Awesome-LLMs-for-Video-Understanding 是 基于大型语言模型的视频理解研究
- github : https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding
- paper:Video Understanding with Large Language Models: A Survey
https://arxiv.org/pdf/2312.17432
视频理解的发展
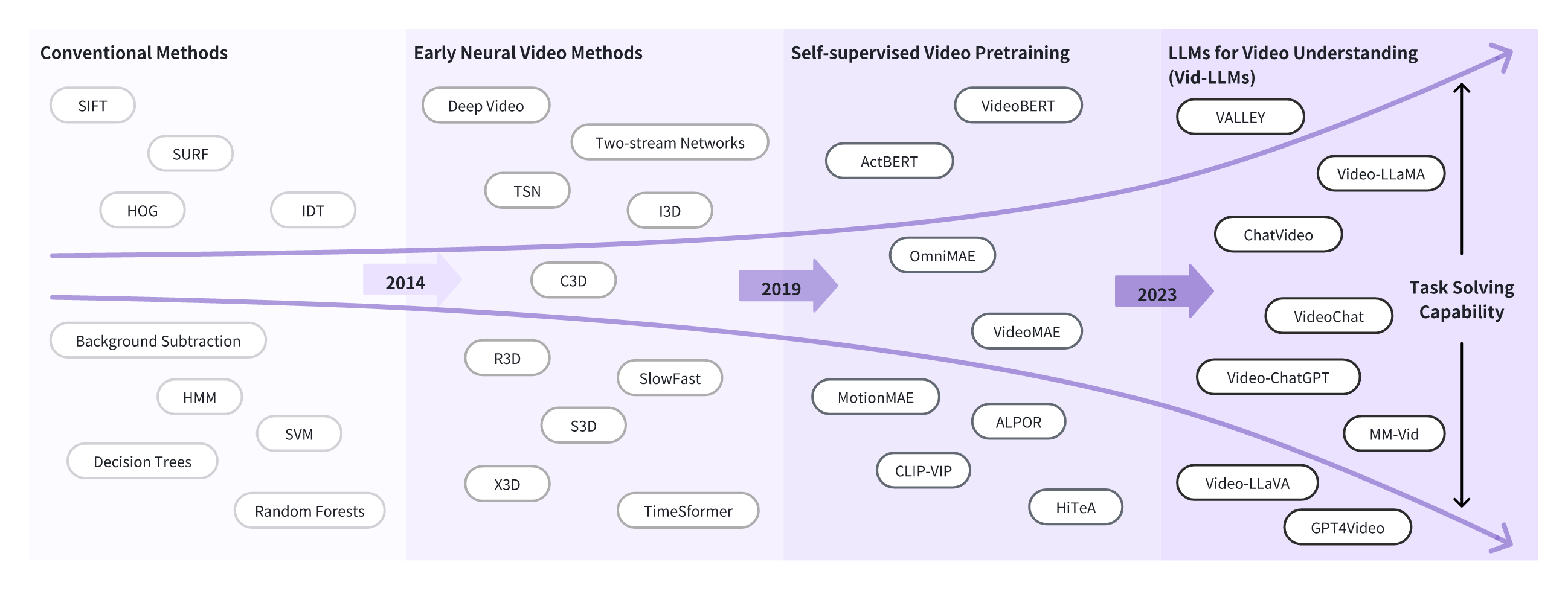
为什么我们需要 vid-llms ?
