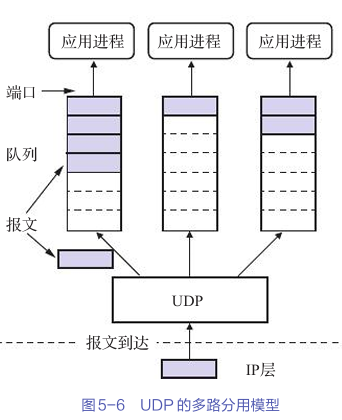
在本项目中,通过数据科学和AI的方法,分析挖掘人力资源流失问题,并基于机器学习构建解决问题的方法,并且,我们通过对AI模型的反向解释,可以深入理解导致人员流失的主要因素,HR部门也可以根据分析做出正确的决定。
探索性数据分析

##1.数据加载
import pandas as pd
import seaborn as sns
data = pd.read_csv('../data/train.csv')
#分析建模,查看数据情况,1.数据包含数值型和类别型
data

查看数据基本信息
#字段,类型,缺失情况
data.info()
data.info() 来获取数据的信息,包括总行数(样本数)和总列数(字段数)、变量的数据类型、数据集中非缺失的数量以及内存使用情况。
从数据集的信息可以看出,一共有31 个特征,Attrition 是目标字段,23个变量是整数类型变量,8个是对象类型变量。

2.数据基本分析
#数据无缺失值,查看数据分布
data.describe()

跑baseline模型(使用不同的分类算法)
对特征不进行处理
# 选出数值型特征
numerical_feat = data.select_dtypes(include=['int64'])
numerical_feat
# 切分特征和标签
X = numerical_feat.drop(['Attrition'],axis=1)
Y = numerical_feat.Attrition
# 特征幅度缩放
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
x_scaled = scaler.fit_transform(X)
x_scaled = pd.DataFrame(x_scaled, columns=X.columns)
x_scaled
# 第一次跑模型
## 训练集测试集切分
from sklearn.model_selection import train_test_split
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
import xgboost as xgb
import lightgbm as lgb
X_train, X_test, Y_train, Y_test = train_test_split(x_scaled,Y,test_size=0.3,random_state=1)
# 决策树
dt_clf = DecisionTreeClassifier()
dt_clf.fit(X_train, Y_train)
dt_auc = roc_auc_score(Y_test, dt_clf.predict_proba(X_test)[:, 1])
# 逻辑回归
lr_clf = LogisticRegression()
lr_clf.fit(X_train, Y_train)
lr_auc = roc_auc_score(Y_test, lr_clf.predict_proba(X_test)[:, 1])
# 随机森林
rf_clf = RandomForestClassifier()
rf_clf.fit(X_train, Y_train)
rf_auc = roc_auc_score(Y_test, rf_clf.predict_proba(X_test)[:, 1])
# 集成学习 - 梯度提升
gb_clf = GradientBoostingClassifier()
gb_clf.fit(X_train, Y_train)
gb_auc = roc_auc_score(Y_test, gb_clf.predict_proba(X_test)[:, 1])
#XGBoost
xgb_clf = xgb.XGBClassifier(eval_metric="auc")
xgb_clf.fit(X_train, Y_train)
xgb_auc = roc_auc_score(Y_test, xgb_clf.predict_proba(X_test)[:, 1])
#LightGBM
lgb_clf = lgb.LGBMClassifier()
lgb_clf.fit(X_train, Y_train)
lgb_auc = roc_auc_score(Y_test, lgb_clf.predict_proba(X_test)[:, 1])
# 打印AUC值
print(f"Decision Tree AUC: {dt_auc}")
print(f"Logistic Regression AUC: {lr_auc}")
print(f"Random Forest AUC: {rf_auc}")
print(f"Gradient Boosting AUC: {gb_auc}")
print(f"XGBoost AUC: {xgb_auc}")
print(f"LightGBM AUC: {lgb_auc}")

