往期回顾>>
-
华为内部“维度数据”解析
-
数据入湖是个什么鬼?
-
为什么数据治理工作越来越迷茫?(附数据治理方案PPT下载)
-
数字化的本质逻辑:连接、数据、智能
-
125页PPT:数据中台应用技术方案
-
数据中台解决方案,附55页PPT下载
-
125页PPT:某行业数据架构蓝图规划方案
-
PPT分享:数据治理的方法论、设计思路与方案(干货)
-
数字化转型之数据治理(附PPT下载链接)
-
PPT分享:某集团主数据治理项目方案与主数据治理方法论
-
智能工厂的数据采集与应用是怎么做的?附PPT分享:智能制造工业互联网数字化智能工厂解决方案
-
Hadoop大数据平台构建及应用案例分析
-
PPT分享:华为-联通大数据平台规划方案
-
27页PPT:数据安全治理解决方案
-
67页PPT:如何利用大数据进行数据挖掘与分析
-
华为数据架构核心要素:基于业务对象进行设计和落地
数据湖建设方案下载链接见文末~
从传统信息化向数字化转型的过程中,企业积累了海量的数据,并且不断地增长。数据很多,但真正产生价值的数据却很少。数据普遍存在分散、不拉通的问题,缺乏统一的定义和架构,找到想要的、能使用的数据越来越困难。
华为从2007年就启动了数据治理,经历了两个阶段的持续变革,系统地建立了华为数据管理的体系。第一阶段10年的持续投入为华为在2016年开始的数字化转型打下了坚实的基础。同时在数字化转型蓝图的规划下,华为正式进入以建立统一的数据底座为核心的第二阶段,数据治理工作也迎来了新的挑战和发展。
今天笔者给读者带来的是华为数据底座的基础部分的构建内容-数据湖,详细说明华为如何通过数据湖的建设,实现数据的汇聚与连接,打破数据孤岛的。
数据湖是数据底座的基础部分,是逻辑上对各种原始数据的汇聚和集合,数据湖保留了数据的原格式,不对数据进行清洗和加工。
华为数据湖面向各领域,实现数据资产找得到、可理解、可信任,是数据主题联接和数据消费的基础。
华为数据湖的3个特点
华为数据湖(见下图)是逻辑上对内外部、结构化、非结构化的原始数据的逻辑汇聚。数据入湖要遵从6项入湖标准,以保证入湖数据的数据质量。
数据入湖的方式包括物理入湖和虚拟入湖。采用物理入湖时,原始数据将被物理存储在数据湖的物理表中;采用虚拟入湖时,原始数据不在数据湖中进行物理存储,而是通过建立对应虚拟表的集成方式实现入湖。两种方式相互协同,面向不同的消费场景共同满足数据连接和用户数据消费需求。
