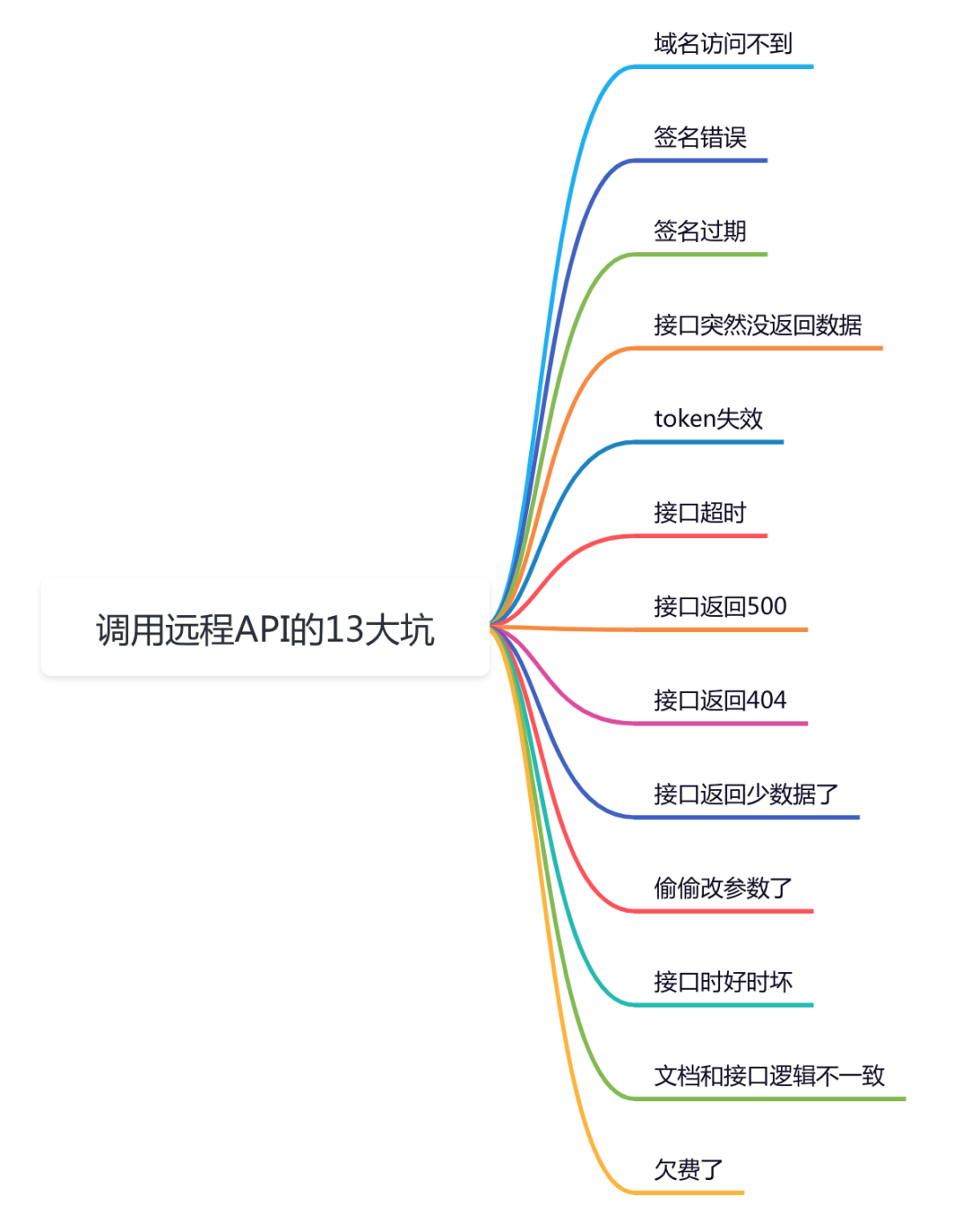
在此前,transformer已经通过ViT等作品展现出了它在cv领域的无限可能性,但是,vit主要针对的是图像分类问题的讨论,而分类只是cv众多问题中最基础的问题之一。那么,怎么用transformer进行物体检测,语义分割这些需要更复杂网络结构的任务呢?
介绍
在CNN对于图像分类,目标检测等问题的探索中,大家已经发现,检测,语义分割这类任务,相比于图像分类对于网络backbone有着不一样的需求。
而基于vit对于图像分类问题的探索,接下来,大家可以依葫芦画瓢,尝试解决更有挑战的问题了。
关于目标检测,语义分割这类任务,通常需要网络具有分层提取不同颗粒度的特征,并且,网络的是输入可能是更高分辨率的图像,输出也是更精细的特征,比如语义分割的mask。所以,基于transformer执行复杂cv任务的挑战在于1. 解决特征的尺度问题 2. 高效的处理大尺度的输入和输出。

这张图体现了vit和swin的区别,在vit中,每个block处理的都是相同大小的patch(16 x 16)
为了解决这些问题,swin transformer提出了shifted window的概念,去建立网络各层窗口的联系,此外,通过对于key的共享,我们可以实现显存更高效的使用。
参考李沐讲论文,在CNN中,我们可以知道,针对目标检测任务,我们通常使用FPN,而针对语义分割任务,我们通常使用UNet来解决问题,以及空洞卷积,PSP,ASPP。
方法论
Patch Merging-解决感受野的缩放问题
随着图像尺寸增加,计算量会面临O2级别的复杂度增加: 参考下面的图片,图像处理中,我们的输入通常是512*512以上的大小,再加上O2的复杂度,计算量飙升。在卷积网络中,通常会使用max pooling来实现感受野的缩放,而在swin transformer中,类似的需求是通过patch merging这个方法来满足,

其思路是,以4个元素为patch,分为4层,再通过线性层转换为2层,这样就实现了感受野长宽缩小一倍,通道数增加一倍。
The first patch merging layer concatenates the features of each group of 2 × 2 neighboring patches, and applies a linear layer on the 4C-dimensional concatenated features. This reduces the number of tokens by a multiple of 2×2 = 4 (2× downsampling of resolution), and the output dimension is set to 2C.
Shifted Window based Self-Attention
这里有三个词,shifted,window,self-attention,这三个词很值得推敲,因为它们是三个东西。因果关系是,因为self-attention的引入,我们需要考虑计算量,通过对于特定大小的patch计算注意力,我们保证了计算量没有随着图像尺度增加倍数增加。但是,单个窗口需要与相邻窗口建立联系,所以又提出了shift window的概念。
pixel --> patch --> window
patch是Vit就有的一个概念,意味着以多少个像素为集合进行attention的操作。window是swin提出的“新概念”,为了保证复杂度的限制,我们只在window中进行各个patch彼此间的注意力计算。
shift window
我们通过窗口的偏移,来实现与邻近window的交互,但是,在窗口偏移后,怎么处理edge上的元素呢?这里要考虑2个点,首先不希望增加计算量,其次,不希望像素位置不相邻的元素建立联系,比如左上方和右下方。所以,这里提出了cyclic shift, masked MSA两个概念。

Pixel shuffling


参考资料:
Swin Transformer论文精读【论文精读】_哔哩哔哩_bilibili