文章目录
- 概述
- 位序和字节序
- 驱动层CAN帧数据结构
- 待发送数据的结构
- 待接收数据的结构
- 仲裁段使用U32的低位?
- 位段结构和寄存器位的映射
- 数据段的发送顺序
- CAN协议定义
- 协议文档中的定义
- 仲裁段定义
- 数据段定义
- 跨平台CAN通信
概述
我们已然明确地知道,CAN仲裁段的定义,决定了CAN帧在物理总线上的传送优先级。那么,该怎么定义这个仲裁段,或者说如何定义CAN标准帧或扩展帧的CanID位段结构,才能按照自己的需求控制各设备发出的CAN帧的优先级呢?CAN帧的仲裁段和数据段的信息组织,是否要考虑大小端字节序?
@History
参考《语言基础/分析和实践 C&C++ 位域结构数据类型》文中的讲述,其中也简单的提到了CAN协议仲裁段定义的注意事项。在接下来的嵌入式开发项目中,又要用到CAN通信,4年前的使用只是浮于表面,这回算是正是入手了。在整理上述关于位域的CSDN博文时,将与CAN仲裁段位域定义的相关部分单独提溜了出来,结合对 STM32 CAN 驱动源码的阅读,写了此文。
位序和字节序
以太网协议规定了数据的字节传输顺序,即网络字节序,但并没有规定数据的位传输顺序。与之不同的是,CAN协议本身并没有规定字节发送顺序,它只规定了数据的位传输顺序。通常说,位传输顺序是由具体的硬件实现决定的,可以是从左到右(Most Significant Bit First,MSb)或从右到左(Least Significant Bit First,LSb)的顺序,这里的硬件可能包括但不限于,如,数据寄存器、移位寄存器等(仅是个人理解哈)。在CAN协议中,数据的位传输顺序是由协议本身明确定义的,所有厂商制造的CAN外设都要按照此规范来实现。

在计算中,最低有效位(LSb)是二进制整数中表示整数二进制1的位位置,最高有效位(MSb)表示二进制整数的最高位。由于在位值记法(我们平时对二进制数的阅读法)中将较不显著的数字写在右边,因此LSb有时被称为低阶位或最右边位。类似地,MSb被称为高阶位或最左边位。在维基百科 Bit numbering 的描述如上,两种不同的位传输顺序。“Most significant bit first”和“least significant bit at last” 这两个表述指示了在串行传输协议或流(例如音频流)中发送的字节中比特序列的排序方式。“Most significant bit first”意味着最重要的比特将首先到达:因此,例如十六进制数0x12,在二进制表示中为00010010,将以顺序0 0 0 1 0 0 1 0到达。“Least significant bit first” 意味着最不重要的比特将首先到达:因此,例如相同的十六进制数0x12,再次是00010010的二进制表示,将以(反转的)顺序0 1 0 0 1 0 0 0到达。
字节序是小端的 CPU 通常其位序为 LSb 0,不仅是数据字节在内存中“高高低低”存放,字节的位序也是“高高低低”放置的,即 MSb 存放在 bit7 位置上,LSb 放置在 bit0 位置上。值得注意的是,字节序是大端的 CPU 采用的位序却不是那么统一,既有 MSb 0,也有LSb0 。一个常规的样子如下,