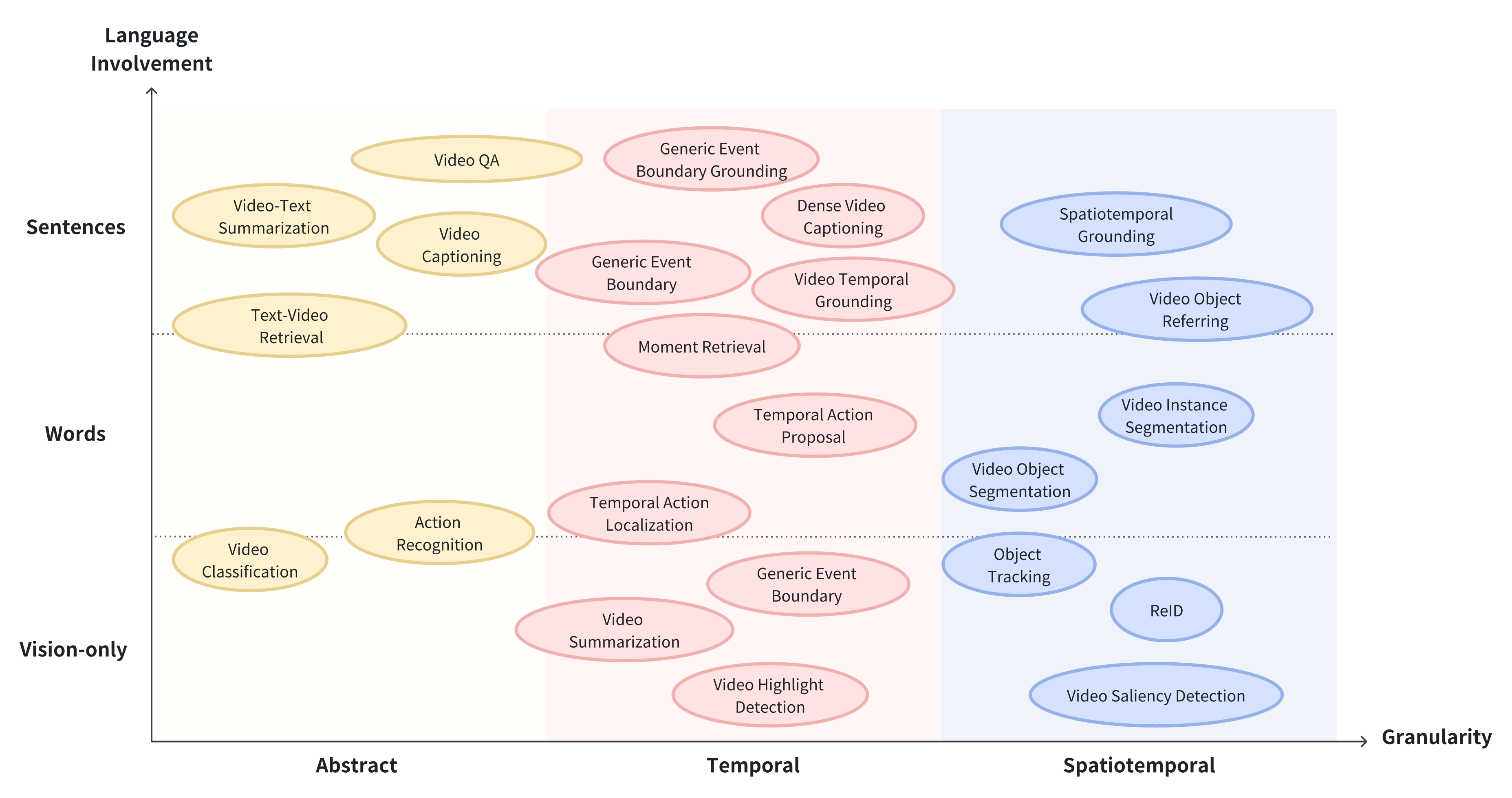
😎 Vid-LLMs:模型
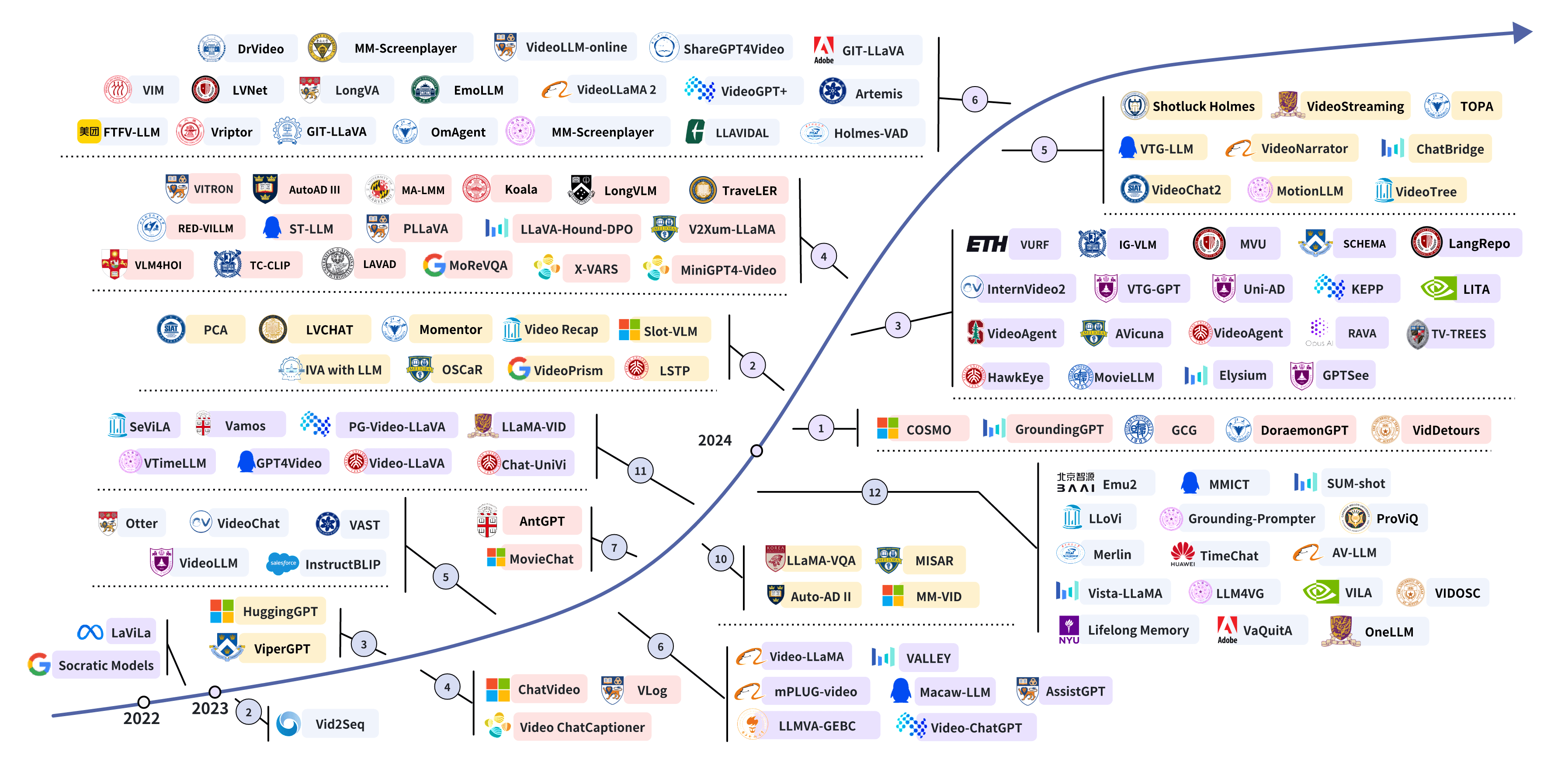
🤖基于llm的视频代理
| Title | Model | Date | Code | Venue |
|---|
| Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language | Socratic Models | 04/2022 | project page | arXiv |
| Video ChatCaptioner: Towards Enriched Spatiotemporal Descriptions github | Video ChatCaptioner | 04/2023 | code | arXiv |
| VLog: Video as a Long Document github | VLog | 04/2023 | code | - |
| ChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System | ChatVideo | 04/2023 | project page | arXiv |
| MM-VID: Advancing Video Understanding with GPT-4V(ision) | MM-VID | 10/2023 | - | arXiv |
| MISAR: A Multimodal Instructional System with Augmented Reality github | MISAR | 10/2023 | project page | ICCV |
| Grounding-Prompter: Prompting LLM with Multimodal Information for Temporal Sentence Grounding in Long Videos | Grounding-Prompter | 12/2023 | - | arXiv |
| NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation | NaVid | 02/2024 | project page - | RSS |
| VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding | VideoAgent | 03/2024 | project page | arXiv |
👾 Vid-LLM 预训练
| 标题 | 模型 | 日期 | 代码 | 聚会地点 |
|---|
| 从大型语言模型中学习视频表示 github | LaViLa | 12/2022 | 代码 | CVPR的 |
| Vid2Seq:密集视频字幕 视觉语言模型 的大规模预训练 | Vid2Seq | 02/2023 | 代码 | CVPR的 |
| 一个 视觉-音频-字幕-文本全模态基础模型和数据集 github | VAST | 05/2023 | 代码 | 神经IPS |
| Merlin : 赋予多式联运 LLM 以远见 | Merlin | 12/2023 | - | arXiv的 |
👀Vid-LLM指令调优
使用连接适配器进行微调
