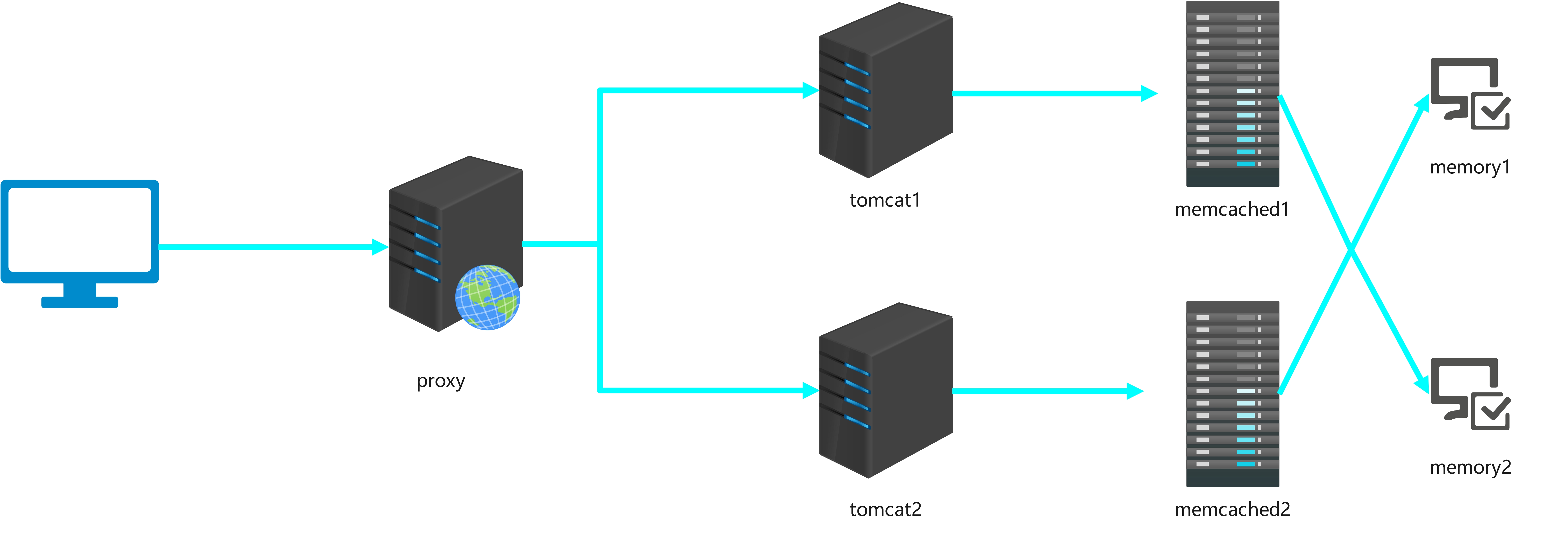
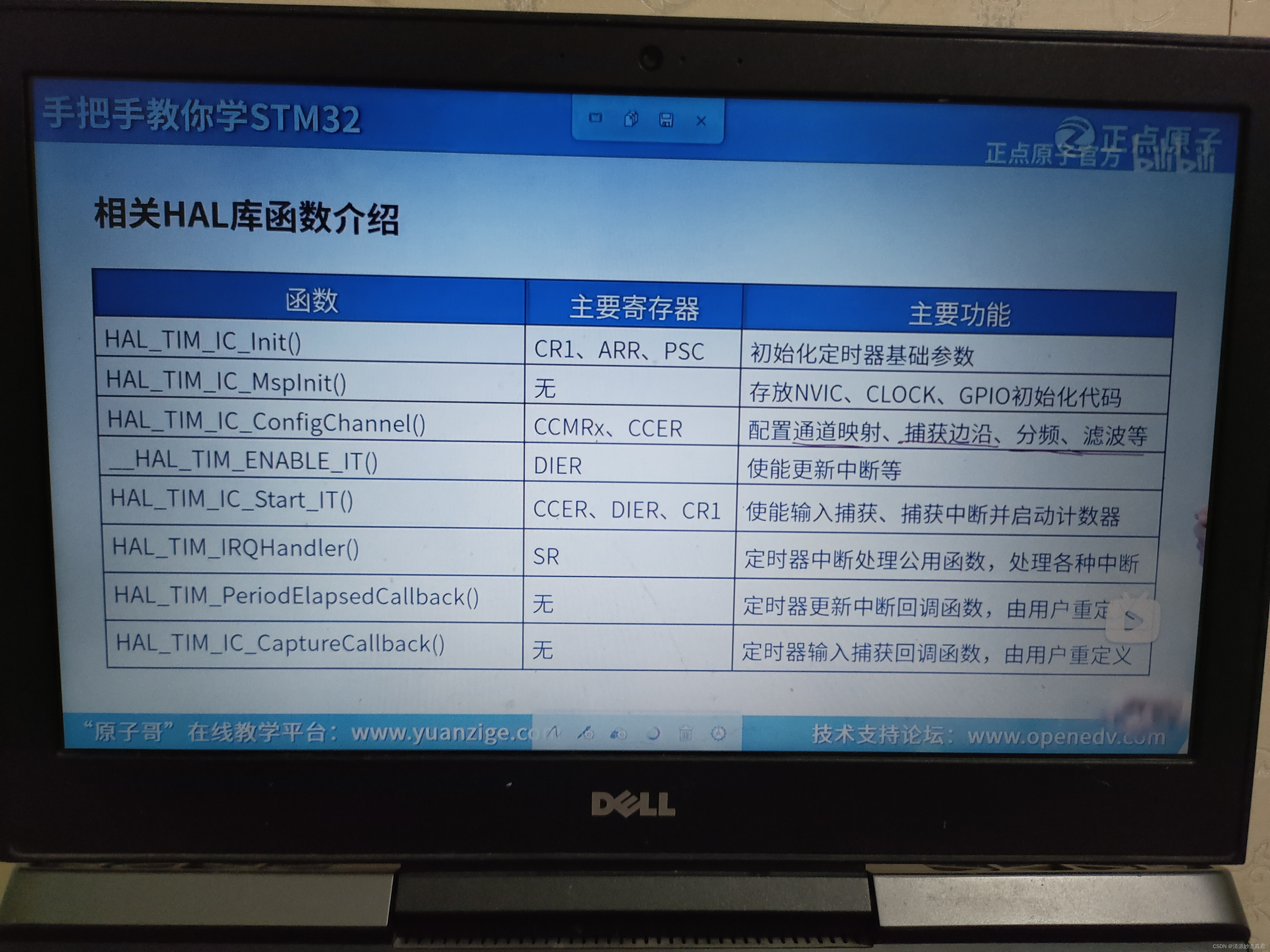
1、概念
随机森林(Random Forest)是一种集成学习方法,它通过构建多个决策树来进行分类或回归预测。随机森林的核心原理是“集思广益”,即通过组合多个弱学习器(决策树)的预测结果来提高整体模型的准确性和健壮性。
2、集成学习(Ensemble Learning):
集成学习是一种机器学习方法,它结合多个学习器的预测结果来提高整体模型的性能。随机森林是集成学习的一种实现方式。
3、决策树(Decision Tree):
决策树是一种监督学习算法,它通过学习简单的决策规则来预测目标值。每个决策树都是一个二叉树,每个节点代表一个特征的测试,每个分支代表测试的结果,每个叶节点代表一个预测结果。
4、Bagging(自助采样聚合):
随机森林使用Bagging方法来减少模型的方差。Bagging是一种通过从原始数据集中随机抽取样本(有放回抽样)来构建多个训练集的方法。每个决策树都是在这些不同的训练集上训练得到的。
5、投票机制:
对于分类问题,随机森林通过多数投票的方式来确定最终的预测结果。每个决策树都会给出一个预测,随机森林会统计每个类别的得票数,得票数最多的类别被选为最终预测结果。
6、特征重要性:
随机森林可以评估每个特征对模型预测的贡献度,即特征重要性。这通常是通过观察在构建树时,某个特征被用于分割的次数来确定的。
7、处理能力:
随机森林能够处理高维数据,并且对于缺失数据具有一定的鲁棒性。它也可以处理分类和回归问题。
8、优点:
- 通常具有较高的准确率。
- 对于高维数据表现良好。
- 能够提供特征重要性的估计。
- 对于数据集中的异常值和噪声具有一定的鲁棒性。
9、缺点:
- 训练时间可能较长,尤其是在数据集很大或特征很多的情况下。
- 模型可能会占用较多的内存。
- 模型的解释性不如单个决策树。
10、数据预处理,找到数据的特征与标签

data = pd.read_csv("spambase.csv") # 读取数据集
x = data.iloc[:, :-1] # 选取数据集中的特征列(除了最后一列)
y = data.iloc[:, -1] # 选取数据集中的最后一列作为标签11、划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=100)12、创建随机森林分类器实例
rf = RandomForestClassifier(n_estimators=100, max_features=0.8, random_state=0) # 创建随机森林分类器实例