结合近期关于大小端、结构体、位段结构等主题文章的整理和学习,我基本可以推论,CAN通信在协议层次上强势规定传输位序,是比以太网规定字节序更加严苛的规定,这种规定,使得CAN通信不必关注通信双方的字节序模式,各通信设备根据自身情况去解读bit位就可以。但这只是推论,对目前的我来说,去构建一个32bit的大端环境(参见《存储和传输/寻找大端字节序》),都要耗费心神还难以搞定。让我在搭建一个不光支持大端字节序还要支持CAN通信的环境,就更难为我了。
首先的一个前提是,无论标准帧的仲裁段11bit还是扩展帧的29bit,都不会超过寄存器位宽32bit,即不超过机器字长位宽,这么说可能有点欠妥,明白那个意思就行了。如果我是芯片制造厂商的设计者,我会充分利用高位到低位的传输约定,在结合自身CPU大小端字节序的特点,直接将收到的位数据转换为符合自身字节序的字节存储。再不济,从CAN寄存器中取出数据时,在驱动层通过软手段,也能灵活的将位数据映射为大端存储或小端存储的内存数据。
驱动层CAN帧数据结构
我们已经知道CAN协议是定义了发送位序的,从高位到低位顺序发送。
待发送数据的结构
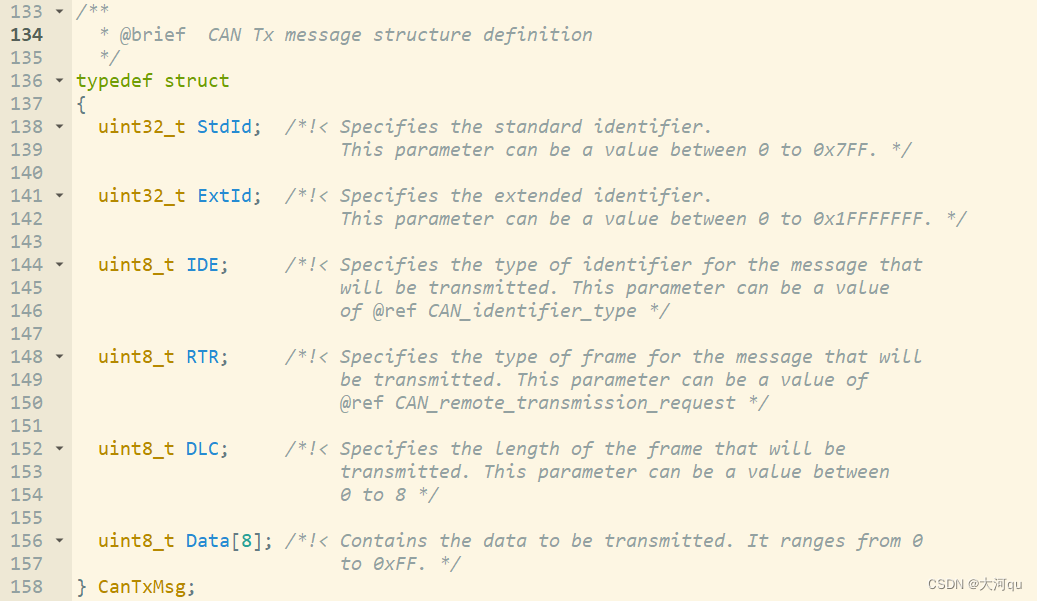
在 STM32F4xx_StdPeriph_Driver\inc\stm32f4xx_can.h 头文件定义,
typedef struct { //river.qu @CSDN
uint32_t StdId; /*! 存储标准帧的标识符,11bit 0 to 0x7FF*/
uint32_t ExtId; /*! 存储标准帧的标识符,29bit 0 to 0x1FFFFFFF. */
uint8_t IDE; /*! 取值 CAN_ID_STD(表示标准帧)或 CAN_ID_EXT(表示扩展帧) */
uint8_t RTR; /*! 取值 CAN_RTR_DATA(表示数据帧)或 CAN_RTR_REMOTE(表示远程帧) */
uint8_t DLC; /*! 表示数据帧中的实际数据长度,范围为0-8 */
uint8_t Data[8]; /*! 用于存储CAN消息的数据部分,最多包含8个字节的数据 */
} CanTxMsg;
首先映入眼帘的是 StdId 和 ExtId 是并列定义的,而不是union联合定义,说实话,我不是太理解这是出于怎样的考虑?
理论上来说,标准帧和扩展帧不能同时存在,同一时刻只有StdId或ExtId字段中的一个会被填充,无疑,此时使用联合结构可以更加节省空间。有点牵强的说法是,上述并列定义可以帮助开发人员在同一个结构体中方便地存储和处理不同类型的CAN标识符,提供了更大的灵活性和可扩展性,有更好的可读性和可维护性。另外,这种并列方式的定义,可能使得该驱动代码,可以更好地兼容和适应不同的CAN硬件和软件实现,以确保代码在不同的平台和芯片上的可移植性。这里不再深究,认定 STM32 芯片 CAN 驱动的开发者们是基于合理的、我不太理解的原因,如此定义,哈哈,毕竟我们只是普通的使用者,也改变不了它。
待接收数据的结构

仲裁段使用U32的低位?
