文章目录
- 1、前言
- 2、Self-attention的特点
- 3、为什么是(Q, K, V)三元组
- 4、归一化和放缩
- 4.1、Normalization
- 4.2、Scaled
- 4.3、总结
- 5、Softmax的梯度变化
- 5.1、Softmax函数的输入分布是如何影响输出的
- 5.2、反向传播的过程中的梯度求导
- 5.3、出现梯度消失现象的原因
- 6、维度与点积大小的关系
- 7、小结
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎人工智能和前端开发。
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
1、前言
对于self-attention不太了解的,可以先看:https://xzl-tech.blog.csdn.net/article/details/141308634
解释了self-attention的详细运算机制
本文主要侧重的是Self-attention反向传播计算推导
对于本文的主要内容,如下:
- 掌握self-attention的机制和原理
- 掌握为什么要使用三元组(Q, K, V)来计算self-attention
- 理解 S o f t m a x Softmax Softmax函数的输入是如何影响输出分布的
- 理解 S o f t m a x Softmax Softmax函数反向传播进行梯度求导的数学过程
- 理解 S o f t m a x Softmax Softmax函数出现梯度消失的原因
- 理解self-attention计算规则中归一化的原因
2、Self-attention的特点
self-attention是一种通过自身和自身进行关联的attention机制,从而得到更好的representation来表达自身;
self-attention是attention机制的一种特殊情况,在self-attention中,Q=K=V,序列中的每个单词(token)都和该序列中的其他所有单词(token)进行attention规则的计算;
attention机制计算的特点在于,可以直接跨越一句话中不同距离的token,可以远距离的学习到序列的知识依赖和语序结构。
应用传统的RNN、LSTM在获取长距离语义特征和结构特征的时候,需要按照序列顺序依次计算,距离越远的联系信息的损耗越大,有效提取和捕获的可能性越小;
但是应用self-attention时,计算过程中会直接将句子中任意两个token的联系通过一个计算步骤直接联系起来。
3、为什么是(Q, K, V)三元组
关于self-attention为什么要使用(Q, K, V)三元组而不是其他形式:
- 首先一条就是从分析的角度看,查询Query是一条独立的序列信息,通过关键词Key的提示作用,得到最终语义的真实值Value表达,数学意义更充分、完备
- 这里不使用(K, V)或者(V)没有什么必须的理由,也没有相关的论文来严格阐述比较试验的结果差异,所以可以作为开放性问题未来去探索,只要明确在经典self-attention实现中用的是三元组就好。
4、归一化和放缩
这里有一个问题,那就是self-attention公式中的归一化有什么作用? 为什么要添加scaled?
Self-Attention中的归一化和缩放操作是Self-Attention机制中两个关键的步骤,它们对模型的稳定性和性能有重要影响。我们来详细讨论这两个问题。
4.1、Normalization
在Self-Attention公式中,归一化通常是指
S
o
f
t
m
a
x
Softmax
Softmax操作,它被用于将注意力分数转换为概率分布:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V
Attention(Q,K,V)=softmax(dkQKT)V
S
o
f
t
m
a
x
Softmax
Softmax归一化:
S
o
f
t
m
a
x
Softmax
Softmax函数将注意力分数 (即查询向量
Q
Q
Q 和键向量
K
K
K 的点积结果) 转换为一个概率分布。
这个分布的总和为1,每个元素的值介于0和1之间,表示模型在当前序列中“关注”每个位置的程度。
作用:
- 概率解释:通过归一化,模型可以根据注意力分数来判断当前步“关注”其他序列中位置的程度。
- 稳定性: S o f t m a x Softmax Softmax操作使得每个位置的注意力分数差异更加平滑,避免了模型过于依赖某些位置的信息,从而提高了模型的稳定性。
- 梯度的可控性: S o f t m a x Softmax Softmax使得梯度的范围在合理的区间内,避免了梯度爆炸或消失的问题。
