🍉CSDN小墨&晓末:https://blog.csdn.net/jd1813346972
个人介绍: 研一|统计学|干货分享
擅长Python、Matlab、R等主流编程软件
累计十余项国家级比赛奖项,参与研究经费10w、40w级横向
文章目录
- 1 数据框的创建方法
- 1.1 直接定义
- 1.2 导入定义
- 2 查看行或列
- 3 引用行或列
- 4 index操作
- 5 删除或过滤行/列
- 6 算数运算
- 7 大小比较运算
- 8 统计信息
- 9 排序
- 10 导入/导出
- 11 缺失数据处理
- 12 分组统计
【Python进阶(八)】——数据框,建议收藏!
该篇文章主要讲解了Python数据结构之DataFrame,针对DataFrame不同数据操作形式及基础统计方法进行实例演示。
1 数据框的创建方法
1.1 直接定义
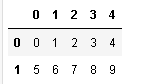
运行程序:
import numpy as np
import pandas as pd
df1=pd.DataFrame(np.arange(10).reshape(2,5))
df1
运行结果:
1.2 导入定义
运行程序:
import openpyxl
import pandas as pd
df2=pd.read_excel('1副本1.xlsx')#读取数据
df2.shape#形状
df2=df2[["Time t(s)","Q"]]#提取对应列
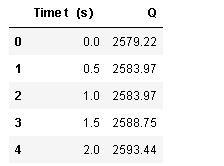
df2.head() #显示前5行
运行结果:
(404, 1300)
2 查看行或列
运行程序:
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all" ##执行多输出
df2.index#查看行名,即行的显式索引-用index属性
df2.index.size #行大小
df2.columns #显示列名
df2.columns.size#列大小
df2.shape#数据框形状
print("行数为:", df2.shape[0])
print("列数为:", df2.shape[1])
运行结果:
RangeIndex(start=0, stop=404, step=1)
404
Index(['Time t(s)', 'Q'], dtype='object')
2
(404, 2)
行数为: 404
列数为: 2
3 引用行或列
运行程序:
df2["Time t(s)"].head()#时间列前几行
df2.Q.head() #Q列前几行
df2["Time t(s)"][2] #时间列第3个
df2.Q[2]#Q列第三个
df2["Time t(s)"][[2,4]]#时间列第3个和第5个
df2.loc[1,"Time t(s)"] #显式index,时间列第2个
df2.iloc[1,0] #第2行第1列,隐式index
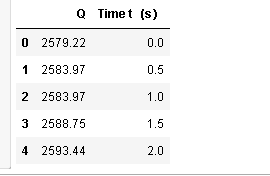
df2[["Q","Time t(s)"]].head()#Q和时间列前5行,显式访问非连续元素
运行结果:
0 0.0
1 0.5
2 1.0
3 1.5
4 2.0
Name: Time t(s), dtype: float64
0 2579.22
1 2583.97
2 2583.97
3 2588.75
4 2593.44
Name: Q, dtype: float64
1.0
2583.97
2 1.0
4 2.0
Name: Time t(s), dtype: float64
0.5
0.5
4 index操作
运行程序:
df2.index#索引状况
df2.columns#列名
df2["Q"].head()#Q列前几行
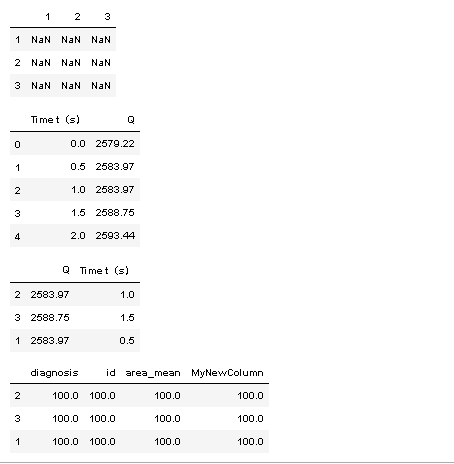