结合上文,标识仲裁段位数据的 StdId 和 ExtId 都是 uint32_t 数据类型,但是它们都不足32bit呢,于是就产生了题目中的问题。以 StdId 为例,CAN 标准帧的11 位仲裁位是 U32的高11位 [0-10]bit,还是U32的低11位 [21-31]bit 呢?
为此,我们找到CAN的发送函数实现,如下,
/**
* @brief Initiates and transmits a CAN frame message.
* @param CANx: where x can be 1 or 2 to to select the CAN peripheral.
* @param TxMessage: pointer to a structure which contains CAN Id, CAN DLC and CAN data.
* @retval The number of the mailbox that is used for transmission or
* CAN_TxStatus_NoMailBox if there is no empty mailbox.
*/
uint8_t CAN_Transmit(CAN_TypeDef* CANx, CanTxMsg* TxMessage)
{
uint8_t transmit_mailbox = 0;
/* Check the parameters */
assert_param(IS_CAN_ALL_PERIPH(CANx));
assert_param(IS_CAN_IDTYPE(TxMessage->IDE));
assert_param(IS_CAN_RTR(TxMessage->RTR));
assert_param(IS_CAN_DLC(TxMessage->DLC));
/* Select one empty transmit mailbox */
if ((CANx->TSR&CAN_TSR_TME0) == CAN_TSR_TME0) {
transmit_mailbox = 0;
}
else if ((CANx->TSR&CAN_TSR_TME1) == CAN_TSR_TME1) {
transmit_mailbox = 1;
}
else if ((CANx->TSR&CAN_TSR_TME2) == CAN_TSR_TME2) {
transmit_mailbox = 2;
}
else {
transmit_mailbox = CAN_TxStatus_NoMailBox;
}
if (transmit_mailbox != CAN_TxStatus_NoMailBox) {
/* Set up the Id */
CANx->sTxMailBox[transmit_mailbox].TIR &= TMIDxR_TXRQ;
if (TxMessage->IDE == CAN_Id_Standard) {
assert_param(IS_CAN_STDID(TxMessage->StdId));
CANx->sTxMailBox[transmit_mailbox].TIR |= ((TxMessage->StdId << 21) | \
TxMessage->RTR);
}
else {
assert_param(IS_CAN_EXTID(TxMessage->ExtId));
CANx->sTxMailBox[transmit_mailbox].TIR |= ((TxMessage->ExtId << 3) | \
TxMessage->IDE | \
TxMessage->RTR);
}
/* Set up the DLC */
TxMessage->DLC &= (uint8_t)0x0000000F;
CANx->sTxMailBox[transmit_mailbox].TDTR &= (uint32_t)0xFFFFFFF0;
CANx->sTxMailBox[transmit_mailbox].TDTR |= TxMessage->DLC;
/* Set up the data field */
CANx->sTxMailBox[transmit_mailbox].TDLR = (((uint32_t)TxMessage->Data[3] << 24) |
((uint32_t)TxMessage->Data[2] << 16) |
