揭秘高效存储模型与数据结构底层实现
- 【专栏简介】
- 【技术大纲】
- 【专栏目标】
- 【目标人群】
- 1. Redis爱好者与社区成员
- 2. 后端开发和系统架构师
- 3. 计算机专业的本科生及研究生
- 压缩列表(ziplist)
- 压缩列表使用目的
- 压缩列表结构组成
- 压缩列表的各个组成部分
- 三个节点压缩列表的属性分析案例
- 节点元素长度
- 字节数组长度大小
- 整数数值的大小范围
- 节点元素组成
- previous_entry_length
- 1字节的表示
- 5字节的表示
- encoding
- 字节数组编码
- content
- 保存一个‘hello world’压缩列表
- 保存一个10086压缩列表
- 最后压缩列表总给
【专栏简介】
随着数据需求的迅猛增长,持久化和数据查询技术的重要性日益凸显。关系型数据库已不再是唯一选择,数据的处理方式正变得日益多样化。在众多新兴的解决方案与工具中,Redis凭借其独特的优势脱颖而出。
【技术大纲】
为何Redis备受瞩目?原因在于其学习曲线平缓,短时间内便能对Redis有初步了解。同时,Redis在处理特定问题时展现出卓越的通用性,专注于其擅长的领域。深入了解Redis后,您将能够明确哪些任务适合由Redis承担,哪些则不适宜。这一经验对开发人员来说是一笔宝贵的财富。

在这个专栏中,我们将专注于Redis的6.2版本进行深入分析和介绍。Redis 6.2不仅是我个人特别偏爱的一个版本,而且在实际应用中也被广泛认为是稳定性和性能表现都相当出色的版本。
【专栏目标】
本专栏深入浅出地传授Redis的基础知识,旨在助力读者掌握其核心概念与技能。深入剖析了Redis的大多数功能以及全部多机功能的实现原理,详细展示了这些功能的核心数据结构和关键算法思想。读者将能够快速且有效地理解Redis的内部构造和运作机制,这些知识将助力读者更好地运用Redis,提升其使用效率。
将聚焦于Redis的五大数据结构,深入剖析各种数据建模方法,并分享关键的管理细节与调试技巧。
【目标人群】
Redis技术进阶之路专栏:目标人群与受众对象,对于希望深入了解Redis实现原理底层细节的人群。
1. Redis爱好者与社区成员
Redis技术有浓厚兴趣,经常参与社区讨论,希望深入研究Redis内部机制、性能优化和扩展性的读者。
2. 后端开发和系统架构师
在日常工作中经常使用Redis作为数据存储和缓存工具,他们在项目中需要利用Redis进行数据存储、缓存、消息队列等操作时,此专栏将为他们提供有力的技术支撑。
3. 计算机专业的本科生及研究生
对于学习计算机科学、软件工程、数据分析等相关专业的在校学生,以及对Redis技术感兴趣的教育工作者,此专栏可以作为他们的学习资料和教学参考。
无论是初学者还是资深专家,无论是从业者还是学生,只要对Redis技术感兴趣并希望深入了解其原理和实践,都是此专栏的目标人群和受众对象。
让我们携手踏上学习Redis的旅程,探索其无尽的可能性!
