✨✨ 欢迎大家来到贝蒂大讲堂✨✨🎈🎈养成好习惯,先赞后看哦~🎈🎈
所属专栏:数据结构与算法
贝蒂的主页:Betty’s blog

1. 跳表的概念
**跳表(Skiplist)**是在有序链表基础上增加了“跳跃”功能的一种数据结构。它在原来的有序链表上添加多级索引,以实现通过索引快速查找,能够支持快速的删除、插入和查找操作。实际上,跳表是一种增加了前向指针的链表,属于随机化的数据结构。
跳表本质上是一种查找结构,可作为key或者key/value的查找模型,与平衡搜索树和哈希表的价值一样,用于解决算法中的查找问题。跳表由William Pugh发明,最早出现于他在1990年发表的论文《Skip Lists: A Probabilistic Alternative to Balanced Trees》,对细节感兴趣的同学可以下载论文原文阅读。
2. 跳表的思路
2.1 提出问题
跳表最开始的思路如下:
William Pugh最初的想法是在有序链表中,每相邻两个节点升高一层,增加一个指针指向下下个节点,这样所有新增加的指针连成新的链表,且此链表包含的节点个数是原来的一半,如图b。- 以此类推,可在第二层新产生的链表上继续为每相邻两个节点升高一层增加指针,产生第三层链表,这样搜索效率进一步提高,如图c。
按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似二分查找,使得查找的时间复杂度可以从原本链表的 O ( N ) O(N) O(N)降低到 O ( l o g N ) O(logN) O(logN)。
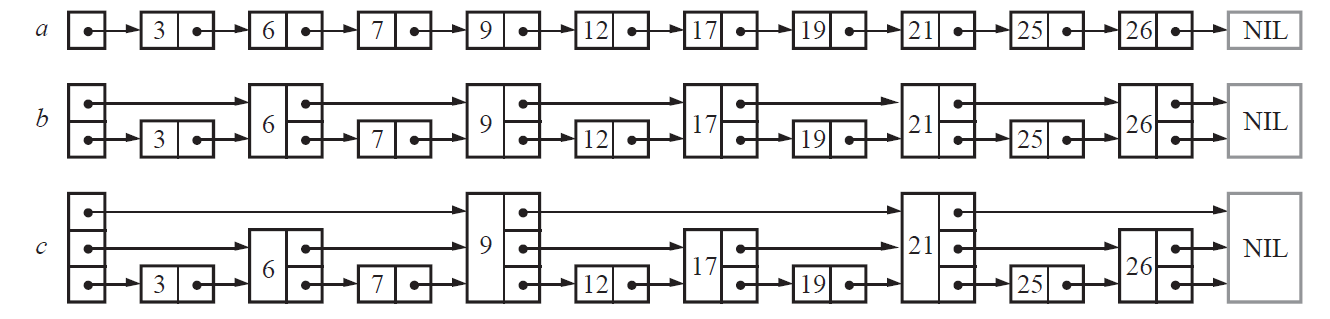
但是很快,William Pugh就发现这个结构在插入删除数据的时候有很大的问题,插入或者删除一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新劣为成
O
(
N
)
O(N)
O(N)。
2.2 解决方法
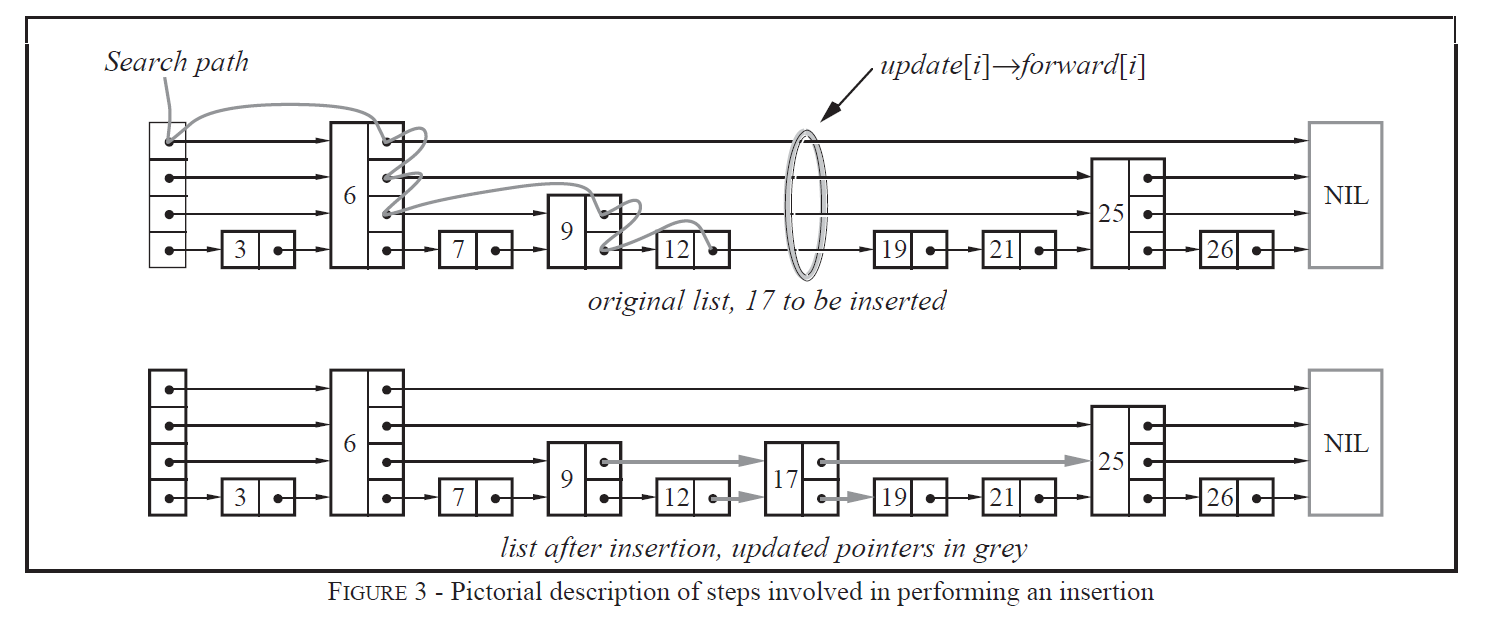
skiplist的设计为了避免这种问题,做了一个大胆的处理,不再严格要求对应比例关系,而是插入一个节点的时候随机出一个层数。这样每次插入和删除都不需要考虑其他节点的层数,这样就好处理多了。细节过程入下图:
3. 随机函数的设计
为了保证我们skiplist的效率,所以随机层数时一定要合理——保证层数越高的出现概率越小。William Pugh设计的伪代码如下:

在Redis中的skiplist实现中,这两个参数的取值为:
- p = 1/4
- MarxLevel = 32
根据前面randomLevel()的伪码,我们可以分析每一层的概率分布:
- 节点层数恰好等于1的概率为
1 - p。- 节点层数大于等于2的概率为
p,而节点层数恰好等于2的概率为p(1 - p)。- 节点层数大于等于3的概率为
p²,而节点层数恰好等于3的概率为p²(1 - p)。- 节点层数大于等于4的概率为
p³,而节点层数恰好等于4的概率为p³(1 - p)。
……
然后我们可以计算一个节点的平均层数,计算如下:
KaTeX parse error: {align*} can be used only in display mode.
现在很容易计算出:
- 当p=1/2时,每个节点所包含的平均指针数目为2;
- 当p=1/4时,每个节点所包含的平均指针数目为1.33。
4. 实现跳表
4.1 跳表的结构
为了适合所有类型,我们同样采用泛型编程的方式。其中跳表节点应该包含键值_val以及下几个节点的索引_nextV。而跳表中则需要包含三个成员变量:_head(头节点),_maxLevel(最大层数),_p(生成概率)。
template<class T>
//跳表节点
struct SkipListNode
{
T _val;
vector<SkipListNode*> _nextV;
SkipListNode(const T& val,int level)
:_val(val)
,_nextV(level,nullptr)
{}
};
//跳表
template<class T>
class SkipList
{
typedef SkipListNode<T> Node;
public:
SkipList();
bool Search(int target);
void Add(int num);
bool Erase(int num);
// 析构函数
~SkipList();
private:
Node* _head;
size_t _maxLevel = 32;
double _p = 0.25;
};
4.2 跳表的初始化为销毁
