🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.导入数据
5.数据可视化
小结
源代码
1.项目背景
随着全球经济的不断变化和科技的快速发展,各行各业都面临着前所未有的挑战和机遇。在这个背景下,裁员作为一种企业调整和优化人力资源配置的常见手段,其背后的数据和趋势显得尤为重要。通过对裁员数据集进行深入的分析和可视化展示,我们可以更好地理解这一现象的内在规律和影响因素,为企业决策和政策制定提供有力的数据支持。
首先,从全球宏观经济的角度来看,近年来全球经济形势复杂多变,受到多种因素的影响,如贸易保护主义的抬头、地缘政治的紧张局势、新冠疫情的全球大流行等。这些因素不仅对企业经营产生了巨大的冲击,也加剧了劳动力市场的波动和不确定性。因此,裁员作为企业在这种环境下的一种应对策略,其数据和趋势能够反映出全球经济形势的变化和企业经营的困境。
其次,从行业发展的角度来看,不同行业在面临市场变化和竞争压力时,其裁员情况也存在显著的差异。例如,一些传统行业由于产能过剩、技术创新不足等原因,可能面临较大的裁员压力;而一些新兴行业则由于市场需求旺盛、技术发展迅速等原因,呈现出较好的发展态势。通过对不同行业的裁员数据进行分析和比较,我们可以更深入地了解各行业的发展状况和趋势,为企业制定发展战略提供参考。
此外,从人力资源管理的角度来看,裁员不仅关系到企业的经济效益和竞争力,也关系到员工的切身利益和发展前景。因此,在裁员过程中,企业需要充分考虑员工的权益和利益,采取合理的补偿和安置措施,以减少裁员对员工的负面影响。通过对裁员数据集的分析和可视化展示,我们可以更直观地了解裁员对员工的影响和企业的应对策略,为制定更加人性化、合理的裁员政策提供参考。
2.数据集介绍
本实验数据集来源于Kaggle,原始数据集为2020-2024年裁员数据,共有3577条,12个变量,该数据集提供了不同公司的裁员信息。它包括以下几栏:
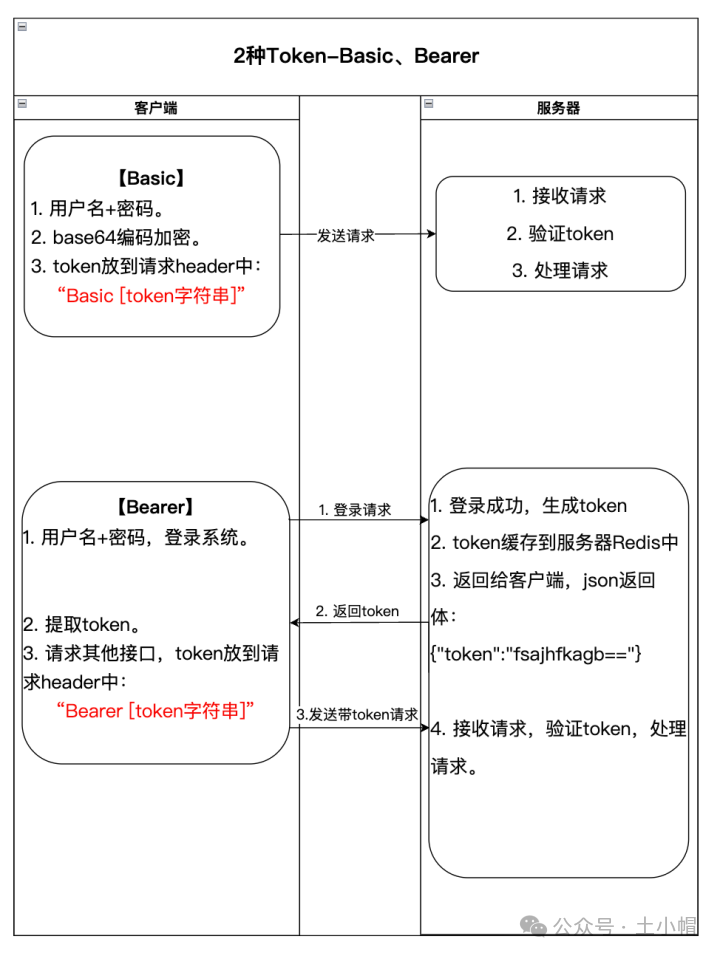
Company:裁员发生的公司名称。
Location_HQ:公司总部位置。
Industry:公司所属的行业或部门。
Laid_Off_Count:公司解雇的员工数量。
Percentage:公司员工被解雇的百分比。
Date:裁员发生的日期。
Source:信息来源网址。
Funds_Raised:公司募集资金的信息。
Stage:公司发展或成长的阶段。
Date_Added:数据库中添加的日期
Country:公司所在的国家。
List_of_Employees_Laid_Off:链接到谷歌文档的员工名单
该数据集专门用于跟踪和分析不同公司的裁员情况,为不同行业和地理位置的裁员提供见解。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