3.特征工程
人才流失中,更多的是做特征选择
尝试编码
# 按照出差的频度进行编码
data.BusinessTravel = data.BusinessTravel.replace({
'Non-Travel':0,'Travel_Rarely':1,'Travel_Frequently':2
})
# 性别与overtime编码
data.Gender = data.Gender.replace({'Male':1,'Female':0})
data.OverTime = data.OverTime.replace({'Yes':1,'No':0})
data.Over18 =data.Over18.replace({'Y':1,'N':0})
# 独热向量编码
new_df = pd.get_dummies(data=data,columns=['Department','EducationField','JobRole', 'MaritalStatus'])
new_df
# 切分特征和标签
X = new_df.drop(['Attrition'],axis=1)
Y = new_df.Attrition
# 特征幅度缩放
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
x_scaled = scaler.fit_transform(X)
x_scaled = pd.DataFrame(x_scaled, columns=X.columns)
# 决策树
dt_clf = DecisionTreeClassifier()
dt_clf.fit(X_train, Y_train)
dt_auc = roc_auc_score(Y_test, dt_clf.predict_proba(X_test)[:, 1])
# 逻辑回归
lr_clf = LogisticRegression()
lr_clf.fit(X_train, Y_train)
lr_auc = roc_auc_score(Y_test, lr_clf.predict_proba(X_test)[:, 1])
# 随机森林
rf_clf = RandomForestClassifier()
rf_clf.fit(X_train, Y_train)
rf_auc = roc_auc_score(Y_test, rf_clf.predict_proba(X_test)[:, 1])
# 集成学习 - 梯度提升
gb_clf = GradientBoostingClassifier()
gb_clf.fit(X_train, Y_train)
gb_auc = roc_auc_score(Y_test, gb_clf.predict_proba(X_test)[:, 1])
#XGBoost
xgb_clf = xgb.XGBClassifier(eval_metric="auc")
xgb_clf.fit(X_train, Y_train)
xgb_auc = roc_auc_score(Y_test, xgb_clf.predict_proba(X_test)[:, 1])
#LightGBM
lgb_clf = lgb.LGBMClassifier()
lgb_clf.fit(X_train, Y_train)
lgb_auc = roc_auc_score(Y_test, lgb_clf.predict_proba(X_test)[:, 1])
# 打印AUC值
print(f"Decision Tree AUC: {dt_auc}")
print(f"Logistic Regression AUC: {lr_auc}")
print(f"Random Forest AUC: {rf_auc}")
print(f"Gradient Boosting AUC: {gb_auc}")
print(f"XGBoost AUC: {xgb_auc}")
print(f"LightGBM AUC: {lgb_auc}")

并没有明显提高
特征筛选,选出对模型贡献度大的特征
## 训练集测试集切分
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import mutual_info_classif
X_train, X_test, Y_train, Y_test = train_test_split(x_scaled,Y,test_size=0.3,random_state=1)
mutual_info = pd.Series(mutual_info)
mutual_info.index = X_train.columns
mutual_info.sort_values(ascending=False)
plt.title("Feature Importance",fontsize=20)
mutual_info.sort_values().plot(kind='barh',figsize=(12,9),color='r')
plt.show()

剔除无效特征(后18位)
sorted_mutual_info = mutual_info.sort_values(ascending=False)
# 获取互信息值最低的18个特征的索引(列名)
least_important_feature_indices = sorted_mutual_info.tail(18).index
# 从new_df中删除这些特征
new_df = new_df.drop(columns=least_important_feature_indices)
new_df

# 切分特征和标签
X = new_df.drop(['Attrition'],axis=1)
Y = new_df.Attrition
# 特征幅度缩放
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
x_scaled = scaler.fit_transform(X)
x_scaled = pd.DataFrame(x_scaled, columns=X.columns)
## 训练集测试集切分
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import mutual_info_classif
X_train, X_test, Y_train, Y_test = train_test_split(x_scaled,Y,test_size=0.3,random_state=1)
# 定义模型列表
models = [
("Decision Tree", DecisionTreeClassifier()),
("Logistic Regression", LogisticRegression()),
("Random Forest", RandomForestClassifier()),
("Gradient Boosting", GradientBoostingClassifier()),
("XGBoost", xgb.XGBClassifier(eval_metric="auc")),
("LightGBM", lgb.LGBMClassifier())
]
# 训练模型并计算AUC
for name, model in models:
model.fit(X_train, Y_train)
pred_proba = model.predict_proba(X_test)[:, 1]
auc = roc_auc_score(Y_test, pred_proba)
print(f"{name} AUC: {auc}")

有了明显提高
做一些SMOTE
# SMOTE处理类别不均衡
from imblearn.over_sampling import SMOTE
sm = SMOTE(sampling_strategy='minority')
x,y = sm.fit_resample(X,Y)
# 过采样之后的比例
sns.countplot(data=new_df,x=y,palette='Set1')
plt.show()
print(y.value_counts())

# 特征幅度缩放
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
x_scaled = scaler.fit_transform(x)
x_scaled = pd.DataFrame(x_scaled, columns=x.columns)
## 训练集测试集切分
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import mutual_info_classif
X_train, X_test, Y_train, Y_test = train_test_split(x_scaled,y,test_size=0.3,random_state=1)
# 定义模型列表
models = [
("Decision Tree", DecisionTreeClassifier()),
("Logistic Regression", LogisticRegression()),
("Random Forest", RandomForestClassifier()),
("Gradient Boosting", GradientBoostingClassifier()),
("XGBoost", xgb.XGBClassifier(eval_metric="auc")),
("LightGBM", lgb.LGBMClassifier())
]
# 训练模型并计算AUC
for name, model in models:
model.fit(X_train, Y_train)
pred_proba = model.predict_proba(X_test)[:, 1]
auc = roc_auc_score(Y_test, pred_proba)
print(f"{name} AUC: {auc}")

