Selenium 是否有效?
Selenium 是一个流行的开源网页自动化框架,主要用于浏览器测试自动化。此外,它也可以用来解决动态网页抓取问题。
Selenium 有三个主要组件:
- Selenium IDE:一个浏览器插件,提供了一种更快、更简单的方式来创建、执行和调试 Selenium 脚本。
- Selenium WebDriver: 一组便携的 API,帮助你用任何编程语言编写在浏览器上运行的自动化测试。
- Selenium Grid: 自动化工具,用于在多个浏览器、操作系统和平台上分发和扩展测试。
Browserless 对于网页抓取是否好用?
什么是 Browserless?
Nstbrowserless 是一个基于云的无头 Chrome 服务,它执行网页操作并运行自动化脚本,无需图形用户界面。它特别适合自动化任务,如网页抓取和其他自动化过程。
Browserless 对于网页抓取是否好用?
是的,绝对好用!Nstbrowserless 可以在云端完成复杂的网页抓取和其他自动化任务。它会释放你设备的本地服务和存储。Nstbrowserless 通过防检测浏览器和无头 Chrome 特性进行工作。不再需要担心被检测到或遇到网站屏蔽。
将 Browserless 和 Selenium 结合使用,通过让 Selenium 在 Browserless 提供的云端无头 Chrome 环境中运行测试脚本来增强网页自动化。这种设置对于大规模任务,如网页抓取,是有效的,因为它消除了对物理浏览器的需求,同时仍能处理动态内容和用户交互。
你对网页抓取和 Browserless 有什么精彩的想法和疑问吗?
让我们看看其他开发者在 Discord 和 Telegram 上分享了什么吧!
Selenium 网页抓取的优势是什么?
- 处理动态内容: Selenium 可以与 JavaScript 重的网站进行交互。它允许你抓取在初始页面加载后动态加载的内容。
- 浏览器自动化: Selenium 可以模拟用户与网站的实际交互,例如点击按钮、填写表单和导航页面,使其非常适合抓取需要用户交互的网站的数据。
- 多浏览器支持: Selenium 支持多种浏览器(Chrome、Firefox、Safari),因此你可以在不同环境中进行测试和抓取。
- 编程语言灵活性: Selenium 与多种编程语言兼容,包括 Python、Java、C# 和 JavaScript,这为开发者提供了选择其首选语言的灵活性。
- 绕过反抓取措施: Selenium 模拟真实用户行为的能力使其能够有效绕过一些旨在防止自动化抓取的反抓取措施,例如 CAPTCHA 和限流。
- 实时数据收集: 使用 Selenium,你可以实时抓取和收集数据,这对于时间敏感的应用非常有用。
- 广泛的社区和文档: Selenium 拥有一个庞大且活跃的社区,以及广泛的文档,帮助解决问题并提高你的网页抓取项目的效率。
如何在 Selenium 中使用 NodeJS?
通过在 Selenium 中使用 Node.js,开发者可以控制无头 Chrome 执行各种操作,如网页抓取、自动化测试、生成屏幕截图等。
这种组合利用了 Node.js 的高效非阻塞特性和无头 Chrome 的浏览器能力,实现高效的自动化和数据处理。
步骤 1. 安装
在终端中输入以下命令:
npm install selenium-webdriver如果终端报告错误,请检查你的计算机是否有 node 环境:
node --version没有 node 环境?请先安装最新版本的 node 环境。
步骤 2. 使用 NodeJS 在 Selenium 中运行浏览器
Selenium 以其强大的浏览器自动化能力而闻名。它支持大多数主要浏览器,包括 Chrome、Firefox、Edge、Opera、Safari 和 Internet Explorer。
由于 Chrome 是其中最受欢迎和最强大的浏览器,你将在本教程中使用它。
import { Builder, Browser } from 'selenium-webdriver';
async function run() {
const driver = new Builder()
.forBrowser(Browser.CHROME)
.build();
await await driver.get('https://www.yahoo.com/');
}你还可以添加任何个性化的设置。让我们将脚本设置为无头 Chrome:
import { Builder, Browser } from 'selenium-webdriver';
import chrome from 'selenium-webdriver/chrome';
const options = new chrome.Options();
options.addArguments('--remote-allow-origins=*');
options.addArguments('--headless');
async function run() {
const driver = new Builder()
.setChromeOptions(options)
.forBrowser(Browser.CHROME)
.build();
await await driver.get('https://www.yahoo.com/');
}现在,你可以访问任何网站了!