df2.reindex(index=["1","2","3"],columns=["1","2","3"])#更改显示index方法,调整index顺序
df2.head()#df2前几行
df2.reindex(index=[2,3,1], columns=["Q","Time t(s)"])#更改显示index方法,调整index顺序
df3=df2.reindex(index=[2,3,1], columns=["diagnosis","id","area_mean","MyNewColumn"],fill_value=100)#修改index顺序后,新增列
df3
运行结果:
RangeIndex(start=0, stop=404, step=1)
Index(['Time t(s)', 'Q'], dtype='object')
0 2579.22
1 2583.97
2 2583.97
3 2588.75
4 2593.44
Name: Q, dtype: float64
5 删除或过滤行/列
运行程序:
import pandas as pd
df2 = pd.read_csv('bc_data.csv')#导入文件
df2=df2[["id","diagnosis","area_mean"]]#提取对应列
df2.head()#显示前几行
df2.drop([2]).head()#删除第三行
df2.head()#显示前几行
运行结果:

运行程序:
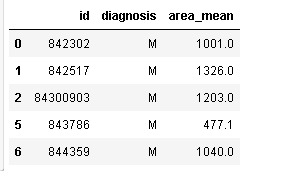
import pandas as pd
df2 = pd.read_csv('bc_data.csv')
df2=df2[["id","diagnosis","area_mean"]]
df2.drop([3,4], axis=0, inplace=True)#删除第4、5行,》drop不改变数据框本身
df2.head()
运行结果:
运行程序:
import pandas as pd
df2 = pd.read_csv('bc_data.csv')
df2=df2[["id","diagnosis","area_mean"]]
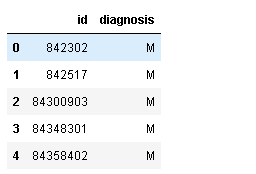
df2.drop(["id","diagnosis"], axis=1, inplace=True)#删除列
df2.head()
运行结果:
运行程序:
import pandas as pd
df2 = pd.read_csv('bc_data.csv')
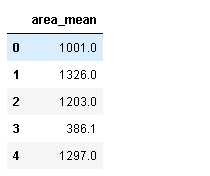
df2=df2[["id","diagnosis","area_mean"]]
df2.drop(["id","diagnosis"], axis=1, inplace=True)#删除列
df2.head()
运行结果:
运行程序:
import pandas as pd
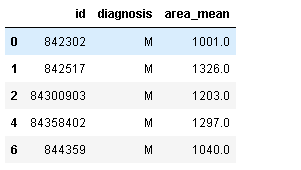
df2 =pd.read_csv('bc_data.csv')
df2=df2[["id","diagnosis","area_mean"]]
df2[df2.area_mean> 1000].head()#满足对应列值大于1000
运行结果:
运行程序:
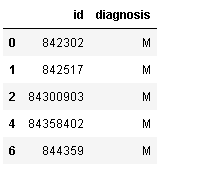
df2[df2.area_mean> 1000][["id","diagnosis"]].head()#妈祖对应列大于1000且仅显示对应列
运行结果:
6 算数运算
运行程序:
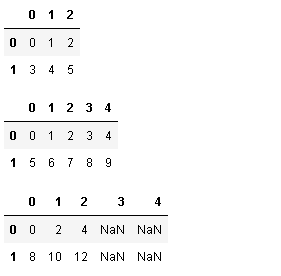
df4=pd.DataFrame(np.arange(6).reshape(2,3))
df4#矩阵转成数据框