((uint32_t)TxMessage->Data[1] << 8) |
((uint32_t)TxMessage->Data[0]));
CANx->sTxMailBox[transmit_mailbox].TDHR = (((uint32_t)TxMessage->Data[7] << 24) |
((uint32_t)TxMessage->Data[6] << 16) |
((uint32_t)TxMessage->Data[5] << 8) |
((uint32_t)TxMessage->Data[4]));
/* Request transmission */
CANx->sTxMailBox[transmit_mailbox].TIR |= TMIDxR_TXRQ;
}
return transmit_mailbox;
}
其中关于仲裁段设置的代码如下,
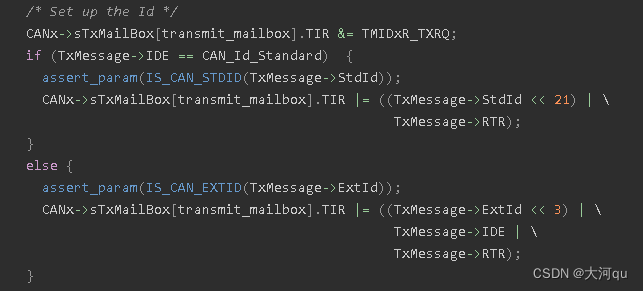
上述代码中,其中 TIR 是发送邮箱结构定义中的字段,其结构体定义如下,
/**
* @brief Controller Area Network TxMailBox
*/
typedef struct {
__IO uint32_t TIR; /*!< CAN TX mailbox identifier register */
__IO uint32_t TDTR; /*!< CAN mailbox data length control and time stamp register */
__IO uint32_t TDLR; /*!< CAN mailbox data low register */
__IO uint32_t TDHR; /*!< CAN mailbox data high register */
} CAN_TxMailBox_TypeDef;
邮箱 TIR 是 TX mailbox identifier register 的意思,即发送邮箱标识符寄存器,也就是CAN仲裁段在发送出去的前一刻所在的位置。结合上文对TIR的设置代码,在标准帧模式下,32位的StdId,先是左移了21位,也就是说高21位被干掉了,即CAN底层使用的是StdId的低11位。同样地,32位的ExtdId在传递给邮箱 TIR 字段时,抛弃了高3位,使用的是其ExtdId的低29位。
分析至此变可以明确:在CAN应用层传入的32位的CanID值,如果是标准帧ID,则高21位被抛弃;如果是扩展帧ID,则高3bit最终被驱动层抛弃。在CAN驱动层会截取其低11bit(标准帧) 或 29bit(扩展帧) 来最终使用,因此,具体标准帧ID和扩展帧ID的的位段结构定义中,保留位是在末尾的字段哦,具体参见文末章节中的定义。
位段结构和寄存器位的映射
在《语言基础/分析和实践 C&C++ 位域结构数据类型》文中的讲述,已经足够证明,最后出现的字段占据数值的高位区,最后出现字段的最高位,对应的是存储字段内存区的MSb。直觉告诉我,CAN的高位发送,其中的高位,应该是指存储发送数据的寄存器的高位。
在进一步讨论前,要先明确的2点是,
1、对于寄存器而言,通常不涉及字节序的概念,因为寄存器中的位和比特是按照位的顺序来定义和访问的,而不是按照字节来分割。在寄存器级别的操作中,通常会直接操作寄存器的位(bit),而不是以字节为单位进行操作。
2、邮箱是软件和硬件之间传递报文的接口,其包含了所有跟报文有关的标识符、数据、控制、状态和时间戳信息。
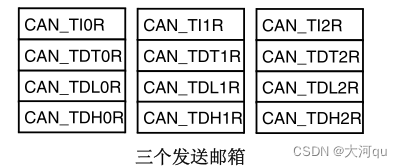
与 F407 一样,103也通常是3个发送邮箱,如下图,每个邮箱包含4个寄存器。CAN 发送邮箱标识符寄存器 (CAN_TIxR) (x=0…2) / CAN 邮箱数据长度控制和时间戳寄存器 (CAN_TDTxR) (x=0…2) / CAN 邮箱数据低位寄存器 (CAN_TDLxR) (x=0…2) / CAN 邮箱数据高位寄存器 (CAN_TDHxR) (x=0…2)
我进一步想去验证的是,我从应用层传递到驱动层的CanID,等存储到CAN的发送邮箱中的 TIR 标识符寄存器中后,其位序或值是否完全一致,有没有位的反转或什么别的啥?或者我当时就想简单的看看 CAN_TxMailBox_TypeDef 中的TIR 内存字段值与直接读外设寄存器值,是不是完全一样?小端上的内存位序和寄存的位序难道会有不同?