rf.fit(x_train, y_train) # 使用训练集数据训练模型13、打印分类报告
predict_train = rf.predict(x_train) # 使用训练集数据进行预测
print(metrics.classification_report(y_train, predict_train)) # 打印训练集的分类报告
predict_test = rf.predict(x_test) # 使用测试集数据进行预测
print(metrics.classification_report(y_test, predict_test)) # 打印测试集的分类报告14、数据可视化
import matplotlib.pyplot as plt # 导入matplotlib.pyplot,用于数据可视化
from pylab import mpl # 导入pylab的mpl模块
# 获取每一项特征所占的权重(重要性)
importances = rf.feature_importances_
# 转换成数组,重新命名
im = pd.DataFrame(importances, columns=["importances"])
# 从原表格中获取所有列名称,将其转换成列表格式,除去最后一列
clos = data.columns
clos_1 = clos.values
clos_2 = clos_1.tolist()
clos = clos_2[:-1] # 切片操作,获取除了最后一列的所有列名
# 将名称添加到im
im["clos"] = clos
# 对importances进行排序,获取前10个
im = im.sort_values(by=["importances"], ascending=False)[:10]
index = range(len(im)) # 创建一个索引列表
plt.yticks(index, im.clos) # 设置y轴的刻度标签为特征名称
plt.barh(index, im["importances"]) # 绘制水平条形图
plt.show() # 显示图形15、结果


16、完整代码
import pandas as pd # 导入pandas库,用于数据处理
data = pd.read_csv("spambase.csv") # 读取数据集
x = data.iloc[:, :-1] # 选取数据集中的特征列(除了最后一列)
y = data.iloc[:, -1] # 选取数据集中的最后一列作为标签
from sklearn.model_selection import train_test_split # 导入train_test_split函数
