文章目录
- 134.加油站
- 思路
- 小结
- 135.分发糖果
- 思路
- 拓展——环形分糖
- 小结
- 860.柠檬水找零
- 思路
- 406.根据身高重建队列
- 思路
- 小结
今天是贪心算法专题第三天,直接上题目
134.加油站
建议:本题有点难度,不太好想,推荐大家熟悉一下方法二
题目链接:134. 加油站 - 力扣(LeetCode)
思路
这是我学校算法设计与分析课程的期末题,这道题目比较难
暴力解法不能通过最后一个测试,这里我们只研究贪心解法
- 如果总油量减去总消耗大于等于0,即各个站点的加油站 剩油量rest[i]≥0,那么一定可以跑完这一圈
- 如果当前站点的rest[i] < 0,那么这个站点一定不是start,则选择下一个站点作为起始位置,继续判断
- 将连续的多个站点等效地看成一个站点,如果其累积剩油量 < 0,则跳过,选择下一个站点作为起始位置,继续判断
对第3条的解释:
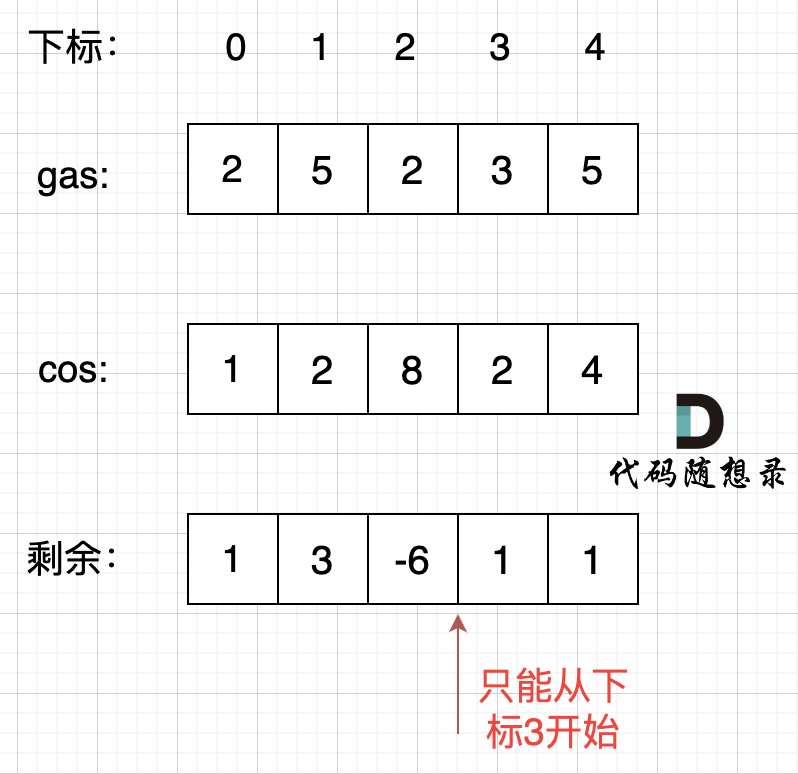
设start为当前的起始位置,i从start开始累加rest[i](start初始为0),和记为curSum,一旦curSum < 0,说明[start, i]区间都不能作为起始位置,因为在这个区间中选择任意一个位置作为起点,到站点i都会断油,那么起始位置就应该从i + 1算起,再从0计算curSum,即start = i + 1; curSum = 0;
如图所示:
-
证明:若[start, i]区间和为负数,则[start, i]区间内的任意一点都不能作为起始位置,否则从该点到站点i,curSum都小于0
取区间内一点a,将[start, i]分为两个子区间——区间1 和 区间2,如果curSum < 0,说明 区间1的和 + 区间2的和 < 0,假设从点a开始计数curSum不小于0,即区间2的和 ≥ 0
区间1的和 + 区间2的和 < 0,而区间2的和 ≥ 0,只能有区间1的和 < 0,即[start, a]的区间和 curSum < 0。[start, i-1]区间和始终为正数(我们在每个站点处都检测curSum是否大于0,只有某个站点的curSum < 0时,我们才更新start,因此[start, i-1]区间和始终为正数),与[start, a]的区间和 curSum < 0矛盾,故 点a不能作为起始位置
那么局部最优:当前累加rest[i]的和curSum一旦小于0,起始位置至少要是i+1,因为从i之前开始一定不行。全局最优:找到可以跑一圈的起始位置
这里的“局部最优”是对于当前区间[start, i]而言的,如果[start, i]的curSum < 0,则起始位置至少为i + 1,“全局最优”可以看为对于整个区间[0, N]而言的,如果[0, N]的totalSum < 0,则不能跑完一整圈。最终我们找到的起始位置start有这样的性质:[0, start]的curSum1 < 0,[start, N]的curSum2 > 0。由于totalSum > 0,因此curSum2 + curSum1 > 0,即[start, N]的剩余油量 足够 [0, start]的消耗量,从start能够跑完一整圈
代码如下:
// 贪心解法
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
int curSum = 0;
int totalSum = 0;
int start = 0;
for(int i=0; i<gas.size(); ++i)
{
curSum += gas[i] - cost[i];
totalSum += gas[i] - cost[i];
if(curSum < 0)
{
start = i + 1; // 当前累加的rest[i]和 curSum小于0,则说明[0, i]之间不会出现起始点,因此更新start为 i + 1
curSum = 0; // 重新开始计数
}
}