df5=pd.DataFrame(np.arange(10).reshape(2,5)) #矩阵转成数据框
df5
df4+df5#矩阵加法:先补齐显式index(新增索引对用值为NaN),得到相同结构后再进行计算
运行结果:
运行程序:
df6=df4.add(df5,fill_value=10)#默认填充的NAN改为固定值10
df6
s1=pd.Series(np.arange(3))#将数组改变为序列类型
s1
df6-s1#按行广播,先把行改为等长,行内不做循环补齐,只是一行一行计,不会跨行广播
df5=pd.DataFrame(np.arange(10).reshape(2,5))
df5
s1=pd.Series(np.arange(3))
df5-s1
运行结果:

运行程序:
df5=pd.DataFrame(np.arange(10).reshape(2,5))
s1=pd.Series(np.arange(3))
df5.sub(s1,axis=1)#逐行计算:df5-s1
df5=pd.DataFrame(np.arange(10).reshape(2,5))
s1=pd.Series(np.arange(3))
df5.sub(s1,axis=0)#逐列计算:df5-s1
df7=pd.DataFrame(np.arange(20).reshape(4,5))
df7
df7+2#所有数+2
print(df7)
print("df7.cumsum=",df7.cumsum()) #累计逐行求和
df7
df7.rolling(2).sum() #依次计算相邻两个元素之和,即本元素和上一个元素之和,默认按行
df7.rolling(2,axis=1).sum() #依次计算相邻两个元素之和,即本元素和上一个元素之和,按列
df7.cov()#协方差矩阵
df7.corr()#相关系数矩阵
import pandas as pd
df2 = pd.read_csv('bc_data.csv')
df2=df2[["id","diagnosis","area_mean"]][2:5]
df2.T#数据框的转置
运行结果:

7 大小比较运算
运行程序:
print(df6)
df6>5#判断元素是否大于5
print(s1)
df6>s1 #判断是否大于s1,按行
运行结果:

8 统计信息
运行程序:
import numpy as np
import pandas as pd
df2 = pd.read_csv('bc_data.csv')
df2=df2[["id","diagnosis","area_mean"]]
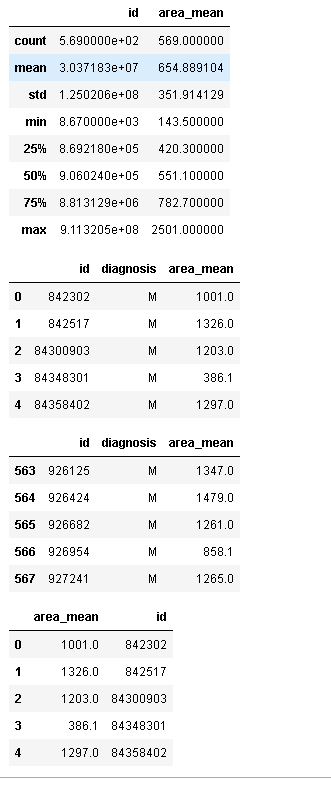
df2.describe()#描述性统计
dt = df2[df2.diagnosis=='M']#条件过滤,提取满足条件行
dt.head()
dt.tail()#显示最后几行
df2[["area_mean","id"]].head()#条件列前几行
运行结果:
9 排序
运行程序:
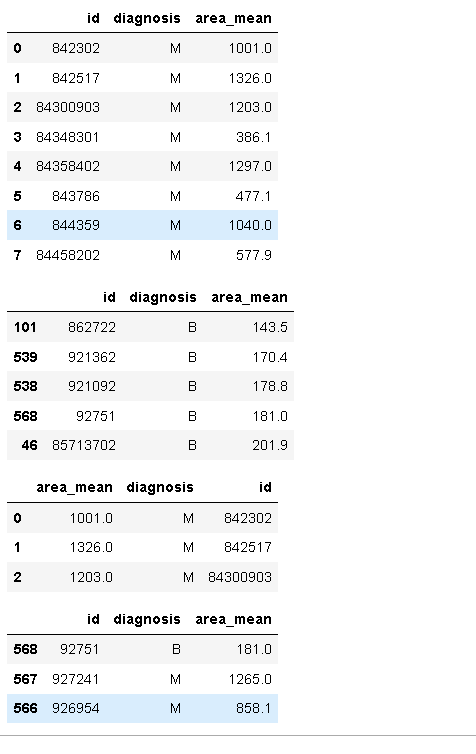
df2.head(8)
df2.sort_values(by="area_mean",axis=0,ascending=True).head()#行值排序
df2.sort_index(axis=1).head(3)#列值排序
df2.sort_index(axis=0,ascending=False).head(3)#index倒序
运行结果:
10 导入/导出
运行程序:
import os
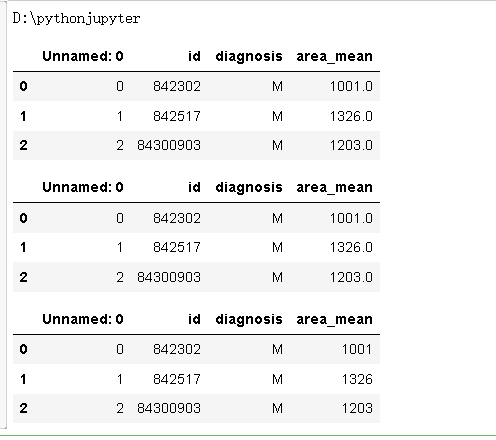
print(os.getcwd())#查看当前目录
df2.head(3).to_csv("df2.csv")#保存为csv文件
import pandas as pd
df3 = pd.read_csv('df2.csv') #读取文件
df3