| 标题 | 模型 | 日期 | 代码 | 聚会地点 |
|---|
| Video- llama : 一个用于视频理解的教学微调视觉语言模型 github | Video-LLaMA | 06/2023 | 代码 | arXiv的 |
| VALLEY : 视频助手与大语言模型增强能力 github | VALLEY | 06/2023 | 代码 | - |
| 视频聊天技术:通过大视觉和语言模型实现详细的视频理解 github | Video-ChatGPT | 06/2023 | 代码 | arXiv的 |
| 多模态语言建模与图像、音频、视频和文本集成 github | Macaw-LLM | 06/2023 | 代码 | arXiv的 |
| LLMVA-GEBC:用于通用事件边界字幕的带有视频适配器的大型语言模型 github | LLMVA-GEBC | 06/2023 | 代码 | CVPR的 |
| Youku-mPLUG:用于预训练和基准测试的1000万大规模中文视频语言数据集 github | mPLUG-video | 06/2023 | 代码 | arXiv的 |
| MovieChat:从密集令牌到稀疏记忆的长视频理解 github | mPLUG-video | 07/2023 | 代码 | arXiv的 |
| 大型语言模型 是视频问答的时间 和因果推理器 github | LLaMA-VQA | 10/2023 | 代码 | EMNLP |
| Video-LLaVA:通过投影前的对齐学习统一的视觉表现 github | Video-LLaVA | 11/2023 | 代码 | arXiv的 |
| Chat-UniVi:统一的视觉表示使大型语言模型具有图像和视频理解能力 github | Chat-UniVi | 11/2023 | 代码 | arXiv的 |
| LLaMA-VID:在大型语言模型中,一个图像值2个符号 github | LLaMA-VID | 11/2023 | 代码 | arXiv的 |
| VISTA-LLAMA:可靠的视频叙述者通过相等距离的视觉标记 | VISTA-LLAMA | 12/2023 | - | arXiv的 |
| **视频理解视听 LLM ** | - | 12/2023 | - | arXiv的 |
| AutoAD:上下文中的电影描述 | AutoAD | 06/2023 | 代码 | CVPR的 |
| AutoAD II:续集-谁,什么时候,什么在电影音频描述 | AutoAD II | 10/2023 | - | ICCV |
| 多模态大型语言模型的细粒度视听联合表示 github | FAVOR | 10/2023 | 代码 | arXiv的 |
| **VideoLLaMA2:推进时空建模和音频理解视频 LLM ** github | VideoLLaMA2 | 06/2024 | 代码 | arXiv的 |
使用插入适配器进行微调
| 标题 | 模型 | 日期 | 代码 | 聚会地点 |
|---|
| Otter : 具有上下文指令调优的多模态模型 github | Otter | 06/2023 | 代码 | arXiv的 |
| VideoLLM : 用大语言模型建模视频序列 github | 视频 LLM | 05/2023 | 代码 | arXiv的 |
混合适配器微调