导入数据分析第三方库并加载数据集

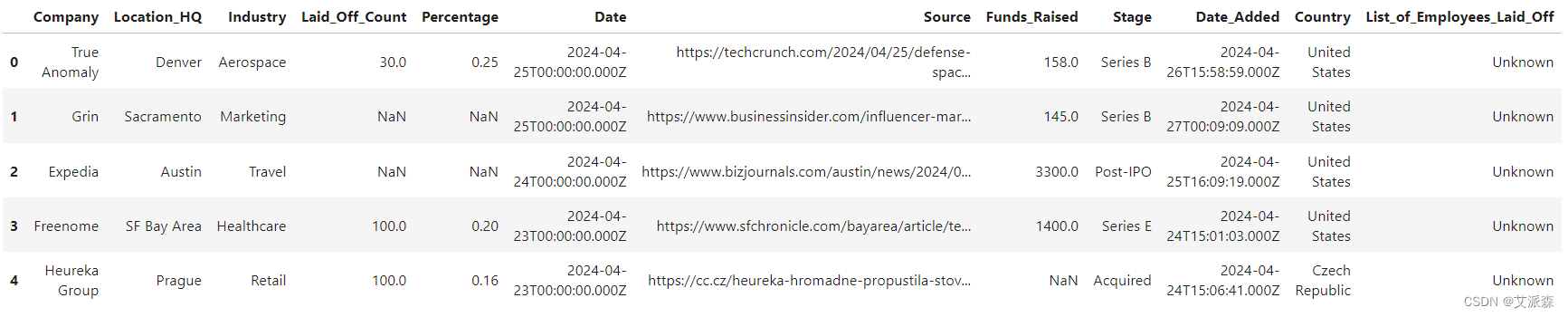
查看数据大小
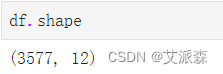
查看数据基本信息
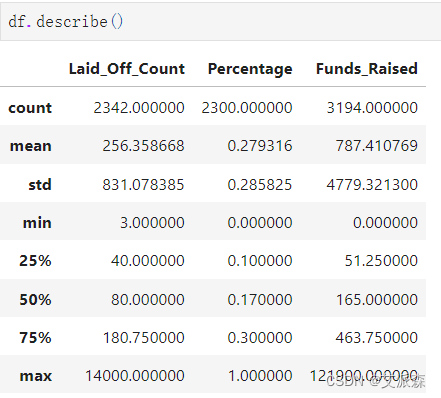
查看数值型变量的描述性统计
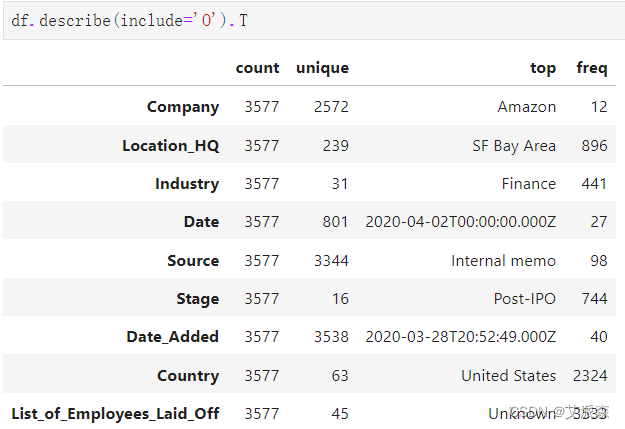
查看非数值型变量的描述性统计
统计数据集缺失值情况
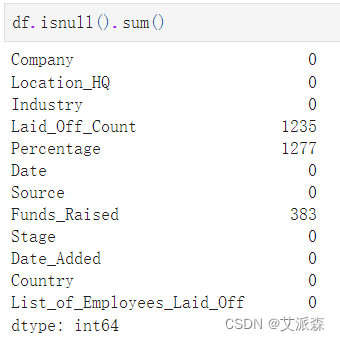
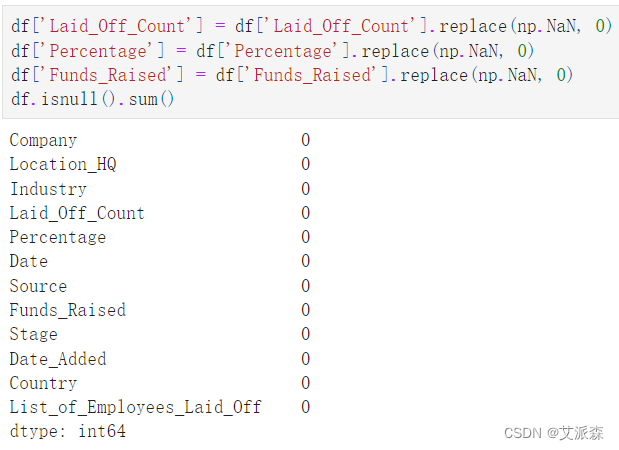
从结果看出,有三个变量存在缺失值,且缺失值较多,故我们采用0进行填充
统计重复值情况
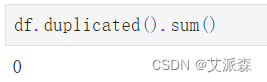
可以发现原始数据集不存在重复值
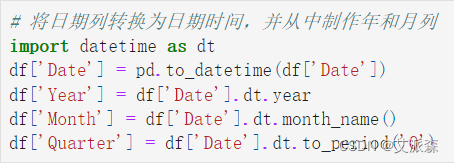
将日期列转换为日期时间,并从中制作年和月列,便于后面的可视化分析
5.数据可视化



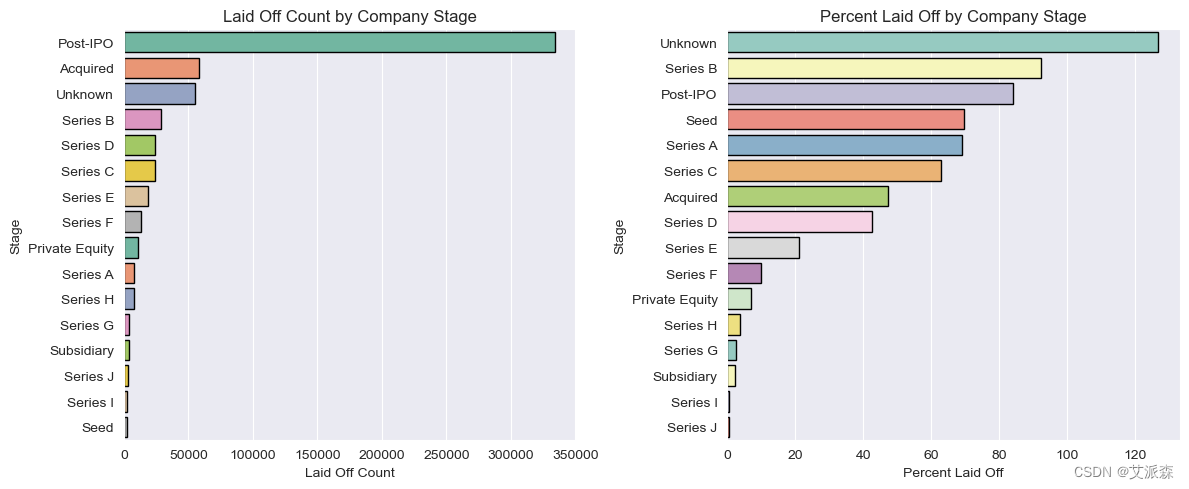
裁员最多的是上市后的公司,裁员比例最高的是b轮融资公司,相比之下,很多人都在上市后的公司工作。

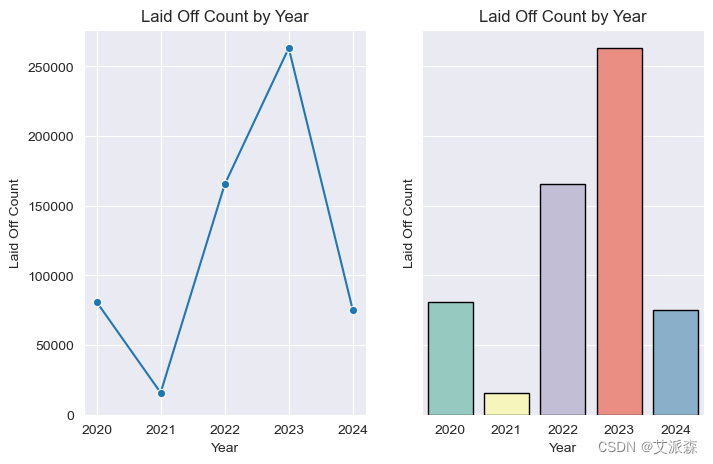
对员工来说,2023年是最糟糕的一年,2021年的裁员减少了很多,我们必须检查一下

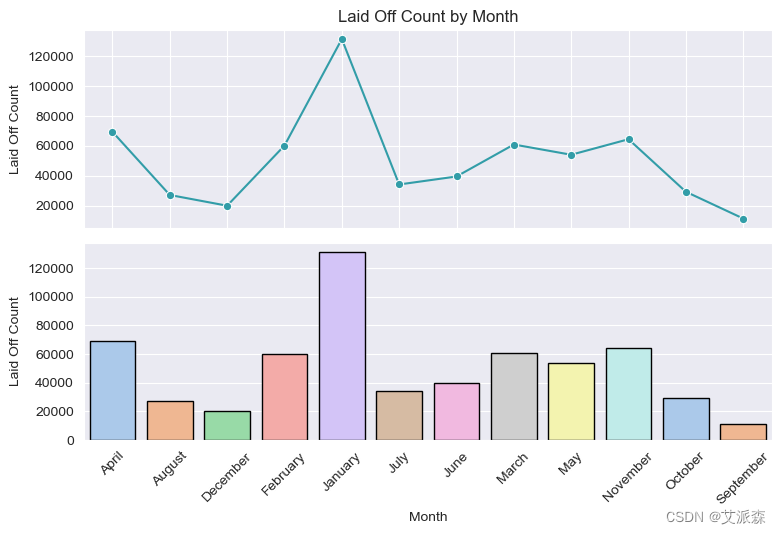
大多数裁员发生在1月份,裁员随时都可能发生。但就裁员最常发生的时间而言,1月和12月是众所周知的裁员高峰期。雇主们在每年的这个时候都在审查他们的预算。

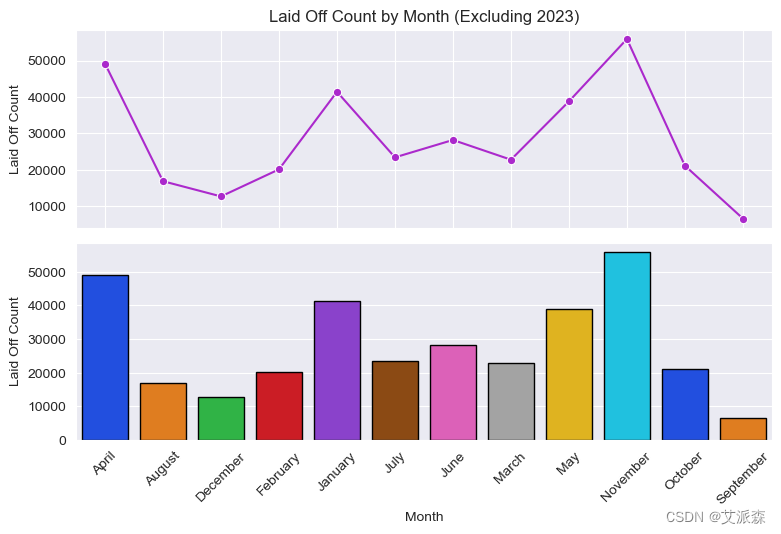
如果我们忽略2023年,由于大规模的经济衰退和公司在1月份解雇了大量员工,我们看到裁员通常发生在11月份。


美国的情况非常令人担忧,从柱状图中可以看出,美国的数据远远超过其他国家的数据,这对比较产生了明显的影响。



小结
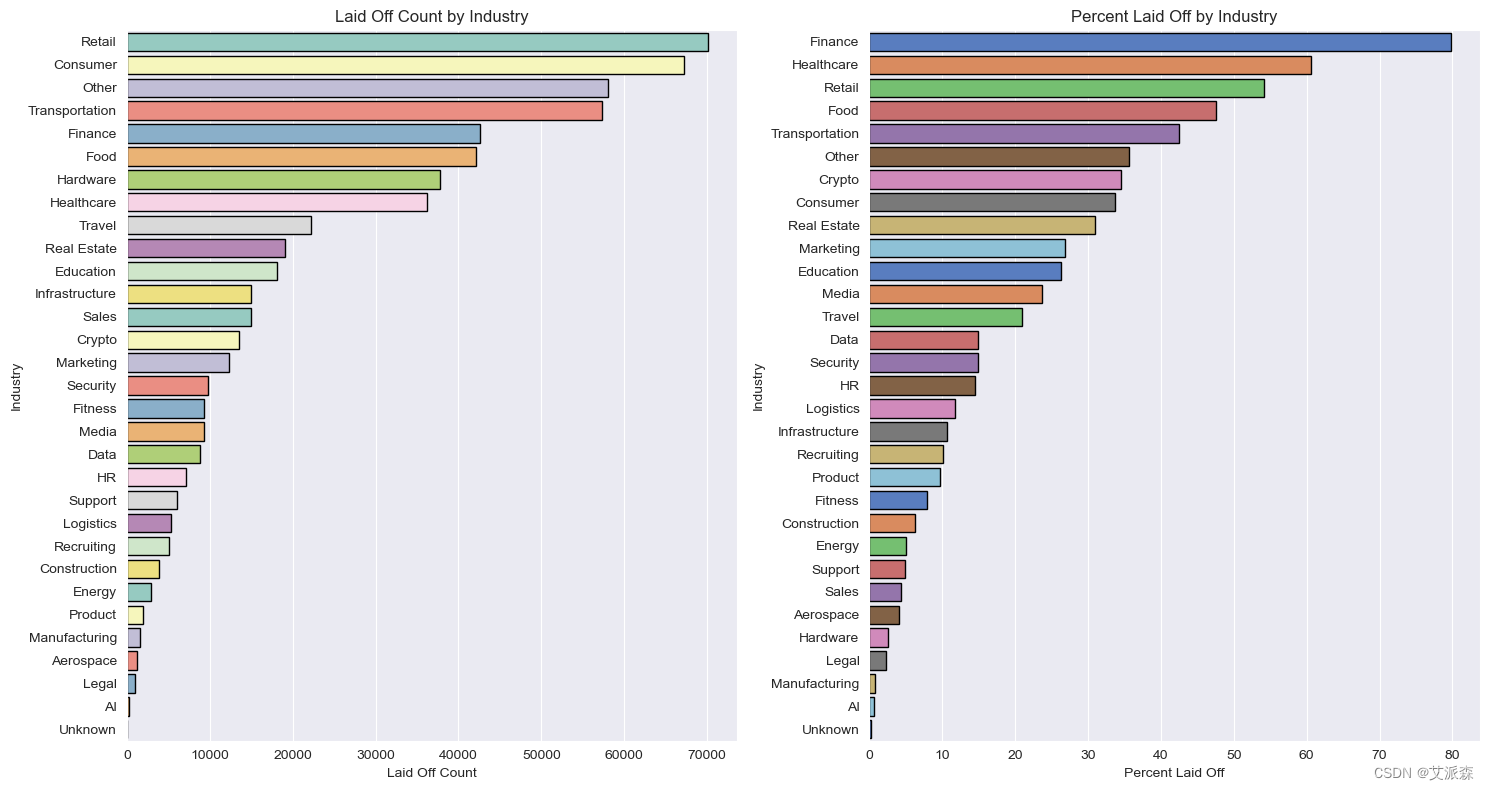
1.零售业裁员最多,而旅游业裁员最少。
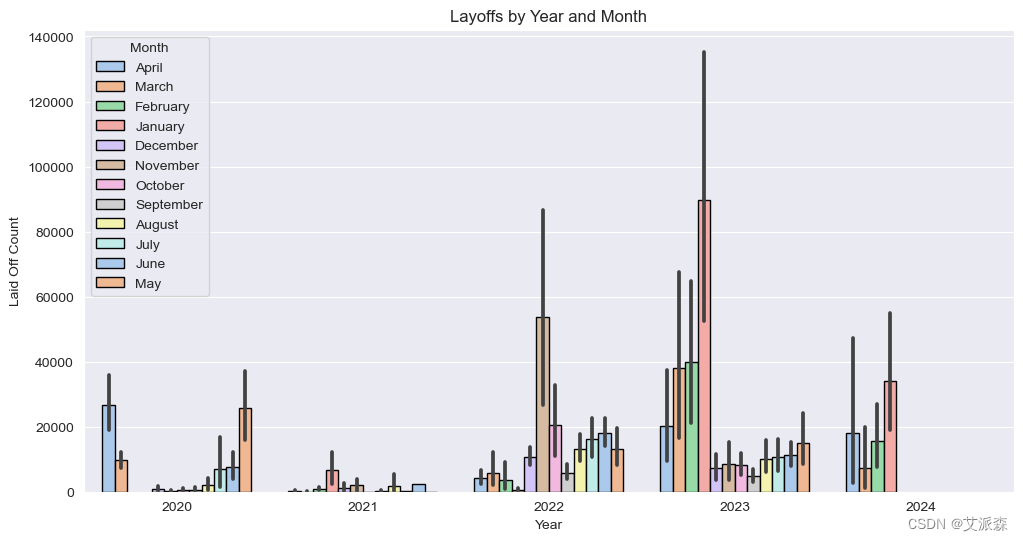
2.如图所示,在2022年,裁员人数达到了一个显著的峰值,这一趋势在2023年继续增加。
3.今年1月,裁员人数达到了历史最高水平,这与公司在这一时期进行财政年度结束和结算的惯例相符。