压缩列表(ziplist)
压缩列表(Ziplist)是Redis中用于实现列表键(list keys)和哈希键(hash keys)等数据结构的一种高效内存表示形式。当列表键包含的元素数量较少,且每个元素要么是小型整数值,要么是长度较短的字符串时,Redis会选择使用压缩列表作为其底层实现,从而能够提供出色的性能和内存效率。
例如,执行如LPUSH mylist "element1"这样的命令来向mylist这个列表键添加元素,且后续的操作也表明这个列表将保持小巧和紧凑,Redis可能会选择使用压缩列表来存储这个列表键。
redis> RPUSH mylist "element1"
(integer) 1
redis> OBJECT ENCODING mylist
"ziplist"
从上面可以看出来,我们使用OBJECT ENCODING mylist 指令查看到对应的对象类型属于ziplist类型,可以理解为当涉及到列表键的数据存储时,主要采用以下两种方式进行切换为ziplist类型:
- 较小的元素空间(列表):当列表内部主要包含的是诸如小整数值,以及短字符串的时候,便会压缩列表(Ziplist)来作为这些列表键的底层实现。
- 较少的元素数量(哈希):当哈希键只包含少量键值对,且每个键值对的键和值要么就是小整数值,要么就是长度比较短的字符串,Redis就会使用压缩列表来做哈希键的底层实现。
压缩列表使用目的
压缩列表的背后的原因是能够以更紧凑的方式存储数据,从而减少内存占用。它通过将多个元素连续存储在一个内存块中,并使用一种特殊的编码方案来存储每个元素及其长度,从而实现了高效的内存利用,后面我会对此进行先关的详细介绍。
压缩列表结构组成
压缩列表是Redis为了优化内存使用而精心设计的,它是一种顺序型数据结构,由一系列经过特殊编码的连续内存块构成。在压缩列表中,可以灵活地存储多个节点(entry),每个节点既可以保存一个字节数组,也可以保存一个整数值,如下图所示。
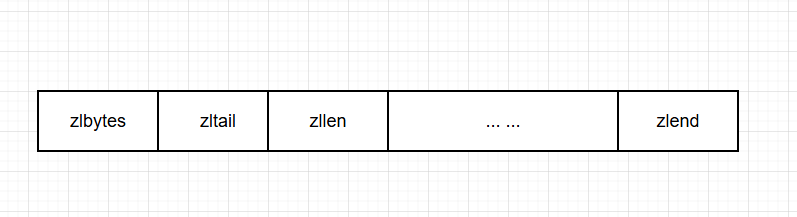
压缩列表的各个组成部分
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 记录整个压缩列表占用的内存字节数,用于在对压缩列表进行内存重分配或计算zlend的位置时使用 |
| zltail | uint32_t | 4字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,程序无须遍历整个压缩列表就可以确定表尾节点的地址 |
