目录
一、用法精讲
401、pandas.Series.to_string方法
401-1、语法
401-2、参数
401-3、功能
401-4、返回值
401-5、说明
401-6、用法
401-6-1、数据准备
401-6-2、代码示例
401-6-3、结果输出
402、pandas.Series.to_clipboard方法
402-1、语法
402-2、参数
402-3、功能
402-4、返回值
402-5、说明
402-6、用法
402-6-1、数据准备
402-6-2、代码示例
402-6-3、结果输出
403、pandas.Series.to_latex方法
403-1、语法
403-2、参数
403-3、功能
403-4、返回值
403-5、说明
403-6、用法
403-6-1、数据准备
403-6-2、代码示例
403-6-3、结果输出
404、pandas.Series.to_markdown方法
404-1、语法
404-2、参数
404-3、功能
404-4、返回值
404-5、说明
404-6、用法
404-6-1、数据准备
404-6-2、代码示例
404-6-3、结果输出
405、pandas.DataFrame类
405-1、语法
405-2、参数
405-3、功能
405-4、返回值
405-5、说明
405-6、用法
405-6-1、数据准备
405-6-2、代码示例
405-6-3、结果输出
二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页



一、用法精讲
401、pandas.Series.to_string方法
401-1、语法
# 401、pandas.Series.to_string方法
pandas.Series.to_string(buf=None, na_rep='NaN', float_format=None, header=True, index=True, length=False, dtype=False, name=False, max_rows=None, min_rows=None)
Render a string representation of the Series.
Parameters:
buf
StringIO-like, optional
Buffer to write to.
na_rep
str, optional
String representation of NaN to use, default ‘NaN’.
float_format
one-parameter function, optional
Formatter function to apply to columns’ elements if they are floats, default None.
header
bool, default True
Add the Series header (index name).
index
bool, optional
Add index (row) labels, default True.
length
bool, default False
Add the Series length.
dtype
bool, default False
Add the Series dtype.
name
bool, default False
Add the Series name if not None.
max_rows
int, optional
Maximum number of rows to show before truncating. If None, show all.
min_rows
int, optional
The number of rows to display in a truncated repr (when number of rows is above max_rows).
Returns:
str or None
String representation of Series if buf=None, otherwise None.401-2、参数
401-2-1、buf(可选,默认值为None):优先接收一个字符串缓冲区,若未提供,则返回字符串;如果提供了缓冲区,则方法将结果写入该缓冲区,而不是返回结果。
401-2-2、na_rep(可选,默认值为'NaN'):用于表示缺失值的字符串,默认是'NaN',如果Series中含有缺失值(NaN),则可以使用此参数来定义替代显示字符串。
401-2-3、float_format(可选,默认值为None):用于格式化浮点数的字符串,可以指定一个函数,用于处理浮点数的输出格式,例如lambda x:'%.2f' % x。
401-2-4、header(可选,默认值为True):布尔值,指示是否在输出中包含Series的名称,如果Series有名称,则在输出中打印。
401-2-5、index(可选,默认值为True):布尔值,指示是否在输出中包含索引列。
401-2-6、length(可选,默认值为False):布尔值,指示是否输出Series的长度。
401-2-7、dtype(可选,默认值为False):布尔值,指示是否在输出中包含数据类型信息。
401-2-8、name(可选,默认值为False):布尔值,指示是否在输出中包含Series的名称。
401-2-9、max_rows(可选,默认值为None):整数,用于指定显示的最大行数,如果Series的行数超过此值,则将以省略号表示。
401-2-10、min_rows(可选,默认值为None):整数,用于指定显示的最小行数,即使Series的行数少于此值,仍然会显示。