步骤 3. 抓取网站
一旦你有了网页的完整 HTML,你可以继续提取所需的数据。在这种情况下,让我们解析页面上所有新闻的标题和内容。
为完成此任务,你必须执行以下步骤:
- 使用 DevTools 分析网页的 DOM。
- 实现有效的节点选择策略以定位新闻。
- 提取所需数据并将其存储在 JavaScript 数组/对象中。
DevTools 是网页抓取中一个宝贵的工具。它帮助你检查当前加载的 HTML、CSS 和 JavaScript。你还可以获得有关页面网络请求及其对应加载时间的信息。
CSS 选择器和 XPath 表达式是最可靠的节点选择策略。你可以使用其中任何一个来定位元素,但在本教程中,为了简单起见,我们将使用 CSS 选择器。
让我们使用 DevTools 查找正确的 CSS 选择器。在浏览器中打开目标网页并右键点击产品元素 > 检查以打开 DevTools。
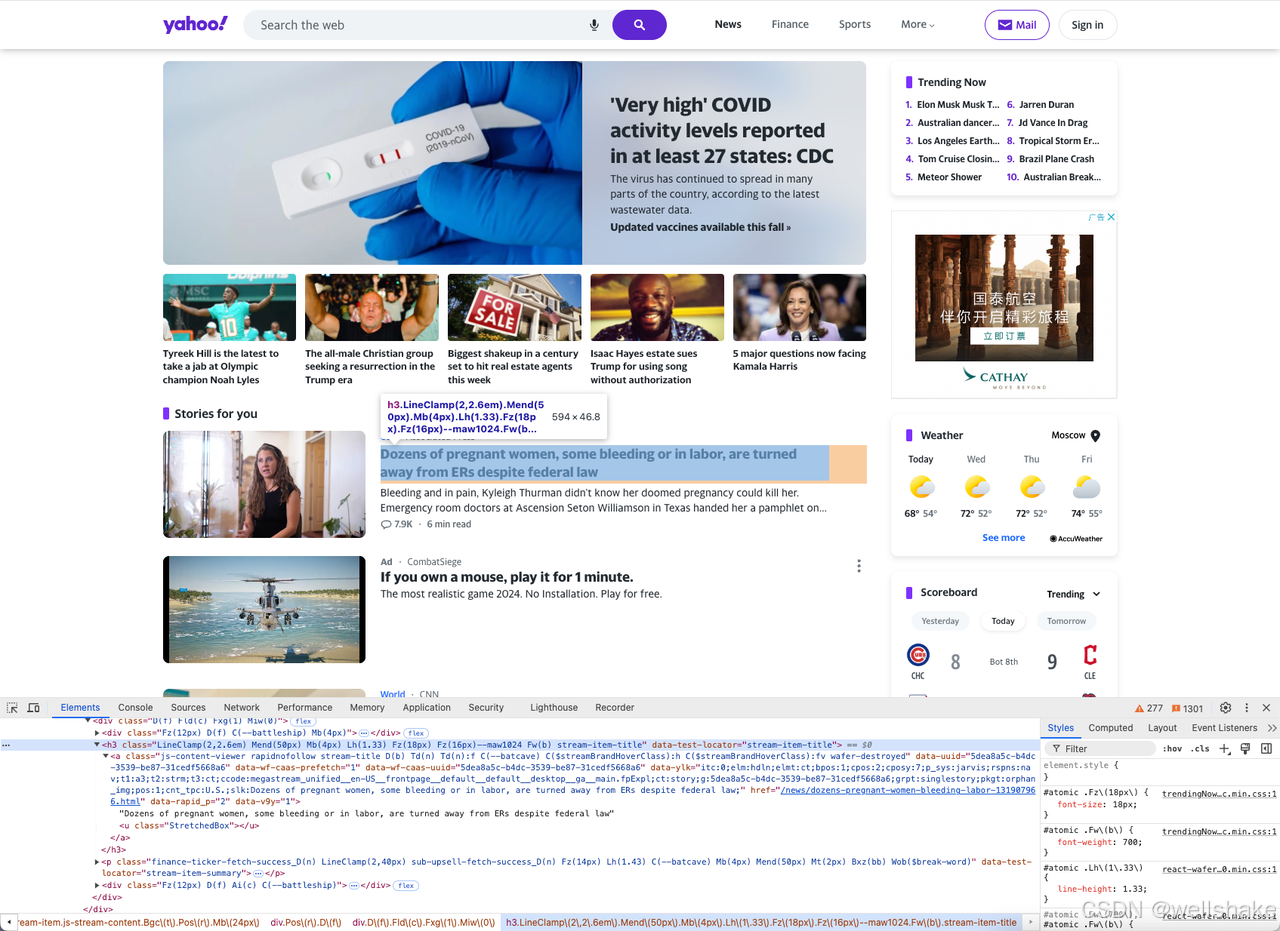
你可以看到每个新闻标题的结构由一个 h3 标签和 a 标签组成,我们可以使用选择器 h3[data-test-locator="stream-item-title"] 来定位它们。
我们使用相同的方法查找选择器 p[data-test-locator="stream-item-summary"] 用于新闻内容。
使用上述信息定义 CSS 选择器,并通过 findElements() 和 findElement() 方法定位产品。
此外,使用 getText() 方法提取 HTML 节点的内文本,最后将提取的名称和价格存储在一个数组中。
const titlesArray = [];
const contentArray = [];
const newsTitles = await driver.findElements(By.css('h3[data-test-locator="stream-item-title"]'));
const newsContents = await driver.findElements(By.css('p[data-test-locator="stream-item-summary"]'));
for (let title of newsTitles) {
titlesArray.push(await title.getText());
}
for (let content of newsContents) {
contentArray.push(await content.getText());
}步骤 4. 导出数据
我们已经获得了网页抓取的数据!现在,我们需要将它们导出到一个 CSV 文件中。
导入内置的 Node.js fs 模块,该模块提供了处理文件系统的函数:
import fs from 'node';然后,初始化一个名为 newsData 的字符串变量,其中包含一个包含列名的标题行("title, content\n")。
let newsData = 'title,content\n';接下来,循环遍历包含新闻标题和内容的两个数组(titlesArray 和 contentsArray)。对于数组中的每个元素,在 newsData 后附加一行,用逗号分隔标题和内容。
for (let i = 0; i < titlesArray.length; i++) {
newsData += `${titlesArray[i]},${contentsArray[i]}\n`;
}使用 fs.writeFile() 函数将 newsData 字符串写入名为 yahooNews.csv 的文件中。此函数接受三个参数:文件名、要写入的数据和处理写入过程中遇到的任何错误的回调函数。
fs.writeFile("yahooNews.csv", newsData, err => {
if (err) {
console.error("Error:", err);
} else {
console.log("Success!");
}
});运行我们的代码,我们会得到类似于以下的结果:

恭喜你,已经学会了如何使用 Selenium 和 HeadlessChrome: NodeJS 进行网页抓取。
如何避免在使用 Browserless 抓取时被封锁?
