向量嵌入将数据转换为数学方程,赋予了人工智能的认知能力,但它们是如何使机器能够“学习”和“成长”的呢?
向量嵌入是什么?
向量嵌入这玩意儿,其实就是给数据穿上一件数学的外衣,让它们之间的关系和相似之处变得一目了然。这样一来,我们就能对这些数据进行数学操作和比较了,这在文本分析或者推荐系统这些地方特别有用。
现在大家聊生成性人工智能聊得挺多的,但背后的原理听起来可能有点高大上。今天咱们就来说说这里面的一个关键点,也就是向量嵌入,它可是让人工智能有了基本的学习能力,让机器学习模型不断进步的秘诀。
向量嵌入嘛,简单说就是用数学方程来表达数据的技巧。谷歌是这么定义的,把数据看成是n维空间里的点,相似的点就挨得近。懂数学的人听起来可能觉得没啥,但对于不太熟悉数学的人来说,可能就有点云里雾里了。

理解向量嵌入以及数据的数学表示
好,咱们换个说法来聊聊这个事儿。想象一下,你手头上有一碗你超爱的M&M巧克力豆,结果你家那个小调皮蛋儿,把一碗彩虹糖(Skittles)也给掺和进来了。可能有人不太了解这两种糖,它们都是那种五颜六色的糖豆,外表看起来差不多,但一个是巧克力味儿的,另一个是柑橘味儿的,这两种味道混在一起可不太搭。所以咱们得把这糖豆给分开,咱们按种类和颜色来分。绿颜色的M&M豆一堆,绿颜色的彩虹糖一堆,红颜色的M&M豆和红颜色的彩虹糖又各自一堆,以此类推。分完以后,咱们就能看到按颜色分好的M&M豆和彩虹糖,一目了然,这样新来的糖豆一看就知道该归到哪一堆了。
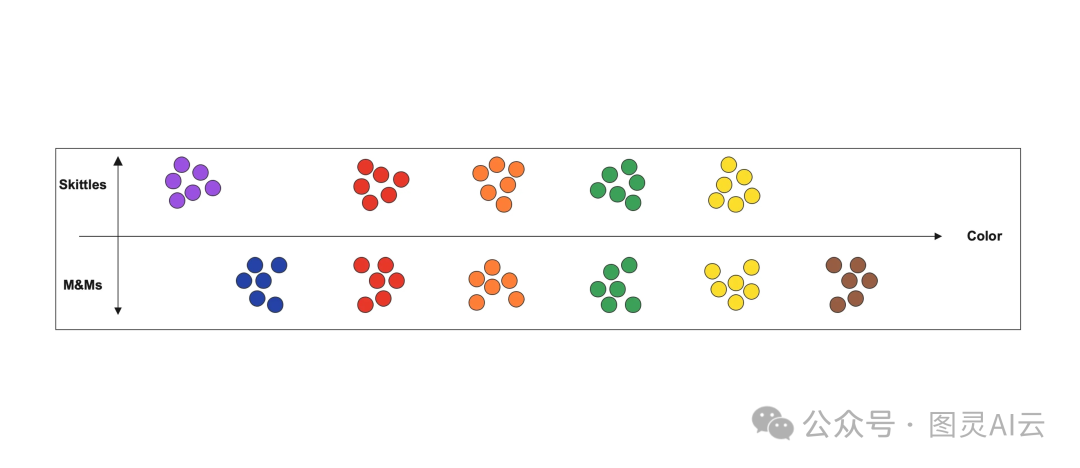
分糖果的时候,咱们实际上已经开始在弄出一些模式和分组了,这样一来,不同糖果之间的关系就更容易看出来,而且一旦发现新的糖果,我们也能迅速找到它应该归到哪一堆。向量嵌入就是这么个事儿,它把这种视觉上的排列转换成数学上的位置表示。简单来说,就是给每个位置一个特定的数值。
就像咱们给每个糖果根据它们的特性打分,比如它们的颜色、形状或者大小,然后根据这些分数,我们就知道每个糖果在数学上的位置了。这样一来,不管是老糖果还是新糖果,咱们都能快速地给它们找到合适的位置。
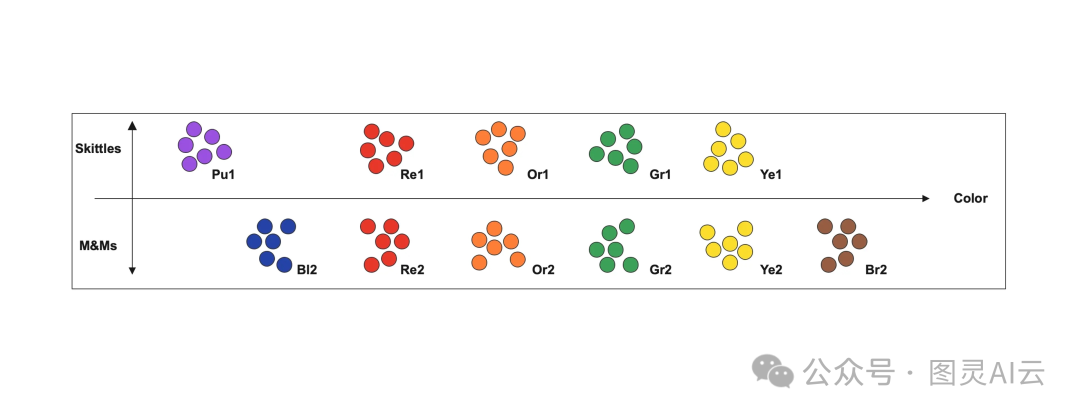
给糖果分类这事儿,其实跟向量嵌入有异曲同工之妙。你看,我们可以根据糖果的特性,比如颜色、口味,给它们一个个打分,这就像是给每颗糖果一个独特的数学标签。然后,根据这个分数,我们就知道每颗糖果应该放在哪个位置,这就是向量嵌入的核心思想,虽然实际上它比这个要复杂得多。
这种数学上的表示方法,其实就是人工智能认知能力的基础。就像人的大脑有无数神经元一样,人工智能系统通过这些嵌入来处理信息,做出决策。单个嵌入可能不起眼,但当它们数量众多,相互关联时,就能形成强大的认知网络。而当我们把这些嵌入集中存储,能快速访问和处理时,这就形成了向量数据库。
要想深入理解向量嵌入,以及它们对生成性人工智能的巨大贡献,我们就得知道它们能用来干什么,怎么创建它们,以及它们能表示哪些数据类型。简单来说,向量嵌入就是人工智能的大脑,帮助它理解和处理各种信息。
示例:使用向量嵌入
向量嵌入这玩意儿,用起来确实有点挑战,主要是因为它几乎啥数据都能表示。咱们平时在计算机科学或者编程里用的数据类型,比如字符、整数、浮点数,都是用来表示特定形式的数据。但这些类型,说白了,它们只能表示它们擅长的那类数据。
向量数据类型看起来就像是数组的升级版,能多维扩展,还能在图上指个方向。但向量真正厉害的地方在于,它能让你把任何数据都变成向量,而且这些向量还能相互比较,找出它们在多维空间里的相似之处。
咱们这么说可能还是有点抽象,感觉像是一锅乱炖。要真搞懂向量是啥,怎么用,就得聊聊Word2Vec了,这可是谷歌2013年鼓捣出来的技术。
Word2Vec这技术,就是把单词变成向量,然后用这些向量在图上画出它们的相似关系,比如同义词啥的,都能在图上看出来是一窝儿的。

Word2Vec这技术,其实就是给每个词都弄一个n维空间里的坐标,或者说,一个向量。咱们的例子里,用了5个维度来表示,但真正的向量嵌入可能有几百甚至几千个维度,这玩意儿太多了,咱们人脑根本想象不出来。但是,就是这些高维数据,让机器学习模型能把这些数据点联系起来,画出来,用来做语义搜索或者向量搜索这些高级功能。
在咱们说的这个图表里,你能看到,有些词因为意思差不多,就自然而然地聚在一块儿了。比如"bunny"(小兔)和"rabbit",它们俩的关系就比跟"hamster"(仓鼠)近多了。而"bunny"、"rabbit"和"hamster"这三个词,要是看向量属性的话,它们又比跟"hutches"关系近。就是这种在n维空间里的方向感,让神经网络能处理出最近邻搜索这种功能。
向量嵌入的应用是什么?
咱们来聊聊向量嵌入怎么用。想象一下,你在看一个你喜欢的电视节目,对吧?如果我把这个节目的各种特点变成向量,然后把其他所有节目的特点也都变成向量,那我就能找出跟你现在看的节目在某些方面很像的其他节目。你看的节目越多,机器学习系统就越懂你,它就能根据你的喜好,给你推荐更多你可能喜欢的节目。
再说说搜索,比如谷歌的反向图片搜索。用向量来做这个特别快,特别方便。你上传一张图片,搜索引擎把它转换成向量,然后在这个n维空间里找到对应的位置,还能告诉你关于这张图片的其他信息。
向量嵌入的用途多得很。一旦数据变成了向量,你就能做欺诈检测啊,异常检测啊。在机器学习模型里,你可以处理数据,转换数据,做映射。聊天机器人也能用上这个,它们可以读产品文档,然后用自然语言跟用户交流,帮用户解决问题。
向量嵌入是机器学习和人工智能的核心。数据一旦变成向量,就得找个地方存起来,这个地方得能扩展,性能还得好,这就是向量数据库。数据一旦存成向量,那它的用处就大了,能支持各种各样的向量搜索场景。
创建向量嵌入
向量嵌入这事儿,其实就是把数据点转化成高维空间里的向量。咱们用3D空间来想象这个事儿,比较容易懂。比如说,咱们有三个词:"cat"(猫)、"duck"(鸭子)和"mudskipper"(泥跳鱼)。咱们要看看这些动物是走路、游泳还是飞。
拿"cat"这个词来说吧。猫嘛,主要是走路,那咱们就给走路这个特性打个3分;猫也能游泳,不过大多数猫都不喜欢水,那咱们就给游泳打个1分;至于飞,咱们没听说猫还能飞的,那就给飞行打个0分。
这样,"cat"这个词在咱们这个小模型里就变成了一个向量:(Swim - 1, Fly - 0, Walk - 3)。同样的方法,咱们也能给"duck"和"mudskipper"打分,然后它们也会变成自己的向量。这些向量就能在3D空间里有自己对应的点,这就是向量嵌入的基本想法。
所以猫的数据点是:
Cat: (Swims - 1, Flies - 0, Walks - 3)
如果我们对单词"duck"和"mudskipper"做同样的事情,我们得到:
Duck: (Swims - 2, Flies - 2, Walks - 2)
Mudskipper: (Swims - 3, Flies - 0, Walks - 1)
根据这个映射,我们可以将每个单词绘制到一个三维图表中,所创建的线就是向量嵌入。Cat [1,0,3],Duck [2,2,2],Mudskipper [3,0,1]。
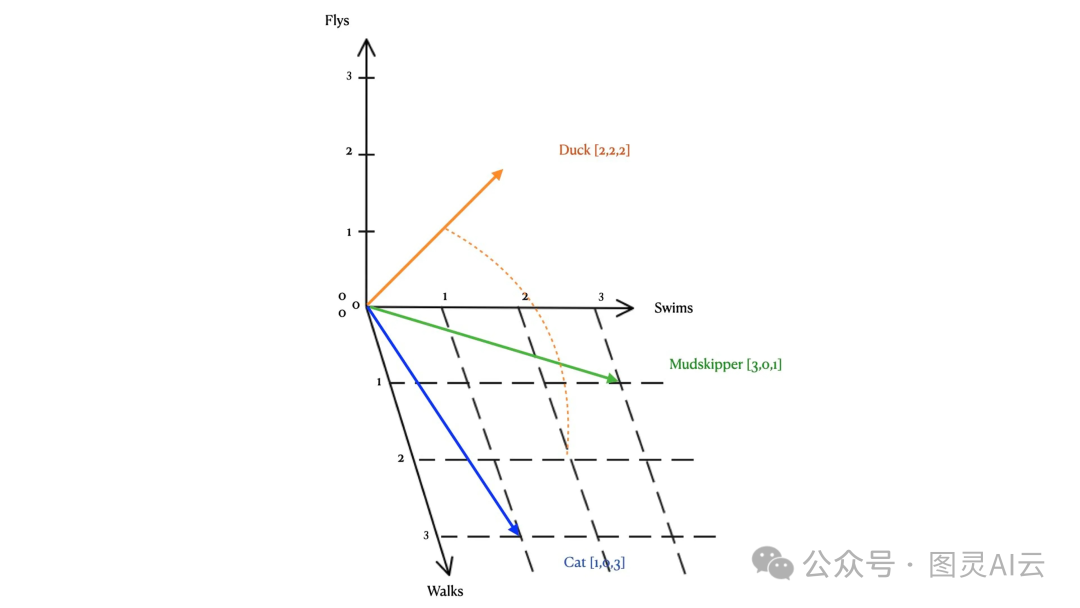
一旦我们所有的离散对象(单词)都转换为向量,我们就可以基于语义相似性看到它们彼此之间的关系有多密切。例如,很容易看出所有三个单词都绘制在z轴上,因为所有这些动物都能行走。当你在图的平面上查看向量表示时,机器学习等事物的真正力量就显现出来了。例如,如果我们比较这些动物在行走和游泳方面的表现,我们可以看到猫与鸭子的关系比与泥跳鱼更近。
现在再来看个例子,图上图,用的是3D空间,挺直观的。但真正的向量嵌入,那可复杂多了,它们能在一个N维的空间里。这么多的维度,机器学习和神经网络就能用来做决策,还能搞出那种分层的最近邻搜索。
说到创建向量嵌入,有两种招儿。第一种是特征工程,这得用到专业知识,得把那些能定义向量不同点的特征给量化了。第二种方法,就是用深度神经网络来训练模型,把对象转换成向量。现在一般都爱用训练模型这个方法,因为特征工程虽然能深入理解问题,但太花时间和钱了,不好扩展。训练模型呢,能一下子生成一大堆高维的向量,成千上万的维度,给力得很。
预训练模型
预训练模型,就是那种已经训练好的模型,它们能解决一些普遍的问题,咱们可以直接拿来用,或者在它们的基础上调整一下,去解决更复杂或者特定领域的问题。这类模型对各种类型的数据都有,比如文本、图像、音频等等。
比如说,BERT、Word2Vec和ELMo这些,都是处理文本数据的预训练模型。它们已经被训练得能处理大量的文本信息,不管是单词、句子,还是一整段文字或者整个文档,都能转换成向量嵌入。
而且啊,预训练模型不只限于文本。图像和音频数据也有类似的预训练模型。比如Inception,它用的是卷积神经网络(CNN),还有Dall-E 2,用的是扩散模型。这些都是现成的工具,帮我们处理图像和生成新的图像内容。
向量嵌入可以嵌入哪些类型的事物?
