#清华大模型公开课第二季 #OpenBMB
目录
1. The Evolution of Artificial Intelligence --History 人工智能的演变--历史
1.1 Definition of AI --定义
1.2 Conceptualization of AI -- 概念
1.3 Birth of AI as a Discipline
1.4 Development of AI
1.4.1 Symbolic Intelligence --符号智能(1950-1980)
1.4.2 Narrow Intelligence --专用智能
1.4.3 Genral Intelligence--通用智能
2. The Evolution of Artificial Intelligence --Present 人工智能的演变--现在
What to do —— 大语言模型要做啥??
How to do —— 大语言模型怎么做??
How to trianing and inference —— 大语言模型怎么训练和推理 ??
3. 模型训练的具体过程
3.1 Self-supervised Pre-training
3.2 Supervised Fine-Tuning(STF)
3.3 Reinforcement learning from human feedback(RLHF)
3.4 总结——LLMs 究竟怎么学习知识
3.5 LLMs的“emergent abilities”——大语言模型的涌现能力
3.5.1 In-context learning
3.5.2 Instruction following
3.5.3 Chain-of-thought
4. Potential and Challenges of LLMs
4.1 信息污染:
4.2 劳动力市场的变化
4.3 伦理和法律问题
5. 未来之路
笔者注:该篇笔记是清华大学 X Open BMB社区大模型公开课第二季的课程笔记,下面附有课程链接:
【清华大模型公开课第二季回归!全球顶级开源社区梦幻联动【每周更新中】】https://www.bilibili.com/video/BV1pf421z757?vd_source=9c952252ce8bcaca7d3380ab92c74afb
由于笔者也是初学者,后续也会继续跟进学习,欢迎大家与我进行探讨,如有错误,请不吝赐教!!
感悟:
通过对于这节课的学习,我更加系统全面的了解了大语言模型的前世今生,众所周知,当下,大语言模型正经历着快速迭代时期,可是我们应该一味的追求训练量的增大,模型参数的增大吗?
通过清华大学刘知远教授的大模型第一课讲授,我们可以知道,并不是这样的,可以类比于芯片领域的摩尔定律,通过对大模型近几年的迭代发展,我们可以观察总结出这样的规律:
大模型的知识密度每8个月就会增加一倍
4年前的1750亿参数的GPT3,我们现在只需要24亿参数就可以实现类似的功能
因此,对于大模型的提升,根本性的问题是提升知识密度
1. The Evolution of Artificial Intelligence --History 人工智能的演变--历史
1.1 Definition of AI --定义
人工智能是对计算机系统的应用,通过与计算机等学科的深度融合,使得计算机变得更加智能,让计算系统具备智能能力,像人一样行动和思考的学科。
1.2 Conceptualization of AI -- 概念
计算机科学和人工智能之父——阿兰图灵在1950年发表的一篇论文中提出,“Can machines think?”首次提出 了对于人工智能核心命题的思考。
Turing Test (Imtation game-模仿游戏)-图灵测试
1.3 Birth of AI as a Discipline
1956年,Dartmouth Workshop
1.4 Development of AI
人工智能的核心目标:使得机器具有完成复杂任务的知识
1.4.1 Symbolic Intelligence --符号智能(1950-1980)
-
现代句法理论(Noam Chomsky):面向人类语言的句法规则,从而帮助计算机更好的理解人类语言的相关成分,从而理解真正含义。
-
专家系统(Edward Feigenbaum):其中的一个重要模块就是知识库,其中涵盖了专家手工总结出来的一系列实质性知识和规则。
该阶段,知识库的构建需要专家按照特定的规则,通过自然语言或者其他编程语言进行手工总结,最终通过符号的形式将不同专业领域的知识进行表示。
挑战:1. 我们很难通过专家手工总结的方式,穷尽所有可能性。2. 很多任务的特殊和复杂性,使得专家很难通过特定规则进行描述。
1.4.2 Narrow Intelligence --专用智能
构建了一个自动化的知识提取的方案,只需自动从数据中进行学习,无需专家手动总结
挑战:我们必须预先定义一些任务,比如机器翻译的数据得到的模型,只能去做机器翻译,比如人脸识别的数据(如果只用了中国人的信息做数据标注),那么只能识别中国人的脸。所以,正如该时期的总结narrow(意为狭窄的),泛化能力比较差,只能完成指定的任务。
1.4.3 Genral Intelligence--通用智能
2018年,openAI 产出了GPT,Google 产出了BERT,unified model architectures for NLP tasks——自此产生了统一的对于NLP任务的模型结构
优势:Unlabeled data is cost-effective, easily accessible ; large-scale parameters facilitate the learning and storage of general knowledge
2. The Evolution of Artificial Intelligence --Present 人工智能的演变--现在
AGI: Artificial General Intelligence
从专用智能迈向通用智能,体现为3个转变:
-
针对不同领域的统一结构:从特殊领域架构转移到统一的Transformer架构
在2018年以前:
对于文本、语音或者其他的序列化的数据,我们使用Recurrent Neural Network (RNN)模型进行处理
对于图片、视频等二维的数据,我们使用卷积神经网络进行处理
对于结构化、半结构化的数据,会使用图神经网络进行处理