| zllen | uint16_t | 2字节 | 记录压缩列表包含的节点数量。当值小于UINT16MAX(65535)时,直接表示节点数量;当值等于UINT16MAX时,需要遍历整个压缩列表才能计算得出真实节点数量 |
| 元素 | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定 |
| zlend | uint8_t | 1字节 | 特殊值0xEF(十进制255),用于标记压缩列表的末端 |
三个节点压缩列表的属性分析案例

-
压缩列表的
zlbytes属性值设置为0x50(即十进制80),这明确标识了整个压缩列表的总长度为80字节。 -
zltail属性的值为0x3C(即十进制60),这代表了一个偏移量。当我们拥有一个指向压缩列表起始地址的指针P时,只需将指针P加上这个偏移量60,就可以精确地定位到压缩列表的表尾节点(第三个元素)的内存地址。这一机制显著提升了数据访问的效率。 -
zllen属性的值为0x3(即十进制3),直观地展示了压缩列表内包含三个节点。这种直接计数的方式在节点数量较少时,提供了高效的节点数量查询。
节点元素长度
每个压缩列表的节点具备灵活性,能够存储不同类型的数据,包括字节数组和整数值。特别地,对于字节数组,它支持三种不同的长度规格,以满足不同的数据存储需求。
字节数组长度大小
-
小型数据:较短的字节数组,其长度可以达到63字节(即2的6次方减1),适用于存储小型数据片段。
-
中型数据:中等长度的字节数组,其长度可以达到16383字节(即2的14次方减1),适用于存储一些中等规模的数据。
-
大型数据:当需要存储大量数据时,字节数组的长度可以扩展到惊人的4294967295字节(即2的32次方减1),长度足以满足大多数大型数据存储需求。
整数数值的大小范围
-
4位无符号整数:取值范围在0至12之间的微型数值,占用4位(半个字节)存储空间,适用于表示非常小的数值范围。
-
1字节有符号整数:占用1字节(8位)的存储空间,支持有符号(正数和负数)表示,适用于表示较小的整数范围。
-
3字节有符号整数:占用3字节(24位)的存储空间,同样支持有符号表示,能够处理更大范围的整数。
-
int16t类型整数:标准的16位有符号整数类型,通常用于需要更大数值范围但又不希望占用过多内存的场景。
-
int32t类型整数:32位有符号整数类型,它提供了广泛的数值范围,是许多应用程序和系统中常用的整数类型。
-
int64t类型整数:64位有符号整数类型,具有极其庞大的数值范围,适用于需要处理超大数据集或高精度计算的场景。
节点元素组成