模型有了大幅度提高
LOF
from pyod.models.lof import LOF
train = new_df.copy()
val = new_df.copy()
#创建LOF对象
clf = LOF(n_neighbors=20, algorithm='auto')
# 切分特征和标签
X = train.drop(['Attrition'],axis=1)
#无监督学习算法,因此没有y,不需要传入y
clf.fit(X)
#模型预测
train['out_pred'] = clf.predict_proba(X)[:,1]
#随机给的一个93%分数数的一个参考值(93%是随便给的,不宜太小)
#判断依据:只要小于93%分位数的值,就说明这个样本是正常数据,如果大于93%分位数的值,则说明是异常数据
key = train['out_pred'].quantile(0.93)
# 'Attrition' 是目标变量列,我们不想将其包括在特征列表中
excluded_columns = ['Attrition']
# 获取所有列名,并将排除列从列表中移除
feature_lst = [col for col in new_df.columns.tolist() if col not in excluded_columns]
#获取用于模型训练的特征列
x = train[train['out_pred'] < key][feature_lst]
y = train[train['out_pred'] < key]['Attrition']
#准备验证集的x和y
x =train[feature_lst]
y = train['Attrition']
val_x = val[feature_lst]
val_y = val['Attrition']
#模型训练
lr_model = LogisticRegression(C=0.1,class_weight='balanced')
lr_model.fit(x,y)
from sklearn.metrics import roc_curve
#模型预测和画图
y_pred = lr_model.predict_proba(x)[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
from matplotlib import pyplot as plt
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR')
plt.plot(fpr_lr,tpr_lr,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()

交叉验证和超参数调优
- 网格搜索:模型针对具有一定范围值的超参数网格进行评估,尝试参数值的每种组合,并实验以找到最佳超参数,计算成本很高。
- 随机搜索:这种方法评估模型的超参数值的随机组合以找到最佳参数,计算成本低于网格搜索。
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import cross_val_score
# 定义模型列表
models = [
("Decision Tree", DecisionTreeClassifier()),
("Logistic Regression", LogisticRegression()),
("Random Forest", RandomForestClassifier()),
("Gradient Boosting", GradientBoostingClassifier()),
("XGBoost", xgb.XGBClassifier(eval_metric="auc")),
("LightGBM", lgb.LGBMClassifier())
]
# X_train, Y_train, X_test, Y_test是已经准备好的数据集
# X_scaled是经过标准化的特征数据集
# 训练模型并计算AUC
for name, model in models:
model.fit(X_train, Y_train)
pred_proba = model.predict_proba(X_test)[:, 1]
auc = roc_auc_score(Y_test, pred_proba)
print(f"{name} AUC: {auc}")
# 使用交叉验证查看得分
for name, model in models:
print("******", name, "******")
cv_scores = cross_val_score(model, x_scaled, y, cv=5, scoring='roc_auc') # 使用roc_auc作为评分标准
cv_mean = cv_scores.mean()
print(f"Cross-validated AUC mean score: {cv_mean}")

from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer, roc_auc_score
# 定义模型列表
models = [
("Decision Tree", DecisionTreeClassifier(), {'max_depth': [3, 5, 10]}),
("Logistic Regression", LogisticRegression(), {'C': [0.1, 1, 10]}),
("Random Forest", RandomForestClassifier(), {'n_estimators': [10, 50, 100]}),
("Gradient Boosting", GradientBoostingClassifier(), {'n_estimators': [50, 100, 200]}),
("XGBoost", xgb.XGBClassifier(eval_metric="auc"), {'n_estimators': [50, 100, 200]}),
("LightGBM", lgb.LGBMClassifier(), {'n_estimators': [50, 100, 200]})
]
# 使用网格搜索进行交叉验证
for name, model, params in models:
print(f"Grid searching {name}...")
grid_search = GridSearchCV(model, param_grid=params, cv=5, scoring='roc_auc')
grid_search.fit(X_scaled, y)
print(f"Best parameters for {name}: {grid_search.best_params_}")
print(f"Cross-validated AUC mean score for {name}: {grid_search.best_score_}")



![[JavaScript版本五子棋小游戏]](https://i-blog.csdnimg.cn/direct/015ebc0fe8924ebf9df683b52a1f73f9.png)