEXT,
city VARCHAR(50),
state VARCHAR(50),
country VARCHAR(50),
segment VARCHAR(20)
);
CREATE TABLE dim_store (
store_key INT PRIMARY KEY,
store_id VARCHAR(20),
store_name VARCHAR(100),
store_type VARCHAR(50),
address TEXT,
city VARCHAR(50),
state VARCHAR(50),
country VARCHAR(50)
);
CREATE TABLE dim_promotion (
promotion_key INT PRIMARY KEY,
promotion_id VARCHAR(20),
promotion_name VARCHAR(100),
promotion_type VARCHAR(50),
start_date DATE,
end_date DATE,
discount_percent DECIMAL(5, 2)
);
ETL过程
以下是一个简化的ETL过程示例:
import pandas as pd
from sqlalchemy import create_engine
# 连接到源数据库和目标数据仓库
source_engine = create_engine('mysql://user:password@localhost/source_db')
dw_engine = create_engine('postgresql://user:password@localhost/data_warehouse')
# 提取数据
orders_df = pd.read_sql('SELECT * FROM orders', source_engine)
products_df = pd.read_sql('SELECT * FROM products', source_engine)
customers_df = pd.read_sql('SELECT * FROM customers', source_engine)
# 转换数据
# 1. 日期转换
orders_df['order_date'] = pd.to_datetime(orders_df['order_date'])
# 2. 创建日期维度
date_df = orders_df['order_date'].drop_duplicates().reset_index(drop=True)
date_df = pd.DataFrame({
'date_key': range(1, len(date_df) + 1),
'date': date_df,
'day_of_week': date_df.dt.day_name(),
'month': date_df.dt.month_name(),
'quarter': date_df.dt.quarter,
'year': date_df.dt.year
})
# 3. 创建销售事实表
sales_fact = orders_df.merge(date_df, left_on='order_date', right_on='date')
sales_fact = sales_fact.merge(products_df, on='product_id')
sales_fact = sales_fact.merge(customers_df, on='customer_id')
sales_fact['sales_amount'] = sales_fact['quantity'] * sales_fact['unit_price']
sales_fact['discount_amount'] = sales_fact['sales_amount'] * (sales_fact['discount'] / 100)
# 加载数据
date_df.to_sql('dim_date', dw_engine, if_exists='append', index=False)
products_df.to_sql('dim_product', dw_engine, if_exists='append', index=False)
customers_df.to_sql('dim_customer', dw_engine, if_exists='append', index=False)
sales_fact.to_sql('fact_sales', dw_engine, if_exists='append', index=False)
数据分析查询
有了这个数据模型,我们可以进行各种复杂的分析查询。以下是一些示例:
- 按月份和产品类别的销售趋势:
SELECT
d.year,
d.month,
p.category,
SUM(f.sales_amount) as total_sales
FROM
fact_sales f
JOIN dim_date d ON f.date_key = d.date_key
JOIN dim_product p ON f.product_key = p.product_key
