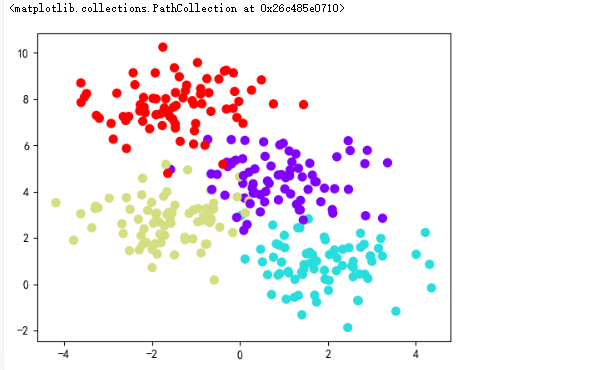
计算机视觉(Computer Vision, CV)是一门多学科交叉的科学,旨在让计算机具备“看”的能力,即通过图像或视频数据来理解世界。它结合了信号处理、图像处理、模式识别、机器学习等多个领域的技术,让计算机能够执行诸如识别、分类、追踪等复杂的视觉任务。本文将深入探讨计算机视觉的核心概念和技术。
一、计算机视觉概述
计算机视觉是一门研究如何让计算机“看”世界并从中获取信息的科学。它主要关注如何处理、分析和理解图像和视频数据,以实现自动化任务的完成。计算机视觉的目标之一就是让机器能够模拟人类的视觉功能。
二、计算机视觉的基本流程
计算机视觉的任务一般遵循以下几个基本步骤:
- 数据采集:获取图像或视频数据。
- 预处理:包括图像增强、归一化、裁剪等,以改善图像质量。
- 特征提取:从图像中提取有用的特征,如边缘、角点、纹理等。
- 特征匹配:在不同的图像之间寻找相似特征。
- 目标检测:识别和定位图像中的对象。
- 目标识别:确定检测到的对象属于哪个类别。
- 语义理解:理解图像中的场景和上下文信息。
三、关键技术与算法
1. 图像处理
- 灰度转换:将彩色图像转换为灰度图像。
- 滤波器:用于降噪、锐化、模糊等。
- 边缘检测:使用Sobel、Canny等算法检测图像中的边缘。
- 直方图均衡化:调整图像对比度。
2. 特征提取
- SIFT (Scale-Invariant Feature Transform):尺度不变特征变换。
- SURF (Speeded Up Robust Features):加速鲁棒特征。
- HOG (Histogram of Oriented Gradients):方向梯度直方图。
- ORB (Oriented FAST and Rotated BRIEF):方向快速响应和旋转简明特征。
3. 深度学习
- 卷积神经网络 (Convolutional Neural Networks, CNNs):用于图像分类和识别。
- R-CNN (Region-based Convolutional Neural Networks):用于目标检测。
- YOLO (You Only Look Once):实时目标检测框架。
- U-Net:用于语义分割的架构。
- GANs (Generative Adversarial Networks):生成对抗网络,用于图像生成。
4. 目标检测与识别
- 滑动窗口:遍历图像,寻找特定大小的目标。
- 候选区域:选择感兴趣区域进行检测。
- 多尺度检测:适应不同大小的目标。
5. 语义分割
- 全卷积网络 (FCNs):用于像素级别的分类。
- 条件随机场 (CRFs):优化分割结果。
6. 实例分割
- Mask R-CNN:扩展R-CNN以实现像素级别的分割。
- DeepLab:利用空洞卷积进行分割。
7. 三维重建
- 立体视觉:使用两幅或多幅图像估计深度。
- 光流法:跟踪图像序列中像素的移动来估计运动。
- 结构光:投射已知图案来辅助三维重建。
8. 动态场景分析
- 背景减除:从视频流中移除静态背景。
- 运动检测:检测视频中的运动。
- 光流估计:估计像素的运动方向和速度。
四、计算机视觉的应用
- 自动驾驶:车辆使用摄像头和其他传感器来感知周围环境。
- 医学成像:用于辅助诊断疾病,如癌症早期检测。
- 安全监控:自动识别异常行为或面部识别。
- 增强现实/虚拟现实:提供沉浸式体验,如游戏和教育软件。
- 工业检测:用于检查产品质量和一致性。
- 无人机导航:用于自主飞行和避障。
- 生物识别:如指纹、虹膜识别。
- 艺术与设计:用于图像编辑、生成艺术作品。
五、挑战
尽管计算机视觉取得了显著进展,但仍面临许多挑战,包括但不限于:
- 低光照条件下的图像处理。
- 大规模图像数据库的管理。
- 小样本学习和无监督学习。
- 模型的可解释性。
随着技术的发展,未来的计算机视觉系统将会更加智能、高效,并且能够处理更加复杂和多样化的视觉任务。




![[数据集][目标检测]红外场景下车辆和行人检测数据集VOC+YOLO格式19069张4类别](https://i-blog.csdnimg.cn/direct/dc64255d3e294f138c58f83fd8334275.png)







![[云计算] 虚拟化笔记](https://i-blog.csdnimg.cn/direct/3ca19254888f452f9b3409139991bc47.png#pic_center)