大模型时代下针对不同领域的架构转变
在2018年以后,对于不同类型的数据,都可以使用Transformer架构
-
针对不同任务的统一模型:从特定任务的小模型到统一的大模型
在2018年以前:
针对机器翻译任务,我们需要训练一个模型,模型的输入是一个语言,输出是另一个语言。
针对数学推理任务:我们输入数学问题,模型输出推理过程和结果。
2018年以后:
所有的任务都可以通过大模型进行解决。
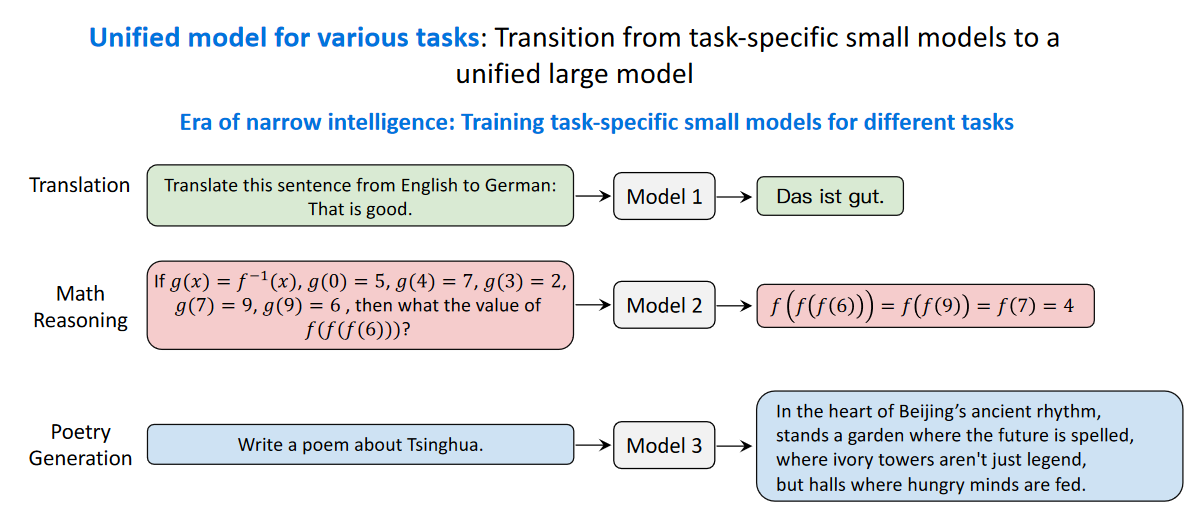
大模型时代下针对不同任务的模型转变
-
针对不同模态的统一模型:从不同的模型数据到被输入到大模型中的统一标记序列
不论是自然语言,图像,DNA 等等模态的数据,都可以通过大模型进行建模。
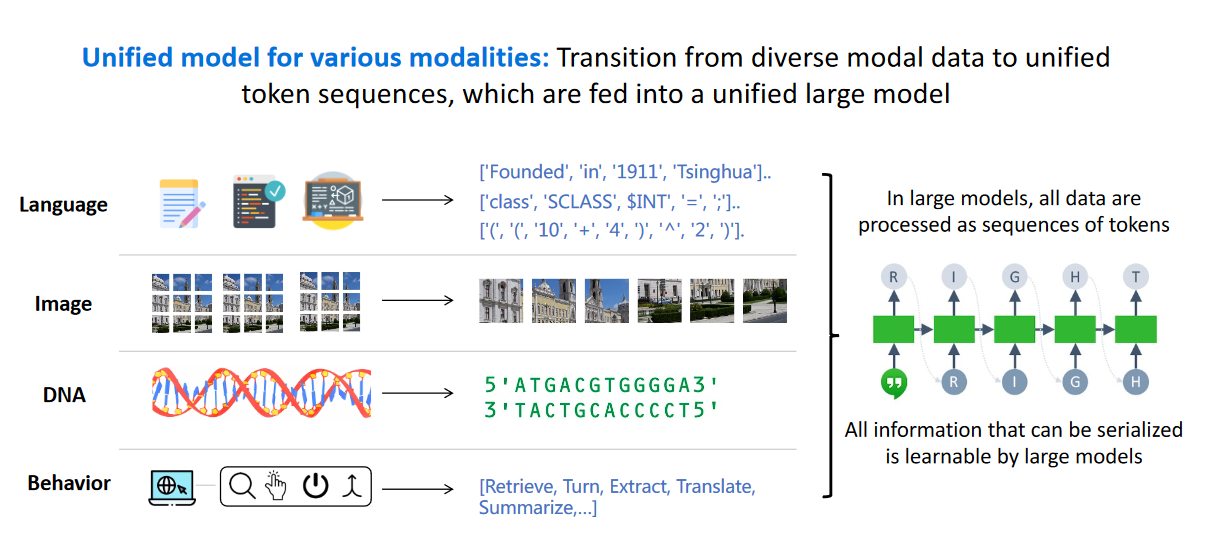
大模型时代下针对不同模态的模型转变
What to do —— 大语言模型要做啥??
Next Token Prediction--- 看到前面的词,要有能力去预测下面的词是什么。
autoregressive generation ---自回归生成
这里需要注意的是,并不是只依赖第一次我们给出的Token,而是不断包含生成的Token,使之也作为已知信息。
How to do —— 大语言模型怎么做??
对于不同的任务,例如,机器翻译,自动问答等,都可以看做是Next Token Prediction