if(totalSum < 0) return -1;
return start;
}
};
Q:start = i + 1,会不会有这样的情况:当 i 为 gas.size() - 1 时,curSum < 0,导致start 为 gas.size(),出现错误?
A:不会,如果[start, N]的curSum < 0,又有[0, start]的curSum < 0,则totalSum < 0,此时返回-1,而不返回start,不会造成错误
小结
这是一道比较难的题目,关键是要想到如果整个区间的totalSum < 0,则不会走完一整圈(全局),由此可以想到 对于部分区间[start, i]的curSum,如果curSum < 0,则区间[start, i]中的任意一点都不可能为起始位置,起始位置至少是 i + 1,否则 从区间内任意一个点 到 站点i,都有curSum < 0(局部),这里体现了贪心的”局部最优“ 和 ”全局最优”
也可以这么想:对于一个站点i,如果它的rest[i] < 0,则站点i不能作为起始位置。接下来将连续的站点视为一个站点,将这些站点的累积剩余量 视为 这一个站点的rest[i],如果这些站点的累积剩余量 < 0,则相当于 这一个站点的rest[i] < 0,那么这些站点都不能作为起始位置
135.分发糖果
建议:本题涉及到一个思想,就是想处理好一边再处理另一边,不要两边想着一起兼顾,后面还会有题目用到这个思路
题目链接:135. 分发糖果 - 力扣(LeetCode)
思路
这种需要考虑两边(既要和左孩子比较,又要和右孩子比较)的题目,需要先确定一边(只与左孩子比较),再确定另一边(只与右孩子比较),两边同时考虑会很乱,我们以ratings为[1,2,2,5,4,3,2]为例,初始时,candyVec每个元素都初始化为1,满足每个孩子都至少有一个糖果
-
首先考虑 当前孩子 与 左孩子比较,我们关注 当前孩子评分 大于 左孩子的情况
从前向后遍历,只要当前孩子评分比其左孩子大,当前孩子就比左孩子多得一个糖果(局部最优),这样,相邻的孩子中,所有比左孩子评分高的孩子都能获得 比左孩子更多的糖果(全局最优),代码如下:
for(int i=1; i<rating.size(); ++i) { if(ratings[i] > ratings[i-1]) { candyVec[i] = candyVec[i-1] + 1; } }举例说明:
- ratings : [1,2,2,5,4,3,2]
- candyVec : [1,2,1,2,1,1,1]
-
然后考虑 当前孩子 与 右孩子比较,我们关注 当前孩子评分 大于 右孩子的情况
从后向前遍历,只要当前孩子评分比其右孩子大,当前孩子的糖果数candyVec[i] 就至少为 右孩子糖果数+1,即candyVec[i+1] + 1
如果 ratings[i] > ratings[i + 1],此时candyVec[i](第i个小孩的糖果数量)就有两个选择了,一个是candyVec[i + 1] + 1(从右边这个加1得到的糖果数量),一个是candyVec[i](之前比较 当前孩子与左孩子得到的糖果数量)
注意,还要同时满足当前孩子 与 左孩子比较的情况。对于第一次遍历后的数组candyVec,它实现了:若当前孩子评分 比其左孩子大,则当前孩子的糖果数candyVec[i] 至少为 candyVec[i-1]+1。我们要同时满足当前孩子 与 左右孩子比较的情况,就要让candyVec[i]取到candyVec[i+1] + 1 和 candyVec[i] 中最大的值,candyVec[i]只有取最大的才能既保持对左边candyVec[i - 1]的糖果多,也比右边candyVec[i + 1]的糖果多
这里使用的贪心:
- 局部最优:取candyVec[i + 1] + 1 和 candyVec[i] 最大的糖果数量,保证第i个小孩的糖果数量既大于左边的也大于右边的
