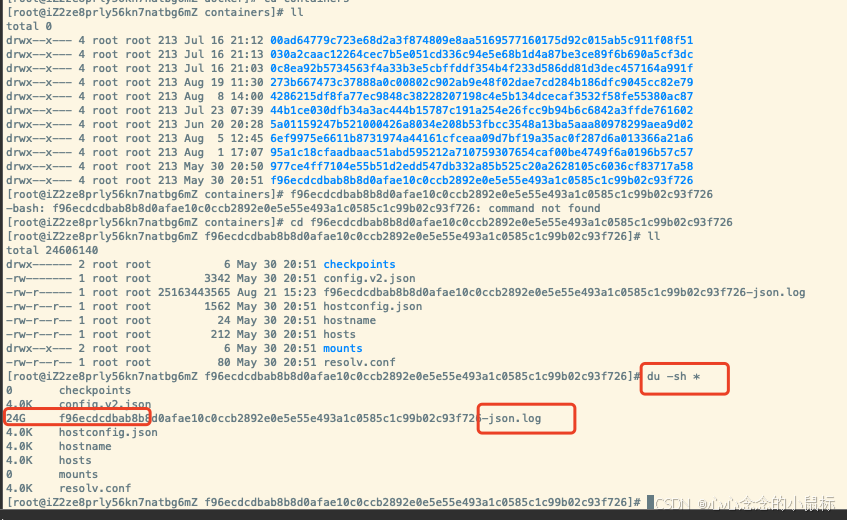
学习YOLO的过程中遇到了mAP指标,在网上看了很多关于mAP的讲解,不是很理解其计算过程,于是总结了各个帖子及自己的理解,给出mAP计算的规律,这样就能很好的记忆。
目录
一、P(精确率)、R(召回率)和F1 Score
二、PR曲线
三、AP和mAP
一、P(精确率)、R(召回率)和F1 Score
-
True Positive(TP): 预测对了。预测为正,实际为正。
-
False Negative(FN):预测错了。 预测为负,实际为正。
-
False Positive(FP): 预测错了。预测为正,实际为负。
-
True Negative(TN): 预测对了。预测为负,实际为负。(在目标检测问题中,由于模型通常不会明确标记非目标的所有背景区域,所以通常不会计算TN)
有T就是对,有F就是错。

P: Precision,精确率,也叫查准率。预测为正类的样本中确实为正类的比例。
R:Recall,召回率,也叫查全率。所有实际正类中,有多少正类被预测出来。
F1 Score:是精确率和召回率的调和平均数,是一种兼顾精确率和召回率的综合指标。
举个例子:一张图片中总共有10只猫咪,模型显示检测到了5只猫咪,但是检测到的其中只有4个是猫咪,另外一只实际上是小狗。
此时TP=4(检测到的4只猫咪是真猫咪),FN=6(没能检测到剩下的真实的6只猫咪), FP=1(误将1只小狗检测成小猫)。
此时P = 4/5 = 0.8,R = 4/10 = 0.6,F1 Score = 2X(0.8X0.6)/(0.8+0.6) = 0.686。
一般来说,P 和 R 是相互制约的,一个越高另一个就越低。
因为查准率只关注预测出的正类中有多少是真的,而查全率关注实际上所有的正类中模型检测出来多少。如果我的模型只关注查全率不关注查准率,我将所有物体都识别为正类,那么确实所有小猫都检测到了,但是不准确。
二、PR曲线

当你训练好一个分类算法后,它会对每个输入样本给出一个置信度评分,这个评分表示该样本是正类的概率。例如,算法认为样本A有99%的可能性是正类,而样本B只有1%的可能性是正类。
我们设定一个阈值,比如50%,来决定哪个样本被划分为正类,哪个样本被划分为负类。如果一个样本的置信度评分超过50%,我们就把它看作是正类;如果低于50%,则视为负类。
然后,可以按照置信度评分对所有样本进行排序。从置信度最高的样本开始,每次选取一个样本作为新的阈值。例如,首先选择置信度最高的样本A作为阈值,那么所有比样本A置信度高的样本都被认为是正类,其他样本则是负类。接着,计算当前状态下模型的精确率和召回率。
接着,继续选择下一个置信度稍低的样本B作为阈值,再次计算精确率和召回率。重复这个过程,直到遍历完所有样本。这样,就得到了一系列的精确率和召回率值,每个值对应着一个不同的阈值。
最后,把这些精确率和召回率值连接起来,就形成了一个 PR 曲线。这条曲线显示了随着阈值的变化,模型的精确率和召回率是如何变化的。
随着阈值的下降,recall值是递增的(但并非严格递增),因为实际为正类的对象会越来越多的被检测为正类,不会减少。而精确率precision并非递减,而是有可能振荡的,虽然正例被判为正例的变多,但负例被判为正例的也变多了,因此precision会振荡,但整体趋势是下降。
三、AP和mAP
虽然 PR 曲线提供了关于模型性能的直观信息,但它并没有提供一个单一的数值来概括整个曲线的表现。
平均精度(Average Precision, AP)平均精度是一种统计量,AP 是 PR 曲线上各点的精确率的平均值,每个精确率值乘以其对应的召回率的增量。。

口语化解释就是:
通过选取每个recall及其对应的precision,绘制出PR曲线。然后,对于每个recall值,计算下一个recall与当前recall之间的差值,并乘以从当前recall到之后的所有recall对应的最大precision值。重复这一过程直到遍历所有recall值,将这些值相加就得到了某个类别的AP (Average Precision)。(recall相同的点去precision最高的点)
举个图中特殊的点(框起来那个),此时下一个recall为0.71,当前recall为0.57,从当前recall开始(包括当前recall)一直到最后的recall中对应的precision最高为0.71,所以为(0.71-0.57)*0.71。
mAP:得到了不同类别的AP,取这些AP的平均值就是mAP。