401-3、功能
以用户定义的方式格式化和显示Series对象,通过调整参数,用户可以自定义显示的内容和格式,从而使其更适合特定的输出需求。
401-4、返回值
当buf参数为None时,此方法返回一个字符串,表示格式化后的Series内容;当提供了buf参数时,结果将被写入该缓冲区,方法本身返回None。
401-5、说明
使用场景:
401-5-1、数据审查:在数据清洗和预处理时,通常需要快速查看数据的摘要信息,使用该方法可以清晰地输出Series的内容,方便发现潜在的问题,如缺失值或异常值。
401-5-2、报告生成:在生成数据分析报告时,可以将数据以美观的格式输出,该方法允许自定义缺失值的表示和浮点数的格式,从而帮助提升报告的可读性。
401-5-3、日志记录:在数据处理过程中,可能需要将Series的状态记录到日志中,利用该方法可以快速构建记录信息,方便后续的审计和追踪。
401-5-4、数据检查和调试:在编写复杂的数据处理代码时,快速显示Series的内容有助于调试,通过控制输出的行数和格式,可以专注于问题所在。
401-5-5、输出到文件:当需要将结果输出到文件时,可以利用该方法将Series格式化后写入到文本文件中,以便后续处理或查看。
401-6、用法
401-6-1、数据准备
无401-6-2、代码示例
# 401、pandas.Series.to_string方法
# 401-1、数据审查
import pandas as pd
# 创建示例数据
data = pd.Series([10, 20, None, 40, 50], name="Scores")
# 审查数据
print(data.to_string(na_rep='Missing'), end='\n\n')
# 401-2、报告生成
import pandas as pd
# 创建示例数据
data = pd.Series([1.2345, 2.3456, 3.4567], name="Measurements")
# 输出数据,以指定格式显示
output = data.to_string(float_format=lambda x: f"{x:.2f}")
print(output, end='\n\n')
# 401-3、日志记录
import pandas as pd
import logging
logging.basicConfig(level=logging.INFO)
data = pd.Series([5, None, 15], name="Transaction Values")
# 记录当前Series状态
logging.info("Current transaction values:\n%s", data.to_string(na_rep='N/A'))
# 401-4、数据检查和调试
import pandas as pd
# 创建一个大的 Series
large_data = pd.Series(range(100))
# 检查前几行数据
print(large_data.to_string(max_rows=10), end='\n\n')
# 401-5、输出到文件
data = pd.Series([100, 200, None, 400], name="Sales")
with open('output.txt', 'w') as f:
f.write(data.to_string(na_rep='Missing'))401-6-3、结果输出
# 401、pandas.Series.to_string方法
# 401-1、数据审查
# 0 10.0
# 1 20.0
# 2 Missing
# 3 40.0
# 4 50.0
# 401-2、报告生成
# 0 1.23
# 1 2.35
# 2 3.46
# 401-3、日志记录
# INFO:root:Current transaction values:
# 0 5.0
# 1 N/A
# 2 15.0
# 401-4、数据检查和调试
# 0 0
# 1 1
# 2 2
# 3 3
# 4 4
# ..
# 95 95
# 96 96
# 97 97
# 98 98
# 99 99
# 401-5、输出到文件
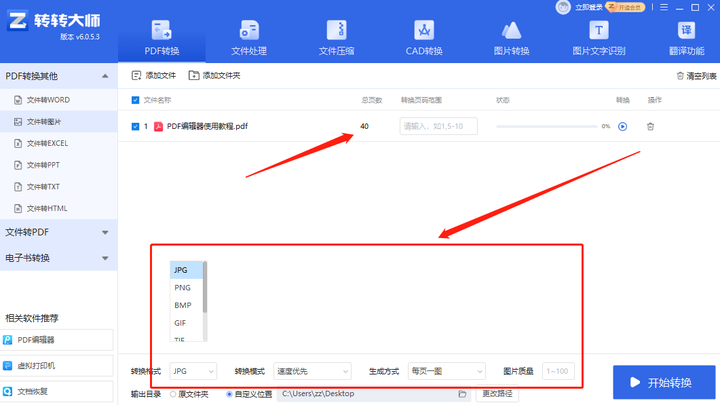
# 见图1图1:

402、pandas.Series.to_clipboard方法
402-1、语法
# 402、pandas.Series.to_clipboard方法
pandas.Series.to_clipboard(*, excel=True, sep=None, **kwargs)
Copy object to the system clipboard.
Write a text representation of object to the system clipboard. This can be pasted into Excel, for example.
Parameters:
excelbool, default True
Produce output in a csv format for easy pasting into excel.
True, use the provided separator for csv pasting.
False, write a string representation of the object to the clipboard.
sepstr, default '\t'
Field delimiter.