跳表的初始化只需要生成一个头结点,顺便播下随机种子即可。
SkipList()
{
srand((unsigned int)time(NULL));
_head = new Node(T(), 1);//初始化一个头节点
}
跳表的销毁和链表的销毁差不多,直接遍历销毁即可。
// 析构函数
~SkipList()
{
Node* cur = _head;
while (cur)
{
//保存下一个节点
Node* next = cur->_nextV[0];
delete cur;
cur = next;
}
}
4.3 跳表的查找
跳表的查找就是从最高层开始遍历,如果查找值比下一个索引节点的值要大,那么往右继续查找;如果查找值比下一个索引节点的值要小或者为空,则往下继续查找,最后如果找到节点返回true,否则返回false。
bool Search(int target)
{
Node* cur = _head;
//从最高层开始筛选
int level = _head->_nextV.size() - 1;
while (level >= 0)
{
//大于往右走
if (cur->_nextV[level] && target > cur->_nextV[level]->_val)
{
cur = cur->_nextV[level];
}
//为空或者小于等于往下走
else if (cur->_nextV[level] == nullptr || target < cur->_nextV[level]->_val)
{
--level;
}
//相当返回true
else
{
return true;
}
}
return false;
}
4.4 跳表的插入
跳表的插入逻辑稍微有点复杂,需要先找到插入位置的前驱节点集合,然后再实现链接。并且还需要实现一个随机函数,生成随机层数,如果层数比原来层数都大则需要更新层数。
//寻找前驱节点集合
vector<Node*> FindPrevNode(int num)
{
Node* cur = _head;
//从最高层开始筛选
int level = _head->_nextV.size() - 1;
vector<Node*> preV(level + 1, nullptr);
while (level >= 0)
{
//大于往右走
if (cur->_nextV[level] && num > cur->_nextV[level]->_val)
{
cur = cur->_nextV[level];
}
//为空或者小于等于往下走
else if (cur->_nextV[level] == nullptr || num <= cur->_nextV[level]->_val)
{
preV[level--] = cur;
}
}
return preV;
}
//生成随机层数
int RandomLevel()
{
size_t level = 1;
// rand() / RAND_MAX -> [0, 1]
while (rand() <= RAND_MAX * _p && level <= _maxLevel)
{
level++;
}
return level;
}
void Add(int num)
{
//寻找前驱节点
vector<Node*> preV = FindPrevNode(num);
//随机层数
int level = RandomLevel();
Node* newnode = new Node(num, level);
//如果超过最大层数
if (level > _head->_nextV.size())
{
_head->_nextV.resize(level, nullptr);
preV.resize(level, _head);
}
//链接前后节点
for (int i = 0; i < level; i++)
{
newnode->_nextV[i] = preV[i]->_nextV[i];
preV[i]->_nextV[i] = newnode;
}
}
4.5 跳表的删除
跳表的删除逻辑同样需要先找到该节点的前驱节点集合,然后重新链接后删除,如果删除的节点层数最高的话,最后还可以判断是否需要减少层数。
bool Erase(int num)
{
vector<Node*> preV = FindPrevNode(num);
// 第一层下一个不是val,则val不在跳表中
if (preV[0]->_nextV[0] == nullptr || preV[0]->_nextV[0]->_val != num)
{
return false;
}
//删除节点
Node* del = preV[0]->_nextV[0];