经过近几年的数据湖建设,华为目前已经完成2.2万个逻辑数据实体,50多万个业务属性的数据入湖,同时数据入湖在华为公司也形成了标准的流程和规范,每个数据资产都要入湖成为数据工作的重要标准。
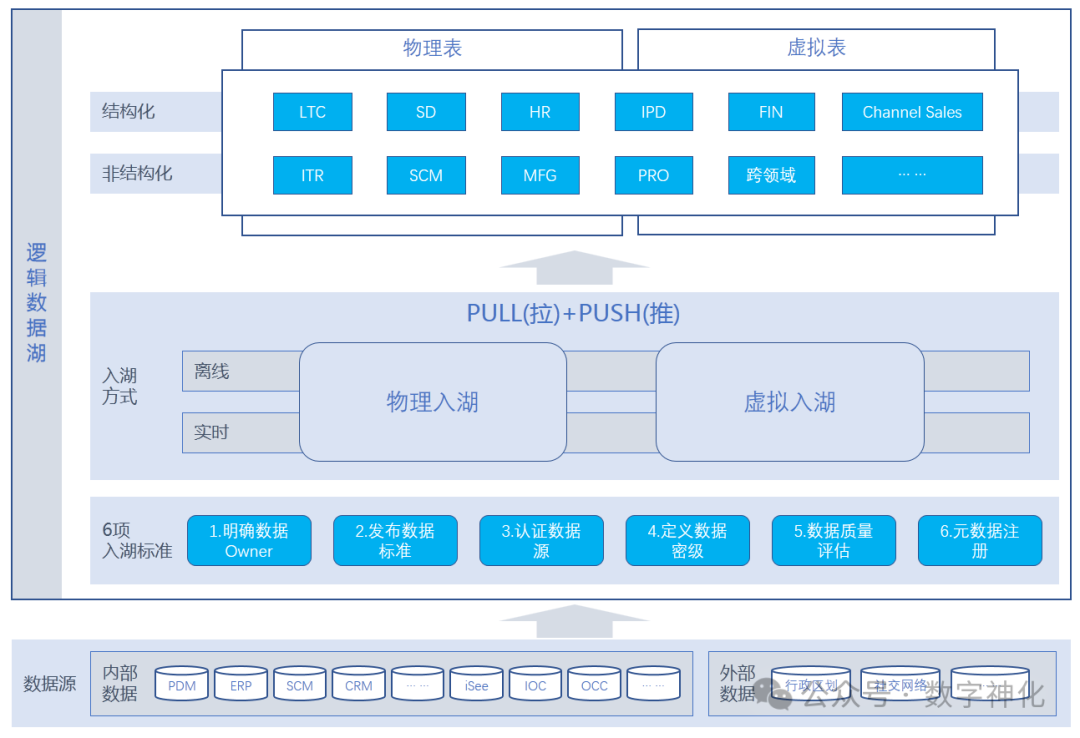
华为数据湖主要有以下几个特点:
1)逻辑统一。华为数据湖不是一个单一的物理存储,而是根据数据类型、业务区域等多个不同的物理存储构成,并通过统一的元数据语义层进行定义、拉通和管理。
2)类型多样。数据湖存放所有不同类型的数据,包括企业内部IT系统产生的结构化数据、业务交易和内部管理的非结构化的文本数据、公司内部园区各种传感器检测到的设备运行数据以及外部的媒体数据等。
3)原始记录。华为数据湖是对原始数据的汇聚,不对数据做任何的转换、清洗、加工等处理,保留数据最原始特征,为数据的加工和消费提供丰富的可能。
数据入湖的6项标准
数据入湖是数据消费的基础,需要严格满足入湖的6项标准,包括明确数据Owner、发布数据标准、认证数据源、定义数据密级、数据质量评估、元数据注册。通过这6项标准保证入湖的数据都有明确的业务责任人,且各项数据都可理解,同时都能在相应的信息安全保证下进行消费。
1.明确数据 Owner
数据 Owner 主要由数据产生所对应的流程Owner来担任,是所辖数据端到端管理的责任人,负责对入湖的数据定义数据标准和密级,承接数据消费中的数据质量问题,并制订数据管理工作路标,持续提升数据质量。
2.发布数据标准
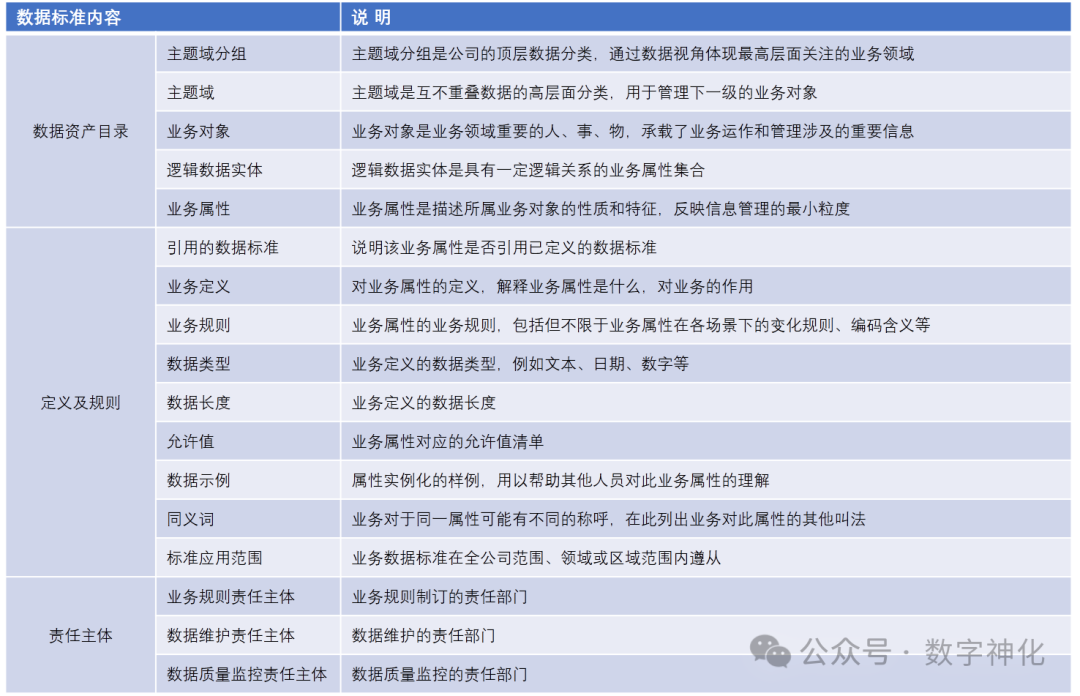
入湖数据要有相应的业务数据标准。业务数据标准描述公司层面需共同遵守的“属性层”数据含义和业务规则,是公司层面对某个数据的共同理解,这些理解一旦明确并发布,就需要作为标准在企业内被共同遵守。数据标准包括的信息如下表所示。
3.认证数据源
认证数据源,以确保数据从正确的数据源头入湖。认证数据源需遵循公司数据源管理的要求,一般数据源是指业务上首次正式发布某项数据的IT系统,并经过数据管理专业组织认证。认证过的数据源作为唯一数据源头被数据湖调用。当承载数据源的IT系统出现合并、分拆、下线情况时,需及时对数据源进行失效处理,并启动新数据源认证。
4.定义数据密级