我们重点关注 TIR 发送邮箱标识符寄存器,其位分配如下,

使用如下代码,标准帧进行如下测试过程,
#define MR_U32 unsigned int
//StdID 标准帧
typedef struct {
MR_U32 bitDevID:5; //设别标识
MR_U32 bitDevType:4; //设别类型
MR_U32 bitPriority:2; //优先级
MR_U32 bitReserve:21; //高位不使用 /参见CAN驱动代码
} TCanIDStd;
//
typedef union {
TCanIDStd tCanStdID;
MR_U32 u32CanStdID;
} UStdID;
//测试用用发送函数
u8 CAN1_Send_Msg(u8* msg,u8 len) {
u8 i=0;
u32 TxMailbox;
u8 message[8];
UStdID uStdID;
//仲裁段赋值
uStdID.tCanStdID.bitPriority = 1;
uStdID.tCanStdID.bitDevType = 2;
uStdID.tCanStdID.bitDevID = 3;
uStdID.tCanStdID.bitReserve = 0;
TxHeader.StdId = uStdID.u32CanStdID;
TxHeader.ExtId = 0;
TxHeader.IDE=CAN_ID_STD; //使用标准帧
TxHeader.RTR=CAN_RTR_DATA; //数据帧
TxHeader.DLC=len;
for(i=0;i<len;i++) {
message[i]=msg[i];
}
if(HAL_CAN_AddTxMessage(&CAN1_Handler, &TxHeader, message, &TxMailbox) != HAL_OK) {
return 1;
}
...
}
按照如上代码赋值的 StdId 其值和内存字节如下图,

如上,4字节的 StdId ,在小端的STM32中,其存储为 43 02 00 00,翻译为二进制为,

如上,uStdID.u32CanStdID 其中的第一个字段 bitDevID 被放置在了最低bit位。

先要明确的是,CAN的从高位发送,更具体的说应该是,从发送邮箱的第一个寄存器TIR的最高位开始发送。接下来是要重点验证的地方,TxHeader.StdId 的低11bit,被安置到TIR寄存器中。STDID[10] 被安置在 TIR [31],按照上述TIR寄存器位配置,

翻译成16进制数据,0x48600000,我们来监视TIR寄存器的值,是否符合预期。在 View 菜单的 System Viewer 子菜单中打开 CAN 寄存器监视窗口(以普通103为例,这例要监视的是 CAN_TI0R寄存器),如下图,
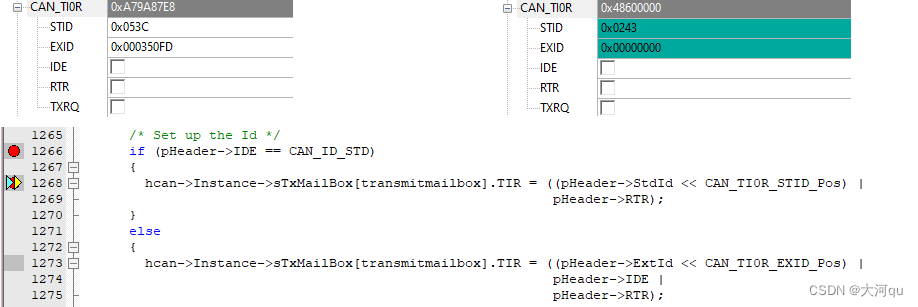
结果符合预期。what?寄存器中反读到的值,与TIR值一致,其中的CanID部分也与应用层传入的值一致,位序也匹配。
数据段的发送顺序
我们实际压入CAN数据区的数据可能是U16、U32、U64等多字节整数值或位域结构值。假如我们的实际数据是U64的位域值,如文末给出的 TCanDenoDt位段结构数据,接下来,我们将看看数据段的位发送顺序或者是字节发送顺序。
参照前文给出的待发送CAN帧的驱动层数据结构,数据段形式为 U8 Data[8]。结合《存储与传输/大小端字节序的概念、决定因素、给编程带来的困扰》中的讲述,数组在内存中的存储本质与结构对象无异,下标为0的元素,在内存存储位置上与结构体第一字段存储位置一致,无论是大端还是小端系统,Data[0]一定是在内存低地址上的,加之这里的数据段元素是单字节,因此,从交互的角度上看,似乎没有大小端问题呢?要考虑的,只是U64和U8 Data[8]之间(可以将他们放在一个假想的联合结构内)的字节映射关系。Data[0]指向的是内存最低地址,Data[7]指向的是内存最高地址。至此,问题就可以具体到CAN上是先发送Data[7](小端:高地址,高字节)还是Data[0](低地址,低字节)呢?
uint8_t CAN_Transmit(CAN_TypeDef* CANx, CanTxMsg* TxMessage) {
...