df3 = pd.read_csv('df2.csv')#读取文件
df3
df2.head(3).to_excel("df3.xls")#保存为excel文件
df3 = pd.read_excel("df3.xls")#读取excel文件
df3
运行结果:
11 缺失数据处理
运行程序:
df3.empty#判断一个数据框是否有空数据集
np.nan-np.nan +1#nan可以参加运算
np.nan-np.nan
None+1 #【提示】报错信息为TypeError: unsupported operand type(s) for +: 'NoneType' and 'int',原因分析:None不能参加算数运算。
#None是Python基础语法中的特殊数据类型,不属于数值类型,不能参加算数运算
运行结果:
False
nan
nan
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[28], line 7
3 np.nan-np.nan +1#nan可以参加运算
5 np.nan-np.nan
----> 7 None+1
TypeError: unsupported operand type(s) for +: 'NoneType' and 'int'
运行程序:
import pandas as pd
import numpy as np
A=pd.DataFrame(np.array([10,10,20,20]).reshape(2,2),columns=list("ab"),index=list("SW"))
A
list("ab")#列表
B=pd.DataFrame(np.array([1,1,1,2,2,2,3,3,3]).reshape(3,3), columns=list("abc"),index=list("SWT"))
B
C=A+B #先补列索引,并补NaN
C
运行结果:
A.add(B,fill_value=0) #数据框相加,空值补齐NaN
A.add(B,fill_value=A.stack().mean()) #缺失值用均值补齐
A.mean()#按列计算均值
A.stack() #建立多级索引,计算一个数据框中所有index不同列均值
A.stack().mean()
C
C.isnull()#判断数据框每个元素为空值
C.notnull()#判断数据框每个元素不为空值
C.dropna(axis='index')#直接删除缺失值,axis='index':某行存在缺失值,直接删除改行
C.fillna(0)#用0填补空值
C.fillna(method="ffill")#向前填充
C.fillna(method="bfill",axis=1) #向后填充

12 分组统计
运行程序:
import pandas as pd
df2 = pd.read_csv('bc_data.csv')
df2=df2[["id","diagnosis","area_mean"]]
df2.head()
df2.groupby("diagnosis")["area_mean"].mean()#按照diagnosis分组计算area_mean均值
df2.groupby("diagnosis")["area_mean"].aggregate(["mean","sum","max",np.median])#按照diagnosis分组计算area_mean均值、求和、最大值、中值
df2.groupby("diagnosis")["area_mean"].aggregate(["mean","sum"]).unstack()#将关系转化为二级索引
def myfunc(x):
x["area_mean"]/=x["area_mean"].sum()
return x
df2.groupby("diagnosis").apply(myfunc).head()#分组自定义函数计算
运行结果: