正则表达式是什么?
正则表达式(Regular Expression,通常简写为 regex、regexp 或 RE)是一种强大的文本处理工具,用于描述一组字符串的模式。它可以用来匹配、查找、替换等操作,几乎所有现代编程语言都支持正则表达式的使用,包括 Java 和 JavaScript (Vue.js 应用中的 JavaScript 代码)。在实际开发中,正则表达式可以用于验证表单输入、解析文本文件、进行文本搜索和替换等任务。
在线测试工具
正则表达式在线测试 | 菜鸟工具 (jyshare.com)
正则表达式 – 语法 | 菜鸟教程 (runoob.com)
语法
1、普通字符
1.1 [ABC]
匹配 [...] 中的所有字符
例如: /[abcd]/g 会匹配到
![]()
1.2 [^ABC]
匹配除了 [...] 中字符的所有字符
例如: /[^abcd]/g 会匹配
![]()
1.3 [A-Z]
[A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。
例如: /[A-Z]/g 会匹配
![]()
1.4 . (有点子问题)
匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。
例如: /./g 会匹配
![]()
1.5 [\s\S]
匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。
例如:/[\s]/g 会匹配
![]()
例如: /[\S]/g 会匹配
![]()
例如: /[\s\S]/g会匹配
![]()
1.6 \w或[\w]
匹配字母、数字、下划线。等价于 [A-Za-z0-9_]
例如: /[\w]/g 会匹配
![]()
1.7 \d或[\d]
匹配任意一个阿拉伯数字(0 到 9)。等价于 [0-9]
例如: /\d/g 会匹配
![]()
2、 非打印字符--了解
| 字符 | 描述 |
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
3、特殊字符
| 特别字符 | 描述 |
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。 |
| ( ) | 标记一个子表达式的开始和结束位置。 子表达式可以获取供以后使用。 要匹配这些字符,请使用 \( 和 \)。 |
| * | 匹配前面的子表达式零次或多次。 要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。 要匹配 + 字符,请使用 \+。 |
| [ | 标记一个中括号表达式的开始。 要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次, 或指明一个非贪婪限定符。 要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。 例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。 序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。 要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。 要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \|。 |
4、限定符(重要)
| * | 匹配前面的子表达式零次或多次。* 等价于 {0,}。 例如:zo*
|
| + | 匹配前面的子表达式一次或多次。+ 等价于 {1,}。 例如:zo*
|
| ? | 匹配前面的子表达式零次或一次。? 等价于 {0,1}。 例如:zo?
do(es)?
|
| {n} | n 是一个非负整数。匹配确定的 n 次。 例如:do(es){1}
o{2}
|
| {n,} | n 是一个非负整数。至少匹配n 次。o{1,} 等价于 o+。o{0,} 则等价于 o*。 例如:o{1,}
o{2,}
|
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。 例如: o{2,3}
|
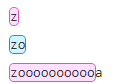

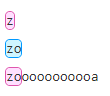
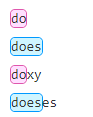

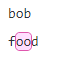
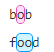


5、定位符(重要)
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 例如:^a(b|c)
另一个无匹配
|
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 例如:^a(b|c)*$
另一个无匹配
|
| \b | 匹配一个单词边界,即字与空格间的位置。 例如
有六处匹配 |
| \B | 非单词边界匹配 例如:
有七处匹配 |
6、选择-分组(x|x)
用圆括号 () 将所有选择项括起来,相邻的选择项之间用 | 分隔。
() 表示捕获分组,() 会把每个分组里的匹配的值保存起来, 多个匹配值可以通过数字 n 来查看(n 是一个数字,表示第 n 个捕获组的内容)。
例如:
([1-9])([a-z]+)
![]()
匹配以第一个数字开头多个字母结尾。
6.1 exp1(?=exp2):查找 exp2 前面的 exp1。
例如:abc(?=[\d+])
![]()
匹配数字前面的abc
6.2 (?<=exp2)exp1:查找 exp2 后面的 exp1。
例如:(?<=\d+)abc
![]()
匹配数字后面的abc
6.3 exp1(?!exp2):查找后面不是 exp2 的 exp1。
例如:abc(?![0-9]+)
![]()
匹配后面不是数字的 abc
6.4(?<!exp2)exp1:查找前面不是 exp2 的 exp1。
例如:(?<![0-9]+)abc
![]()
匹配前面不是数字abc
7、修饰符(标记)
格式:/正则表达式/修饰符
| 符 | 含义 | 描述 |
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。 |
| g | global - 全局匹配 | 查找所有的匹配项。 |
| m | multi line - 多行匹配 | 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。 |
| s | 特殊字符圆点 . 中包含换行符 \n | 默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |
7.1 修饰符-g 全局匹配
例如:/abc/g
![]()
例如:
![]()
7.2 修饰符-i 不区分大小写
例如: /abc/gi
![]()
7.3 修饰符-m 多行匹配
例如:/abc/gm

注:实例可以是\n
7.4 修饰符-s 特殊字符.包含换行
例如:/abc/gs
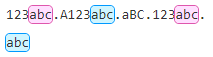
常用正则表达式
一、校验数字的表达式
1.数字:^[0-9]*$
2.n位的数字:^\d{n}$
3.至少n位的数字:^\d{n,}$
4.m-n位的数字:^\d{m,n}$
5.非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(\.[0-9]{1,2})?$
6.带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})$
7.正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
8.非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
9.非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
10.非负整数:^\d+$ 或 ^[1-9]\d*|0$
二、校验字符的表达式
- 汉字:^[\u4e00-\u9fa5]{0,}$
- 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
- 长度为3-20的所有字符:^.{3,20}$
- 由26个英文字母组成的字符串:^[A-Za-z]+$
- 由26个大写英文字母组成的字符串:^[A-Z]+$
- 由26个小写英文字母组成的字符串:^[a-z]+$
- 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
- 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
三、特殊需求的表达式
- Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
- 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?
- 手机号码:^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$
- 身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)
- 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
- 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$
- 强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
- 日期格式:^\d{4}-\d{1,2}-\d{1,2}
- IPv4地址:((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}
JavaScript中使用
一、创建正则表达式
1、RegExp函数
语法
//pattern是字符串形式的正则表达式
//flags是字符串形式的修饰符,包含igm等
let patttern = new RegExp("pattern","flags")示例
let patttern = new RegExp("abcd","g")2、字面量创建正则表达式
语法
//pattern是字符串形式的正则表达式
//flags是字符串形式的修饰符,包含igm等
const regex = /pattern/flags;示例
const regex = /abc/g;二、js正则表达式常用方法
1、test()方法
检测字符串是否匹配正则表达式
const str = "Hello World";
const regex = /hello/i; // 忽略大小写
console.log(regex.test(str)); // 输出 true
2、exec()方法
用于执行一个匹配,返回匹配结果的数组或 null。
const str = "Hello World";
const regex = /hello/i;
const match = regex.exec(str);
console.log(match); // 输出 ["Hello", index: 0, input: "Hello World", groups: undefined]
3、match()方法
用于在字符串中执行一个匹配
const str = "Hello World";
const match = str.match(/hello/i);
console.log(match); // 输出 ["Hello"]
4、search()方法
用于查找匹配的位置。
const str = "Hello World";
const index = str.search(/hello/i);
console.log(index); // 输出 0
5、replace()方法
用于替换字符串中的匹配项。
const str = "Hello World";
const newStr = str.replace(/hello/i, "Hi");
console.log(newStr); // 输出 "Hi World" 6、split()方法
用用于根据匹配项分割字符串。
const str = "Hello,World,Again";
const words = str.split(/,/);
console.log(words); // 输出 ["Hello", "World", "Again"] 三、示例
function validateEmail(email) {
const emailRegex = /^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$/;
return emailRegex.test(email);
}
console.log(validateEmail("example@example.com")); // 输出 true
console.log(validateEmail("invalid-email.com")); // 输出 false
java中使用
在 Java 中,正则表达式主要通过 java.util.regex 包中的类来实现。以下是使用正则表达式的一些基本方法:
一、创建正则表达式
在 Java 中,可以通过 Pattern 类来创建正则表达式对象。
1、使用字符串创建
Pattern pattern = Pattern.compile("your_regex_here");2、使用字符串和标志位创建
Pattern pattern = Pattern.compile("your_regex_here", Pattern.CASE_INSENSITIVE | Pattern.MULTILINE);二、java正则表达式常用方法
1、matches() 方法