定义数据密级是数据入湖的必要条件,为了确保数据湖中的数据能充分共享,同时又不发生信息安全问题,入湖的数据必须要定密。数据定密的责任主体是数据Owner,数据管家有责任审视入湖数据密级的完整性,并推动、协调数据定密工作。数据密级定义在属性层级,根据资产的重要程度,定义不同等级。不同密级的数据,有相应的数据消费要求。同时,为了促进公司数据的消费,数据湖中的数据有相应的降密机制,到降密期或满足降密条件的数据应及时降密,并刷新密级信息。
5.数据质量评估
数据质量是数据消费结果的保证。数据入湖不需要通过清洗数据来提升数据质量,但需要对数据质量进行评估,让数据消费人员了解数据的质量情况,并了解消费该数据的质量风险。同时数据Owner和数据管家可以根据数据质量评估的情况,推动源头数据质量的提升,满足数据质量的消费要求。
6.元数据注册
元数据注册是指将人湖数据的业务元数据和技术元数据进行关联,包括逻辑实体与物理表的对应关系,及业务属性和表字段的对应关系。连接业务元数据和技术元数据的关系,能够支撑数据消费人员通过业务语义快速地搜索到数据湖中的数据,降低数据湖中数据消费的门槛,让更多的业务分析人员能理解和消费数据。
华为数据入湖方式
数据入湖道循华为信息架构,以逻辑数据实体为粒度进行入湖。逻辑数据实体在首次人湖时应该考虑信息的完整性,原则上一个逻辑数据实体的所有属性应该一次人湖,避免一个逻辑实体多次入湖,增加入湖工作量。
数据人湖的方式主要有物理入湖和虚拟入湖两种。根据数据消费的场景和需求,一个逻辑实体可以有不同的入湖方式。两种入湖方式相互协同,共同满足数据连接和用户数据消费需求。数据管家有责任根据消费场景的不同,提供相应的人湖数据。
物理入湖是指将原始数据复制到数据湖中,包括批量处理、数据复制同步、消息和流集成等方式。虚拟入湖是指原始数据不在数据湖中进行物理存储,而是通过建立对应虚拟表的集成方式实现入湖,实时性强,一般面向小数据量应用,大批量的数据操作可能影响源系统。
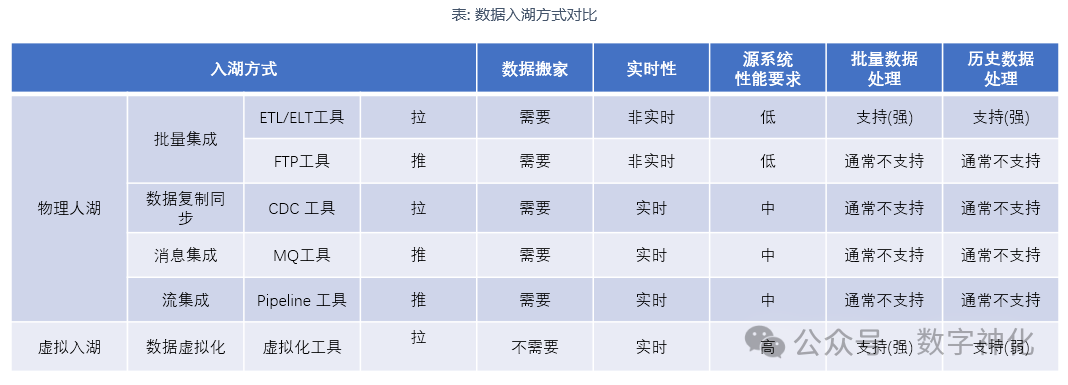
数据入湖的5种主要技术手段包括批量集成(Bulk/Batch Data Movement)、数据复制同步(Data Replication/Data Synchronization)、消息集成(Message-Oriented Movement of Data)、流集成(StreamDataIntegration)、数据虚拟化(Data Virtualization)。