4.2、Scaled
在Self-Attention中,缩放操作是指将查询和键的点积结果除以
d
k
\sqrt{d_k}
dk,即
Q
K
T
d
k
\frac{QK^T}{\sqrt{d_k}}
dkQKT
为什么要缩放:
- 避免过饱和的 S o f t m a x Softmax Softmax输出问题:查询向量 Q Q Q 和键向量 K K K 的点积结果可能会随着向量维度 d k d_k dk 的增加而增大,进而导致 S o f t m a x Softmax Softmax函数输出极端的概率值 (即接近于0或1),这会使得模型的注意力机制变得不稳定,过于关注某些位置,而忽略其他位置的信息。
- 稳定性: 缩放操作减少了点积结果的值,使得经由 S o f t m a x Softmax Softmax后的注意力分数更加平滑,从而使模型更稳定。这有助于模型更好地学习。
缩放的原理:
- 在计算查询向量 q q q 和键向量 k k k 的点积时,结果的值与向量的维度 d k d_k dk 成正比。
- 假设 q q q 和 k k k 的各个分量独立且均值为0,方差为1,那么点积结果的方差为 d k d_k dk。
- 因此,为了保持输出分数的稳定性,需要计算中主动将点积结果除以 d k \sqrt{d_k} dk 来抵消因方差增大的影响,这样点积后的结果依然满足均值为0、方差为1。
4.3、总结
- 归一化:通过 S o f t m a x Softmax Softmax将点积结果转换为概率分布,确保模型可以合理地分配注意力权重,提升稳定性和解释性。
- 缩放:通过除以 d k \sqrt{d_k} dk,缓解了随着向量维度增加而产生的值变大的问题,从而使得 S o f t m a x Softmax Softmax操作更加平滑和稳定,避免了梯度爆炸或消失的问题。
这两个步骤共同确保了Self-Attention机制在处理不同长度和维度的输入序列时,能够保持稳定的性能,并在训练过程中更容易优化。
5、Softmax的梯度变化
这里我们分3个步骤来解释 S o f t m a x Softmax Softmax的梯度问题:
- S o f t m a x Softmax Softmax函数的输入分布是如何影响输出的;
- S o f t m a x Softmax Softmax函数在反向传播的过程中是如何梯度求导的;
- S o f t m a x Softmax Softmax函数出现梯度消失现象的原因。
5.1、Softmax函数的输入分布是如何影响输出的
对于一个输入向量
x
x
x,
S
o
f
t
m
a
x
Softmax
Softmax函数将其做了一个归一化的映射,首先通过自然底数e将输入元素之间的差距先"拉大",然后再归一化为一个新的分布。
在这个过程中假设某个输入
x
x
x中最大的元素下标是
k
k
k,如果输入的数量级变大(就是
x
x
x中的每个分量绝对值都很大),那么在数学上会造成
y
k
y_k
yk的值非常接近1。
具体用一个例子来演示, 假设输入的向量
x
=
[
a
,
a
,
2
a
]
x = [a, a, 2a]
x=[a,a,2a],那么随便给几个不同数量级的值来看看对
y
3
y_3
y3产生的影响.
代码示例:
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/24 22:41
import numpy as np
import matplotlib.pyplot as plt
def softmax(x):
exp_x = np.exp(x)
return exp_x / np.sum(exp_x)
a_values = np.linspace(1, 10, 10)
print("a_values: ", a_values)
y3_values = []
for a in a_values:
x = [a, a, 2 * a]
y = softmax(x)
print("y: ", y)
y3_values.append(y[2]) # y[2] 是 y3 对应的输出
plt.plot(a_values, y3_values)
plt.xlabel('a')
plt.ylabel('y3')
plt.title('y3 vs a')
plt.show()
输出结果:
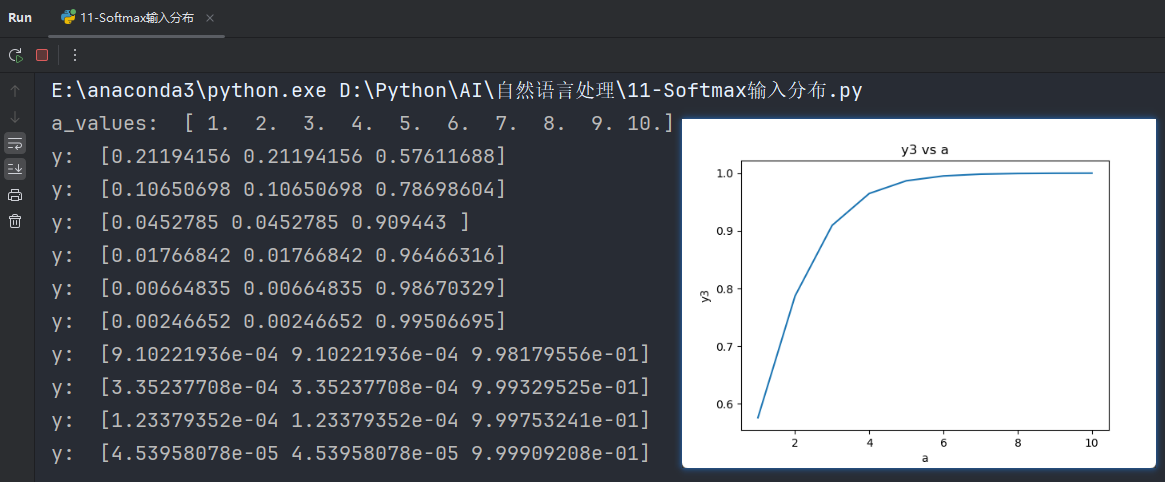
从上图可以很清楚的看到输入元素的数量级对
S
o
f
t
m
a
x
Softmax
Softmax最终的分布影响非常之大.
如果把代码的范围和数量扩大到100甚至是1000,图像就会更加平滑:

5.2、反向传播的过程中的梯度求导
关于 S o f t m a x ( ) Softmax() Softmax()函数:

首先定义神经网络的输入和输出:
设
X
=
[
x
1
,
x
2
,
⋯
,
x
n
]
,
Y
=
softmax
(
X
)
=
[
y
1
,
y
2
,
⋯
,
y
n
]
X=[x_1,x_2,\cdots,x_n],Y=\text{softmax}(X)=[y_1,y_2,\cdots,y_n]
X=[x1,x2,⋯,xn],Y=softmax(X)=[y1,y2,⋯,yn] 则
y
i
=
e
x
i
∑
j
=
1
n
e
x
j
y_i=\frac{e^{x_i}}{\sum_{j=1}^{n}e^{x_j}}
yi=∑j=1nexjexi ,
显然
∑
i
=
1
n
y
i
=
1
\sum_{i=1}^{n}y_i=1
∑i=1nyi=1
反向传播就是输出端的损失函数对输入端求偏导的过程,这里要分两种情况,
第一种如下所示:
-
当 i = j i=j i=j 时

-
当 i ≠ j i\neq j i=j 时:

经过对两种情况分别的求导计算:

对推导公式的解释:


5.3、出现梯度消失现象的原因
根据第二步中
S
o
f
t
m
a
x
Softmax
Softmax函数的求导结果, 可以将最终的结果以矩阵形式展开如下:
∂
g
(
X
)
∂
X
≈
[
y
^
1
0
⋯
0
0
y
^
2
⋯
0
⋮
⋮
⋱
⋮
0
0
⋯
y
^
d
]
−
[
y
^
1
2
y
^
1
y
^
2
⋯
y
^
1
y
^
d
y
^
2
y
^
1
y
^
2
2
⋯
y
^
2
y
^
d
⋮
⋮
⋱
⋮
y
^
d
y
^
1
y
^
d
y
^
2
⋯
y
^
d
2
]
\frac{\partial g(X)}{\partial X}\approx \begin{bmatrix} \hat y_1 & 0 & \cdots & 0 \\ 0 & \hat y_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \hat y_d \end{bmatrix} - \begin{bmatrix} \hat y_1^2 & \hat y_1 \hat y_2 & \cdots & \hat y_1 \hat y_d \\ \hat y_2 \hat y_1 & \hat y_2^2 & \cdots & \hat y_2 \hat y_d \\ \vdots & \vdots & \ddots & \vdots \\ \hat y_d \hat y_1 & \hat y_d \hat y_2 & \cdots & \hat y_d^2 \end{bmatrix}
∂X∂g(X)≈
y^10⋮00y^2⋮0⋯⋯⋱⋯00⋮y^d
−