每个压缩列表节点均精心构建,包含三个核心组成部分:previous_entry_length、encoding以及content。接下来,我们将对这三个组成部分进行详细的解析与介绍。
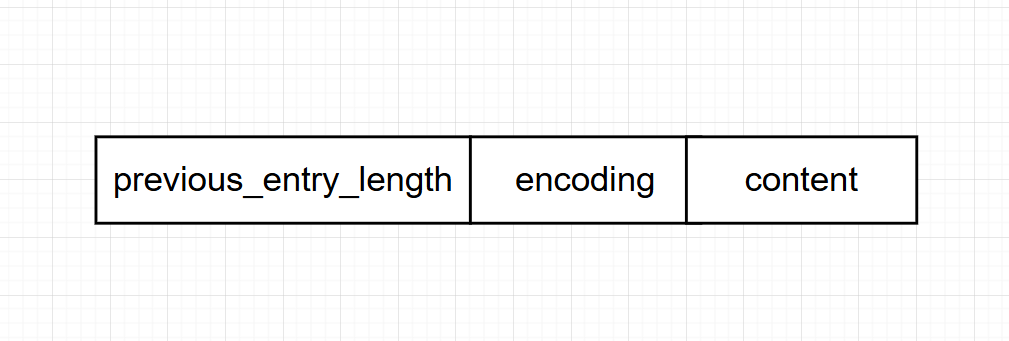
previous_entry_length
节点的previous_entry_length属性是用于记录压缩列表中前一个节点长度的关键字段,其计量单位为字节。这一属性的长度设计得十分巧妙,能够根据实际需要灵活地选择1字节或5字节的长度。
1字节的表示
若previous_entry_length属性仅占用一字节,并且其值为0x05,这意味着前一个节点的长度恰好为5字节。这一设计使得我们能够迅速了解前一节点的尺寸,进而高效地进行数据定位和操作。
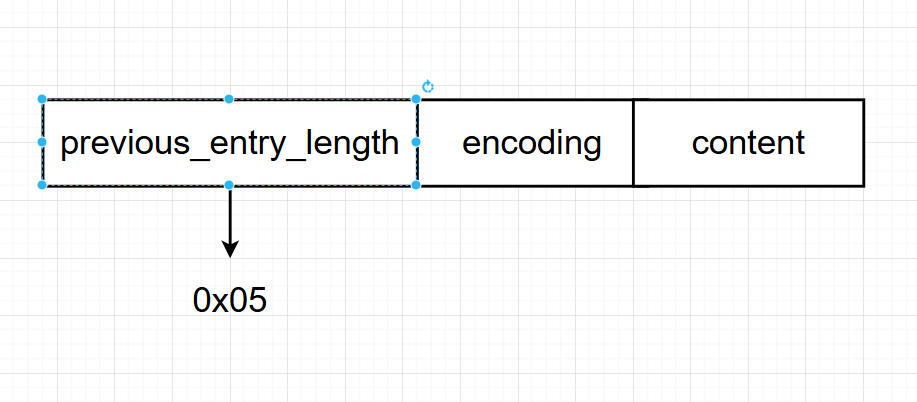
当压缩列表中前一节点的长度小于或等于254字节时,previous_entry_length属性会采用1字节的编码方式,以高效存储这一长度信息。这种设计确保了数据的紧凑性,同时简化了对前一节点长度的快速访问。
5字节的表示
当压缩列表中前一节点的长超过254字节时,previous_entry_length属性将扩展至5字节的编码方式。具体而言,属性的首字节会被特别设置为0xE(即十进制值254),作为长度编码的标识,而紧随其后的四个字节则用于精确存储前一节点的实际长度。
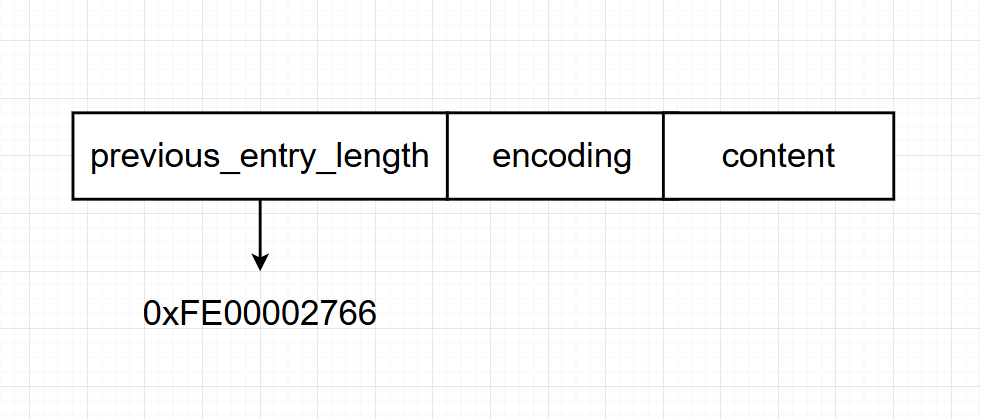
若previous_entry_length属性占据五字节的长度,并且其值为0xFE00002766,则该值的设计体现了精巧的编码策略。其中,最高位字节0xFE(即十进制254)作为特殊标记,指明这是一个五字节长度的previous_entry_length属性。而紧随其后的四个字节0x00002766则直接表示了前一节点的实际长度,十进制为10086。
encoding
节点的encoding属性扮演着关键角色,它详细记录了content属性所存储数据的类型以及具体长度,为数据的解析和访问提供了重要依据。
字节数组编码
字节数组编码具有一字节、两字节或五字节的长度,并且其值的最高位为00、01或10,这种编码方式表明节点的content属性中存储的是字节数组。数组的具体长度由编码中除去最高两位后的其余位来记录。
| 编码 | 编码长度 | content属性保存的值 |
|---|---|---|
| 00bbbbbb | 1字节 | 长度小于等于63字节的字节数组 |
| 01bbbbbb | 2字节 | 长度小于等于16383字节的字节数组(此处用X代替具体值) |
