决策树是一种非常直观且易于理解的机器学习方法,被广泛应用于分类和回归任务中。在这篇文章中,我们将探讨两种经典的决策树算法:ID3与C4.5,并分析它们之间的区别。
一 算法概述
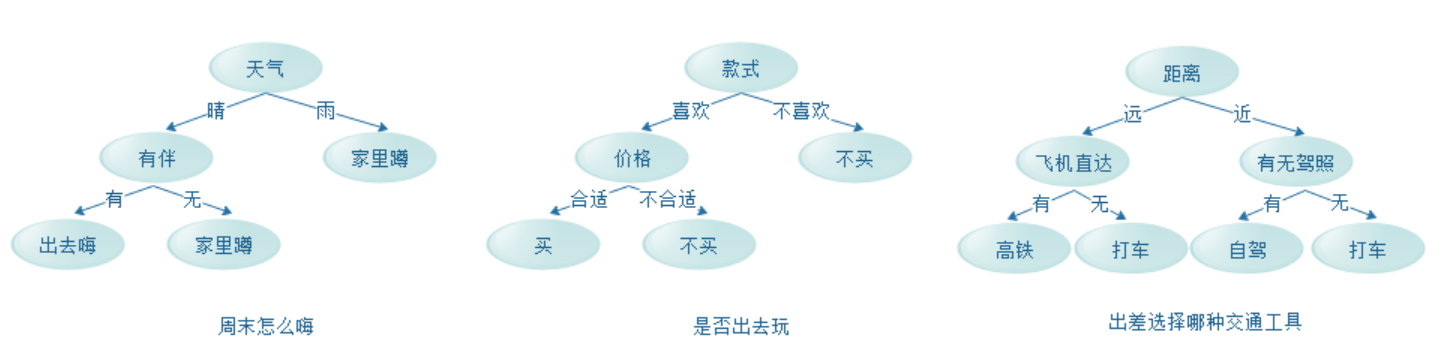
我们每天都做着各种形形色色的决策——周末怎么嗨、是否买下衣服、出差选哪种交通工具等等,这些决策的过程我们用图形的形式表现出来就是一种类似树形的结构,将这种决策思想应用到机器学习算法领域,那就是我们本文要说的决策树算法。
决策树算法属于有监督学习算法的一员,在决策前需要先根据先验数据进行学习,构建并训练出一个决策树模型。决策树模型中每一个非叶子结点代表着一个特征属性,其下每一个分支都代表对该特征属性值域的不同取值划分,每一个叶子结点代表一个输出分类。应用模型进行决策时,从第一个非叶子结点(根节点)开始,根据特征属性和值选择分支直到最后的叶子结点,最后的叶子结点所代表的分类就是最终的决策结果。
决策树算法的本质是根据训练数据进行学习,构建一颗最优的决策树。之所以说最优,是因为对于同一个数据集,在不同的策略下可能构造出不一样的决策树。假设我们有如下一个数据集,用于判断同事是否是程序员(纯属瞎编娱乐,请勿深究):
我们可能构建出下面这棵树:
也有可能构建出下面这棵树:
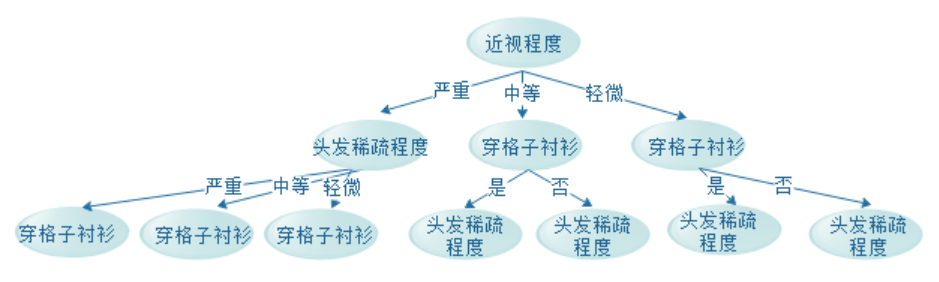
甚至还有其他结构的决策树。对于不同结构的决策树,当然对决策的效率,甚至是准确率都是有所影响,那么,怎么构建一颗最优的决策树呢?