用于检测字符串是否完全匹配正则表达式。
String str = "Hello World";
boolean matches = str.matches("Hello.*World");
System.out.println(matches); // 输出 true
2、find()方法
用于在字符串中查找匹配项。
String str = "Hello World";
Pattern pattern = Pattern.compile("Hello.*World");
Matcher matcher = pattern.matcher(str);
boolean found = matcher.find();
System.out.println(found); // 输出 true
3、replaceAll() 方法
用于替换字符串中的匹配项。
String str = "Hello World";
String replaced = str.replaceAll("Hello", "Hi");
System.out.println(replaced); // 输出 "Hi World"
4、replaceFirst() 方法
用于替换字符串中的第一个匹配项。
String str = "Hello World, Hello again";
String replaced = str.replaceFirst("Hello", "Hi");
System.out.println(replaced); // 输出 "Hi World, Hello again"
5、split() 方法
用于根据匹配项分割字符串
String str = "Hello,World,Again";
String[] words = str.split(",");
for (String word : words) {
System.out.println(word); // 输出 "Hello", "World", "Again"
}6、Matcher 类
提供了更多高级功能,如查找多个匹配项、获取匹配位置等。
String str = "Hello World, Hello again";
Pattern pattern = Pattern.compile("Hello");
Matcher matcher = pattern.matcher(str);
while (matcher.find()) {
System.out.println("Found at position: " + matcher.start() + " - " + matcher.end());
}
三、示例
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class EmailValidator {
public static void main(String[] args) {
String email = "example@example.com";
boolean isValid = validateEmail(email);
System.out.println(isValid); // 输出 true
}
public static boolean validateEmail(String email) {
String EMAIL_PATTERN = "^[_A-Za-z0-9-\\+]+(\\.[_A-Za-z0-9-]+)*@"
+ "[A-Za-z0-9-]+(\\.[A-Za-z0-9]+)*(\\.[A-Za-z]{2,})$";
Pattern pattern = Pattern.compile(EMAIL_PATTERN);
Matcher matcher = pattern.matcher(email);
return matcher.matches();
}
}
注意事项:
当使用正则表达式进行多次匹配时,可以考虑使用 Pattern 编译正则表达式,以避免每次调用时重新编译正则表达式。
使用 Matcher 类时,如果希望进行多次匹配,可以使用 find() 方法。
当使用 replaceAll() 或 replaceFirst() 时,如果需要全局匹配,可以使用带有 Pattern.DOTALL 标志的正则表达式。
C#中使用
在 C# 中使用正则表达式可以通过 System.Text.RegularExpressions 命名空间下的 Regex 类来实现。下面是一些基本的使用方法和示例。
一、 引入命名空间
首先,需要引入 System.Text.RegularExpressions 命名空间。
using System.Text.RegularExpressions;
二、 创建正则表达式对象
你可以创建一个 Regex 对象来编译正则表达式,以便多次使用。
Regex regex = new Regex(@"\b[A-Za-z]+\b");//匹配任何单词字符。三、 常用方法
1、 IsMatch()
检查字符串是否与正则表达式匹配。
bool isMatch = regex.IsMatch("This is a test.");//true2、 Match()
返回一个 Match 对象,表示第一次匹配的结果。
Match match = regex.Match("This is a test.");
if (match.Success)
{
Console.WriteLine("Match found: " + match.Value);//This
}3、 Matches()
返回一个 MatchCollection,包含所有匹配的结果
MatchCollection matches = regex.Matches("This is a test.");
foreach (Match m in matches)
{
Console.WriteLine("Match found: " + m.Value);
}
4、 Replace()
替换匹配的部分。
string result = regex.Replace("This is a test.", "new word");
//结果:new word new word new word new word. 匹配的四个单词全部替换四、示例
验证电子邮件地址
using System;
using System.Text.RegularExpressions;
class Program
{
static void Main()
{
string email = "example@example.com";
string pattern = @"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$";
Regex regex = new Regex(pattern);
bool isValid = regex.IsMatch(email);
if (isValid)
{
Console.WriteLine("Email is valid.");
}
else
{
Console.WriteLine("Email is invalid.");
}
}
}