y^12y^2y^1⋮y^dy^1y^1y^2y^22⋮y^dy^2⋯⋯⋱⋯y^1y^dy^2y^d⋮y^d2
根据第一步中的讨论结果, 当输入
x
x
x 的分量值较大时,
S
o
f
t
m
a
x
Softmax
Softmax函数会将大部分概率分配给最大的元素, 假设最大元素是
x
1
x_1
x1 , 那么
S
o
f
t
m
a
x
Softmax
Softmax的输出分布将产生一个接近one-hot的结果张量
y
=
[
1
,
0
,
0
,
…
,
0
]
y_ = [1, 0, 0,\dots, 0]
y=[1,0,0,…,0] , 此时结果矩阵变为:
∂
g
(
X
)
∂
X
≈
[
1
0
⋯
0
0
0
⋯
0
⋮
⋮
⋱
⋮
0
0
⋯
0
]
−
[
1
0
⋯
0
0
0
⋯
0
⋮
⋮
⋱
⋮
0
0
⋯
0
]
=
0
\frac{\partial g(X)}{\partial X}\approx \begin{bmatrix} 1 & 0 & \cdots & 0 \\\\ 0 & 0 & \cdots & 0 \\\\ \vdots & \vdots & \ddots & \vdots \\\\ 0 & 0 & \cdots & 0 \end{bmatrix} - \begin{bmatrix} 1 & 0 & \cdots & 0 \\\\ 0 & 0 & \cdots & 0 \\\\ \vdots & \vdots & \ddots & \vdots \\\\ 0 & 0 & \cdots & 0 \end{bmatrix}=0
∂X∂g(X)≈
10⋮000⋮0⋯⋯⋱⋯00⋮0
−
10⋮000⋮0⋯⋯⋱⋯00⋮0
=0
结论:综上可以得出,所有的梯度都消失为0(接近于0),参数几乎无法更新,模型收敛困难。
6、维度与点积大小的关系
针对为什么维度会影响点积的大小,原始论文(Attention Is All You Need)中有这样的一点解释如下:

我们分两步对其进行一个推导,首先假设向量
q
q
q 和
k
k
k 的各个分量是相互独立的随机变量,
X
=
q
i
X = q_i
X=qi,
Y
=
k
i
Y = k_i
Y=ki ,
X
X
X 和
Y
Y
Y 各自有
d
k
d_k
dk 个分量,也就是向量的维度等于
d
k
d_k
dk,有
E
(
X
)
=
E
(
Y
)
=
0
E(X) = E(Y) = 0
E(X)=E(Y)=0 ,以及
D
(
X
)
=
D
(
Y
)
=
1
D(X) = D(Y) = 1
D(X)=D(Y)=1。
那么可以得到随机变量的期望
E
(
X
Y
)
=
E
(
X
)
E
(
Y
)
E(XY) = E(X)E(Y)
E(XY)=E(X)E(Y)
同理,对于随机变量的方差
D
(
X
Y
)
D(XY)
D(XY) 推导如下:

根据期望和方差的性质,对于相互独立的变量满足下式:

对这两个公式解释一下:
- 期望的线性性质: E ( ∑ i Z i ) = ∑ i E ( Z i ) E\left( \sum_{i} Z_i \right) = \sum_{i} E(Z_i) E(∑iZi)=∑iE(Zi)
- 含义:这条公式表明,多个独立随机变量的和的期望等于这些随机变量的期望的和。
- 解释:
- 假设我们有一组相互独立的随机变量 Z 1 , Z 2 , … , Z n Z_1, Z_2, \dots, Z_n Z1,Z2,…,Zn。
- 如果我们将它们加在一起,得到 ∑ i Z i \sum_{i} Z_i ∑iZi。
- 公式表明,这个总和的期望值 E ( ∑ i Z i ) E\left( \sum_{i} Z_i \right) E(∑iZi) 可以直接等于每个随机变量的期望值 E ( Z i ) E(Z_i) E(Zi) 的总和 ∑ i E ( Z i ) \sum_{i} E(Z_i) ∑iE(Zi)。
- 线性代数:这就像在向量空间中,向量的线性组合的期望是各个向量期望的线性组合。期望值的这种性质使得它可以穿透到每个独立的分量上。
- 方差的可加性(针对独立随机变量): D ( ∑ i Z i ) = ∑ i D ( Z i ) D\left( \sum_{i} Z_i \right) = \sum_{i} D(Z_i) D(∑iZi)=∑iD(Zi)
- 含义:这条公式表明,多个独立随机变量的和的方差等于这些随机变量的方差的和。
- 解释:
- 同样地,假设我们有一组相互独立的随机变量 Z 1 , Z 2 , … , Z n Z_1, Z_2, \dots, Z_n Z1,Z2,…,Zn。
- 当我们将它们加在一起时,它们的方差 D ( ∑ i Z i ) D\left( \sum_{i} Z_i \right) D(∑iZi) 等于它们各自的方差之和 ∑ i D ( Z i ) \sum_{i} D(Z_i) ∑iD(Zi)。
- 为什么只适用于独立随机变量:
- 方差的可加性要求这些随机变量之间没有协方差,即它们是相互独立的。如果随机变量之间存在相关性(协方差不为零),那么它们之间的依赖关系会影响总和的方差。
- 在独立的情况下,协方差为零,因此方差可以直接相加。
- 总结
- 期望公式: 对于相互独立的随机变量,它们的和的期望等于各自期望的和。这是因为期望是线性的,可以穿透到每个独立的随机变量上
- 方差公式: 对于相互独立的随机变量,它们的和的方差等于各自方差的和。因为独立性保证了没有有效的额外协方差项需要考虑。
根据上面的公式,可以轻松的得出
q
⋅
k
q \cdot k
q⋅k 的均值为
E
(
q
k
)
=
0
E(qk) = 0
E(qk)=0,
D
(
q
k
)
=
d
k
D(qk) = d_k
D(qk)=dk。
所以方差越大,对应的
q
k
qk
qk 的点积就越大,这样
S
o
f
t
m
a
x
Softmax
Softmax 的输出分布就会更加偏向值所在的分量。
一个技巧就是将点积除以
d
k
\sqrt{d_k}
dk,将方差在数学上“重新”拉回 1:KaTeX parse error: {align*} can be used only in display mode.
最终的结论:通过数学上的技巧将方差控制在 1,也就有效的控制了点积结果的发散,也就控制了对应的梯度消失的问题。
7、小结
- s e l f − a t t e n t i o n self-attention self−attention机制的重点是使用三元组(Q, K, V)参与规则运算, 这里面 Q = K = V Q=K=V Q=K=V。
- s e l f − a t t e n t i o n self-attention self−attention最大的优越是可以方便有效的提取远距离依赖的特征和结构信息, 不必像向 R N N RNN RNN那样依次计算并传递结果。
- 关于 s e l f − a t t e n t i o n self-attention self−attention采用三元组的原因, 经典实现的方式数学意义明确, 理由充分, 至于其他方式的可行性暂时没有专门论文做充分的对比实验研究。
- 学习了
s
o
f
t
m
a
x
softmax
softmax函数的输出是如何影响输出分布的。
- s o f t m a x softmax softmax函数本质是对输入的数据做一次归一化处理, 但是输入元素的数量级对 s o f t m a x softmax softmax最终的分布影响非常之大。
- 在输入元素的数量级较大时, s o f t m a x softmax softmax函数几乎将全部的概率分布都分配给了最大值分量所对应的元素。
- 学习了
s
o
f
t
m
a
x
softmax
softmax函数在反向传播的过程中是如何梯度求导的。
- 具体的推导过程见正文部分, 注意要分两种情况讨论, 分别处理。
- 学习了
s
o
f
t
m
a
x
softmax
softmax函数出现梯度消失现象的原因。
- 结合第一步, 第二步的结论, 可以很清楚的看到最终的梯度矩阵接近于零矩阵, 这样在进行参数更新的时候就会导致梯度消失现象。
- 学习了维度和点积大小的关系推导。
- 通过期望和方差的推导理解了为什么点积会造成方差变大。
- 理解了通过数学技巧 d k \sqrt{d_k} dk就可以让方差恢复到1。






![[C++] 异常详解](https://i-blog.csdnimg.cn/direct/91b9f85d9d434021a32afb20a82654a9.jpeg)








![洛谷 P2254 [NOI2005] 瑰丽华尔兹](https://i-blog.csdnimg.cn/direct/e18ebdb9342b4b028d84829ebbc95b2e.png)