我们知道,决策树是一种递归的逻辑结构,其每一个节点都可以作为一棵树,那么,我们只需要做到每个节点最优,就可以保证整个决策树最优。所以,对于构建一颗决策树,如何选择最优分裂特征属性,即从当前数据的特征中选择一个特征属性作为当前节点的划分标准,使分裂后各子树的样本子集的“纯度”越来越高。
在决策树算法中,根据选择最优分裂特征属性的策略不同,分为多种决策树算法,最经典的就是ID3、C4.5、CART,本文主要ID3和C4.5两种分类树,CART由于其特殊性,将在下一篇博客中介绍。
二 ID3决策树算法
ID3 (Iterative Dichotomiser 3) 是由Ross Quinlan在1986年提出的一种早期决策树算法。它的核心思想是通过计算信息增益来选择最优的特征进行分割,从而构建一棵决策树。
2.1 信息增益
信息增益是用来衡量一个特征对样本集纯度提升程度的指标。在ID3中,我们选择信息增益最大的特征作为节点进行分割。
之前说过,选择分裂特征属性时,分裂后的样本子集“纯度”越高越好,对于这个纯度,有一个专门的概念用于量化衡量——信息熵(entropy)。
信息熵是信息论中的概念,通常简称为熵,表示随机变量不确定性或者说混乱程度。设当前样本集合 X X X包含 n n n个分类, p i {p_i} pi表示第 k k k类所在的比例,则集合 X X X的熵定义为:
E n t ( X ) = − ∑ i = 1 n p i l o g 2 p i Ent(X) = - \sum\limits_{i = 1}^n {{p_i}} lo{g_2}{p_i} Ent(X)=−i=1∑npilog2pi
E n t ( X ) Ent(X) Ent(X)的值越趋近于0,表示 D D D的纯度越高,越趋近于1,表示 D D D的纯度越低。
在ID3决策树算法中,采用信息增益作为选择最优分裂特征属性的标准。假设 A A A是 X X X中的一个离散型特征属性,包含 L L L个可能取值,则根据属性 A A A对 X X X进行分裂可产生 L L L个分支,第 i i i个分支上获得的样本子集记为 X i {X_i} Xi,我们可以根据上式计算出每一个分支下获得的分裂子集 X i {X_i} Xi的熵,由于各子集 X i {X_i} Xi的样本数量不同,我们在熵的基础上添加一个权重 ∣ X i ∣ ∣ X ∣ {{|{X_i}|} \over {|X|}} ∣X∣∣Xi∣,也就是说,样本子集中样本数量越多,所占权重越大,以特征属性 A A A作为分裂节点后的熵为:
E n t A ( X ) = − ∑ i = 1 L ∣ X i ∣ ∣ X ∣ E n t ( X i ) En{t_A}(X) = - \sum\limits_{i = 1}^L {{{|{X_i}|} \over {|X|}}Ent({X_i})} EntA(X)=−i=1∑L∣X∣∣Xi∣Ent(Xi)
特征属性 A A A的信息增益定义为:
G a i n ( A ) = E n t ( X ) − E n t A ( X ) Gain(A) = Ent(X) - En{t_A}(X) Gain(A)=Ent(X)−EntA(X)
属性 A A A的信息增益 G a i n ( A ) 越大,表示使用属性 Gain(A)越大,表示使用属性 Gain(A)越大,表示使用属性A$作为当前数据集的分裂节点对数据集“纯度”的提升越大。ID3算法选择最优分裂特征属性的策略就是每次选择信息增益最大的一个特征属性最为当前数据集的分裂特征属性,然后对每一个分支节点的数据子集重复迭代这一策略,直到数据子集都属于同一分类或者所有特征属性都已用完。
我们已上面表格中用于判断同事是否是程序员的数据为例,通过实例感受一下ID3算法。
首先计算整个数据集的熵:
E n t ( X ) = − ( 7 10 × l o g 2 7 10 + 3 10 × l o g 2 3 10 ) = 0.88129 Ent(X) = - ({7 \over {10}} \times lo{g_2}{7 \over {10}} + {3 \over {10}} \times lo{g_2}{3 \over {10}}) = 0.88129 Ent(X)=−(107×log2107+103×log2103)=0.88129
采用属性 A A A(是否穿格子衬衫)的作为分裂特征属性后的熵为:
E n t A ( X ) = − { 5 10 × ( 4 5 × l o g 2 4 5 + 1 5 × l o g 2 1 5 ) + 5 10 × ( 3 5 × l o g 2 3 5 + 2 5 × l o g 2 2 5 ) } = 0.84645 En{t_A}(X) = - \{ {5 \over {10}} \times ({4 \over 5} \times lo{g_2}{4 \over 5} + {1 \over 5} \times lo{g_2}{1 \over 5}){\rm{ + }}{5 \over {10}} \times ({3 \over 5} \times lo{g_2}{3 \over 5} + {2 \over 5} \times lo{g_2}{2 \over 5})\} = 0.84645 EntA(X)=−{105×(54×log254+51×log251)+105×(53×log253+52×log252)}=0.84645
那么,属性 A A A的信息增益为:
G a i n ( A ) = 0.88129 − 0.84645 = 0.034840 Gain(A) = 0.88129 - 0.84645 = 0.034840 Gain(A)=0.88129−0.84645=0.034840
用同样的方法可以计算出属性 B B B(头发稀疏程度)和属性 C C C(近视程度)的信息增益分别为:
E n t B ( X ) = − { 3 10 × ( 2 3 × l o g 2 2 3 + 1 3 × l o g 2 1 3 ) + 4 10 × ( 4 4 × l o g 2 4 4 + 0 ) + 3 10 × ( 1 3 × l o g 2 1 3 + 2 3 × l o g 2 2 3 ) } = 0.612197 En{t_B}(X) = - \{ {3 \over {10}} \times ({2 \over 3} \times lo{g_2}{2 \over 3}{\rm{ + }}{1 \over 3} \times lo{g_2}{1 \over 3}) + {4 \over {10}} \times ({4 \over 4} \times lo{g_2}{4 \over 4}{\rm{ + }}0){\rm{ + }}{3 \over {10}} \times ({1 \over 3} \times lo{g_2}{1 \over 3}{\rm{ + }}{2 \over 3} \times lo{g_2}{2 \over 3})\} = 0.612197 EntB(X)=−{103×(32×log232+31×log231)+104×(44×log244+0)+103×(31×log231+32×log232)}=0.612197
G a i n ( B ) = 0.88129 − 0.61220 = 0.269093 Gain(B) = 0.88129 - 0.61220 = 0.269093 Gain(B)=0.88129−0.61220=0.269093
E n t C ( X ) = − { 3 10 × ( 3 3 × l o g 2 3 3 + 0 ) + 4 10 × ( 3 4 × l o g 2 3 4 + 1 4 × l o g 2 1 4 ) + 3 10 × ( 1 3 × l o g 2 1 3 + 2 3 × l o g 2 2 3 ) } = 0.6 En{t_C}(X) = - \{ {3 \over {10}} \times ({3 \over 3} \times lo{g_2}{3 \over 3}{\rm{ + }}0) + {4 \over {10}} \times ({3 \over 4} \times lo{g_2}{3 \over 4}{\rm{ + }}{1 \over 4} \times lo{g_2}{1 \over 4}){\rm{ + }}{3 \over {10}} \times ({1 \over 3} \times lo{g_2}{1 \over 3}{\rm{ + }}{2 \over 3} \times lo{g_2}{2 \over 3})\} = 0.6 EntC(X)=−{103×(33×log233+0)+104×(43×log243+41×log241)+103×(31×log231+32×log232)}=0.6
G a i n ( C ) = 0.88129 − 0.6 = 0.28129 Gain(C) = 0.88129 - 0.6 = 0.28129 Gain(C)=0.88129−0.6=0.28129
对比三个属性的信息增益,显然属性 C C C(近视程度)具有最大的信息增益,因此使用属性 C C C作为当前分裂特征属性。