在 Browserless 中使用 headlesschrome 模式可以最大限度地自动避免网页检测和封锁。但请结合以下策略以获得更高效的抓取和无缝体验。
- 模拟真实用户行为
以下是一个使用 Selenium 和 Node.js 模拟真实用户行为的示例代码。代码展示了如何设置 User-Agent、模拟鼠标操作、处理动态内容、模拟键盘输入和控制浏览器行为。
在使用之前,请确保已安装 selenium-webdriver 和 chromedriver。
const { Builder, By, Key, until } = require('selenium-webdriver');
const chrome = require('selenium-webdriver/chrome');
const path = require('path');
// 启动浏览器
(async function example() {
// 配置 Chrome 选项
let chromeOptions = new chrome.Options();
chromeOptions.addArguments('headless'); // 使用 headless 模式
chromeOptions.addArguments('window-size=1280,800'); // 设置浏览器窗口大小
// 创建 WebDriver 实例
let driver = await new Builder()
.forBrowser('chrome')
.setChromeOptions(chromeOptions)
.build();
try {
// 设置 User-Agent 和其他请求头
await driver.executeCdpCmd('Network.setUserAgentOverride', {
userAgent: 'Your Custom User-Agent',
});
// 导航到目标页面
await driver.get('https://example.com');
// 模拟鼠标移动和点击
let element = await driver.findElement(By.css('selector-for-clickable-element'));
await driver.actions().move({ origin: element }).click().perform();
// 随机等待时间
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
await sleep(Math.random() * 5000 + 2000); // 随机等待 2 到 7 秒
// 处理动态内容并等待特定元素加载
await driver.wait(until.elementLocated(By.css('#dynamic-content')), 10000);
// 模拟键盘输入
let searchInput = await driver.findElement(By.css('#search-input'));
await searchInput.sendKeys('Node.js', Key.RETURN);
// 随机滚动
await driver.executeScript('window.scrollBy(0, window.innerHeight);');
} finally {
// 关闭浏览器
await driver.quit();
}
})();- 使用代理
使用代理服务器隐藏实际的 IP 地址可以有效避免 IP 封锁。你可以选择轮换代理,以在每次请求时使用不同的 IP 地址,从而减少被封锁的风险。
- 限制抓取频率
控制抓取频率,以避免在短时间内发送大量请求,这可以减少触发反爬虫机制的机会。你可以设置适当的时间间隔来发送请求,以模拟正常的浏览行为。
- 绕过 CAPTCHA
如果网站使用 CAPTCHA 进行保护,你可以使用第三方 CAPTCHA 识别服务自动解决这些挑战,或者配置 Selenium 以处理 CAPTCHA。
- 隐藏真实浏览器指纹
一些网站使用浏览器指纹来识别自动化工具。配置不同的浏览器指纹或使用内置指纹切换的 反检测浏览器可以帮助绕过网站检测。
- 处理动态加载的内容
使用 Browserless 结合 Selenium 处理动态加载的内容(如 AJAX 请求)可以确保捕获网页上的所有动态渲染数据,而不仅仅是静态内容。