向量嵌入厉害的地方就在于,它能把各种各样的数据都变成向量形式。现在用得特别多的,就是文本和图像嵌入。比如,用GPT-4这种工具搞出来的自然语言处理(NLP)聊天机器人,它们就是用文本嵌入来理解人说的话。还有像Dall-E 2这种能生成图片的处理器,它用的就是图像嵌入来理解图像信息,然后创造出新的图像。这种技术让机器能更好地理解和处理人类的语言和视觉内容。
文本嵌入
文本嵌入这东西,其实挺直观的,咱们大部分例子都是基于它。它就是从一大堆文本数据开始,比如Word2Vec这种大型语言模型,它就用维基百科这种海量的文本数据来训练。不过,文本嵌入可不光能处理这种大部头,它对任何文本数据都行,不管是啥,都能用来快速找到意思相近或者相似的内容。
比如,你想搞个聊天机器人,专门回答用户对你产品的问题,那你可以把产品手册啊、FAQs啊这些文本做成嵌入,让机器人能根据用户的问题给出答案。或者你是个烹饪爱好者,手里有一大堆食谱,你也可以用这些食谱文本搞个嵌入,然后根据你厨房里现有的食材,找出可以做的菜。文本嵌入的好处就是,它能把那些散乱的单词、句子、文档,转换成有条理的、结构化的数据。
图像嵌入
图像嵌入和文本嵌入一样,都能把图像的各个方面给表达出来。不管是一整张图,还是图里的一个像素点,图像嵌入都能帮我们把图像的特征分好类,然后用数学的方式表达出来。这样,机器学习模型就能分析这些特征,或者像Dall-E 2这样的图像生成器就能用这些特征来创造新的图像。
说到图像嵌入最常见的用途,一个是做图像分类和反向图片搜索。比如,你拍了张后院里的蛇,想知道这蛇是什么品种,有没有毒。如果你有个包含各种蛇的大数据集,你就可以把你的蛇图输入到这个蛇的向量数据库里,找出和你的图最接近的那个。通过这种语义搜索,你就可以得到最接近的那条蛇的所有“属性”,从而知道它是什么蛇,用不用提防。
还有一个用图像嵌入的例子,就是像Google Magic Photo Editor这样的自动图像编辑工具。这个工具可以用生成性AI来编辑图片,比如把背景里的人给移走,或者调整图片的构图,让图片看起来更好。
产品嵌入
向量嵌入在推荐系统里也大有用处。不管是电影、歌曲还是洗发水,啥玩意儿都能用向量嵌入来表示。电商网站用这个技术,能根据你搜的东西、点的链接、买的习惯来观察你的行为,然后给你推荐那些意思相近的东西。
举个栗子,比如说你逛你最爱的网店,给你新来的小狗挑东西。你往购物车里加了狗粮、狗链、狗碗和水碗。然后你又搜了网球,因为你想让小狗有玩具玩。但你要的是网球呢,还是狗玩具呢?如果你在宠物店里,店员一看就知道你其实是想要狗玩具,不是网球。产品嵌入就能做到这一点,它通过分析你的购物行为,用每个产品生成的向量来理解你其实是在找什么——在这个例子里,就是狗玩具,不是网球。
文档嵌入
文档嵌入这玩意儿,就是把文本嵌入的概念给放大了,用在更大的文本上,比如一整份文件或者一堆文件的集合。这种嵌入能抓住文件的整体意思,让咱们能做文件分类、聚类,还有信息检索这些活儿。比如,在公司里头,用文档嵌入可以帮助咱们根据文件的意思,从一大堆内部文件里找出需要的来。在法律行业里,也能用这个技术来分析和比较不同的法律文件。
音频嵌入
音频嵌入就像是给声音穿上一件向量的衣服。这个过程就是从音频信号里头提取出各种特征,比如音高、音色、节奏这些,然后用一种机器学习模型能处理的方式把它们表达出来。用到音频嵌入的地方可多了,比如语音识别,就是让机器能听懂你在说什么;还有根据音乐的声音特征来推荐歌曲;甚至还能从人说话的声音里头分析出情绪来。开发那些能听懂你命令的智能助手,或者根据你听歌的历史来推荐新歌的App,都离不开音频嵌入这个技术。
句子嵌入
句子嵌入就是把每个句子变成一个向量,这样就能抓住句子的意思和它用的环境。这在分析人的情绪时特别有用,因为有时候一句话里的感情很微妙,得仔细体会。句子嵌入还能让聊天机器人更懂人话,能更准确地理解用户在说什么,然后给出更好的回答。还有,在机器翻译的时候,句子嵌入也很关键,它能保证翻译出来的内容不仅意思对,而且还能保持原来句子的上下文。
词嵌入
词嵌入,这可是文本嵌入里最细致的活儿了,就是把单个词转换成向量。这样一来,词和词之间的那种微妙关系,比如谁是同义词、谁又是反义词,还有它们在不同上下文中怎么用,都能被捕捉到。这些嵌入在自然语言处理的各种任务里特别重要,像是给文本分类、建立语言模型或者生成同义词等等。
而且啊,词嵌入在搜索引擎里也很有用,它能帮助搜索引擎更好地理解你搜的词到底啥意思,然后给你提供更贴近的搜索结果。简单来说,词嵌入就是让机器更懂人话,让信息处理更精准。