**kwargs
These parameters will be passed to DataFrame.to_csv.402-2、参数
402-2-1、excel(可选,默认值为True):布尔值,指定输出内容的格式,如果设置为True,则以 Excel 格式复制内容,这意味着将数据以制表符分隔;当设置为False,则输出的数据将以其他形式复制(例如纯文本),适用于纯文本编辑器。
402-2-2、sep(可选,默认值为None):字符串,指定分隔符,默认情况下,当excel=True时,使用制表符作为分隔符;如果您需要使用其他分隔符(如逗号或分号),可以在此参数中指定。
402-2-3、**kwargs(可选):其他参数,可传递给to_string方法,例如header、index等,这些参数用于控制Series的输出格式,如是否包含索引和标题。
402-3、功能
将Series对象的内容复制到剪贴板,方便在其他应用程序(如电子表格软件、文本编辑器等)中使用;支持Excel格式的输出,能够方便地在数据分析工作流中进行数据的临时共享和处理。
402-4、返回值
该方法没有返回值(返回None),主功能是将数据复制到剪贴板。
402-5、说明
无
402-6、用法
402-6-1、数据准备
无402-6-2、代码示例
# 402、pandas.Series.to_clipboard方法
import pandas as pd
# 创建一个示例Series
data = pd.Series([1, 2, 3, 4], name="Numbers")
# 将Series复制到剪贴板
data.to_clipboard(excel=True, sep='\t')
# 现在可以在Excel或文本编辑器中粘贴402-6-3、结果输出
无
403、pandas.Series.to_latex方法
403-1、语法
# 403、pandas.Series.to_latex方法
pandas.Series.to_latex(buf=None, *, columns=None, header=True, index=True, na_rep='NaN', formatters=None, float_format=None, sparsify=None, index_names=True, bold_rows=False, column_format=None, longtable=None, escape=None, encoding=None, decimal='.', multicolumn=None, multicolumn_format=None, multirow=None, caption=None, label=None, position=None)
Render object to a LaTeX tabular, longtable, or nested table.
Requires \usepackage{{booktabs}}. The output can be copy/pasted into a main LaTeX document or read from an external file with \input{{table.tex}}.
Changed in version 2.0.0: Refactored to use the Styler implementation via jinja2 templating.
Parameters:
bufstr, Path or StringIO-like, optional, default None
Buffer to write to. If None, the output is returned as a string.
columnslist of label, optional
The subset of columns to write. Writes all columns by default.
headerbool or list of str, default True
Write out the column names. If a list of strings is given, it is assumed to be aliases for the column names.
indexbool, default True
Write row names (index).
na_repstr, default ‘NaN’
Missing data representation.
formatterslist of functions or dict of {{str: function}}, optional
Formatter functions to apply to columns’ elements by position or name. The result of each function must be a unicode string. List must be of length equal to the number of columns.
float_formatone-parameter function or str, optional, default None
Formatter for floating point numbers. For example float_format="%.2f" and float_format="{{:0.2f}}".format will both result in 0.1234 being formatted as 0.12.
sparsifybool, optional
Set to False for a DataFrame with a hierarchical index to print every multiindex key at each row. By default, the value will be read from the config module.
index_namesbool, default True
Prints the names of the indexes.
bold_rowsbool, default False
Make the row labels bold in the output.
column_formatstr, optional
The columns format as specified in LaTeX table format e.g. ‘rcl’ for 3 columns. By default, ‘l’ will be used for all columns except columns of numbers, which default to ‘r’.
longtablebool, optional
Use a longtable environment instead of tabular. Requires adding a usepackage{{longtable}} to your LaTeX preamble. By default, the value will be read from the pandas config module, and set to True if the option styler.latex.environment is “longtable”.
Changed in version 2.0.0: The pandas option affecting this argument has changed.
escapebool, optional
By default, the value will be read from the pandas config module and set to True if the option styler.format.escape is “latex”. When set to False prevents from escaping latex special characters in column names.
Changed in version 2.0.0: The pandas option affecting this argument has changed, as has the default value to False.
encodingstr, optional
A string representing the encoding to use in the output file, defaults to ‘utf-8’.
decimalstr, default ‘.’