| 标题 | 模型 | 日期 | 代码 | 聚会地点 |
|---|
| VTimeLLM:授权 LLM 掌握视频时刻 github | VTimeLLM | 11/2023 | 代码 | arXiv的 |
| GPT4Video:用于指令跟随理解和安全意识生成的统一多模态大语言模型 | GPT4Video | 11/2023 | - | arXiv的 |
🦾混合方法
| 标题 | 模型 | 日期 | 代码 | 聚会地点 |
|---|
| VideoChat:以聊天为中心的视频理解 github | VideoChat | 05/2023 | 代码演示 | arXiv的 |
| PG-Video-LLaVA:像素接地大型视频语言模型 github | PG-Video-LLaVA | 11/2023 | 代码 | arXiv的 |
| TimeChat:用于长视频理解的时间敏感多模态大型语言模型 github | TimeChat | 12/2023 | 代码 | CVPR的 |
| Video-GroundingDINO : 走向开放词汇时空视频接地 github | Video-GroundingDINO | 12/2023 | 代码 | arXiv的 |
| 一个视频价值4096个代币:用语言描述视频,以零镜头理解它们 | Video4096 | 05/2023 | | EMNLP |
🦾免培训方法
| 标题 | 模型 | 日期 | 代码 | 聚会地点 |
|---|
| SlowFast-LLaVA : 视频大型语言模型的强大无训练基线 | SlowFast-LLaVA | 07/2024 | - | arXiv的 |
任务、数据集和基准
认知与预期
| 名字 | 纸 | 日期 | 链接 | 聚会地点 |
|---|
| Charades | 家庭中的好莱坞:众包数据收集以了解活动 | 2016 | 链接 | ECCV |
| YouTube8M | YouTube-8M:一个大规模视频分类基准 | 2016 | 链接 | - |
| ActivityNet | ActivityNet:人类活动理解的大规模视频基准 | 2015 | 链接 | CVPR的 |
| Kinetics-GEBC | GEB:通用事件边界标注、基础和检索的基准 | 2022 | 链接 | ECCV |
| **Kinetics-400 | 动力学人类动作视频数据集 | 2017 | 链接 | - |
| VidChapters-7M | VidChapters-7M : 视频章节的规模 | 2023 | 链接 | 神经IPS |
标题和描述
| 名字 | 纸 | 日期 | 链接 | 聚会地点 |
|---|
| 微软研究视频描述语料库 | Microsoft Research Video Description Corpus (MSVD) | 为释义评估收集高度平行的数据 | 2011 | 链接 | ACL |
| 微软研究院视频转文本(MSR-VTT) | MSR-VTT:用于桥接视频和语言的大型视频描述数据集 | 2016 | 链接 | CVPR |
| Tumblr GIF (GIF) | TGIF:动画GIF描述的新数据集和基准 | 2016 | 链接 | CVPR |
| Charades | 家庭中的好莱坞:活动理解的众包数据收集 | 2016 | 链接 | ECCV |
| Charades-Ego | 演员和观察者:第一人称和第三人称视频的联合建模 | 2018 | 链接 | CVPR |
| ActivityNet Captions | 视频中的密集字幕事件 | 2017 | 链接 | ICCV |
| HowTo100m | HowTo100M:通过观看1亿段视频片段来学习文本视频嵌入 | 2019 | 链接 | ICCV |
| Movie Audio Descriptions (MAD) | 一个可扩展的数据集,用于从电影音频描述的视频的语言基础 | 2021 | 链接 | CVPR的 |
| YouCook2 | 基于网络教学视频的程序自动学习 | 2017 | 链接 | AAAI |
| MovieNet | MovieNet:电影理解的整体数据集 | 2020 | 链接 | ECCV |
| Youku-mPLUG | Youku-mPLUG:用于预训练和基准测试的1000万大规模中文视频语言数据集 | 2023 | 链接 | arXiv |
| Video Timeline Tags (ViTT) | 密集视频字幕的多模态预训练 | 2020 | 链接 | AACL-IJCNLP |
| TVSum | TVSum:使用标题总结网络视频 | 2015 | 链接 | CVPR的 |
| SumMe | 从用户视频创建摘要 | 2014 | 链接 | ECCV |
| VideoXum | VideoXum:视频的跨模态视觉和纹理摘要 | 2023 | 链接 | IEEE Trans Multimedia |
| Multi-Source Video Captioning (MSVC) | **VideoLLaMA2:推进时空建模和音频理解视频 LLM ** | 2024 | 链接 | arXiv |
接地与回收
| 名字 | 纸 | 日期 | 链接 | 聚会地点 |
|---|
| Epic-Kitchens-100 | 重新调整自我中心视野 | 2021 | 链接 | IJCV |
| VCR (Visual Commonsense Reasoning) | 从识别到认知:视觉常识推理 | 2019 | 链接 | CVPR的 |
| Ego4D-MQ 和 Ego4D-NLQ | Ego4D:环游世界在3000小时的自我中心视频 | 2021 | 链接 | CVPR的 |
| Vid-STG | 它在哪里:多形式句子的时空视频基础 | 2020 | 链接 | CVPR的 |
| Charades-STA | TALL:通过语言查询进行时间活动定位 | 2017 | 链接 | ICCV |
| DiDeMo | 用自然语言定位视频中的瞬间 | 2017 | 链接 | ICCV |
问题回答
| 名字 | 纸 | 日期 | 链接 | 聚会地点 |
|---|
| MSVD-QA | 通过对外观和动作的逐渐细化的注意进行视频问答 | 2017 | 链接 | ACM Multimedia |
| MSRVTT-QA | 通过对外观和动作的逐渐细化的注意进行视频问答 | 2017 | 链接 | ACM Multimedia |
| TGIF-QA | TGIF-QA:面向视觉问答的时空推理 | 2017 | 链接 | CVPR |
| ActivityNet-QA | ActivityNet-QA:一个通过问答来理解复杂网络视频的数据集 | 2019 | 链接 | AAAI |