// del结点每一层前后指针链接起来
for (size_t i = 0; i < del->_nextV.size(); i++)
{
preV[i]->_nextV[i] = del->_nextV[i];
}
delete del;
// 如果删除最高层结点,把头节点的层数也降一下
int i = _head->_nextV.size() - 1;
while (i >= 0)
{
//直接为空
if (!_head->_nextV[i])
{
i--;
}
else
{
break;
}
}
//调整
_head->_nextV.resize(i + 1);
return true;
}
5. 复杂度分析
跳表的时间复杂度:
- 查找操作:
- 在跳表中进行查找操作时,从最高层开始,每一层最多进行一次比较和移动,直到找到目标元素或者到达底层。
- 由于每一层的节点数量逐渐增多,但节点之间的跨度也逐渐增大,因此在平均情况下,查找操作的时间复杂度为 O ( l o g n ) O(log n) O(logn),其中 n n n 是跳表中的元素数量。
- 插入操作:
- 插入操作首先需要进行查找,以确定插入的位置。这个查找过程的时间复杂度为 O ( l o g N ) O(logN) O(logN)。
- 然后,根据随机生成的层数,进行节点的插入操作。插入操作本身的时间复杂度是常数级别的,因为只需要调整一些指针。
- 总体来说,插入操作的时间复杂度也为 O ( l o g N ) O(logN) O(logN)。
- 删除操作:
- 删除操作同样先进行查找,找到要删除的元素。查找过程的时间复杂度为 O ( l o g N ) O(logN) O(logN)。
- 一旦找到要删除的元素,只需要调整一些指针来删除该元素,时间复杂度也是常数级别的。
- 所以删除操作的时间复杂度也是 O ( l o g N ) O(logN) O(logN)。
跳表的空间复杂度:
- 空间占用:
- 跳表的空间复杂度主要取决于节点的数量和层数。
- 在最理想的情况下,跳表的层数为 l o g N log N logN,其中 N N N 是元素数量。每个节点除了存储自身的值外,还需要存储指向不同层下一个节点的指针。
- 如果每层的指针占用固定的空间,那么总体的空间复杂度为 O ( N ) O(N) O(N),其中 N N N 是元素数量。
- 额外空间:
- 考虑到跳表在插入元素时需要随机生成层数,可能会有一些额外的空间开销用于存储随机数生成的状态等。但这些额外的空间开销相对较小,不会对总体的空间复杂度产生主要影响。
综上所述,跳表的时间复杂度为 O ( l o g N ) O(log N) O(logN),空间复杂度为 O ( N ) O(N) O(N)。
6. 跳表与平衡搜索树/哈希表的对比
以下是跳表与平衡搜索树(以 AVL 树和红黑树为例)以及哈希表的对比总结:
一、跳表与平衡搜索树对比
- 实现复杂度:
- 跳表实现相对简单,容易控制。在增删查改和遍历操作上,平衡树更加复杂。
- 空间消耗:
- 当跳表中参数 p = 1 / 2 p = 1/2 p=1/2 时,每个节点平均指针数目为 2;当 p = 1 / 4 p = 1/4 p=1/4 时,平均指针数目为 1.33。而平衡树的节点需要存储三叉链、平衡因子或颜色等信息,空间消耗相对较大。
二、跳表与哈希表对比
- 时间复杂度:
- 哈希表平均时间复杂度为 O ( 1 ) O(1) O(1),比跳表快。
- 空间消耗:
- 哈希表空间消耗略多一点。跳表相对空间消耗略小,因为哈希表存在链接指针和表空间消耗。
- 其他方面:
- 跳表的优势在于遍历数据有序,而哈希表无序。
- 哈希表扩容时有性能损耗。
- 在极端场景下,哈希冲突高时效率下降厉害,需要红黑树等补足接力,而跳表不存在此问题。
总体而言,跳表在实现复杂度和空间消耗上有一定优势,与平衡搜索树一样能保证数据有序遍历,虽然时间复杂度不如哈希表,但在一些需要有序性且对实现复杂度和空间有要求的场景下,跳表是一个不错的选择。
7. 源码
template<class T>
struct SkipListNode
{
T _val;
vector<SkipListNode*> _nextV;
SkipListNode(const T& val,int level)
:_val(val)
,_nextV(level,nullptr)
{}
};
template<class T>
class SkipList
{
typedef SkipListNode<T> Node;
public:
SkipList()
{
srand((unsigned int)time(NULL));