使用 Selenium 进行其他网页操作
1. 定位元素
Selenium 本身提供了多种方法来查找页面元素,包括:
- 按标签名查找:按元素的标签名搜索,如
<input>或<button>,适合广泛搜索。 - 按 HTML 类名查找:使用元素的 CSS 类名搜索,如
.class-name,适合快速定位具有特定类名的元素。 - 按 ID 查找:按元素的唯一 ID 搜索,如
#element-id,特别适合快速准确地找到特定元素。 - 使用 CSS 选择器:使用 CSS 选择器语法查找元素,可以选择具有特定属性、类名或结构的元素,如 div
> p.class-name。 - 使用 XPath 表达式:通过 XPath 路径查找元素,允许精确导航页面结构,如
//div[@id='example']。
因此,在 Selenium WebDriver 中,我们可以通过 find_element 方法在网页上定位元素。你只需在使用时添加具体要求。例如:
find_element_by_id:按唯一 ID 查找元素。find_element_by_class_name:按 CSS 类名查找元素。find_element_by_link_text:按链接文本查找超链接元素。
2. 等待元素
在某些情况下,如网络或浏览器缓慢,你的脚本可能会失败或显示不一致的结果。
不要等到固定的时间间隔,而是选择智能等待,如等待特定节点出现或显示在页面上。这可以确保在与元素交互之前,网页元素已正确加载,从而减少 element not found 和 element not interactable 等错误的机会。
以下代码片段实现了等待策略。until.elementsLocated 方法定义了等待条件,确保 WebDriver 等待直到指定的元素找到或达到最大等待时间 5000 毫秒(5 秒)。
const { Builder, By, until } = require('selenium-webdriver');
const yourElements = await driver.wait(until.elementsLocated(By.css('.your-css-selector')), 5000);3. 截图
在 NodeJS 中,你可以通过调用一个函数来截图。然而,有一些考虑事项以确保截图正确捕获:
- 窗口大小:确保浏览器窗口大小适合你需要捕获的内容。如果窗口太小,页面的部分内容可能会被截断。
- 页面加载完成:在截图之前,确认所有异步 HTTP 请求已完成,页面已完全渲染。这确保截图准确反映页面的最终状态。
import fs from 'node';
import { Builder, Browser } from 'selenium-webdriver';
async function screenshot() {
const driver = new Builder()
.forBrowser(Browser.CHROME)
.build();
await driver.get('https://www.yahoo.com/');
const pictureData = await driver.takeScreenshot();
fs.writeFileSync('screenshot.png', pictureData, 'base64');
}
screenshot();4. 执行自定义 JavaScript 命令
使用像 Selenium 这样的浏览器自动化工具的一个突出特点是可以利用浏览器自身的 JavaScript 引擎。这意味着你可以在你与之交互的网页上下文中注入和执行自定义的 JavaScript 代码。
const javascript = 'window.scrollBy(100, 100)';
await driver.executeScript(javascript);最终想法
在本 Selenium Node.js 教程中,你学习了如何使用 headlesschrome 和 Selenium 来设置一个 Node.js WebDriver 项目,从动态网站中抓取数据,处理动态内容,并解决常见的网页抓取挑战。
现在是建立你自己的网页抓取流程的好时机!借助 Nstbrowser RPA,一切复杂的任务将会得到简化。