/* Set up the data field */
CANx->sTxMailBox[transmit_mailbox].TDLR = (((uint32_t)TxMessage->Data[3] << 24) |
((uint32_t)TxMessage->Data[2] << 16) |
((uint32_t)TxMessage->Data[1] << 8) |
((uint32_t)TxMessage->Data[0]));
CANx->sTxMailBox[transmit_mailbox].TDHR = (((uint32_t)TxMessage->Data[7] << 24) |
((uint32_t)TxMessage->Data[6] << 16) |
((uint32_t)TxMessage->Data[5] << 8) |
((uint32_t)TxMessage->Data[4]));
...
return transmit_mailbox;
}
如上CAN_Transmit函数中显示的那样,Data[7]被放在了TDHR数据高寄存器的最高字节中,Data[0]被放在了TDLR数据低寄存器的最低字节中。下图是F407手册中,CAN 邮箱数据高位寄存器 (CAN_TDHxR) 的32bit位,与Data字节之间的关系图,

如上图,DATA7[7]对应的是CAN邮箱高位寄存器的最高bit位,再结合CAN协议从高位到低位发送顺序的约定,这里可以大胆的猜测,CAN上最先发送出去的就是高位寄存器中存储的最高位,即上述DATA7[7],其后发送的是DATA7[6]…DATA6[7]…DATA6[0]…DATA4[0]…DATA3[7]…DATA3[0]…DATA0[0],共计64bit数据。
也即可以确定,数据字节发送顺序是Data[7]到Data[0],这倒是与网络字节序发送顺序相反,在以太网数据传输中,数据字节流从低地址到高地址向外发送,这里反而是从高地址到低地址进行发送(要强调的一点是,网络字节序规定了多字节数据要转成大端后再进行传输,但TCP/IP本身并不去关心传输的数据是什么字节序的,其按照内存字节流顺序向远端发送)。Data[7]对应的是U64的高字节,因此,在stm32这个小端MCU中,CAN数据段先传递到远端的是64bit数据的最高有效字节,且最高有效字节的最高有效位(下图bit63)最先先传输,

如上图,在小端系统上,以U64的数据u64Data=0x1122334455667788为例,注明了该数据在小端内存中的存储,其与Data[8]各元素对应关系,位序和位取值。
再次强调,所谓网络字节序的约定,是期望你把所有带发送数据先转换成大端字节序,回存到数据发送缓冲区的内存中,然后发送这个转换后的字节流。TCP/IP不关心你要发送的字节流是什么,当然不会替你转换,如果你自己不去转换,而是直接发送,那么内存中存储的全部字节流的从低地址到搞地地址的存储顺序就是最终的数据字节传输顺序。网络传输上不关注位顺序,如上,位顺序大概率是7-0,15-8, …, 63-56,具体的不再深究,可能要用示波器等硬件信号分析仪来深入探究。总之,对于没有经过人为转换的u64Data原始存储数据,在网络上,先传输Data[0],最后传输Data[7]。
而CAN数据段上,在传输上述u64Data原始存储数据时,其字节顺序很明显是相反的,先传输Data[7],最后传输Data[0]。这有点像是,有的像是,CAN驱动层默默的替你做将小端字节序转位大端字节序这个事情。
假设上述通信过程的CAN远端是一个大端系统(发送端是小端系统),
我想,只是猜测哈,在CAN硬件和驱动层的加持下,可以保证接收端 TDHR 和 TDLR 两个寄存器的值与发送端相应寄存器的值是一致的。如此一来,接收端的CAN驱动层,完全可以在判断出自己是大端或小端后,将TDHR 和 TDLR 两个寄存器的位数据映射成不同的内存字节顺序。这样就在CAN驱动层上屏蔽了大小端字节序,在CAN应用层就不必要在去执行和关系大小端字节序转换问题。