Character recognized as decimal separator, e.g. ‘,’ in Europe.
multicolumnbool, default True
Use multicolumn to enhance MultiIndex columns. The default will be read from the config module, and is set as the option styler.sparse.columns.
Changed in version 2.0.0: The pandas option affecting this argument has changed.
multicolumn_formatstr, default ‘r’
The alignment for multicolumns, similar to column_format The default will be read from the config module, and is set as the option styler.latex.multicol_align.
Changed in version 2.0.0: The pandas option affecting this argument has changed, as has the default value to “r”.
multirowbool, default True
Use multirow to enhance MultiIndex rows. Requires adding a usepackage{{multirow}} to your LaTeX preamble. Will print centered labels (instead of top-aligned) across the contained rows, separating groups via clines. The default will be read from the pandas config module, and is set as the option styler.sparse.index.
Changed in version 2.0.0: The pandas option affecting this argument has changed, as has the default value to True.
captionstr or tuple, optional
Tuple (full_caption, short_caption), which results in \caption[short_caption]{{full_caption}}; if a single string is passed, no short caption will be set.
labelstr, optional
The LaTeX label to be placed inside \label{{}} in the output. This is used with \ref{{}} in the main .tex file.
positionstr, optional
The LaTeX positional argument for tables, to be placed after \begin{{}} in the output.
Returns:
str or None
If buf is None, returns the result as a string. Otherwise returns None.
See also
io.formats.style.Styler.to_latex
Render a DataFrame to LaTeX with conditional formatting.
DataFrame.to_string
Render a DataFrame to a console-friendly tabular output.
DataFrame.to_html
Render a DataFrame as an HTML table.
Notes
As of v2.0.0 this method has changed to use the Styler implementation as part of Styler.to_latex() via jinja2 templating. This means that jinja2 is a requirement, and needs to be installed, for this method to function. It is advised that users switch to using Styler, since that implementation is more frequently updated and contains much more flexibility with the output.403-2、参数
403-2-1、buf(可选,默认值为None):字符串或None,输出的目标字符串缓冲区,如果为None,则返回LaTeX格式的字符串;如果提供了字符串,将写入该缓冲区。
403-2-2、columns(可选,默认值为None):列表或None,要包含在输出中的列名,如果为None,则包含所有列,通常在Series中无需这个参数,因为Series只有一列。
403-2-3、header(可选,默认值为True):布尔值,是否包含列头信息,对于Series,该参数通常无效,因为Series只有一列。
403-2-4、index(可选,默认值为True):布尔值,是否在输出中包含行索引。
403-2-5、na_rep(可选,默认值为'NaN'):字符串,用于表示缺失值的字符串。例如,可以设置为'-'。
403-2-6、formatters(可选,默认值为None):字典或可回调对象,指定格式化函数的字典或一个适用于所有值的格式化函数。
403-2-7、float_format(可选,默认值为None):可回调对象或None,处理浮点数格式的函数。
403-2-8、sparsify(可选,默认值为None):布尔值,是否简化输出格式,省略多级索引中的重复条目。
403-2-9、index_names(可选,默认值为True):布尔值,是否包含索引名称。
403-2-10、bold_rows(可选,默认值为False):布尔值,是否将行索引以粗体显示。
403-2-11、column_format(可选,默认值为None):字符串,指定列格式,可以用于定制表格布局。
403-2-12、longtable(可选,默认值为None):布尔值,如果为True,则输出将使用longtable环境,适用于跨页表格。
403-2-13、escape(可选,默认值为None):布尔值,是否转义LaTeX特殊字符。