使用属性 C C C作为当前分支节点后,每个分支产生新的数据子集,对每个子集重复上述步骤计算各特征属性的信息增益,选择最优分裂特征属性,直到数据子集都属于同一分类或者所有特征属性都已用完,整个决策树就算构建好了。
2.2 优缺点
优点:
- 构建速度快;
- 易于理解和实现;
- 对训练数据的要求不高,不需要数据标准化等预处理。
缺点:
-
在特征选择时偏好具有较多值的特征。在选择最优分裂特征属性时,偏好于多取值的特征属性。在选择最优分裂特征属性时,某特征属性的取值越多,分裂后的数据子集就越多,子集中类别相对而言就可能更少,数据“纯度”更高,信息增益更大,所以更有可能被选为当前分裂节点的特征属性。
-
只能处理离散型特征,不能处理连续型特征属性。
-
没有树剪枝过程,容易发生过拟合现象。
针对ID3决策树算法的不足,有大能进行优化改进,于是就有了C4.5决策树算法。
三 C4.5决策树算法
C4.5是Quinlan在1993年提出的ID3的改进版本。它解决了ID3的一些局限性,并引入了新的特性。
3.1 信息增益率
上面提过,ID3决策树算法在选择最优分裂特征属性时,偏好于多取值的特征属性,针对这一问题,C4.5决策树算法不再以信息增益作为选择选最优分裂特征属性的标准,而在选择在信息增益基础上更进一步计算获得的信息增益率作为选择最优分裂特征属性的标准。
在介绍信息增益率之前,还得说说“内部信息”的定义:
I n s t r _ i n f o A = − ∑ i = 1 L ∣ X i ∣ ∣ X ∣ l o g 2 ( ∣ X i ∣ ∣ X ∣ ) Instr\_inf{o_A} = - \sum\limits_{i = 1}^L {{{|{X_i}|} \over {|X|}}} lo{g_2}({{|{X_i}|} \over {|X|}}) Instr_infoA=−i=1∑L∣X∣∣Xi∣log2(∣X∣∣Xi∣)
内部信息 I n s t r _ i n f o A Instr\_inf{o_A} Instr_infoA用于度量属性 A A A进行分裂时分支的数量信息和尺寸信息,属性 A A A的取值数量越多,分支越多 I n s t r _ i n f o A Instr\_inf{o_A} Instr_infoA就越大, 1 I n s t r _ i n f o A {1 \over {Instr\_inf{o_A}}} Instr_infoA1就越小,因此可以将 1 I n s t r _ i n f o A {1 \over {Instr\_inf{o_A}}} Instr_infoA1作为一个惩罚因子与信息增益相结合,于是有了信息增益率:
G a i n _ r a t i o ( A ) = G a i n ( A ) I n s t r _ i n f o A Gain\_ratio(A) = {{Gain(A)} \over {Instr\_inf{o_A}}} Gain_ratio(A)=Instr_infoAGain(A)
用信息增益率替代信息增益作为最优分裂特征属性的选择标准,就可以很好的解决ID3决策树算法在选择最优分裂特征属性时,偏好于多取值的特征属性的问题。
3.2 连续型特征属性处理
C4.5能够处理连续型特征,通过将连续型特征转换为二元特征来进行分割。
对于连续型特征属性,C4.5算法采用的策略是采用二分法将特征属性离散化。假设数据集 X X X中属性 A A A有 n n n个不同取值,我们先将其按升序排序得到集合${ {a_1},{a_2}, \cdots ,{a_n}} ,将每两个相邻元素的中间点 ,将每两个相邻元素的中间点 ,将每两个相邻元素的中间点t = {{{a_i} + {a_{i + 1}}} \over 2} 看做潜在分裂点,于是有 看做潜在分裂点,于是有 看做潜在分裂点,于是有n-1 个潜在的分裂点,每一个潜在分裂点都可以将数据集划分为不大于 个潜在的分裂点,每一个潜在分裂点都可以将数据集划分为不大于 个潜在的分裂点,每一个潜在分裂点都可以将数据集划分为不大于t 和大于 和大于 和大于t$两类,对每一个潜在分裂点计算信息增益,然后选择信息增益最大的一个潜在分裂点作为当前的最优划分点。
在计算各特征属性的信息增益率时,就可以用最优划分点二分离散化之后的 A A A属性来计算信息增益率。
3.3 缺失值处理
C4.5提供了一种处理缺失值的方法,允许在特征值未知的情况下仍然能够做出决策。
3.4 优缺点
优点:
- 改进了ID3的特征选择偏差问题;
- 能够处理连续型特征;
- 提供了缺失值处理机制;
- 包含了剪枝功能以减少过拟合的风险。
缺点:
- 相对于ID3,算法实现更加复杂;
- 处理大规模数据集时效率较低。