| 10aaaaaaaa | 5字节 | 长度小于等于4294967295的字节数组(类型信息未详细展示) |
| cccccccc dddddddd(这部分通常不是编码的一部分,可能是整数值的额外字节) |
对于整数编码,其长度为一个字节,且以11作为值的最高位起始。这种特定的编码方式指示了节点的content属性中存储的是整数值。
| 编码 | 编码长度 | content属性保存的值或描述 |
|---|---|---|
| 11000000 | 1字节 | int16_t类型的整数 |
| 11010000 | 1字节 | int32_t类型的整数(请注意,原始中的“int32七”应为“int32_t”) |
| 11100000 | 1字节 | int64_t类型的整数(同样地,“int64_t”应为“int64_t”) |
| 11110000 | 1字节 | 24位有符号整数 |
| 11111110 | 1字节 | 8位有符号整数 |
| 1111xxxx | 1字节 | 使用这一编码的节点没有content属性,编码本身的xxxx四位已保存一个0-12之间的值 |
content
节点的content属性是其核心存储单元,负责承载节点的实际值。这些值既可以是字节数组形式的数据,也可以是整数类型。为了明确标识这些值的类型和所占用的空间长度。
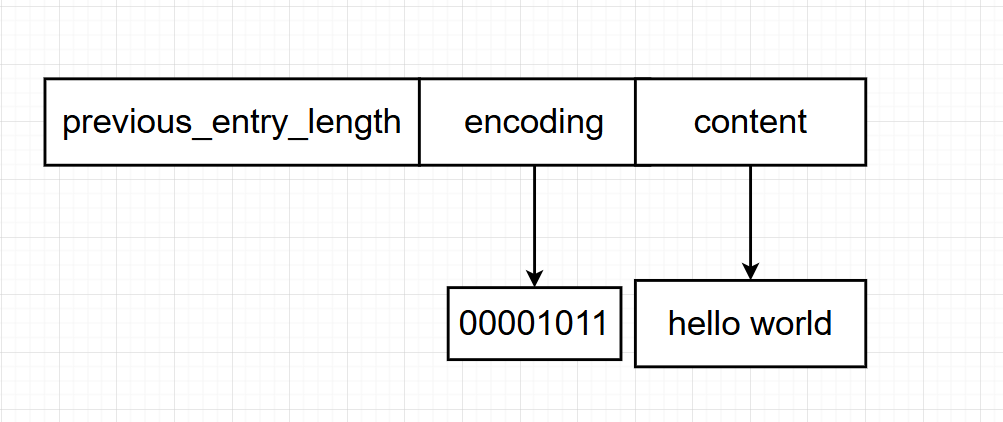
保存一个‘hello world’压缩列表
编码的前两位标识为00时,意味着该节点存储的是一个字节数组。紧接着的六位编码001011则详细记录了该字节数组的长度为11(即十进制的11个字节),而节点的content属性则承载着具体的字节数组数据,即"helloworld"。
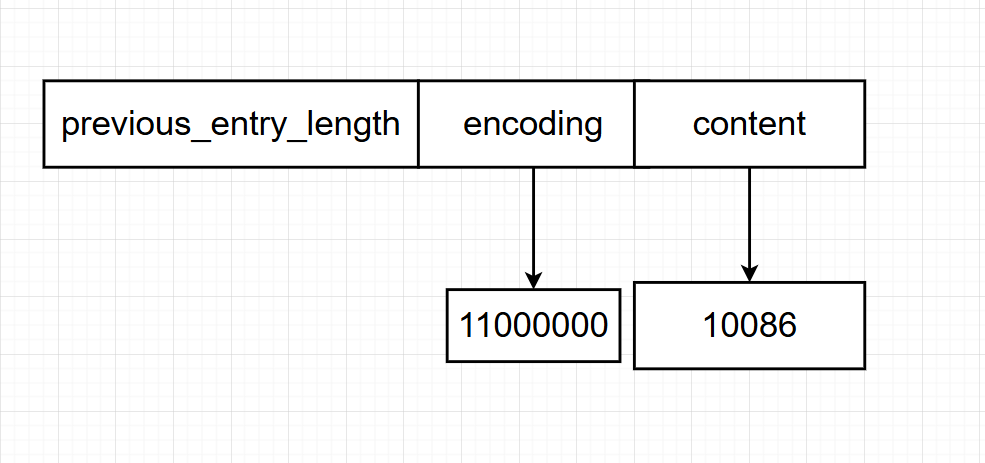
保存一个10086压缩列表
编码11000000明确指示节点存储的是一个int16_t类型的整数值,节点的content属性负责保存这个整数的具体值,即10086。
最后压缩列表总给
压缩列表是一种专为内存优化而设计的顺序数据结构,旨在通过紧凑的存储方式降低内存占用。它被广泛用作列表键和哈希键的底层实现机制之一,为高效数据处理提供了坚实的基础。
压缩列表具备容纳多个节点的能力,每个节点都可以灵活地存储字节数组或整数值,满足了多样化的数据存储需求。尽管在添加新节点到压缩列表或从中删除节点时,可能会触发一系列的连锁更新操作以维护数据的连续性和结构的完整性,但这种情况在实际应用中并不常见,因此不会显著影响压缩列表的整体性能。