文章目录
-
- 一.主成分分析简介
-
- 1.1 数学背景与维度诅咒
- 1.2 PCA的定义与应用
- 二.协方差矩阵——特征值和特征向量
- 三.如何为数据集选择主成分数量
- 四.特征提取方法
- 五.LDA——与PCA的区别
- 六.PCA的应用
- 七.PCA在异常检测中的应用
- 八.总结
一.主成分分析简介
1.1 数学背景与维度诅咒
主成成分分析(PCA)是一种广泛使用的算法,用于从高维数据中提取主要特征,以便更有效地用于机器学习(ML)模型。从数学上讲,维度是指在空间中指定一个向量所需的最少坐标数。在高维空间中计算两个向量之间的距离需要大量的计算资源,因此随着维度的增加,计算复杂性迅速提升,这就是所谓的“维度诅咒”(见图1.1)。这种现象使得许多机器学习算法的效率难以提高。随着数据维度的增加,数据的稀疏性增加,计算距离和密度的努力呈指数级增长。从理论上讲,维度的增加通常会增加大数据集中的噪声和冗余。因此,PCA被广泛应用于应对高维问题中的复杂性。

PCA起源于线性代数,基本上是一种数据预处理方法,通过将数据投影到较低维度的子空间中,保留数据的主要信息,同时减少数据集中的冗余特征。这种技术广泛应用于高维数据的可视化、降维和分类任务中。PCA遵循主轴定理,其主要目标是通过寻找正交基来优化数据表示,按重要性或方差对维度进行排序,丢弃次要的维度,并集中关注主要的无关成分。
1.2 PCA的定义与应用
PCA是一种无监督方法,用于减少高维数据集的特征数量。通过矩阵分解(或分解)来将未标记的数据集减少为其组成部分,然后根据方差对这些部分进行排序。代表原始数据的投影数据成为训练ML模型的输入。
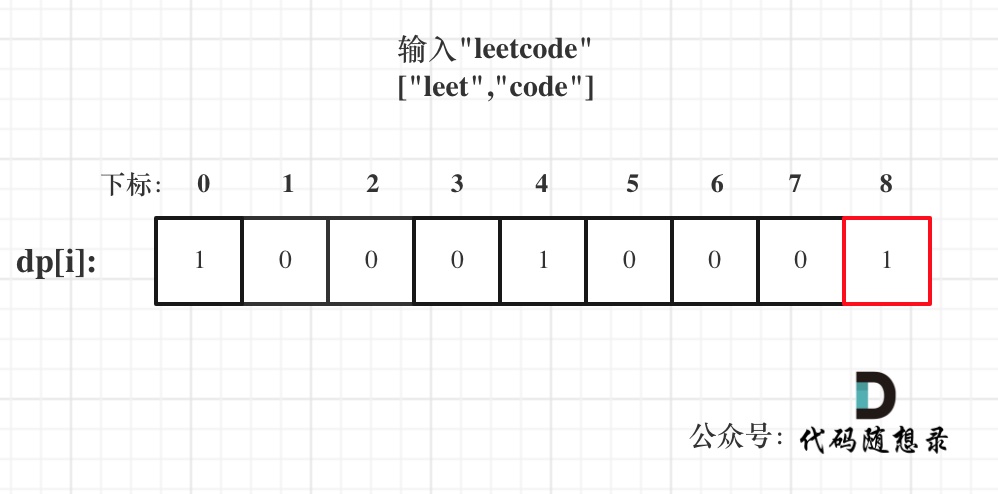
PCA定义