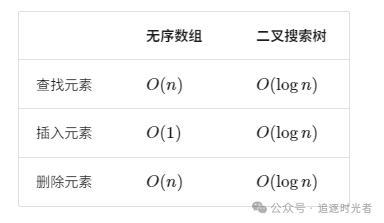
说一下 HashMap 的实现原理?
JDK1.7
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。(其实所谓Map其实就是保存了两个对象之间的映射关系的一种集合),其中Key 和 Value 允许为null。这些个键值对(Entry)分散存储在一个数组当中,HashMap数组每一个元素的初始值都是Null。

骚戴理解:HashMap不能保证映射的顺序,插入后的数据顺序也不能保证一直不变(如1.8以前的扩容操作会导致顺序变化)
Entry是HashMap中的一个静态内部类.
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
} HashMap的总体结构如下

骚戴理解:简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
JDK1.8

JDK 1.8 中 HashMap 的底层原理是采用数组+链表+红黑树的结构实现的,主要包括以下几个方面:
1. 数组:HashMap 内部维护了一个数组,用于存储键值对。数组的长度是固定的,且必须是 2 的幂次方。
2. 链表:数组中的每个元素都是一个链表的头结点,用于存储哈希值相同的键值对。当链表长度超过8(TREEIFY_THRESHOLD - 阈值)时,链表就自行转为红黑树,以提高查找效率。
3. 红黑树:当链表长度超过一定阈值时,HashMap 会将链表转换为红黑树,以提高查找效率。红黑树是一种自平衡二叉查找树,它的查找、插入、删除等操作的时间复杂度都是 O(log n)。
4. 扩容:当 HashMap 中的元素个数超过数组长度的 75% 时,HashMap 会进行扩容操作,即将数组长度扩大一倍,并重新计算每个元素在新数组中的位置。扩容操作会导致所有元素的位置发生变化,因此需要重新计算每个元素在新数组中的位置,这个过程比较耗时。
5. hash 函数:HashMap 会使用键对象的 hashCode() 方法计算出键的哈希值,然后根据哈希值计算出键值对在数组中的位置。
6. 线程安全:JDK 1.8 中的 HashMap 是线程不安全的,如果多个线程同时对 HashMap 进行写操作,可能会导致数据丢失或者出现死循环等问题。如果需要在多线程环境下使用 HashMap,可以使用 ConcurrentHashMap。





![[数据集][目标检测]电力场景输电线防震锤检测数据集VOC+YOLO格式2721张2类别](https://i-blog.csdnimg.cn/direct/bb555640fe714d93a133bcd0691ba618.png)






![[Algorithm][综合训练][mari和shiny][重排字符串]详细讲解](https://i-blog.csdnimg.cn/direct/60cd7ee1af62427d9021ebc1d38830c9.png)
![[项目]-通讯录的实现](https://i-blog.csdnimg.cn/direct/c9ef44cc6aa2417d9f8be57bfd73e5cd.png)