GROUP BY
d.year, d.month, p.category
ORDER BY
d.year, d.month, total_sales DESC;
- 客户细分分析:
SELECT
c.segment,
COUNT(DISTINCT f.customer_key) as customer_count,
AVG(f.sales_amount) as avg_order_value,
SUM(f.sales_amount) / COUNT(DISTINCT f.customer_key) as revenue_per_customer
FROM
fact_sales f
JOIN dim_customer c ON f.customer_key = c.customer_key
GROUP BY
c.segment;
- 促销活动效果分析:
SELECT
p.promotion_name,
SUM(f.sales_amount) as total_sales,
SUM(f.discount_amount) as total_discount,
COUNT(DISTINCT f.customer_key) as customer_count
FROM
fact_sales f
JOIN dim_promotion p ON f.promotion_key = p.promotion_key
GROUP BY
p.promotion_name
ORDER BY
total_sales DESC;
数据仓库的优势与挑战

优势
-
集成的数据视图: 数据仓库提供了一个单一的、综合的数据视图,使得跨部门的数据分析变得可能。
-
历史数据分析: 通过存储历史数据,数据仓库支持趋势分析和时间比较。
-
提高决策质量: 通过提供准确、一致的数据,数据仓库可以显著提高决策的质量和速度。
-
减轻操作系统负担: 通过将分析查询从操作系统中分离出来,数据仓库减轻了事务处理系统的负担。
-
数据质量改善: ETL过程中的数据清洗和转换可以显著提高数据质量。
挑战
-
高初始投资: 建立数据仓库需要大量的时间、资金和专业知识。
-
复杂的ETL过程: 设计和维护ETL过程可能非常复杂,特别是当处理多个异构数据源时。
-
数据新鲜度: 由于批量加载的性质,数据仓库中的数据可能不是实时的。
-
需要持续维护: 随着业务需求的变化,数据仓库需要不断更新和调整。
-
可能的性能问题: 随着数据量的增长,查询性能可能会下降,需要持续优化。
未来展望:数据湖与云数据仓库
随着大数据技术的发展,数据仓库领域也在不断演进。两个重要的趋势是数据湖和云数据仓库。
数据湖
数据湖是一个存储海量原始数据的存储库,可以存储结构化、半结构化和非结构化数据。与数据仓库相比,数据湖具有以下特点:
- 灵活性: 可以存储任何类型的数据,不需要预先定义模式。
- 可扩展性: 可以轻松处理PB级的数据。
- 成本效益: 通常使用低成本的存储解决方案(如Hadoop HDFS)。
- 支持高级分析: 适合机器学习、数据挖掘等高级分析任务。
然而,数据湖也面临着数据治理、元数据管理等挑战。
云数据仓库
云数据仓库将传统数据仓库的概念与云计算的优势相结合。主要优点包括:
- 可扩展性: 可以根据需求快速扩展或缩减资源。
- 成本效益: 采用按需付费模式,无需大额前期投资。
- 易于维护: 供应商负责硬件和软件的维护。
- 高可用性: 通常提供内置的备份和故障恢复机制。
主流的云数据仓库解决方案包括Amazon Redshift, Google BigQuery, Snowflake等。
示例:使用Amazon Redshift创建表
CREATE TABLE sales (
sale_id INT,
date DATE,
customer_id INT,
product_id INT,
quantity INT,
amount DECIMAL(10, 2)
)
DISTKEY(customer_id)
SORTKEY(date);
在这个例子中,我们使用DISTKEY和SORTKEY来优化数据分布和查询性能,这是Redshift等云数据仓库的特有功能。
总结
数据仓库作为一种专门设计用于支持企业决策的数据管理系统,与传统的操作型数据库有着本质的区别。它通过集成、清洗和组织来自多个源系统的数据,为企业提供了一个全面、一致和历史的数据视图。
关键点回顾:
- 数据仓库是面向主题的、集成的、相对稳定的、反映历史变化的数据集合。
- 与传统数据库相比,数据仓库更适合复杂的分析查询和报表生成。
- 数据仓库架构通常包括数据源、暂存区、ETL过程、核心数据仓库、数据集市和前端工具。
- ETL(提取、转换、加载)是数据仓库中最关键的过程之一。
- 维度建模(如星型模式和雪花模式)是数据仓库中常用的数据建模技术。
- 数据仓库面临的挑战包括高初始投资、复杂的ETL过程和持续维护需求。
- 未来趋势包括数据湖和云数据仓库,它们提供了更大的灵活性和可扩展性。
在大数据时代,数据仓库继续发挥着重要作用,帮助企业从海量数据中提取有价值的洞察。随着技术的不断发展,我们可以期待看到数据仓库与新兴技术(如人工智能和机器学习)的进一步融合,为企业决策提供更强大的支持。