# 将数据集分割为训练集和测试集,测试集占20%
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=100)
from sklearn.ensemble import RandomForestClassifier # 导入RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100, max_features=0.8, random_state=0) # 创建随机森林分类器实例
rf.fit(x_train, y_train) # 使用训练集数据训练模型
from sklearn import metrics # 导入metrics库,用于模型评估
predict_train = rf.predict(x_train) # 使用训练集数据进行预测
print(metrics.classification_report(y_train, predict_train)) # 打印训练集的分类报告
predict_test = rf.predict(x_test) # 使用测试集数据进行预测
print(metrics.classification_report(y_test, predict_test)) # 打印测试集的分类报告
import matplotlib.pyplot as plt # 导入matplotlib.pyplot,用于数据可视化
from pylab import mpl # 导入pylab的mpl模块
# 获取每一项特征所占的权重(重要性)
importances = rf.feature_importances_
# 转换成数组,重新命名
im = pd.DataFrame(importances, columns=["importances"])
# 从原表格中获取所有列名称,将其转换成列表格式,除去最后一列
clos = data.columns
clos_1 = clos.values
clos_2 = clos_1.tolist()
clos = clos_2[:-1] # 切片操作,获取除了最后一列的所有列名
# 将名称添加到im
im["clos"] = clos
# 对importances进行排序,获取前10个
im = im.sort_values(by=["importances"], ascending=False)[:10]
index = range(len(im)) # 创建一个索引列表
plt.yticks(index, im.clos) # 设置y轴的刻度标签为特征名称
plt.barh(index, im["importances"]) # 绘制水平条形图
plt.show() # 显示图形