| Pororo-QA | DeepStory:视频故事QA由深度嵌入式记忆网络 | 2017 | 链接 | IJCAI |
| TVQA | TVQA:本地化,组合视频问答 | 2018 | 链接 | EMNLP |
视频教学调优
预训练 数据集
| 名字 | 纸 | 日期 | 链接 | 聚会地点 |
|---|
| VidChapters-7分钟 | 视频章节- 7m:视频章节的规模 | 2023 | 链接 | 神经IPS |
| 值为1米 | VALOR:视觉-听觉-语言全感知预训练模型和数据集 | 2023 | 链接 | arXiv的 |
| Youku-mPLUG | Youku-mPLUG:用于预训练和基准测试的1000万大规模中文视频语言数据集 | 2023 | 链接 | arXiv的 |
| InternVid(英语:InternVid) | intervid:用于多模态理解和生成的大规模视频文本数据集 | 2023 | 链接 | arXiv的 |
| VAST-27M | 一个视觉-音频-字幕-文本全模态基础模型和数据集 | 2023 | 链接 | 神经IPS |
微调数据集
| 名字 | 纸 | 日期 | 链接 | 聚会地点 |
|---|
| 模仿它 | MIMIC-IT:多模态上下文指令调谐 | 2023 | 链接 | arXiv的 |
| VideoInstruct100K | 视频聊天技术:通过大视觉和语言模型实现详细的视频理解 | 2023 | 链接 | arXiv的 |
| TimeIT公司 | TimeChat:用于长视频理解的时间敏感多模态大型语言模型 | 2023 | 链接 | CVPR的 |
基于视频的大型语言模型基准
| 标题 | 日期 | 代码 | 聚会地点 |
|---|
| LVBench:一个极长的视频理解基准 | 06/2024 | 代码 | - |
| Video-Bench:用于评估基于视频的大型语言模型的综合基准和工具包 | 11/2023 | 代码 | - |
| 感知测试:多模态视频模型的诊断基准 | 05/2023 | 代码 | NeurIPS 2023, ICCV 2023 研讨会 |
| Youku-mPLUG:用于预训练和基准测试的1000万大规模中文视频语言数据集 github | 07/2023 | 代码 | - |
| FETV:开放域文本到视频生成的细粒度评估基准 github | 11/2023 | 代码 | 神经IPS 2023 |
| MoVQA:理解长篇电影的通用问答基准 | 12/2023 | 代码 | - |
| MVBench:一个全面的多模态视频理解基准 | 12/2023 | 代码 | - |
| TempCompass:视频 LLM 真的懂视频吗? github | 03/2024 | 代码 | ACL 2024 |
| Video- mme:首个视频分析中多模态 LLM 的综合评估基准 github | 06/2024 | 代码 | - |
| 视频幻觉:在大型视频语言模型中评估内在和外在幻觉 github | 06/2024 | 代码 | - |
2024-08-24(六)









![[数据集][目标检测]红外场景下车辆和行人检测数据集VOC+YOLO格式19069张4类别](https://i-blog.csdnimg.cn/direct/dc64255d3e294f138c58f83fd8334275.png)