How to trianing and inference —— 大语言模型怎么训练和推理 ??
使用互联网上收集到的,我们认为是正确答案的文本,作为大语言模型学习的对象,只要模型预测的Token 和标准答案不一样,我们就要更新模型的参数。
实际上,对于海量的训练集,不可能只有一种正确的输出,但是最终我们只需要一个输出,那就面临着一种概率分布的选择,比如,对于下图而言,我们输入Tsinghua University ,在我们的训练集中Next Token 会有三个输出,我们能做的,就是运用一定的方法,选择出最有可能的Next Token,也就是概率最大的。

3. 模型训练的具体过程
从自监督预训练——>有监督微调——>从人类反馈中学习
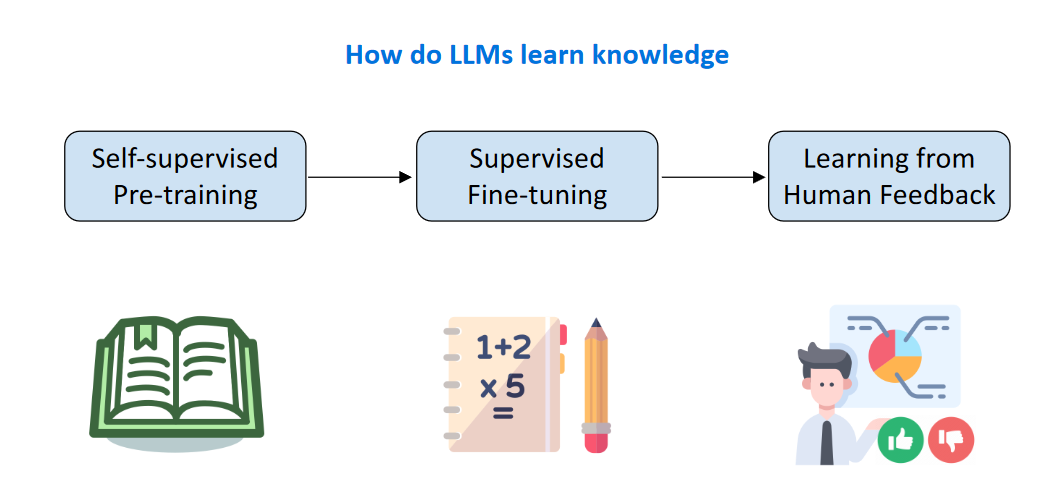
3.1 Self-supervised Pre-training
-
Self-supervised: 学习的数据不需要人工标注
-
Pre-training :有监督之前的训练
该阶段用尽可能多的高质量的数据进行Next Token Prediction,经过该阶段,模型可以生成完整、流畅的句法结构,但是也停留在机械地进行续写的状态,不能够理解问题的含义,也无法更好的利用学到的知识进行回答,也就是答非所问的情况。

3.2 Supervised Fine-Tuning(STF)
-
需要我们提供人工标注的问答数据进行微调
-
值得注意的是,当我们不希望模型回答负面问题时也给出引导性回答时,需要在微调问答数据中给出。
面临的问题是,显而易见,一个问题不可能只对应一个答案,当我们只做Next Token Prediction时,当发现给出的结果和训练集不一样是,我们就会调整参数,但是这个答案也有几率是正确的合理的。
3.3 Reinforcement learning from human feedback(RLHF)
我们不再给定一个固定的标准答案,而是给定一个输入,让模型产生多个输出,并不需要模型强制输出标准答案。而是根据Preforence的反馈,通过人工进行反馈,是对的还是错的。