- 全局最优:相邻的孩子中,评分高的孩子获得更多的糖果。
代码如下:
// 从后向前 for (int i = ratings.size() - 2; i >= 0; i--) { if (ratings[i] > ratings[i + 1] ) { candyVec[i] = max(candyVec[i], candyVec[i + 1] + 1); } }举例说明:
- ratings : [1,2,2,5,4,3,2]
- candyVec : [1,2,1,2,1,1,1] (第一次遍历,与左孩子比较后的结果)
- candyVec : [1,2,1,4,3,2,1] (第二次遍历,与右孩子比较后的结果)
Q:为什么在比较 当前孩子评分 与 右孩子时,要从后向前遍历?从前向后遍历呢?
A:这是为了每次与右孩子比较时,能利用上最新的比较结果,比如rating[5]与rating[4]的比较 需要利用上 rating[5]与rating[6]的比较结果;如果从前向后遍历,rating[5]与rating[4]的比较 就不能用上 rating[5]与rating[6]的比较结果了
举例说明:
- ratings : [1,2,2,5,4,3,2]
- candyVec : [1,2,1,2,1,1,1] (第一次遍历,与左孩子比较后的结果)
如果从前向后遍历,则比较rating[3] 与 rating[4]后,candyVec : [1,2,1,2,1,1,1]( candyVec[3] = max(candyVec[3], candyVec[4]+1) )
接下来比较rating[4] 与 rating[5],candyVec : [1,2,1,2,2,1,1]
然后 比较rating[5] 与 rating[6],candyVec : [1,2,1,2,2,2,1]
最后 比较rating[5] 与 rating[6],candyVec : [1,2,1,2,2,2,2]
发现最后的结果是错误的,这是因为rating[i] 与 rating[i+1]比较后,将rating[i] 更新为 max(rating[i], rating[i+1] + 1),而rating[i+1]在后续的比较中又被修改了,rating[i]是基于旧值修改的,而不是rating[i+1]被修改后的新值,因此出错
代码实现:
class Solution {
public:
int candy(vector<int>& ratings) {
vector<int> candyVec(ratings.size(), 1); // 初始化所有元素为1,保证每个孩子至少有一个糖
// 首先比较当前孩子与左孩子
for(int i=1; i<ratings.size(); ++i)
{
if(ratings[i] > ratings[i-1])
{
candyVec[i] = candyVec[i-1] + 1; // 如果当前孩子 > 左孩子,则当前孩子糖果数 = 左孩子糖果数 + 1
}
}
// 接下来比较当前孩子与右孩子
for(int i=ratings.size()-2; i >= 0; --i)
{
if(ratings[i] > ratings[i+1])
{
candyVec[i] = max(candyVec[i], candyVec[i+1] + 1); // 如果当前孩子 > 右孩子,则让candyVec[i]取到candyVec[i+1] + 1 和 candyVec[i] 中最大的值
}
}
int result = 0;
for(int num : candyVec)
{
result += num;
}
return result;
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(n)
拓展——环形分糖
如果小朋友围成了一个环,其它条件不变,该怎么做?
只在数组前后分别添加末尾元素 和 首元素,再进行两次遍历,这样可以吗?