1.批量集成
对于需要进行复杂数据清理和转换且数据量较大的场景,批量集成是首选。通常,调度作业每小时或每天执行,主要包含ETL、ELT及FTP等工具。批量集成不适合低数据延迟和高灵活性的场景。
2.数据复制同步
数据复制同步适用于需要高可用性和对数据源影响小的场景。使用基于日志的CDC捕获数据变更,实时获取数据。数据复制同步不适合处理各种复杂的数据结构以及需要清理和转换复杂数据的场景。
3.消息集成
消息集成通常通过API捕获或提取数据,适用于处理不同数据结构以及需要高可靠性和复杂转换的场景。尤其是对于许多遗留系统、ERP和SaaS应用来说,消息集成是唯一的选择。消息集成不适合处理大量数据的场景。
4.流集成
流集成主要关注流数据的采集和处理,满足数据实时集成,每秒处理数万、数十万甚至数以百万计的事件流。流集成不适合用于需要复杂数据清理和转换的场景。
5.数据虚拟化
对于需要低延迟、高灵活性和临时模式(不断变化下的模式)的数据消费场景,数据虚拟化是一个很好的选择。在数据虚拟化的基础上,通过共享数据访问层,分离数据源和数据湖,减少数据源变更带来的影响,同时支持数据实时消费。数据虚拟化不适合处理大量数据场景。
5种数据入湖方式的对比可以参考下表。
数据入湖可以由数据湖主动从数据源通过PULL(拉)的方式入湖,也可以由数据源主动PUSH(推)的方式入湖。数据复制同步、数据虚拟化以及传统ETL批量集成都是属于数据湖主动拉的方式。流集成、消息集成属于主动推的方式(见下表)。在特定的批量集成场景下,数据会以CSV、XML等格式,通过FTP推送给数据湖。

数据湖的建设方案下载链接:
https://pan.baidu.com/s/1Ko4aZiN31BfBllJxF4135A?pwd=5wgv

![[答疑]心脏的功能是泵血,心脏是个模块,所以“功能模块”没毛病啊!](https://img-blog.csdnimg.cn/img_convert/af9e390df0453142436d44a1d070b342.png)












![[ 全部搞定 - 发票导出表格 ] PDF发票提取到表,图片发票提取到表格,扫描件发票提取到表格,全电发票PDF,全电发票扫描件识别导出EXCEL表格](https://i-blog.csdnimg.cn/direct/5c210fb098f54763ad83294b79b16c2f.jpeg)