403-2-14、encoding(可选,默认值为None):字符串,字符串编码类型。
403-2-15、decimal(可选,默认值为'.'):字符串,指定小数点符号,可以用于国际化需求。
403-2-16、multicolumn(可选,默认值为None):整数或None,允许将多个列合并为一个列以描述更复杂的表格结构。
403-2-17、multicolumn_format(可选,默认值为None):字符串或None,设置多列合并的格式。
403-2-18、multirow(可选,默认值为None):整数或None,允许将若干行合并为一个单元格。
403-2-19、caption(可选,默认值为None):字符串或None,在表格上方添加的标题。
403-2-20、label(可选,默认值为None):字符串或None,用于cross-referencing的标签。
403-2-21、position(可选,默认值为None):字符串或None,指定表格在LaTeX文档中的位置,例如'h', 't', 'b'等。
403-3、功能
将Pandas Series对象转换为易于在LaTeX文档中排版的表格格式,这使得用户可以轻松地在学术或技术出版物中插入数据,保持高质量的排版效果。
403-4、返回值
如果buf为None,该方法返回一个包含LaTeX表格的字符串;如果buf提供了,则该方法将表格写入指定的缓冲区并返回None。
403-5、说明
无
403-6、用法
403-6-1、数据准备
无403-6-2、代码示例
# 403、pandas.Series.to_latex方法
import pandas as pd
# 创建一个示例Series
data = pd.Series([1.23, 4.56, None, 7.89], index=['A', 'B', 'C', 'D'])
# 转换为LaTeX格式
latex_string = data.to_latex(index=True, na_rep='缺失', caption='示例数据表')
# 输出LaTeX字符串
print(latex_string)403-6-3、结果输出
# 403、pandas.Series.to_latex方法
# \begin{table}
# \caption{示例数据表}
# \begin{tabular}{lr}
# \toprule
# & 0 \\
# \midrule
# A & 1.230000 \\
# B & 4.560000 \\
# C & 缺失 \\
# D & 7.890000 \\
# \bottomrule
# \end{tabular}
# \end{table}404、pandas.Series.to_markdown方法
404-1、语法
# 404、pandas.Series.to_markdown方法
pandas.Series.to_markdown(buf=None, mode='wt', index=True, storage_options=None, **kwargs)
Print Series in Markdown-friendly format.
Parameters:
buf
str, Path or StringIO-like, optional, default None
Buffer to write to. If None, the output is returned as a string.
mode
str, optional
Mode in which file is opened, “wt” by default.
index
bool, optional, default True
Add index (row) labels.
storage_options
dict, optional
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open. Please see fsspec and urllib for more details, and for more examples on storage options refer here.
**kwargs
These parameters will be passed to tabulate.
Returns:
str
Series in Markdown-friendly format.
Notes
Requires the tabulate package.404-2、参数
404-2-1、buf(可选,默认值为None):字符串或None,输出的目标字符串缓冲区,若为None,则返回一个包含Markdown格式的字符串,如果提供了一个字符串,将写入该缓冲区。
404-2-2、mode(可选,默认值为'wt'):字符串,打开文件的模式,常用的模式有'wt'(写入文本)等,该参数主要影响将输出写入文件的方式,对于直接返回字符串时不影响。
404-2-3、index(可选,默认值为True):布尔值,是否在输出中包含行索引。
404-2-4、storage_options(可选,默认值为None):字典或None,用于传递存储选项的字典,主要对读取和写入操作有影响。
404-2-5、**kwargs(可选):其他关键字参数,可能包括格式化、排版等相关设置,具体取决于用户需要自定义的内容,比如精度、是否对齐等。
404-3、功能
将Pandas Series对象转换为Markdown表格格式,该功能使得用户能够轻松地在支持Markdown语法的环境中,比如GitHub、Jupyter Notebook等,展示数据,以保持良好的可读性和格式化效果。
404-4、返回值
如果buf为None,该方法返回一个包含Markdown表格的字符串;如果提供了buf,则将Markdown表格写入指定的缓冲区,并返回None。
404-5、说明
无
404-6、用法
404-6-1、数据准备
无404-6-2、代码示例
# 404、pandas.Series.to_markdown方法
import pandas as pd
s = pd.Series(["elk", "pig", "dog", "quetzal"], name="animal")
print(s.to_markdown())404-6-3、结果输出
# 404、pandas.Series.to_markdown方法
# | | animal |
# |---:|:---------|
# | 0 | elk |
# | 1 | pig |
# | 2 | dog |
# | 3 | quetzal |405、pandas.DataFrame类
405-1、语法
# 405、pandas.DataFrame类
class pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
Two-dimensional, size-mutable, potentially heterogeneous tabular data.