3.4 总结——LLMs 究竟怎么学习知识

大语言模型如何学习知识——三个阶段
第一个阶段:自监督预训练:学习大量的不同领域的无标注数据
第二个阶段:有监督微调:充分利用高质量标注数据,学习如何理解人类自然语言的意图以及给出更高效的反馈
第三个阶段:反馈机制:输入人类对于模型偏好的反馈
3.5 LLMs的“emergent abilities”——大语言模型的涌现能力
(1)怎么出现的涌现能力:
主要是由于大规模的训练集和大规模的参数
(2)目前大语言模型具有怎样的涌现能力:
-
In-context learning
-
Instruction following
-
Chain-of-thought
3.5.1 In-context learning
我们可以输入一些小规模的案例,大语言模型可以从中学习到解决该任务的能力

3.5.2 Instruction following
对于输入的全新复杂指令(这里的全新指的是并没有在训练集中出现过的),大模型能够理解并执行它。

3.5.3 Chain-of-thought
不仅仅只是提供答案,还可以进行详细的步骤分解推导。

4. Potential and Challenges of LLMs
4.1 信息污染:
大语言模型可能会产生一些错误的信息,一旦进行传播,会造成严重的社会危害。

4.2 劳动力市场的变化

4.3 伦理和法律问题
比如说学术诚信,版权归属等

5. 未来之路
在集成电路领域,有一个神乎其神的定律,摩尔定律(1965):一个芯片的电路密度(计算能力),每两年会增加一倍
对于大模型而言,我们可以认为,需要不断提高的不是模型训练数据量,而是知识密度
对于2020年的GPT-3,是1750亿的参数,但是四年后,我们只需要24亿的参数便能实现近乎同等的效果,这是为什么呢?
这是因为大模型的知识密度,呈现着每8个月增加一倍的现象
三大战场:
-
人工智能科学化

-
智能计算系统
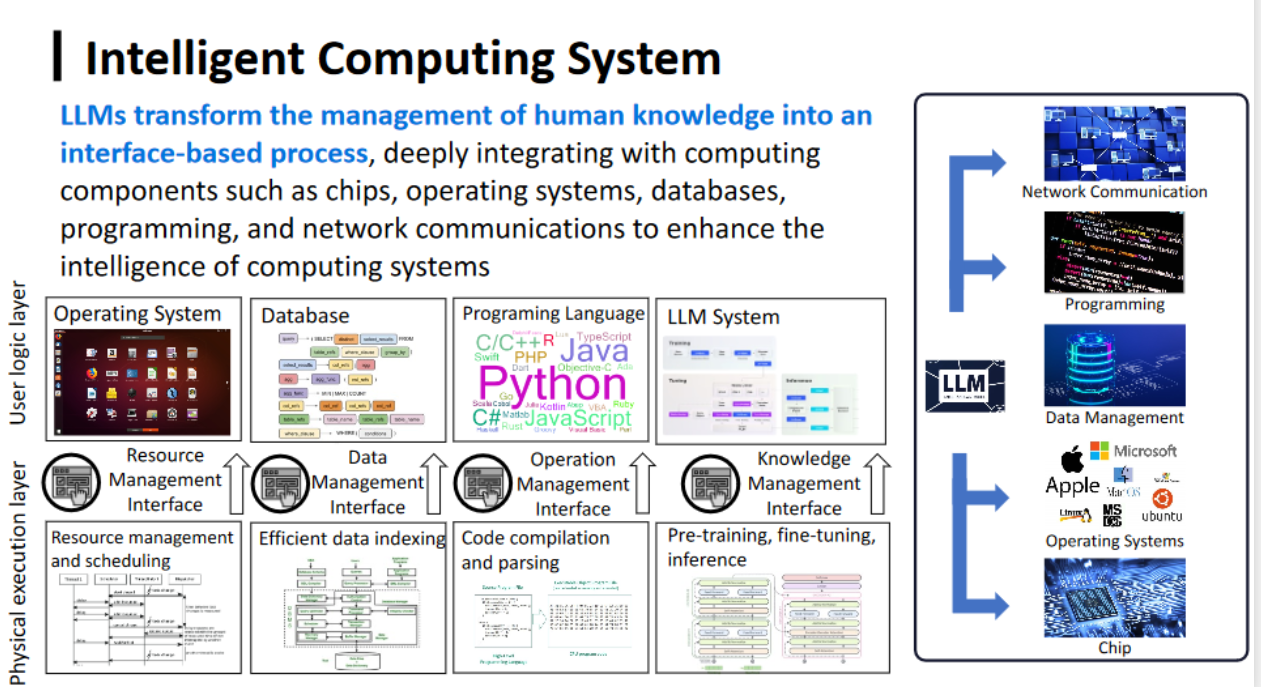
-
不同行业的广泛应用