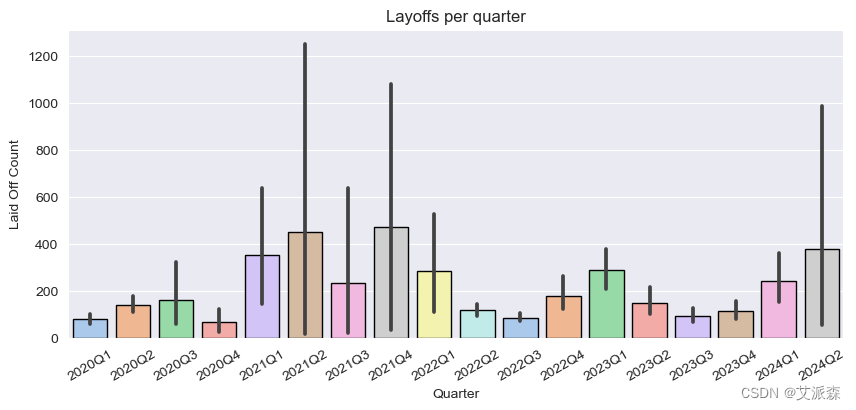
4.受新冠疫情影响,今年第二季度的裁员人数创下了历史最高纪录。
5.美利坚合众国报告的裁员人数最多,超过20万人,而印度的裁员人数第二多,不到5万人。
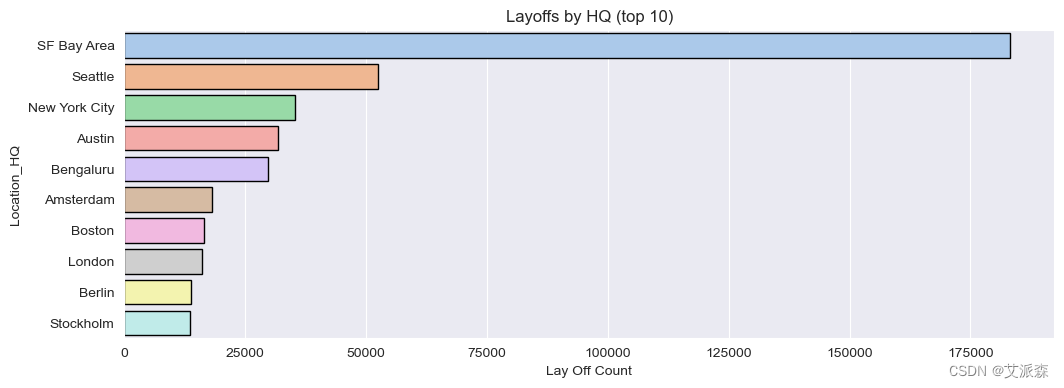
6.旧金山湾区的公司裁员数量最多。
7.大多数裁员(约24,000人)发生在白领岗位,尤其是在金融或金融科技公司。
8.与白领工作相比,蓝领工作,特别是运输部门的蓝领工作受到裁员的严重影响,裁员人数约为3.2万人。
10.科技巨头优步在2020年至2023年期间经历了多次裁员,总计裁员7000多人,在此期间裁员四次。
11.在首次公开募股之后,大多数美国公司都经历了裁员,尤其是在COVID-19大流行之后。值得注意的是,谷歌和微软都报告了类似程度的裁员。
源代码
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
sns.set_style("darkgrid")
df = pd.read_csv('layoffs_data.csv')
df.head()
df.shape
df.info()
df.describe()
df.describe(include='O').T
df.isnull().sum()
df['Laid_Off_Count'] = df['Laid_Off_Count'].replace(np.NaN, 0)
df['Percentage'] = df['Percentage'].replace(np.NaN, 0)
df['Funds_Raised'] = df['Funds_Raised'].replace(np.NaN, 0)
df.isnull().sum()
df.duplicated().sum()
# 将日期列转换为日期时间,并从中制作年和月列
import datetime as dt
df['Date'] = pd.to_datetime(df['Date'])
df['Year'] = df['Date'].dt.year
df['Month'] = df['Date'].dt.month_name()
df['Quarter'] = df['Date'].dt.to_period('Q')
# 行业分析
fig, ax = plt.subplots(1, 2,figsize=(15,8))
ax[0] = sns.barplot(data=df.groupby('Industry')['Laid_Off_Count'].sum().sort_values(ascending=False).reset_index(),
y='Industry', x='Laid_Off_Count', edgecolor='black', palette='Set3', ax=ax[0])
ax[0].set(title='Laid Off Count by Industry', xlabel='Laid Off Count')
ax[1] = sns.barplot(data=df.groupby('Industry')['Percentage'].sum().sort_values(ascending=False).reset_index(),
y='Industry', x='Percentage', edgecolor='black', palette='muted', ax=ax[1])
ax[1].set(title='Percent Laid Off by Industry', xlabel='Percent Laid Off')
plt.tight_layout()
fig.show()
# 阶段分析
fig, ax = plt.subplots(1, 2,figsize=(12,5))
ax[0] = sns.barplot(data=df.groupby('Stage')['Laid_Off_Count'].sum().sort_values(ascending=False).reset_index(),
y='Stage', x='Laid_Off_Count', edgecolor='black', palette='Set2', ax=ax[0])
ax[0].set(title='Laid Off Count by Company Stage', xlabel='Laid Off Count')
ax[1] = sns.barplot(data=df.groupby('Stage')['Percentage'].sum().sort_values(ascending=False).reset_index(),
y='Stage', x='Percentage', edgecolor='black', palette='Set3', ax=ax[1])
ax[1].set(title='Percent Laid Off by Company Stage', xlabel='Percent Laid Off')
plt.tight_layout()
fig.show()
结论
裁员最多的是上市后的公司
裁员比例最高的是b轮融资公司
相比之下,很多人都在上市后的公司工作
# 年度分析
fig, ax = plt.subplots(1,2, sharey=True, figsize=(8,5))
ax[0] = sns.lineplot(data=df.groupby('Year')['Laid_Off_Count'].sum().reset_index(), x='Year', y='Laid_Off_Count',
marker='o', ax=ax[0])
ax[0].set(title='Laid Off Count by Year', ylabel='Laid Off Count')
ax[1] = sns.barplot(data=df.groupby('Year')['Laid_Off_Count'].sum().reset_index(), x='Year', y='Laid_Off_Count',
ax=ax[1], palette='Set3', linewidth=1,edgecolor='black')
ax[1].set(title='Laid Off Count by Year', ylabel='Laid Off Count')
fig.show()
结论
对员工来说,2023年是最糟糕的一年
2021年的裁员减少了很多,我们必须检查一下
# 月分析
fig, ax = plt.subplots(2,1, sharex=True, figsize=(8,5))
ax[0] = sns.lineplot(data=df.groupby('Month')['Laid_Off_Count'].sum().reset_index(), x='Month', y='Laid_Off_Count',
marker='o', ax=ax[0], color='#329da8')
ax[0].set(title='Laid Off Count by Month', ylabel='Laid Off Count')
ax[1] = sns.barplot(data=df.groupby('Month')['Laid_Off_Count'].sum().reset_index(), x='Month', y='Laid_Off_Count',
ax=ax[1], palette='pastel', linewidth=1,edgecolor='black')
ax[1].set(ylabel='Laid Off Count')
plt.tight_layout()
plt.xticks(rotation=45)
fig.show()
结论
大多数裁员发生在1月份
在谷歌上快速搜索,这是我发现的:
裁员随时都可能发生。但就裁员最常发生的时间而言,1月和12月是众所周知的裁员高峰期。雇主们在每年的这个时候都在审查他们的预算。
fig, ax = plt.subplots(2,1, sharex=True, figsize=(8,5))
ax[0] = sns.lineplot(data=df.query("Year != 2023").groupby('Month')['Laid_Off_Count'].sum().reset_index(), x='Month', y='Laid_Off_Count',
marker='o', ax=ax[0], color='#ab29cc')
ax[0].set(title='Laid Off Count by Month (Excluding 2023)', ylabel='Laid Off Count')
ax[1] = sns.barplot(data=df.query("Year != 2023").groupby('Month')['Laid_Off_Count'].sum().reset_index(), x='Month', y='Laid_Off_Count',
ax=ax[1], palette='bright' , linewidth=1,edgecolor='black')
ax[1].set(ylabel='Laid Off Count')
plt.tight_layout()
plt.xticks(rotation=45)
fig.show()
如果我们忽略2023年,由于大规模的经济衰退和公司在1月份解雇了大量员工,我们看到裁员通常发生在11月份。
# 季度分析
fig, ax = plt.subplots(figsize=(10,4))
ax = sns.barplot(data=df.sort_values(by='Quarter'), x='Quarter', y='Laid_Off_Count'
,linewidth=1,edgecolor='black', palette='pastel')
ax.set(title='Layoffs per quarter', ylabel='Laid Off Count')
plt.xticks(rotation=30)
plt.show()
# 国家分析
fig, ax = plt.subplots(2,1,figsize=(10,5), sharex=True)
ax[0] = sns.barplot(data=df.groupby('Country')['Laid_Off_Count'].sum().sort_values(ascending=False).reset_index().head(10),
x='Country', y='Laid_Off_Count', linewidth=1,edgecolor='black', palette='deep', ax=ax[0])
ax[0].set(title='Layoffs by country (top 10)', ylabel='Lay Off Count')
ax[1] = sns.barplot(data=df.groupby('Country')['Laid_Off_Count'].sum().sort_values(ascending=False).reset_index().head(10),
x='Country', y='Laid_Off_Count', linewidth=1,edgecolor='black', palette='muted', ax=ax[1])
ax[1].set(title='Layoffs by country (top 10) - Log Scale', ylabel='Lay Off Count')
ax[1].set_yscale('log')
plt.tight_layout()
plt.xticks(rotation=30)
plt.show()
结论
美国的情况非常令人担忧,从柱状图中可以看出,美国的数据远远超过其他国家的数据,这对比较产生了明显的影响。
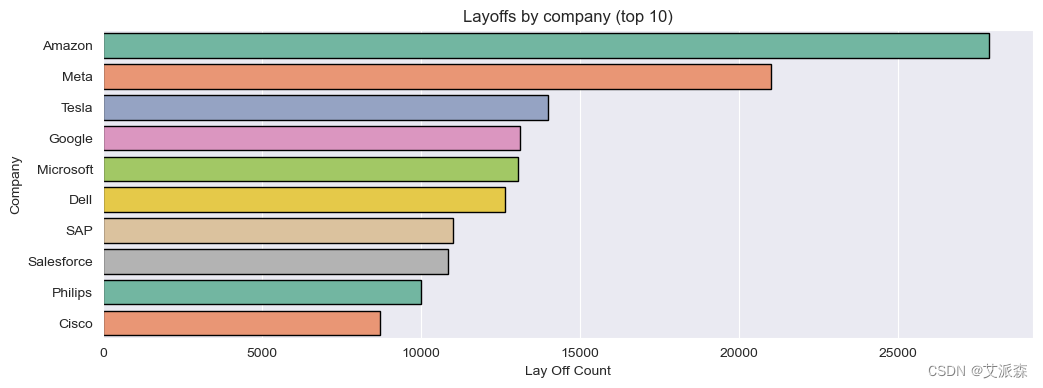
# 公司分析
fig, ax = plt.subplots(figsize=(12,4))
ax = sns.barplot(data= df.groupby('Company')['Laid_Off_Count'].sum().sort_values(ascending=False).reset_index().head(10),
x='Laid_Off_Count', y='Company'
,linewidth=1,edgecolor='black', palette='Set2', ax=ax)
ax.set(title='Layoffs by company (top 10)', xlabel='Lay Off Count')
plt.show()
# 总部分析
fig, ax = plt.subplots(figsize=(12,4))
ax = sns.barplot(data= df.groupby('Location_HQ')['Laid_Off_Count'].sum().sort_values(ascending=False).reset_index().head(10),
x='Laid_Off_Count', y='Location_HQ'
,linewidth=1,edgecolor='black', palette='pastel', ax=ax)
ax.set(title='Layoffs by HQ (top 10)', xlabel='Lay Off Count')
plt.show()
# 年、月分析
fig, ax = plt.subplots(figsize=(12,6))
ax = sns.barplot(data=df, x='Year', y='Laid_Off_Count', hue='Month',estimator=sum, edgecolor='black', ax = ax, palette='pastel')
ax.set(title='Layoffs by Year and Month', ylabel='Laid Off Count')
plt.show()
import plotly.express as px
world = df.groupby("Country")["Laid_Off_Count"].sum().reset_index()
figure = px.choropleth(world,locations="Country",
locationmode = "country names", color="Laid_Off_Count",
hover_name="Country",range_color=[1,10000],
color_continuous_scale="reds",
title="Countries having LayOffs")
figure.show()
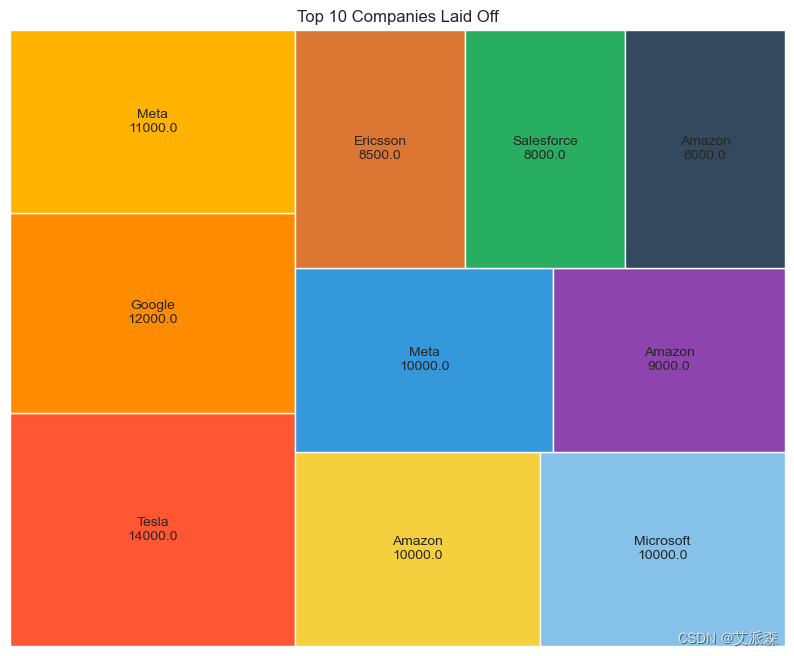
# 十大科技巨头裁员
import squarify
sorted_df = df.sort_values('Laid_Off_Count', ascending=False).head(10)
Companies = sorted_df["Company"].tolist()
Laid_off_count = sorted_df['Laid_Off_Count'].tolist()
colors = ['#FF5733', '#FF8C00', '#FFB300', '#F4D03F', '#85C1E9', '#3498DB', '#8E44AD', '#DC7633', '#27AE60', '#34495E']
sizes = [count / sum(Laid_off_count) for count in Laid_off_count]
labels = [f'{company}\n{laid_off_count}' for company, laid_off_count in zip(Companies, Laid_off_count)]
plt.figure(figsize=(10, 8))
squarify.plot(sizes=sizes,label = labels, color=colors)
plt.title('Top 10 Companies Laid Off')
plt.axis('off')
plt.show()资料获取,更多粉丝福利,关注下方公众号获取