不可以,以4,2,3为例,可能出现这样的情况:当前孩子与左孩子比较时:
- rating : [3,4,2,3,4]
- candyVec : [1,2,1,2,2]
可以发现
末尾元素3的candyVec修改为2,而ratin[0]对应的candyVec[0]为2,这就犯了上面解释过的错误:用旧值修改candyVec[i],而没有用新值,所以添加首尾元素后,只用两次遍历是不可以的
用两种思路:
-
将rating数组复制三份后拼接起来,用两次遍历(从前向后 和 从后向前),取中间部分的candyVec,即为最后结果
-
在原rating数组上操作,但是遍历次数要增多,每轮循环都分别进行两次遍历,若首尾元素的candyVec有变化,就要更新candyVec[0] 和 candyVec[N], candyVec[0] = candyVec[N-1];candyVec[N] = candyVec[1],继续遍历,直至首尾元素的candyVec都没有变化,循环结束
以[4,2,3]为例,在数组前后增加末尾 和 起始元素:[3,4,2,3,4]
-
第一次循环:
- rating: [3,4,2,3,4]
- candyVec: [1,2,1,2,3](与左孩子比较)
- candyVec: [1,2,1,2,3] (与右孩子比较)
可以看到,首尾元素的candyVec发生了变化,需要更新candyVec[0]和candyVec[N]
-
第二次循环:
- rating: [3,4,2,3,4]
- candyVec: [2,2,1,2,2](更新后)
- candyVec: [2,3,1,2,3](与左孩子比较)
- candyVec: [2,3,1,2,3] (与右孩子比较)
首元素的candyVec发生了变化,需要继续循环
-
第三次循环:
- rating: [3,4,2,3,4]
- candyVec: [2,3,1,2,3](更新后)
- candyVec: [2,3,1,2,3](与左孩子比较)
- candyVec: [2,3,1,2,3] (与右孩子比较)
首尾元素的candyVec都没有变化,结束循环
最终结果为[3,1,2]
-
小结
这是一道比较困难的题目,关键是理解这个思想:对于要处理两边的问题,应该先处理好一边,然后再处理另一边,两边同时考虑会很乱
环形分糖问题需要考虑如何处理环形结构,这也是一道面试题目,如果要在原数组上操作,就要循环多次,更新开头的candyVec[0] 和 末尾的candyVec[N],避免出现 用candyVec[0] 或 candyVec[N]的旧值 修改 candyVec[i] 的情况
860.柠檬水找零
建议:本题看上好像挺难,其实很简单,大家先尝试自己做一做
题目链接:860. 柠檬水找零 - 力扣(LeetCode)
思路
只有三种情况:
- 支付5美元,直接收下,增加一张5美元
- 支付10美元,则消耗一张5美元,增加一张10美元
- 支付20美元,则有两种组合:
- 消耗一张10美元+一张5美元
- 消耗三张5美元
前两种情况都是固定策略,只有第三种情况有两种组合策略,这需要我们判断哪种组合策略是优先的,在代码中就是if 和 else if的条件的顺序问题
这里用到了贪心的策略:我们尽可能使用大面额进行找零,保留小面额纸币,10美元只能给账单20找零,而5美元可以给10美元和20美元找零,5美元应用的更广
所以局部最优:遇到账单20,优先消耗美元10,完成本次找零。全局最优:完成全部账单的找零
代码如下:
class Solution {
public:
bool lemonadeChange(vector<int>& bills) {
int five = 0, ten = 0, twenty = 0;
for (int bill : bills) {
// 情况一
if (bill == 5) five++;
// 情况二
if (bill == 10) {
if (five <= 0) return false;
ten++;
five--;
}
// 情况三
if (bill == 20) {
// 优先消耗10美元,因为5美元的找零用处更大,能多留着就多留着
if (five > 0 && ten > 0) {
five--;
ten--;
twenty++; // 其实这行代码可以删了,因为记录20已经没有意义了,不会用20来找零
} else if (five >= 3) {
five -= 3;
twenty++; // 同理,这行代码也可以删了
} else return false;
}
}
return true;
}
};
这道题目可以告诉大家,遇到感觉没有思路的题目,可以静下心来把能遇到的情况分析一下,只要分析到具体情况了,一下子就豁然开朗了。如果一直陷入想从整体上寻找找零方案,就会把自己陷进去,各种情况一交叉,只会越想越复杂了——Carl
406.根据身高重建队列
建议:本题有点难度,和分发糖果类似,不要两头兼顾,处理好一边再处理另一边
题目链接:406. 根据身高重建队列 - 力扣(LeetCode)
思路
这道题的第一个难点在于看懂题目,你可以将这个问题想象为体育课排队问题,第一节课老师让同学们记住队伍前面有几个比自己高的,这就是题目给的people数组,但它是无序的,people[i] 并不对应队列中第i个人的h和k。在上第二节课的时候,我们需要用people数组还原正确的队列que,que[i]对应队列中第i个人的h和k
第二个难点在于如何利用people恢复队列。这道题与 135.分发糖果 类似,如果要同时处理两个维度,要先确定一个维度,再确定另一个维度,这道题目中有两个维度:h和k,关键在于先处理哪个维度
- 如果按照k来从小到大排序,排完之后,会发现k的排列并不符合条件,身高也不符合条件,两个维度哪一个都没确定下来
- 那么按照身高h来排序呢,身高一定是从大到小排(身高相同的话则k小的站前面),让高个子在前面。此时我们可以确定一个维度了,就是身高,此时people按照身高降序排列
因此我们先按照身高h降序排列people
Q:为什么要按照降序排列身高呢?