Data structure also contains labeled axes (rows and columns). Arithmetic operations align on both row and column labels. Can be thought of as a dict-like container for Series objects. The primary pandas data structure.
Parameters:
datandarray (structured or homogeneous), Iterable, dict, or DataFrame
Dict can contain Series, arrays, constants, dataclass or list-like objects. If data is a dict, column order follows insertion-order. If a dict contains Series which have an index defined, it is aligned by its index. This alignment also occurs if data is a Series or a DataFrame itself. Alignment is done on Series/DataFrame inputs.
If data is a list of dicts, column order follows insertion-order.
indexIndex or array-like
Index to use for resulting frame. Will default to RangeIndex if no indexing information part of input data and no index provided.
columnsIndex or array-like
Column labels to use for resulting frame when data does not have them, defaulting to RangeIndex(0, 1, 2, …, n). If data contains column labels, will perform column selection instead.
dtypedtype, default None
Data type to force. Only a single dtype is allowed. If None, infer.
copybool or None, default None
Copy data from inputs. For dict data, the default of None behaves like copy=True. For DataFrame or 2d ndarray input, the default of None behaves like copy=False. If data is a dict containing one or more Series (possibly of different dtypes), copy=False will ensure that these inputs are not copied.
Changed in version 1.3.0.
See also
DataFrame.from_records
Constructor from tuples, also record arrays.
DataFrame.from_dict
From dicts of Series, arrays, or dicts.
read_csv
Read a comma-separated values (csv) file into DataFrame.
read_table
Read general delimited file into DataFrame.
read_clipboard
Read text from clipboard into DataFrame.
Notes
Please reference the User Guide for more information.405-2、参数
405-2-1、data(可选,默认值为None):表示初始数据,可以是多种设计的结构,包括:
- ndarray:由数组元素创建DataFrame。
- list:由列表元素创建DataFrame。
- dict:由字典元素创建DataFrame,字典的键可以是列名,对应的值是列数据。
- DataFrame:使用已有的DataFrame初始化。
- Series:使用Series初始化,Index将被共享。
- dict of Series:一组Series对象。
- 其他iterable:任何可迭代对象。
405-2-2、index(可选,默认值为None):指定行索引标签,用于索引结果,若未提供,则默认从0到n-1作为索引。
405-2-3、columns(可选,默认值为None):指定列索引标签,用于指定列名,若未提供,则默认从0到n-1作为列名(仅针对二维数组)。
405-2-4、dtype(可选,默认值为None):指定DataFrame中数据的类型,若传入None,则数据类型由数据推断。
405-2-5、copy(可选,默认值为None):布尔值,指定是否深拷贝数据,当为True时,即使传入的是DataFrame或其他Pandas数据结构,也进行数据的深拷贝。
405-3、功能
用于表示二维、大小可变、具有潜在异构类型的表格数据。
405-4、返回值
返回一个DataFrame对象,它是Pandas的核心数据结构,提供多种数据操作和分析工具。
405-5、说明
无
405-6、用法
405-6-1、数据准备
无405-6-2、代码示例
# 405、pandas.DataFrame类
import pandas as pd
import numpy as np
# 使用ndarray创建DataFrame
array_data = np.array([[1, 2, 3], [4, 5, 6]])
df_from_array = pd.DataFrame(data=array_data, index=['row1', 'row2'], columns=['col1', 'col2', 'col3'])
print("DataFrame from array:\n", df_from_array)
# 使用dict创建DataFrame
dict_data = {'col1': [1, 2], 'col2': [3, 4], 'col3': [5, 6]}
df_from_dict = pd.DataFrame(data=dict_data, index=['row1', 'row2'])
print("DataFrame from dict:\n", df_from_dict)
# 使用DataFrame创建DataFrame
df_copy = pd.DataFrame(data=df_from_dict, copy=True)
print("Copied DataFrame:\n", df_copy)405-6-3、结果输出
# 405、pandas.DataFrame类
# DataFrame from array:
# col1 col2 col3
# row1 1 2 3
# row2 4 5 6
# DataFrame from dict:
# col1 col2 col3
# row1 1 3 5
# row2 2 4 6
# Copied DataFrame:
# col1 col2 col3
# row1 1 3 5
# row2 2 4 6