0. 前言
本次主要分享之前看的两篇将自注意力机制self-attention应用在视觉感知任务的文章,分别为LRNet和Stand-alone self-attention。为了深化读者的理解,本文提供了较为详细的中文注释的代码。
首先了解一下这两篇文章的背景,其都是在Vision Transformer(ViT)提出之前将transformer应用在感知任务上的尝试。尽管这些方法没有取得像ViT那么大的关注度,其后续的影响也较为深刻。
之前的内容中,我们就ViT模型也做了较为详细的分享。具体链接如下:
- 【Transformer系列】Vision Transformer (ViT)模型解析
感兴趣的小伙伴们可以重温一下!ViT的设计可谓大道至简,而本文将介绍的两篇工作的网络设计较ViT可能更复杂一些。
论文名《Local Relation Networks for Image Recognition》
发表:ICCV 2019
所属领域(关键词):视觉transformer,local relation
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
 ### 1.动机和创新
### 1.动机和创新
人类具有通过有限的手段“看到无限世界”的非凡能力。这是通过从一组有限的低级视觉原语出发,创造性地组合出无限的高级视觉概念来实现的,进而形成对观察场景的理解。
在计算机视觉中,这种组合行为可以通过构建卷积神经网络中的层次化表示来近似实现,不同层次代表不同级别的视觉元素。低层提取基本元素如边缘,中间层组合这些基本元素形成物体部分,高层则表示整个物体。
尽管卷积层可以构建一个层次化的表示,但其将低级元素组合成高级实体的机制在概念推理方面被视为高度低效。卷积层更像是模板,通过卷积滤波器权重在空间上聚合输入特征,而不是识别元素如何有意义地结合在一起。
卷积在训练之后,应用固定的权重,而不管视觉输入的任何改变。
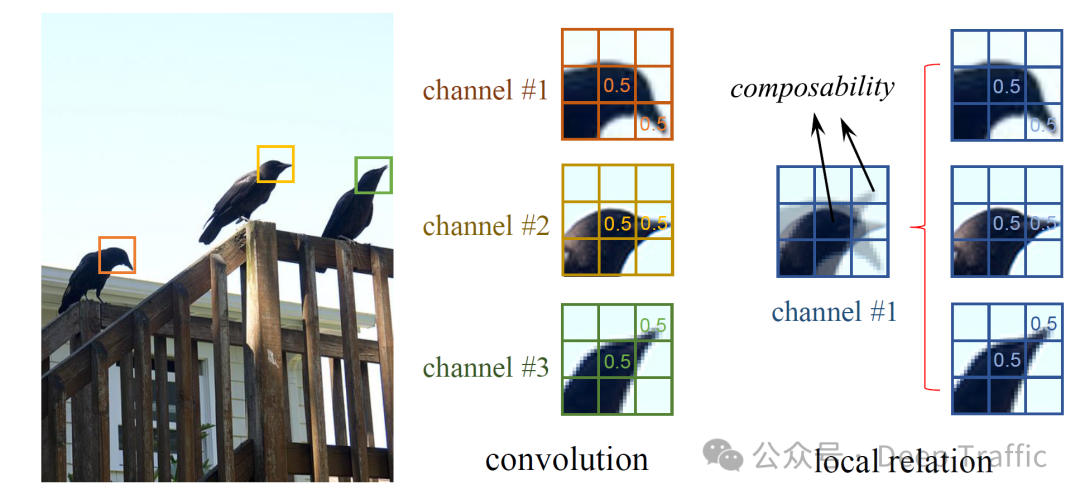
如图,在鸟的眼睛和嘴之间空间是多变的,用固定卷积核的卷积来表示需要3个channel,而如果可以在局部区域内的视觉元素之间自适应地推断出有意义的组合结构,并基于局部像素对的可组合性调整聚合权重,则只需要一个channel即可。
为了实现这一点,本文提出了local relation layer(局部关系层),与使用固定聚合权重的卷积层不同,这个新层基于局部像素对的可组合性(Composability)调整聚合权重。通过学习如何在局部区域内自适应地组合像素,从而构建一个更有效和高效的组合层次结构。
由于这种局部关系层可以直接替换深度网络中的卷积层,几乎不增加额外开销。作者开发了一种名为局部关系网络(Local Relation Network, LR-Net)的网络架构,该架构在ResNet的基础上通过堆叠残差块来优化非常深的网络。
需要提到的是,上面提到的可组合性(composability)是指在视觉元素(如像素)之间根据它们的特征在一个学习到的嵌入空间中的相似性来动态确定它们是否可以组合在一起的能力。简单来说,可组合性是衡量两个视觉元素(比如像素)之间能否根据它们的特征被有效组合的一种度量。这种度量不是静态的,而是通过学习得到的,能够根据元素特征的相似性自适应地调整。
本文是VIT(Vision Transformer)提出前,研究者将transformer和视觉任务融合的一次尝试。
2.思路和方法
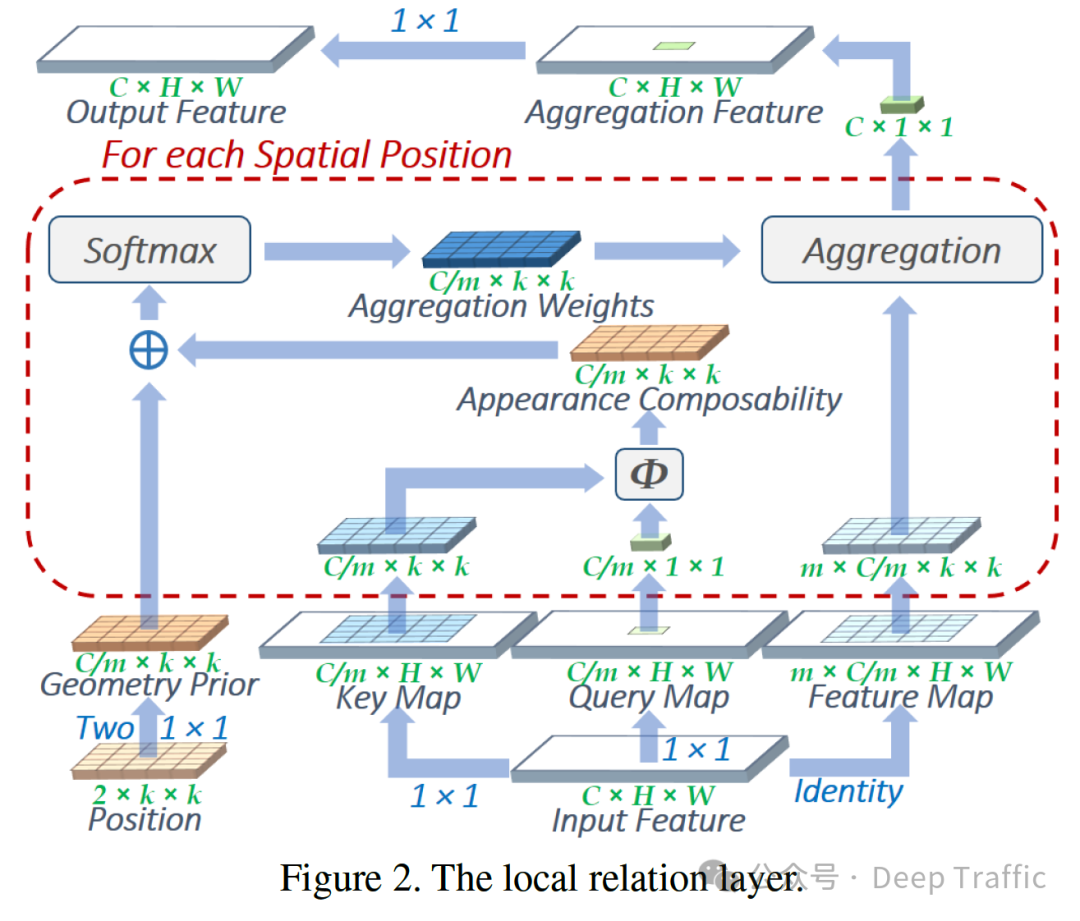
和我们知道的self-attention不同的是(key的选取不再是全图所有像素/cell,而是以query为中心的一个区域中所有的像素,大小为)。local relation layer(局部关系层)具体的实现如下:
-
输入Input Feature,分别通过一个1×1大小的卷积核,得到Key Map和Query Map,通道数为,这里的可以视为注意力头的个数。
-
对于Query Map中的每一个位置,在Key Map中提取出一个以该点为中心,的区域,然后对应像素点相乘,得到Appearance Composability,其大小为。
-
构建几何先验值Gemotry Prior为Appearance Composability提供位置/几何信息。首先构建的相对位置。这里的2可以认为其中一层表示坐标,另一层表示坐标。然后将这个的Position经过两个1×1大小的卷积层,得到Geometry Prior,其大小为。中间使用ReLU激活函数。作者发现,使用该小型网络来间接计算几何先验值比直接学习这些值更有效,特别是当邻域大小较大时。这可能是因为小型网络将相对位置视为度量空间中的向量,而直接学习方法则将不同的相对位置视为独立的实体。这样的向量表示允许模型更好地理解和利用空间关系。
-
将Geometry Prior和Appearance Composability相加,然后经过Softmax,得到某query位置特定的参数Aggregation Weights,其大小为。
-
对Input Feature提取出对应的一个的区域(value),然后与Aggregation Weights进行参数聚合,即对范围进行加权平均操作,最终得到该点的结果,大小为。
-
遍历所有的query的空间尺度(大小为),聚合成Aggregation Feature,其大小为。
-
最后将其经过一个1×1的卷积层,得到Output Feature,其大小为C×W×H
local relation layer(局部关系层)具体的实现代码如下:
import torch
# 几何先验模块
class GeometryPrior(torch.nn.Module):
def __init__(self, k, channels, multiplier=0.5):
super(GeometryPrior, self).__init__()
# 初始化参数
self.channels = channels # 通道数
self.k = k # 局部区域的大小
# 初始化位置信息,范围在-1到1之间
self.position = 2 * torch.rand(1, 2, k, k, requires_grad=True) - 1
# 两个1x1卷积层用于处理位置信息
self.l1 = torch.nn.Conv2d(2, int(multiplier * channels), 1)
self.l2 = torch.nn.Conv2d(int(multiplier * channels), channels, 1)
def forward(self, x):
# 通过两个卷积层处理位置信息,使用ReLU激活函数
x = self.l2(torch.nn.functional.relu(self.l1(self.position)))
# 调整输出形状
return x.view(1, self.channels, 1, self.k ** 2)
# Key和Query映射模块
class KeyQueryMap(torch.nn.Module):
def __init__(self, channels, m):
super(KeyQueryMap, self).__init__()
# 1x1卷积层用于生成Key和Query映射
self.l = torch.nn.Conv2d(channels, channels // m, 1)
def forward(self, x):
# 应用卷积层
return self.l(x)
# 外观可组合性模块
class AppearanceComposability(torch.nn.Module):
def __init__(self, k, padding, stride):
super(AppearanceComposability, self).__init__()
# 初始化参数
self.k = k # 局部区域的大小
# Unfold操作用于提取局部区域
self.unfold = torch.nn.Unfold(k, 1, padding, stride)
def forward(self, x):
key_map, query_map = x
# 提取Key和Query的局部区域
key_map_unfold = self.unfold(key_map)
query_map_unfold = self.unfold(query_map)
# 调整形状,进行相乘操作,这里的self.k**2//2:self.k**2//2+1为选择区域的中心点
return key_map_unfold * query_map_unfold[:, :, :, self.k**2//2:self.k**2//2+1]
# 结合几何先验和外观可组合性
def combine_prior(appearance_kernel, geometry_kernel):
# 使用Softmax结合两者
return torch.nn.functional.softmax(appearance_kernel + geometry_kernel, dim=-1)
# 局部关系层
class LocalRelationalLayer(torch.nn.Module):
def __init__(self, channels, k, stride=1, m=None, padding=0):
super(LocalRelationalLayer, self).__init__()
# 初始化参数
self.channels = channels # 通道数
self.k = k # 局部区域的大小
self.stride = stride # 步长
self.m = m or 8 # 注意力头的数量,默认为8
self.padding = padding # 填充
# 初始化各个子模块
self.kmap = KeyQueryMap(channels, k)
self.qmap = KeyQueryMap(channels, k)
self.ac = AppearanceComposability(k, padding, stride)
self.gp = GeometryPrior(k, channels//m)
self.unfold = torch.nn.Unfold(k, 1, padding, stride)
self.final1x1 = torch.nn.Conv2d(channels, channels, 1)
def forward(self, x):
# 计算几何先验
gpk = self.gp(0)
# 生成Key和Query映射
km = self.kmap(x)
qm = self.qmap(x)
# 计算外观可组合性
ak = self.ac((km, qm))
# 结合几何先验和外观可组合性
ck = combine_prior(ak, gpk)[:, None, :, :, :]
# 提取输入特征的局部区域
x_unfold = self.unfold(x)
# 调整形状并进行加权平均
pre_output = (ck * x_unfold).view(x.shape[0], x.shape[1], -1, x_unfold.shape[-2] // x.shape[1])
# 计算输出特征图的高和宽
h_out = (x.shape[2] + 2 * self.padding - 1 * (self.k - 1) - 1) // self.stride + 1
w_out = (x.shape[3] + 2 * self.padding - 1 * (self.k - 1) - 1) // self.stride + 1
# 聚合特征并调整形状
pre_output = torch.sum(pre_output, axis=-1).view(x.shape[0], x.shape[1], h_out, w_out)
# 应用最后的1x1卷积层并返回结果
return self.final1x1(pre_output)
论文名《Stand-Alone Self-Attention in Vision Models》
发表:NeurIPS 2019
所属领域(关键词):视觉transformer,全注意力视觉模型
1.动机和创新
这一篇和上一篇很接近,连方法论都很相似。动机的话,主要是考虑到卷积神经网络在捕获长范围交互时的挑战性,而自注意力恰好可以弥补这一点不足。
现有一些方法已经结合CNN+Self-attention已经实现了较好的结果,其中Self-attention主要用来实现基于内容(content)的交互的。
本文作者是想构建一个完全基于注意力的视觉模型,这也是Stand-Alone一词的由来,这样的好处是能够直接捕获长距离交互。
当然,这篇论文也是通过在value上构建大小来实现局部关联(local correlation)。为什么选择局部,是因为如果选择全局注意力实现全局关联,那么运算量会很大。
2.思路和方法
如下图所示为本文提出方法的大致示意图:

可见和上面提到的Local Relation Layer很像。
由于这篇论文没有给出详细的网络结构图,这里我给出CoTNet中关于这篇论文的网络图,具体如下:
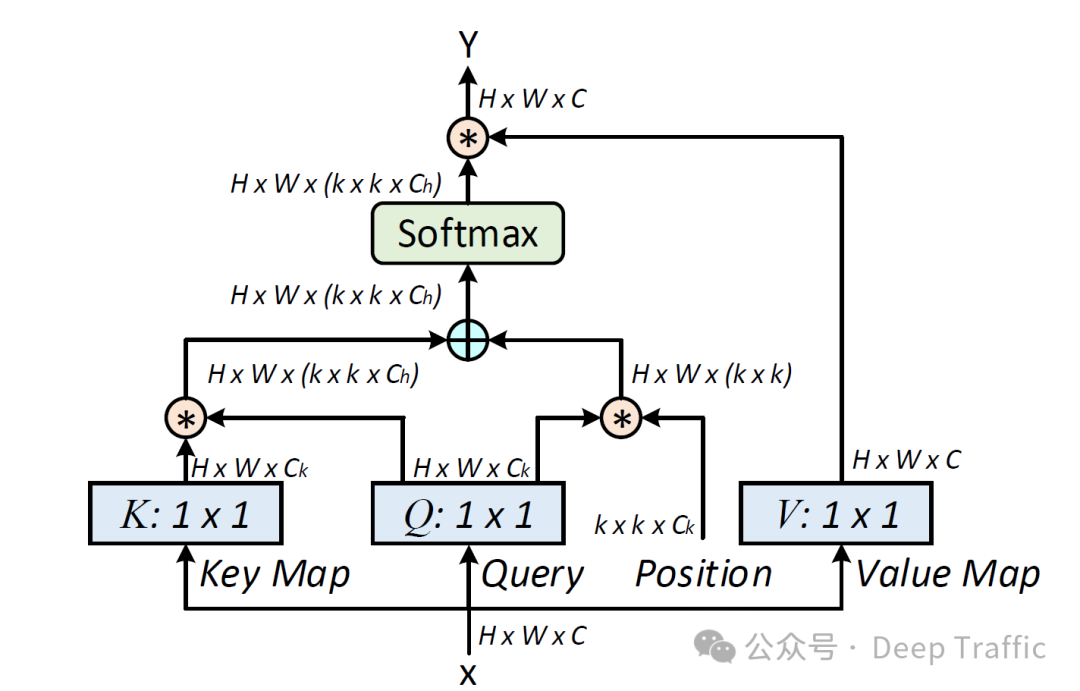
这个流程其实和Local Relation Layer很像,但是这个图画的远没有Local Relation Layer的直观(因为他省略了很多步骤,比如取的区域,而且他也不是以一个query位置为例的,而是以整体实现过程中的张量运算为例)。
这里我以一个query位置为例,拆开来说一下它的运算流程,如下:
-
输入Input Feature(通道数为),分别通过一个1×1大小的卷积核,得到Key Map和Query Map,通道数为,其中,视为注意力头的数量。
-
对于每个注意力头中Query Map的每一个位置,在Key Map中提取出一个以该点为中心,的区域,然后对应像素点相乘,得到一个关联图,其大小为。图中的****其实是遍历了所有query和其对应局部key的结果。
-
为区域构建相对位置的位置编码,其中query位置为原点,那么具体相对位置编码如下图所示:
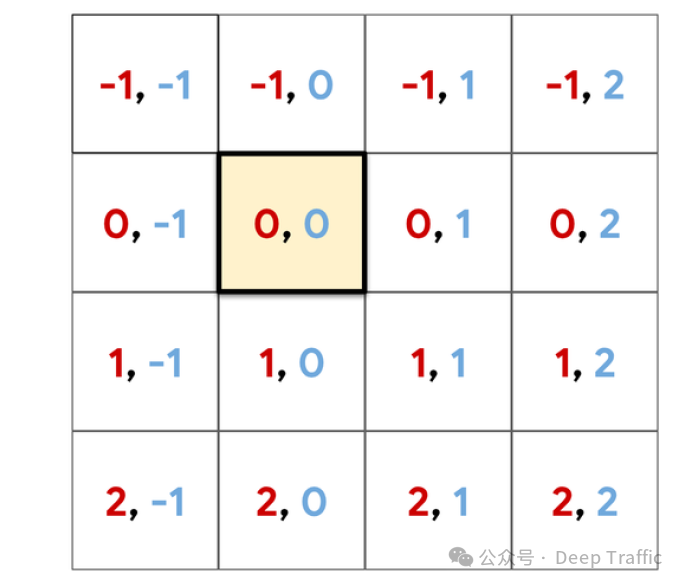
-
将位置编码与query相乘后与关联图相加。这等同于赋予了关联图(所在维度)相对位置信息。随后,输入到softmax,输出注意力图。
-
对Input Feature提取出对应的一个的区域(value),然后与注意力图进行乘法运算,即对范围进行加权平均操作,最终得到该点的结果,大小为。
-
遍历所有的query的空间尺度(大小为),以及堆叠所有的注意力头,最后聚合成输出Y,其大小为。上述过程其实与Local Relation Layer过程非常接近,稍微有点不同的可能是这个是相对位置编码的差异。具体实现代码如下:
class AttentionConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, groups=1, bias=False):
super(AttentionConv, self).__init__()
# 初始化输入参数
self.out_channels = out_channels # 输出通道数
self.kernel_size = kernel_size # 卷积核大小
self.stride = stride # 步长
self.padding = padding # 填充
self.groups = groups # 分组卷积的组数
# 确保输出通道数可以被组数整除
assert self.out_channels % self.groups == 0, "out_channels should be divided by groups. (example: out_channels: 40, groups: 4)"
# 初始化相对位置编码的参数
self.rel_h = nn.Parameter(torch.randn(out_channels // 2, 1, 1, kernel_size, 1), requires_grad=True) # 针对高度方向的相对位置编码
self.rel_w = nn.Parameter(torch.randn(out_channels // 2, 1, 1, 1, kernel_size), requires_grad=True) # 针对宽度方向的相对位置编码
# 定义key, query, value的1x1卷积层
self.key_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=bias) # Key卷积层
self.query_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=bias) # Query卷积层
self.value_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=bias) # Value卷积层
# 初始化参数
self.reset_parameters()
def forward(self, x):
# 获取输入特征图的尺寸
batch, channels, height, width = x.size()
# 对输入特征图进行填充
padded_x = F.pad(x, [self.padding, self.padding, self.padding, self.padding])
# 通过1x1卷积生成query, key, value特征图
q_out = self.query_conv(x)
k_out = self.key_conv(padded_x)
v_out = self.value_conv(padded_x)
# 将key和value特征图展开,形成局部窗口
k_out = k_out.unfold(2, self.kernel_size, self.stride).unfold(3, self.kernel_size, self.stride)
v_out = v_out.unfold(2, self.kernel_size, self.stride).unfold(3, self.kernel_size, self.stride)
# 将key特征图分为两部分,并加上相对位置编码
k_out_h, k_out_w = k_out.split(self.out_channels // 2, dim=1)
k_out = torch.cat((k_out_h + self.rel_h, k_out_w + self.rel_w), dim=1)
# 重塑key和value特征图以适应后续计算
k_out = k_out.contiguous().view(batch, self.groups, self.out_channels // self.groups, height, width, -1)
v_out = v_out.contiguous().view(batch, self.groups, self.out_channels // self.groups, height, width, -1)
# 重塑query特征图
q_out = q_out.view(batch, self.groups, self.out_channels // self.groups, height, width, 1)
# 计算注意力权重,并通过加权求和得到输出特征图
out = q_out * k_out
out = F.softmax(out, dim=-1)
out = torch.einsum('bnchwk,bnchwk -> bnchw', out, v_out).view(batch, -1, height, width)
return out
这里我看了一下相对位置编码的实现其实是设置成可学习的随机参数了,而不是论文中的相对位置,这一点有点奇怪,我在github的issue中也看到别人问了,貌似作者没有正面回答。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