A:只有先让身高高的先进入队伍,后面身高低的才能根据前面高的来找自己的位置,接下来举例说明:
引用6qishi的评论
按照身高降序排列后,people数组:
[[7,0],[7,1],[6,1],[5,0],[5,2],[4,4]]
每次让最高的学生出来找自己的位置,第一个高个子[7,0]自然站到了第一个位置:
[[7,0]]
而第二个高个子[7,1]知道有一个人大于等于自己的身高,站在了第一个人身后:
[[7,0],[7,1]]
第三个人[6,1]想了想,有一个人比自己高,那自己肯定站在第二位,于是就插队,现在也站到了第一个人身后:
[[7,0],[6,1],[7,1]]
第四个人[5,0]想了想,没人比自己高,那自己肯定站在第一位,于是就插队,站到了队头:
[[5,0],[7,0],[6,1],[7,1]]
第五个人[5,2]想了想,有两个人比自己高,于是就插队,站到了第二个人后面,也就是第三个位置:
[[5,0],[7,0],[5,2],[6,1],[7,1]]
第六个人[4,4]看了看眼前的队伍,比自己高的人都在里面,他安心的数着前面有四个人比自己高,心安理得的站到了第四个人身后:
[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
接下来处理维度k。身高低的人是不会对身高高的人的排序造成影响的,所以先把身高高的人排序好了以后,无论低身高的人怎么排都不会造成身高高的人的位置错误,所以只要每次把身高高的人先排序好,其相对位置就固定了,再将低身高的人插入就是正确的排列。因此,按照身高排序之后,优先按身高高的people的k来插入,后序插入节点也不会影响前面已经插入的节点,最终按照k的规则完成了队列
以[5,2]为例:

所以在按照身高从大到小排序后:
局部最优:优先按身高高的people的k来插入。插入操作过后的people满足队列属性
全局最优:最后都做完插入操作,整个队列满足题目队列属性
代码实现:
用链表插入效率高,因此使用链表作为que
class Solution {
public:
static bool cmp(const vector<int>& a, const vector<int>& b)
{
if(a[0] == b[0]) return a[1] < b[1]; // 身高相同,k大的在后面
return a[0] > b[0]; // 身高大的排在前面
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort(people.begin(), people.end(), cmp); // 先处理维度h
list<vector<int>> result;
for(int i=0; i<people.size(); ++i)
{
int pos = people[i][1]; // 再考虑维度k
auto it = result.begin();
advance(it, pos);
result.insert(it, people[i]);
}
return vector<vector<int>>(result.begin(), result.end());
}
};
- 时间复杂度:O(nlog n + n^2)
- 空间复杂度:O(n)
小结
对于两个维度一起考虑的问题,其技巧是确定一边然后贪心另一边,两边一起考虑,就会顾此失彼。优先处理哪个维度,要看处理这个维度后,结果是否确定了这个维度。在这道题目中,如果优先处理k,按照k进行排序,会发现排序后的people不符合k的规则——第i个同学前面有ki个 大于等于其身高的人,没有确定维度k,因此不能优先处理k。如果优先处理h,按照h进行排序,排序后的people确实按照身高降序排列,这确定了维度h,因此要先处理维度h








![[Linux#46][线程->网络] 单例模式 | 饿汉与懒汉 | 自旋锁 |读写锁 | 网络基础 | 书单](https://img-blog.csdnimg.cn/img_convert/6d2a26fcdeb936598828a0578de6306a.png)