_head = new Node(T(), 1);//初始化一个头节点
}
bool Search(int target)
{
Node* cur = _head;
//从最高层开始筛选
int level = _head->_nextV.size() - 1;
while (level >= 0)
{
//大于往右走
if (cur->_nextV[level] && target > cur->_nextV[level]->_val)
{
cur = cur->_nextV[level];
}
//为空或者小于等于往下走
else if (cur->_nextV[level] == nullptr || target < cur->_nextV[level]->_val)
{
--level;
}
//相当返回true
else
{
return true;
}
}
return false;
}
void Add(int num)
{
//寻找前驱节点
vector<Node*> preV = FindPrevNode(num);
//随机层数
int level = RandomLevel();
Node* newnode = new Node(num, level);
//如果超过最大层数
if (level > _head->_nextV.size())
{
_head->_nextV.resize(level, nullptr);
preV.resize(level, _head);
}
//链接前后节点
for (int i = 0; i < level; i++)
{
newnode->_nextV[i] = preV[i]->_nextV[i];
preV[i]->_nextV[i] = newnode;
}
}
bool Erase(int num)
{
vector<Node*> preV = FindPrevNode(num);
// 第一层下一个不是val,则val不在跳表中
if (preV[0]->_nextV[0] == nullptr || preV[0]->_nextV[0]->_val != num)
{
return false;
}
//删除节点
Node* del = preV[0]->_nextV[0];
// del结点每一层前后指针链接起来
for (size_t i = 0; i < del->_nextV.size(); i++)
{
preV[i]->_nextV[i] = del->_nextV[i];
}
delete del;
// 如果删除最高层结点,把头节点的层数也降一下
int i = _head->_nextV.size() - 1;
while (i >= 0)
{
//直接为空
if (!_head->_nextV[i])
{
i--;
}
else
{
break;
}
}
//调整
_head->_nextV.resize(i + 1);
return true;
}
//寻找前驱节点集合
vector<Node*> FindPrevNode(int num)
{
Node* cur = _head;
//从最高层开始筛选
int level = _head->_nextV.size() - 1;
vector<Node*> preV(level + 1, nullptr);
while (level >= 0)
{
//大于往右走
if (cur->_nextV[level] && num > cur->_nextV[level]->_val)
{
cur = cur->_nextV[level];
}
//为空或者小于等于往下走
else if (cur->_nextV[level] == nullptr || num <= cur->_nextV[level]->_val)
{
preV[level--] = cur;
}
}
return preV;
}
//生成随机层数
int RandomLevel()
{
size_t level = 1;
// rand() / RAND_MAX -> [0, 1]
while (rand() <= RAND_MAX * _p && level <= _maxLevel)
{
level++;
}
return level;
}
// 析构函数
~SkipList()
{
Node* cur = _head;
while (cur)
{
//保存下一个节点
Node* next = cur->_nextV[0];
delete cur;
cur = next;
}
}
private:
Node* _head;
size_t _maxLevel = 32;
double _p = 0.25;
};