上述大多只是猜想哈,我现在没能力和时间搭建一个大小端系统间的CAN通信环境。好在,一般情况下,小端系统,尤其是在嵌入式开发中,其主流趋势已经达到了几乎垄断的地步,我们不太需要过度关注CAN通信上的大小端字节序问题。我们只要重点关注CAN仲裁段的位序和位段结构定义就好。
CAN协议定义
本章节将描述CAN协议文档的编写方式、仲裁段位段结构定义、数据段位段结构定义。
协议文档中的定义
在协议文档中,我们通常会把仲裁段中的要优先发送的字段写在文档的最前边,毕竟文档要符合人的阅读习惯。以扩展帧定义为例,

结合《语言基础/分析和实践 C&C++ 位域结构数据类型》和《存储和传输/探究结构数据(C/C++结构体)在内存中的对齐和填充规则》文中的相关分析,我们已经清晰的知道(位段和字段的概念是不一样的哈,多个位段合起来占用一个存储字段,可参考链接中的文章),位段结构定义中先出现的位段占用的是结构存储字段的低bit位,后出现的位段占据的结构存储字段的高bit位。故,会有如下现象:文档中的位段定义顺序与实际代码结构体定义中的位段顺序是相反的。
仲裁段定义
//CAN扩展帧定义
typedef struct {
MX_U32 ibDDevID : 5; //目标设备
MX_U32 ibDDevType : 4; //目标设备
MX_U32 ibMsgF : 5; //消息功能
MX_U32 ibMsgType : 4; //消息类型
MX_U32 ibSDevID : 5; //源设备
MX_U32 ibSDevType : 4; //源设备
MX_U32 ibMsgC : 2; //消息优先级
MX_U32 ibReserve : 3; //占位 //高位
} TCanExtID; //29bit
//CAN标准帧定义
typedef struct {
MX_U32 ibSDevID : 5; //源设备标识
MX_U32 ibSDevType : 4; //源设备类型
MX_U32 ibMsgC : 2; //消息优先级 /MsgTF定义在数据段中
MX_U32 ibReserve : 21; //占位 //高位
} TCanStdID;
数据段定义
//数据段定义举例
typedef struct tagPtlCanDemoData {
MX_U64 ibAck1 : 1;
MX_U64 ibAck2 : 1;
MX_U64 ibDtBlockSn : 4;
MX_U64 ibDtBlockLen : 18;
MX_U64 u8FileType : 8;
MX_U64 u8FileVer : 8;
MX_U64 u8CheckSum : 8;
MX_U64 ibMsTmout : 10;
MX_U64 ibReserve : 6; //保留
} TCanDenoDt;
跨平台CAN通信
在《网络编程/在哪些场景中不必要进行网络字节序转换》中我们谈及了跨平台的以太网通信,结合《存储和传输/探究结构数据(C/C++结构体)在内存中的对齐和填充规则》 中的讲述,我们知道,即使通信双方的平台不一致,其协议层次上的结构类型的定义也是一致的,且必须是完全一致的,包括字段类型和字段定义的顺序。所谓的字节序转换,仅仅是在传输的前一刻或者读取共享文件的后一刻,根据实际情况转换结构的具体多字节字段,或者如文本文件BOM规则和编码规则进行正确解析。
如果真的碰上了CAN通信双方系统的字节序模式不一致,那么CAN协议层次上的数据(位段)结构定义,也是要双方一致的。结合《语言基础/分析和实践 C&C++ 位域结构数据类型》文中的分析可知,无论是在小端系统还是大端系统中,位域结构体中的末尾位段(最后出现的位段),都对应存储字段(也是传输字段)的高位区域,末尾字段的最高有效位对应着整个存储字段的最高有效位。我猜测,即使CAN通信双方字节序模式不一致,发收双发的标识符寄存器和数据寄存器的位值应该会保持一致,并期望在CAN驱动层会替我映射符合本机的大小端字节序。
就这样吧,洗洗睡了。